Cluster Journaling
This chapter contains information about journaling on ECP-based shared-disk clustered systems in Caché. It discusses the following topics:
For related information, see the following chapters:
-
“Backup and Restore” in this guide
-
“Journaling” in this guide
-
“Shadowing” in this guide
-
Configuring Cluster Settings in the “Configuring Caché” chapter of the Caché System Administration Guide
Journaling on Clusters
Journaling is necessary for cluster failover to bring the databases up to date and to use transaction processing. Each node in a cluster maintains its own journal files, which must be accessible to all other nodes in the cluster to ensure recoverability. A cluster session ID (CSI) is the time when the session begins, that is, the cluster start time, which is stored in the header of every journal file on a clustered system.
In addition to the information journaled on a nonclustered system, the following specifics apply to clustered systems:
-
Updates to clustered databases are always journaled, (usually on the master node only) except for scratch globals. On a cluster database, even globals whose database journaling attribute is No are journaled regardless of whether they are updated outside or within a transaction.
-
Database updates via the $Increment function are journaled on the master node as well as on the local node if it is not the master.
-
Other updates are journaled locally if so configured.
The journal files on clustered systems are organized using the following:
The default location of the journal files is in the install-dir\Mgr\journal directory of the Caché instance. However, InterSystems recommends placing journal files on separate storage devices from those on which database files and the CACHE.WIJ file are located. See Journaling Best Practices in the “Journaling” chapter of this guide for more information about separating journal storage.
Do not stop journaling in a cluster environment, although it is possible to do so with the ^JOURNAL routine. If you do, the recovery procedure is vulnerable until the next backup.
Cluster Journal Log
Journal files used by members of a cluster are logged in a file, CACHEJRN.LOG, located in the cluster pre-image journal, or PIJ directory. It contains a list of journal files maintained by nodes while they are part of the cluster. Journal files maintained by a node when it is not part of the cluster may not appear in the cluster journal log; for more information, see Journal History Log in the “Journaling” chapter of this guide.
Following is an example of part of a cluster journal log:
0,_$1$DRA1:[TEST.50.MGR.JOURNAL]20030913.004
1,_$1$DKA0:[TEST.50.MGR.JOURNAL]20030916.002
0,_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.001
0,_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.002
1,_$1$DRA1:[TEST.5A.MGR.JOURNAL]20030916.002
1,_$1$DRA1:[TEST.5A.MGR.JOURNAL]20030916.003
The first value in each comma-delimited row is the cluster system number (CSN) of the node to which the journal file, the second field, belongs. The log is useful for locating journal files of all the members of a cluster, especially the members that have left the cluster. The CSN of a node may change when it restarts.
When a node joins the cluster its current journal file is added to the journal log. Processes that start journaling or switch journal files also add entries. The log is used in a cluster journal restore, by shadowing, and by the journal dump utility.
Cluster Journal Sequence Numbers
InterSystems recommends locking globals in cluster-mounted databases if you require a record of the sequence of updates. This is the tool Caché uses to record the time-sequencing of updates in the journal files of the cluster nodes. If cluster failover occurs, the journals of all the nodes can be applied in the proper order. Updates may not be dejournaled in the same order as they originally occurred, but they are valid with respect to the synchronization guaranteed by the Lock command and $Increment function.
To restore clustered databases properly from the journal files, the updates must be applied in the order they occurred. The cluster journal sequence number, which is part of every journal entry of a database update, and the cluster session ID, which is part of the journal header, provide a way to sequence transactions from the journal files of all the cluster members. For each cluster session, the sequence number starts at 1 and can go as high as 18446744073709551619 (that is, 2**64-1).
The master node of a cluster maintains a master copy of the sequence number, which is incremented during database mounting, and with each use of Lock and $Increment. The master value of the sequence propagates to one or all cluster nodes, depending on the type of operation.
The sequence number is used by cluster journal restore and shadowing, which is a special form of journal restore. Both utilities operate on the assumption that the sequence number increases monotonically during a cluster session.
At the end of a backup, the cluster journal sequence number on all cluster nodes is incremented to be higher than the previous master cluster journal sequence number. Then a journal marker bearing the new cluster journal sequence number is placed in the current local journal file. In a sense, the journal marker serves as a barrier of cluster journal sequence numbers, separating the journaled database updates that are covered in the backup from those that are not. Following the restore of the backup, cluster journal restore can start from the cluster journal sequence number of the journal marker and move forward.
You can also set your own journal markers using the ^JRNMARK utility. See Setting Journal Markers on a Clustered System for details.
Cluster Failover
The Caché cluster failover process protects the integrity of data on other cluster nodes when one cluster member fails. It allows the remaining cluster members to continue to function. The following conditions must be met for cluster failover to work successfully:
-
All directories containing CACHE.DAT files must be accessible to all surviving nodes.
-
Journaling must be enabled at all times while Caché is running.
-
Networking must be properly configured.
If a cluster member fails, the cluster master executes cluster failover. If the master is the failing node, the cluster member that least recently joined the cluster becomes the new master and executes failover. Cluster failover consists of two phases.
In the first phase, the cluster master does the following:
-
Checks the cluster PIJ and the write image journal files (CACHE.WIJ) on each node to determine what recovery is needed from these files.
-
Executes recovery from the WIJ files to all databases that had been mounted in cluster mode.
If an error occurs during this phase, the cluster crashes and further Cluster Recovery must take place.
In the second phase, the cluster master does the following:
-
Mounts databases in private mode, as required, to restore the journals of all cluster members.
-
Attempts to mount the databases in cluster mode if it cannot mount them in private mode.
-
Restores any Caché journal entries after the current index kept in the CACHE.WIJ file for each cluster member’s journal. For details, see Cluster Restore.
-
Rolls back incomplete transactions in the failed node’s journal file.
-
Reforms the lock table if it is the new cluster master; otherwise, it discards the locks of the failing node.
During failover, the journals from all cluster members are applied to the database and any incomplete transactions are rolled back. If cluster failover completes successfully, there is no database degradation or data loss from the surviving nodes. There is only minimal data loss (typically less than the last second) not visible to other cluster members from the failing node.
If failover is unsuccessful, the cluster crashes and you must shut down all cluster nodes before restarting the cluster. See the Failover Error Conditions section for more details.
Cluster Recovery
Recovery occurs when Caché stops on any cluster member. The procedure changes depending on how Caché stops. During successful failover, the recovery procedure is fairly straightforward and automatic. If, however, a clustered system crashes, the recovery is more complex.
Following a cluster crash, a clustered Caché node cannot be restarted until all of the nodes in the cluster have been stopped. If a cluster member attempts Caché startup or tries to join the cluster by cluster-mounting a disk before all other cluster members have been stopped, the following message is displayed:
ENQ daemon failed to start because cluster is crashed.
Once all members are stopped, start each node. The first node that starts runs the Caché recovery procedure if it detects there was an abnormal system shutdown. This node becomes the new cluster master. Cluster members that are not the cluster master are frequently referred to as slave nodes.
The Recovery daemon (RCVRYDMN) performs recovery on the surviving or new master node based on whether the crashed node was the master or a slave. To enable recovery, the node’s databases and WIJ files must be accessible cluster-wide. The master is responsible for managing the recovery cluster-wide based on the WIJ file on each node.
When a slave crashes, the Recovery daemon on the master node does the following:
-
It uses the journal information provided by the WIJ files to apply journal files on all cluster nodes (including the one that crashed) from a common starting point, as with all cluster journal restores.
-
It rolls back all incomplete transactions on the crashed system. Again, the rollbacks are journaled, this time on the host system of the Recovery daemon. For this reason, if you restore journal files, it is safer to do a cluster journal restore than a stand-alone journal restore, as the rollback of an incomplete transaction in one node's journal may be journaled on another node.
When the (former) master crashes, the Recovery daemon does the following:
-
As in step 1 above, it applies the journal files on all the cluster nodes.
-
In between the two steps above, it adjusts the cluster journal sequence number on its host system, which is the new master, so that it is higher than that of the last journaled entry on the crashed system, which was the old master. This guarantees the monotonic increasing property of cluster journal sequence in cluster-wide journal files.
-
As above, all incomplete transactions are rolled back on the crashed system.
If the last remaining node of a cluster crashes, restarting the first node of the cluster involves cluster journal recovery, which includes rolling back any transactions that were open (uncommitted) at the time of crash.
Cluster Restore
Typically, journal files are applied after backups are restored to bring databases up to date or up to the point of a crash. If nodes have not left or joined a cluster since the last backup, you can restore the journal files starting from the marker corresponding to the backup. If one or more nodes have joined the cluster since the last backup, the restore is more complex.
A node joins a cluster either when it restarts with a proper configuration or cluster mounts a database after startup (as long as you properly set up other parameters, such as the PIJ directory, at startup). To make journal restore easier in the latter case, switch the journal file on the node as soon as it joins the cluster.
For each node that has joined the cluster since the last backup of the cluster:
-
Restore the latest backup of the node.
-
If the backup occurred before the node joined the cluster, restore the private journal files from where the backup ends, up to the point when it joined the cluster. (You can make this easier by switching the journal file when the node joins the cluster.)
-
Restore the latest cluster backup.
-
Restore the cluster journal files starting from where the backup ends.
See Cluster Journal Restore for detailed information about running the utility.
This procedure works well for restoring databases that were privately mounted on nodes before they joined the cluster and then are cluster-mounted after that node joined the cluster. It is based on the following assumptions:
-
A cluster backup covers all cluster-mounted databases and a system-only backup covers private databases that, by definition, are not accessible to other systems of the cluster.
-
The nodes did not leave and rejoin the cluster since the last cluster backup.
In more complicated scenarios, these assumptions may not be true. The first assumption becomes false if, say, rather than centralizing backups of all cluster-mounted databases on one node, you configure each node to back up selected cluster-mounted databases along with its private databases.
In this case, you may have to take a decentralized approach by restoring one database at a time. For each database, the restore procedure is essentially the same:
-
Restore the latest backup that covers the database.
-
Restore the private journal files up to the point when the node joined the cluster, if it postdates the backup.
-
Restore the cluster journal files from that point forward.
Even if the database has always been privately mounted on the same node, it is safer to restore the cluster journal files than to apply only the journal files of that node. If the node crashed or was shut down when it was part of the cluster, open transactions on the node would have been rolled back by and journaled on a surviving node of the cluster. Restoring the cluster journal files ensures that you do not miss such rollbacks in journal files of other nodes.
InterSystems does not recommend or support the scenario where a node joins and leaves the cluster multiple times.
Failover Error Conditions
When a cluster member fails, the other cluster members notice a short pause while failover occurs. In rare situations, some processes on surviving cluster nodes may receive <CLUSTERFAILED> errors. You can trap these errors with the $ZTRAP error-trapping mechanism.
Cluster failover does not work if one of the following is true:
-
One or more cluster members go down during the failover process.
-
There is disk drive failure and the first failover phase encounters an error.
-
One of the surviving cluster members does not have a Recovery daemon.
If failover is unsuccessful, the cluster crashes and the following message appears at the operator's console:
****** Caché : CLUSTER CRASH - ALL Caché SYSTEMS ARE SUSPENDED ******
The other cluster members freeze when Caché processes reach a Set or Kill command.
Examine the failover log, which is contained in the console log (normally cconsole.log in the manager’s directory) of the cluster master, to see the error messages generated during the failover process.
If a cluster member that failed attempts startup, or a node tries to join the cluster by cluster-mounting a database while the cluster is in failover, the following message is displayed:
The cluster appears to be attempting to recover from the failure of one or more members at this time. Waiting 45 seconds for failover to complete...
A period (.) appears every five seconds until the active recovery phase completes. The mount or startup then proceeds.
If the cluster crashes during this time, the following message is displayed:
ENQ daemon failed to start because cluster is crashed.
See the Cluster Recovery section for an explanation of what happens when a cluster crashes.
Cluster Shadowing
The use of journaling in a clustered system also makes it possible to shadow a Caché cluster. In a cluster, each node manages its own journal files, which contain data involving private or cluster-mounted databases. The shadow mirrors the changes to the databases (assuming all changes are journaled) on a Caché system that is connected to the cluster via TCP. The following diagram gives an overview of the cluster shadowing process:
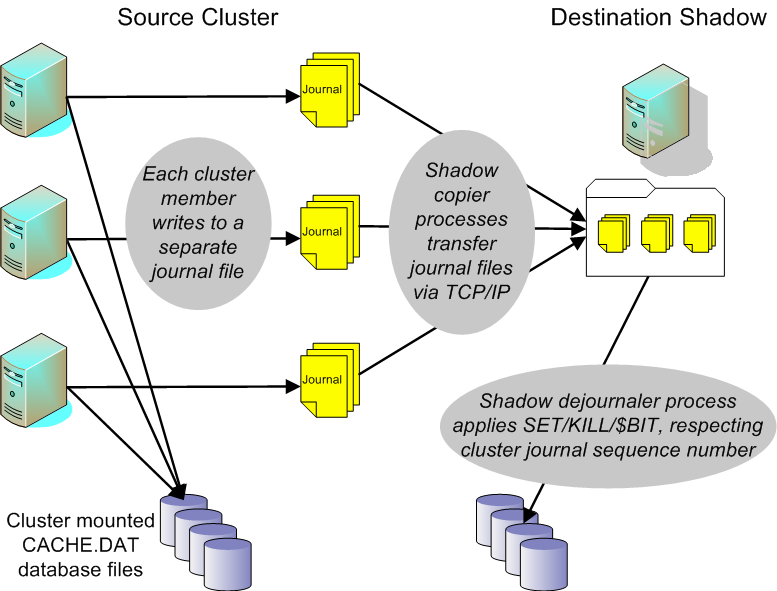
The destination shadow connects to the specified Caché superserver on the cluster, requesting a list of journal files at or after the specified start location (the combination of cluster start time and cluster journal sequence number), one starting file for each cluster member.
For each node (with a unique CSN) returned from the source cluster, the shadow starts a copier process that copies journal files, starting with the file returned, from the server to the shadow. Each copier acts as a semi-independent shadow itself, similar to a nonclustered block-mode shadow.
Once all copiers are up and running, the cluster shadow starts a dejournaling process that applies journal entries from the copied journal files to the databases on the shadow side respecting the cluster journal sequence numbers of each journal record. The cluster shadow maintains a list of current live members (including port numbers and IP addresses) of the cluster which it receives from the source cluster.
The following sections describe what information is necessary and the procedures involved in setting up a cluster shadow as well as the limitations to the completeness and timeliness of the shadow databases:
The shadow does not have to be a clustered system. The word “cluster” in cluster shadowing refers to the source database server, not the shadow.
Configuring a Cluster Shadow
You must provide several types of information to properly configure a cluster shadow. An overview of the required data items is divided into the following categories:
Although a cluster is identified by the PIJ directory that all its member nodes share, the uniqueness of the identifier does not go beyond the physical cluster that hosts the Caché cluster. The shadow needs a way to make a TCP connection to the source cluster; therefore, on the shadow you must specify the IP address or host name of one member of the Caché cluster and the port number of the superserver running on that member. Also provide the shadow with a unique identity to distinguish it from other shadows, if any, in the same Caché instance.
Configure the shadow to identify the journal starting location— a cluster start time (CSI) and, optionally, a cluster journal sequence number— for dejournaling. If you do not specify a cluster journal sequence number, dejournaling starts at the beginning of the cluster session.
Similar to noncluster shadowing, specify a directory to put the journal files copied over from the cluster. However, a single directory is not adequate; journal files from different members of the cluster must be kept separate. The directory you specify serves as the parent of the directories for the shadow copies of the journal files. In fact, the shadow creates directories on the fly to keep up with the dynamic nature of the cluster components.
At run time, for each journal directory on the server cluster, the shadow sets up a distinct subdirectory under the user-specified parent directory and copies journal files from a journal directory on the server to its corresponding directory on the shadow—this is called redirection of journal files. The subdirectories are named by sequential numbers, starting with 1. You cannot override a redirection by specifying a different directory on the shadow for a journal directory on the server.
As with nonclustered shadowing, specify database mapping, or redirections of dejournaled Set and Kill transactions.
There are two ways to provide the information to set up a cluster destination shadow:
Using the Management Portal
You can configure a shadow server using the Management Portal. Perform the following steps:
-
From the Shadow Server Settings page of the Managerment Portal (System Administration > Configuration > Connectivity > Shadow Server Settings), follow the procedure described in the Configuring the Destination Shadow section in the “Shadowing” chapter. Use the following specifics particular to cluster shadowing:
-
Database Server — Enter the IP address or host name (DNS) of one member of the source cluster to which the shadow will connect.
-
Database Server Port # — Enter the port number of the source specified in the previous step.
-
-
After entering the location information for the source instance, click Select Source Event to choose where to begin shadowing. A page displays the available cluster events from the cluster journal file directory.
-
Click Advanced to fill in the Journal file directory field. Enter the full name, including the path, of the journal file directory on the destination shadow system, which serves as the parent directory of shadow journal file subdirectories, created automatically by the shadow for each journal directory on the source cluster. ClickBrowse for help in finding the proper directory.
-
After you successfully save the configuration settings, add database mapping from the cluster to the shadow.
-
Next to Database mapping for this shadow click Add to associate the database on the source system with the directory on the destination system using the Add Shadow Mapping dialog box.
-
In the Source database directory box, enter the physical pathname of the source database file—the CACHE.DAT file. Enter the pathname of its corresponding destination shadow database file in the Shadow database directory box, and then click Save.
-
Verify any pre-filled mappings and click Delete next to any invalid or unwanted mappings. Shadowing requires at least one database mapping to start.
-
Start shadowing.
Using Caché Routines
You can also use the shadowing routines provided by Caché to configure the cluster shadow. Each of the examples in this section uses the technique of setting a return code as the result of executing the routine. After which you check the return code for an error or 1 for success.
To initially configure the cluster shadow:
Set rc=$$ConfigCluShdw^SHDWX(shadow_id,server,jrndir,begloc)| Where ... | is ... |
|---|---|
| shadow_id | A string that uniquely identifies the shadow |
| server | Consists of the superserver port number and IP address or host name of one cluster node, delimited by a comma |
| jrndir | Parent directory of shadow journal file subdirectories, where journal files fetched from the source cluster are stored on the destination shadow, one subdirectory for each journal directory on the source cluster |
| begloc | Beginning location consisting of a cluster session ID (cluster startup time, in YYYYMMDD HH:MM:SS format) and a cluster sequence number, delimited by a comma |
You can run the routine again to change the values of server, jrndir, or begloc. If you specify a new value for jrndir, only subsequent journal files fetched from the source are stored in the new location; journal files already in the old location remain there.
You can also direct the shadow to store journal files fetched from the journal directory, remdir, on the source in a local repository, locdir, instead of the default subdirectory of jrndir. Again, this change affects only journal files to be fetched, not the journal files that have been or are being fetched.
Set rc=$$ConfigJrndir^SHDWX(shadow_id,locdir,remdir)The last mandatory piece of information about a shadow, Set and Kill transaction redirection, can be given as follows:
Set rc=$$ConfigDbmap^SHDWX(shadow_id,locdir,remdir)This specifies that Set and Kill transactions from the source directory, remdir, be redirected to the shadow directory, locdir. Unlike journal files, there is no default redirection for a source database—if it is not explicitly redirected, Set and Kill transactions from that database are ignored by the dejournaling process of the shadow.
Finally, to start and stop shadowing:
Set rc=$$START1^SHDWCLI("test")
Set rc=$$STOP1^SHDWCLI("test")
See Shadow Information Global and Utilities for more information.
Cluster Shadowing Limitations
There are a few limitations in the cluster shadowing process.
Database updates that are journaled outside a cluster are not shadowed. Here are two examples:
-
After a cluster shuts down, if a former member of the cluster starts up as a stand-alone system and issues updates to some (formerly clustered) databases, the updates do not appear on the shadow.
-
After a formerly stand-alone system joins a cluster, the new updates made to its private databases appear on the shadow (if they are defined in the database mapping), but none of the updates made before the system joined the cluster appear. For this reason, joining a cluster on the fly (by cluster-mounting a database) should be planned carefully in coordination with any shadow of the cluster.
In cluster shadowing, there is latency that affects the dejournaler. Journal files on the destination shadow side are not necessarily as up to date as what has been journaled on the source cluster. The shadow applies production journals asynchronously so as not to affect performance on the production server. This results in possible latency in data applied to the shadow.
Only one Caché cluster can be the target of a cluster shadow at any time, although there can be multiple shadows on one machine. There is no guarantee regarding the interactions between the multiple shadows, thus it is the user’s responsibility to ensure that they are mutually exclusive. If you have a single instance with multiple shadows pointing at different clusters, it is your responsibility to ensure that the shadow datasets are mutually exclusive. For example, assume you have two clusters (A and B) shadowed on a single machine: cluster A has datasets X, Y, and Z; cluster B has datasets L, M, and N. Since Caché does not guarantee that datasets X (cluster A) and L (cluster B) are mutually exclusive during the dejournaling process (that is, that one shadow is dejournaling dataset X while the other is dejournaling dataset L), it is your responsibility to ensure that the datasets do not overlap.
Exclude Caché databases from RTVScan when using Symantec Antivirus software to avoid the condition of the cluster shadow hanging on Windows XP. For detailed information, see the Symantec documentationOpens in a new tab.
Tools and Utilities
The following tools and utilities are helpful in cluster journaling processes:
-
Cluster Journal Restore — ^JRNRESTO
-
Journal Dump Utility — ^JRNDUMP
-
Startup Recovery Routine — ^STURECOV
-
Cluster Journal Information Global — ^%SYS(“JRNINFO”)
-
Shadow Information Global and Utilities — ^SYS(“shdwcli”)
Cluster Journal Restore
The cluster journal restore procedure allows you to start or end a restore using the journal markers placed in the journal files by a Caché backup. You can run a cluster journal restore either as part of a backup restore or as a stand-alone procedure.
Caché includes an entry point to the journal restore interface for performing specific cluster journal restore operations. From the %SYS namespace, run the following:
Do CLUMENU^JRNRESTOThis invokes a menu that includes the following options:
Perform a Cluster Journal Restore
The first option of the cluster journal restore menu allows you to run the general journal restore on a clustered or nonclustered system. It is the equivalent of running ^JRNRESTO and answering Yes to the Cluster journal restore? prompt.
%SYS>Do ^JRNRESTO
This utility uses the contents of journal files
to bring globals up to date from a backup.
Replication is not enabled.
Restore the Journal? Yes => Yes
Cluster journal restore? Yes
You are asked to describe the databases to be restored from the journal and the starting and ending points of the restore. The starting and ending points can be based on a backup, on a set of journal markers, at a cluster start, or any arbitrary point in the journal.
The interface prompts for directory information, including any redirection specifics, and whether all databases and globals are to be processed. For example:
Directory: _$1$DKB300:[TEST.CLU.5X]
Redirect to Directory: _$1$DKB300:[TEST.CLU.5X] => _$1$DKB300:[TEST.CLU.5X]
--> _$1$DKB300:[TEST.CLU.5X]
Restore all globals in _$1$DKB300:[TEST.CLU.5X]? Yes => Yes
Directory:
For each directory you enter you are asked if you want to redirect. Enter the name of the directory to which to restore the dejournaled globals. If this is the same directory, enter the period (.) character or press Enter.
Also specify for each directory whether you want to restore all journaled globals. Enter Yes or press Enter to apply all global changes to the database and continue with the next directory. Otherwise, enter No to restore only selected globals.
At the Global^ prompt, enter the name of the specific globals you want to restore from the journal. You may select patterns of globals by using the asterisk (*) to match any number of characters and the question mark (?) to match any single character. Enter ?L to list the currently selected list of globals.
When you have entered all your selected globals, press Enter at the Global^ prompt and enter the next directory. When you have entered all directories, press Enter at the Directory prompt. Your restore specifications are displayed as shown in this example:
Restoring globals from the following clustered datasets:
1. _$1$DKB300:[TEST.CLU.5X] All Globals
Specifications for Journal Restore Correct? Yes => Yes
Updates will not be replicated
Verify the information you entered before continuing with the cluster journal restore. Answer Yes or press Enter if the settings are correct; answer No to repeat the process of entering directories and globals.
Once you verify the directory and global specifications, the Main Settings menu of the cluster journal restore setup process is displayed with the current default settings, as shown in the following example:
Cluster Journal Restore - Setup - Main Settings
1. To LOCATE journal files using cluster journal log
_$1$DKB400:[TEST.5X]CACHEJRN.LOG
with NO redirections of journal files
2. To START restore at the beginning of cluster session <20030319 15:35:37>
3. To STOP restore at sequence #319 of cluster session <20030319 15:35:37>
134388,_$1$DRA2:[TEST.5Y.JOURNAL]20030320.005
4. To SWITCH journal file before journal restore
5. To DISABLE journaling the dejournaled transactions
Select an item to modify ('Q' to quit or ENTER to accept and continue):
From this menu you may choose to modify any of the default values of the five settings by entering its menu item number:
After each modification, the Main Settings menu is displayed again, and you are asked to verify the information you entered before the restore begins. The following is an example of how the menu may look after several changes:
Cluster Journal Restore - Setup - Main Settings
1. To LOCATE journal files using cluster journal log
_$1$DKB400:[TEST.5Y.MGR]CACHEJRN.TXT
with redirections of journal files
_$1$DKB400:[TEST.5X.JOURNAL] -> _$1$DRA2:[TEST.5X.JOURNAL]
_$1$DKB400:[TEST.5Y.JOURNAL] -> _$1$DRA2:[TEST.5Y.JOURNAL]
_$1$DKB400:[TEST.5Z.JOURNAL] -> _$1$DRA2:[TEST.5Z.JOURNAL]
2. To START restore at the journal marker located at
138316,_$1$DKB400:[TEST.5X.JOURNAL]20030401.001
-> _$1$DRA2:[TEST.5X.JOURNAL]20030401.001
3. To STOP restore at the journal marker located at
133232,_$1$DKB400:[TEST.5X.JOURNAL]20030401.003
-> _$1$DRA2:[TEST.5X.JOURNAL]20030401.003
4. NOT to SWITCH journal file before journal restore
5. To DISABLE journaling the dejournaled transactions
Select an item to modify ('Q' to quit or ENTER to accept and continue):
Start journal restore?
Press Enter to accept the settings and continue. If you are using the journal log of the current cluster, you are informed that the restore will stop at the currently marked journal location and asked if you want to start the restore.
Select an item to modify ('Q' to quit or ENTER to accept and continue):
To stop restore at currently marked journal location
offset 134168 of _$1$DRA1:[TEST.50.MGR.JOURNAL]20031002.008
Start journal restore?
Enter Yes to begin the cluster journal restore. Once the restore finishes your system is ready for activity.
Enter No to go back to the main menu where you can continue to make changes to the cluster journal restore setup or enter Q to abort the cluster journal restore. After aborting the cluster journal restore, you can run a private journal restore or abort the restore process entirely.
Select an item to modify ('Q' to quit or ENTER to accept and continue): Q
Run private journal restore instead? No
[Journal restore aborted]
Replication Enabled
Change the Source of the Restore
The first item on the Main Settings menu contains the information required to find the journal files for all the cluster members. The information has two elements:
-
Cluster journal log — a list of journal files and their original full paths.
-
Redirection of journal files — necessary only if the system where you are running the restore is not part of the cluster associated with the journal log.
By default, the restore uses the cluster journal log associated with the current clustered system. If you are running the restore on a nonclustered system, you are prompted for a cluster journal log before the main menu is displayed.
Choose this option to restore the journal files on a different Caché cluster from the one that owns the journal files. You can either:
-
Identify the cluster journal log used by the original cluster.
-
Create a cluster journal log that specifies where to locate the journal files.
The option to redirect the journal files is available only if the specified cluster journal log is not that of the current cluster.
Identify the Cluster Journal Log
The Journal File Information menu displays the cluster journal log file to be used in the cluster journal restore. If the journal files on the original cluster are not accessible to the current cluster, copy them to a location accessible to the current cluster and specify how to locate them by entering redirect information.
Enter I to identify the journal log used by the original cluster.
Select an item to modify ('Q' to quit or ENTER to accept and continue): 1
Cluster Journal Restore - Setup - Journal File Info
[I]dentify an existing cluster journal log to use for the restore
Current: _$1$DRA1:[TEST.50]CACHEJRN.LOG
- OR -
[C]reate a cluster journal log by specifying where journal files are
Selection ( if no change): I
*** WARNING ***
If you specify a cluster journal log different from current one, you
may need to reenter info on journal redirection, restore range, etc.
Enter the name of the cluster journal log ( if no change)
=> cachejrn.txt
Cluster Journal Restore - Setup - Journal File Info
[I]dentify an existing cluster journal log to use for the restore
Current: _$1$DRA1:[TEST.50.MGR]CACHEJRN.TXT
[R]edirect journal files in _$1$DRA1:[TEST.50.MGR]CACHEJRN.TXT
- OR -
[C]reate a cluster journal log by specifying where journal files are
You must redirect journal files if the journal files being restored are not in their original locations, as specified in the cluster journal log. To redirect the journal files listed in the cluster journal log, provide the original and current locations when prompted. You may give a full or partial directory name as an original location. All original locations with leading characters that match the partial name are replaced with the new location. An example of redirecting files follows:
Selection ( if no change): R
Journal directories in _$1$DRA1:[TEST.50.MGR]CACHEJRN.TXT
_$1$DRA1:[TEST.50.MGR.JOURNAL]
_$1$DRA1:[TEST.5A.MGR.JOURNAL]
_$1$DRA1:[TEST.5B.MGR.JOURNAL]
Enter the original and current locations of journal files (? for help)
Journal files originally from: _$1$DRA1:
are currently located in: _$1$DRA2:
_$1$DRA1:[TEST.50.MGR.JOURNAL] -> _$1$DRA2:[TEST.50.MGR.JOURNAL]
_$1$DRA1:[TEST.5A.MGR.JOURNAL] -> _$1$DRA2:[TEST.5A.MGR.JOURNAL]
_$1$DRA1:[TEST.5B.MGR.JOURNAL] -> _$1$DRA2:[TEST.5B.MGR.JOURNAL]
Journal files originally from:
Cluster Journal Restore - Setup - Journal File Info
[I]dentify an existing cluster journal log to use for the restore
Current: _$1$DRA1:[TEST.50.MGR]CACHEJRN.TXT
[R]edirect journal files in _$1$DRA1:[TEST.50.MGR]CACHEJRN.TXT
- OR -
[C]reate a cluster journal log by specifying where journal files are
Selection ( if no change):
This example shows the choice of an alternative cluster journal log, CACHEJRN.TXT, which contains a list of journal files originally located on _$1$DRA1:. These files are redirected to be retrieved from their new location, _$1$DRA2:, during the restore.
When you have finished entering the redirection information, press Enter to return to the Main Settings menu.
Journal redirection assumes a one-to-one or many-to-one relationship between source and target directory locations. That is, journal files from one or multiple original directories may be located in one new location, but not in multiple new locations. To restore from journal files that are in multiple new locations, create a cluster journal log that specifies where to locate the journal files.
Create a Cluster Journal Log
If the journal files on the original cluster are not accessible to the current cluster, create a cluster journal log that specifies the locations of the journal files. The files in the specified locations must all be part of the cluster. Copy them to a location accessible to the current cluster and specify how to locate them by entering redirect information.
Selection ( if no change): C
*** WARNING ***
If you specify a cluster journal log different from current one, you
may need to reenter info on journal redirection, restore range, etc.
Enter the name of the cluster journal log to create (ENTER if none) =>
cachejrn.txt
How many cluster members were involved? (Q to quit) => 3
For each cluster member, enter the location(s) and name prefix (if any) of the
journal files to restore --
Cluster member #0 Journal File Name Prefix:
Directory: _$1$DRA1:[TEST.50.MGR.JOURNAL]
Directory:
Cluster member #1 Journal File Name Prefix:
Directory: _$1$DRA1:[TEST.5A.MGR.JOURNAL]
Directory:
Cluster member #2 Journal File Name Prefix:
Directory: _$1$DRA1:[TEST.5B.MGR.JOURNAL]
Directory:
This example shows the creation of a cluster journal log, CACHEJRN.TXT, for a cluster with three members whose journal files were originally located on _$1$DRA1:.
The next menu contains the additional option to redirect the journal files in the cluster journal log you created:
Cluster Journal Restore - Setup - Journal File Info
[I]dentify an existing cluster journal log to use for the restore
Current: _$1$DRA1:[TEST.50.MGR]CACHEJRN.TXT
[R]edirect journal files in _$1$DRA1:[TEST.50.MGR]CACHEJRN.TXT
- OR -
[C]reate a cluster journal log by specifying where journal files are
Selection ( if no change):
Enter R to redirect the files as described in Identify the Cluster Journal Log. When finished entering redirect information, press Enter to return to the Main Settings menu.
Change the Starting Point of the Restore
The second and third items on the Main Settings menu specify the range of restore—where in the journal files to begin restoring and where to stop. The starting point information contains the starting journal file and sequence number for each cluster member. The default for where to begin is determined in the following order:
-
If a cluster journal restore was performed after any backup restore, restore the journal from the end of last journal restore.
-
If a backup restore was performed on the current system, restore the journal from the end of the last restored backup.
-
If the current system is associated with the cluster journal log being used, restore the journal from the beginning of the current cluster session
-
Otherwise, restore the journal from the beginning of the cluster journal log.
Cluster Journal Restore - Setup - Main Settings
1. To LOCATE journal files using cluster journal log
_$1$DRA1:[TEST.50.MGR]CACHEJRN.TXT
with redirections of journal files
_$1$DRA1:[TEST.50.MGR.JOURNAL] -> _$1$DRA2:[TEST.50.MGR.JOURNAL]
_$1$DRA1:[TEST.5A.MGR.JOURNAL] -> _$1$DRA2:[TEST.5A.MGR.JOURNAL]
_$1$DRA1:[TEST.5B.MGR.JOURNAL] -> _$1$DRA2:[TEST.5B.MGR.JOURNAL]
2. To START restore at the end of last restored backup
_$1$DRA1:[TEST.50.MGR]CLUFULL.BCK
134120,_$1$DRA1:[TEST.50.MGR.JOURNAL]20031002.008
-> _$1$DRA1:[TEST.50.MGR.JOURNAL]20031002.008
3. To STOP restore at the end of the cluster journal log
4. To SWITCH journal file before journal restore
5. To DISABLE journaling the dejournaled transactions
Select an item to modify ('Q' to quit or ENTER to accept and continue): 2
Cluster Journal Restore - Setup - Where to Start Restore
1. At the beginning of a cluster session
2. At a specific journal marker
3. Following the restore of backup _$1$DRA1:[TEST.50.MGR]CLUFULL.BCK (*)
i.e., at the journal marker located at
134120,_$1$DRA1:[TEST.50.MGR.JOURNAL]20031002.008
Selection ( if no change): 1
To start journal restore at the beginning of cluster session ...
1. 20030904 09:47:01
2. 20031002 13:19:12
3. 20031002 13:26:40
4. 20031002 13:29:10
5. 20031002 13:51:31
6. 20031002 13:58:57
7. 20031002 14:29:42
8. 20031002 14:33:55
9. 20031002 14:35:48
=> 5
Cluster Journal Restore - Setup - Main Settings
1. To LOCATE journal files using cluster journal log
_$1$DRA1:[TEST.50.MGR]CACHEJRN.TXT
with redirections of journal files
_$1$DRA1:[TEST.50.MGR.JOURNAL] -> _$1$DRA2:[TEST.50.MGR.JOURNAL]
_$1$DRA1:[TEST.5A.MGR.JOURNAL] -> _$1$DRA2:[TEST.5A.MGR.JOURNAL]
_$1$DRA1:[TEST.5B.MGR.JOURNAL] -> _$1$DRA2:[TEST.5B.MGR.JOURNAL]
2. To START restore at the beginning of cluster session <20031002 13:51:31>
3. To STOP restore at the end of the cluster journal log
4. To SWITCH journal file before journal restore
5. To DISABLE journaling the dejournaled transactions
Select an item to modify ('Q' to quit or ENTER to accept and continue): 2
Cluster Journal Restore - Setup - Where to Start Restore
1. At the beginning of a cluster session (*): <20031002 13:51:31>
2. At a specific journal marker
3. Following the restore of backup _$1$DRA1:[TEST.50.MGR]CLUFULL.BCK
Selection ( if no change): 2
To start restore at a journal marker location (in original form)
journal file: _$1$DRA1:[TEST.50.MGR.JOURNAL]20031002.008
offset: 134120
You have chosen to start journal restore at
134120,_$1$DRA1:[TEST.50.MGR.JOURNAL]20031002.008
the journal location by the end of backup _$1$DRA1:[TEST.50.MGR]CLUFULL.BCK
The submenu varies slightly based on the current settings. For example, if no backup restore was performed, the submenu for specifying the beginning of the restore does not list option 3 to restore from the end of last backup. In a submenu, the option that is currently chosen is marked with an asterisk (*).
Change the Ending Point of the Restore
By default, the restore ends at either the current journal location, if the current system is associated with the selected cluster journal log, or the end of the journal log. The submenu for option 3 is similar to that for option 2:
Cluster Journal Restore - Setup - Main Settings
1. To LOCATE journal files using cluster journal log
_$1$DRA1:[TEST.50.MGR]CACHEJRN.TXT
with redirections of journal files
_$1$DRA1:[TEST.50.MGR.JOURNAL] -> _$1$DRA2:[TEST.50.MGR.JOURNAL]
_$1$DRA1:[TEST.5A.MGR.JOURNAL] -> _$1$DRA2:[TEST.5A.MGR.JOURNAL]
_$1$DRA1:[TEST.5B.MGR.JOURNAL] -> _$1$DRA2:[TEST.5B.MGR.JOURNAL]
2. To START restore at the end of last restored backup
_$1$DRA1:[TEST.50.MGR]CLUFULL.BCK
134120,_$1$DRA1:[TEST.50.MGR.JOURNAL]20031002.008
-> _$1$DRA1:[TEST.50.MGR.JOURNAL]20031002.008
3. To STOP restore at the end of the cluster journal log
4. To SWITCH journal file before journal restore
5. To DISABLE journaling the dejournaled transactions
Select an item to modify ('Q' to quit or ENTER to accept and continue): 3
Cluster Journal Restore - Setup - Where to Stop Restore
1. At the end of a cluster session
2. At the end of _$1$DRA1:[TEST.50.MGR]CACHEJRN.TXT
3. At a specific journal marker
This is the menu you would see if the journal log is the one for the current cluster:
Select an item to modify ('Q' to quit or ENTER to accept and continue): 3
Cluster Journal Restore - Setup - Where to Stop Restore
1. At the end of a cluster session
2. At current journal location (*)
3. At a specific journal marker
The submenu varies slightly based on the current settings. For example, depending whether or not the journal log is the one for current cluster, option 2 in the menu for specifying the end of the restore would be either the current journal location or the end of the journal log. In a submenu, the option that is currently chosen is marked with an asterisk (*).
Toggle the Switching Journal File Setting
The fourth menu item specifies whether to switch the journal file before the restore. If you select this item number, the value is toggled between the values To SWITCH and NOT to SWITCH the journal file; the menu is displayed again with the new setting:
Select an item to modify ('Q' to quit or ENTER to accept and continue): 4
Cluster Journal Restore - Setup - Main Settings
1. To LOCATE journal files using cluster journal log
_$1$DRA1:[TEST.50.MGR]CACHEJRN.TXT
with redirections of journal files
_$1$DRA1:[TEST.50.MGR.JOURNAL] -> _$1$DRA2:[TEST.50.MGR.JOURNAL]
_$1$DRA1:[TEST.5A.MGR.JOURNAL] -> _$1$DRA2:[TEST.5A.MGR.JOURNAL]
_$1$DRA1:[TEST.5B.MGR.JOURNAL] -> _$1$DRA2:[TEST.5B.MGR.JOURNAL]
2. To START restore at the end of last restored backup
_$1$DRA1:[TEST.50.MGR]CLUFULL.BCK
134120,_$1$DRA1:[TEST.50.MGR.JOURNAL]20031002.008
-> _$1$DRA1:[TEST.50.MGR.JOURNAL]20031002.008
3. To STOP restore at the end of the cluster journal log
4. NOT to SWITCH journal file before journal restore
5. To DISABLE journaling the dejournaled transactions
The default is to switch the journal file before the restore. This provides a clean start so that updates that occur after the restore are in new journal files.
Toggle the Disable Journaling Setting
The fifth menu item specifies whether to disable journaling of the dejournaled transactions during the restore. If you select this item, the value is toggled between the values DISABLE and NOT to DISABLE journaling the dejournaled transactions; the menu is redisplayed with the new setting.
Select an item to modify ('Q' to quit or ENTER to accept and continue): 5
Cluster Journal Restore - Setup - Main Settings
1. To LOCATE journal files using cluster journal log
_$1$DRA1:[TEST.50.MGR]CACHEJRN.TXT
with redirections of journal files
_$1$DRA1:[TEST.50.MGR.JOURNAL] -> _$1$DRA2:[TEST.50.MGR.JOURNAL]
_$1$DRA1:[TEST.5A.MGR.JOURNAL] -> _$1$DRA2:[TEST.5A.MGR.JOURNAL]
_$1$DRA1:[TEST.5B.MGR.JOURNAL] -> _$1$DRA2:[TEST.5B.MGR.JOURNAL]
2. To START restore at the end of last restored backup
_$1$DRA1:[TEST.50.MGR]CLUFULL.BCK
134120,_$1$DRA1:[TEST.50.MGR.JOURNAL]20031002.008
-> _$1$DRA1:[TEST.50.MGR.JOURNAL]20031002.008
3. To STOP restore at the end of the cluster journal log
4. NOT to SWITCH journal file before journal restore
5. NOT to DISABLE journaling the dejournaled transactions
For better performance, the default setting is to disable journaling the dejournaled transactions. However, if you are running a cluster shadow, you may want to choose not to disable journaling.
If you choose not to disable journaling, the dejournaled transactions are journaled only if they otherwise meet the normal criteria for being journaled.
Generate a Common Journal File
The user interface for this option is similar to the first with additional questions about the contents and format of the output file. However, instead of restoring the journal files, this option produces a common-format journal file that can be read by the ^%JREAD utility on a Caché system that does not support cluster journal restores or on another platform such as DSM.
^JCONVERT provides the same functionality if you answer Yes to the Cluster Journal Convert? question.
The second option produces a single common-format output file from the cluster journal files. It calls the ^JCONVERT utility, which takes a journal file from a single system and writes it out in a common format to be read by the %JREAD routine. This is useful for restoring journal files across versions of Caché where the journal files are not compatible (for example, as part of an “almost rolling” upgrade) or as part of failing back to an earlier release. You can also use this option to write the journal file in a format that can be loaded into another platform such as DSM.
Cluster Journal Restore Menu
--------------------------------------------------------------
1) Cluster journal restore
2) Generate common journal file from specific journal files
3) Cluster journal restore after backup restore
4) Cluster journal restore corresponding to Caché backups
--------------------------------------------------------------
H) Display Help
E) Exit this utility
--------------------------------------------------------------
Enter choice (1-4) or [E]xit/[H]elp? 2
Perform a Cluster Journal Restore after a Backup Restore
Option three restores the journal files after a Caché backup has been restored. This is similar to the restore performed by the incremental backup restore routine, ^DBREST, after a cluster backup restore when there is no way to run it independently of restoring a backup. (To restart the journal restore, for example.) One difference between this option and restoring using ^DBREST is that this option does not start with the list of databases contained in the backup; you must enter the database list.
The routine offers to include all currently cluster-mounted databases in the restore, but if it is being run after restoring a backup, the databases restored by the backup are then privately mounted unless you change the mount state. (The restore mounts them privately and leaves them privately mounted when it is finished.) It starts with the markers recorded in the journal files by the backup and ends with the end of the journal data.
Perform a Cluster Journal Restore Based on Caché Backups
The fourth menu option restores the journal files using journal markers that were added by a Caché backup to specify the starting point and, optionally, the end point. It is similar to option three except that it uses backups which have been performed to designate where to start rather than backups which have been restored. Functionally they are the same; both options use a marker which has been placed into the journal file by a Caché backup as the starting point. The difference is in the list of choices of where to start.
Journal Dump Utility
On a Caché clustered system, the ^JRNDUMP routine displays the cluster session ID (cluster startup time) of a journal file instead of the word JRNSTART. The ^JRNDUMP routine displays a list of records in a journal file, showing the cluster session ID along with the journal file sizes.
The utility lists journal files maintained by the local system as well as journal files maintained by other systems of the Caché cluster, in the order of cluster startup time (cluster session ID) and the first and last cluster journal sequence numbers of the journal files. Journal files created by ^JRNSTART are marked with an asterisk (*). Journal files that are no longer available (purged, for example) are marked with D (for deleted). Journal file names are displayed with indentions that correspond to their CSN, that is: no indention for journal files from system 0, one space for system 1, two spaces for system 2, etc.
Sample output from the cluster version of ^JRNDUMP follows. By default, The level-1 display on a clustered system is quite different from the nonclustered one:
FirstSeq LastSeq Journal Files
Session 20030820 11:02:43
0 0 D /bench/test/cache/50a/mgr/journal/20030820.003
0 0 /bench/test/cache/50b/mgr/journal/20030820.004
Session 20030822 10:55:46
3 3 /bench/test/cache/50b/mgr/journal/20030822.001
(N)ext,(P)rev,(G)oto,(E)xamine,(Q)uit =>
Besides a list of journal files from every cluster node, (even the dead ones), there are cluster session IDs and the first and the last cluster journal sequence numbers of each journal file. A cluster session ID (the date-time string following Session) is the time the first node of the cluster starts. A cluster session ends when the last node of the cluster shuts down. Files from different nodes are shown with different indention: no indentation for the node with CSN 0, one space for the node with CSN 1, and so on. The CSN of a node uniquely identifies the node within the cluster at a given time. The files labeled D have most likely been deleted from their host systems.
The previous version of ^JRNDUMP for clusters is available as OLD^JRNDUMP, if you prefer that output.
Startup Recovery Routine
The following is the help display of the startup recovery routine, ^STURECOV:
%SYS>Do ^STURECOV
Enter error type (? for list) [^] => ?
Supported error types are:
JRN - Journal restore and transaction rollback
CLUJRN - Cluster journal restore and transaction rollback
Enter error type (? for list) [^] => CLUJRN
Cluster journal recovery options
--------------------------------------------------------------
1) Display the list of errors from startup
2) Run the journal restore again
4) Dismount a database
5) Mount a database
6) Database Repair Utility
7) Check Database Integrity
--------------------------------------------------------------
H) Display Help
E) Exit this utility
--------------------------------------------------------------
Enter choice (1-8) or [E]xit/[H]elp? H
--------------------------------------------------------------
Before running ^STURECOV you should have corrected the
errors that prevented the journal restore or transaction rollback
from completing. Here you have several options regarding what
to do next.
Option 1: The journal restore and transaction rollback procedure
tries to save the list of errors in ^%SYS(). This is not always
possible depending on what is wrong with the system. If this
information is available, this option displays the errors.
Option 2: This option performs the same journal restore and
transaction rollback which was performed when the system was
started. The amount of data is small so it should not be
necessary to try and restart from where the error occurred.
Option 3 is not enabled for cluster recovery
Option 4: This lets you dismount a database. Generally this
would be used if you want to let users back on a system but
you want to prevent them from accessing a database which still
has problems (^DISMOUNT utility).
Option 5: This lets you mount a database (^MOUNT utility).
Option 6: This lets you edit the database structure (^REPAIR utility).
Option 7: This lets you validate the database structure (^INTEGRIT utility).
Option 8 is not enabled for cluster recovery. Shut the system
down using the bypass option with ccontrol stop and then start it
with ccontrol start. During startup answer YES when asked if you
want to continue after it displays the message related to errors
during recovery.
Press <enter> continue
Cluster journal recovery options
--------------------------------------------------------------
1) Display the list of errors from startup
2) Run the journal restore again
4) Dismount a database
5) Mount a database
6) Database Repair Utility
7) Check Database Integrity
--------------------------------------------------------------
H) Display Help
E) Exit this utility
--------------------------------------------------------------
Enter choice (1-8) or [E]xit/[H]elp?
Setting Journal Markers on a Clustered System
To set a journal marker effective cluster-wide, use the following routine
$$CLUSET^JRNMARK(id,text,swset)
| Where.... | is... |
|---|---|
| id | Marker ID (for example, -1 for backup) |
| text | Marker text (for example, “timestamp” for backup) |
| swset | 1 — if the switch that inhibits database reads and writes (switch 10) has been set cluster-wide (and locally) by the caller. The caller is responsible for clearing it afterwards. |
| 0 — if the switch has not been set. The routine takes care of setting and clearing the switch properly |
Note that switch 10 must be set locally and cluster-wide to ensure the integrity of the journal marker. If successful, the routine returns the location of the marker — the offset of the marker in the journal file and the journal file name — delimited by a comma. Otherwise, it returns an error code (<=0) and error message, also delimited by a comma.
Cluster Journal Information Global
The global node ^%SYS("JRNINFO") is where cluster journal information is maintained. It is indexed by current cluster session ID and is recreated every time the cluster restarts. This allows you to modify or delete the cluster journal log (presumably after deleting the journal files) between two cluster sessions, as the update algorithm assumes that you do not alter the cluster journal log during a cluster session.
The ^%SYS("JRNINFO") global has three subcomponents:
-
The jrninfo table is indexed by journal file names, with the value of the top node being the number of entries in the cluster journal log and the value of each subnode being a comma-delimited list of the attributes of that journal file: CSN, line number of the journal file in the cluster journal log, CSI, first and last sequence numbers.
-
The jrninfor (r for reverse) table is a list of journal files, with CSN as the primary key and the line number of the journal file in the cluster journal log as the secondary key.
-
The seqinfo table contains the following subscripts: CSI, first and last sequence numbers, CSN, and line number of the journal file in the cluster journal log.
Here is a sample of ^%SYS("JRNINFO") contents:
^%SYS("JRNINFO",1032803946,"jrninfo")=16
^%SYS("JRNINFO",1032803946,"jrninfo",
"_$1$DKA0:[TEST.50.MGR.JOURNAL]20030916.002")=1,2,1031949277,160,160
"_$1$DRA1:[TEST.50.MGR.JOURNAL]20030913.004")=0,1,1031949277,3,3
"_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.001")=0,3,1031949277,292,292
"_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.002")=0,4,1032188507,3,417
"_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.003")=0,7,1032188507,3,422
"_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.004")=0,8,1032197355,3,4
"_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.005")=0,9,1032197355,3,7
"_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.006")=0,10,1032197355,3,10
"_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.007")=0,11,1032197355,3,17
"_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.008")=0,12,1032197355,3,17
"_$1$DRA1:[TEST.50.MGR.JOURNAL]20030918.001")=0,13,1032197355,3,27
"_$1$DRA1:[TEST.50.MGR.JOURNAL]20030923.001")=0,15,1032803946,3,133
"_$1$DRA1:[TEST.5A.MGR.JOURNAL]20030916.002")=1,5,1032188507,3,3
"_$1$DRA1:[TEST.5A.MGR.JOURNAL]20030916.003")=1,6,1032188507,131,131
"_$1$DRA1:[TEST.5A.MGR.JOURNAL]20030923.001")=1,14,1032197355,39,39
"_$1$DRA1:[TEST.5A.MGR.JOURNAL]20030923.002")=1,16,1032803946,3,3
^%SYS("JRNINFO",1032803946,"jrninfor",0,
1)=_$1$DRA1:[TEST.50.MGR.JOURNAL]20030913.004
3)=_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.001
4)=_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.002
7)=_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.003
8)=_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.004
9)=_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.005
10)=_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.006
11)=_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.007
12)=_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.008
13)=_$1$DRA1:[TEST.50.MGR.JOURNAL]20030918.001
15)=_$1$DRA1:[TEST.50.MGR.JOURNAL]20030923.001
^%SYS("JRNINFO",1032803946,"jrninfor",1,
2)=_$1$DKA0:[TEST.50.MGR.JOURNAL]20030916.002
5)=_$1$DRA1:[TEST.5A.MGR.JOURNAL]20030916.002
6)=_$1$DRA1:[TEST.5A.MGR.JOURNAL]20030916.003
14)=_$1$DRA1:[TEST.5A.MGR.JOURNAL]20030923.001
16)=_$1$DRA1:[TEST.5A.MGR.JOURNAL]20030923.002
^%SYS("JRNINFO",1032803946,"seqinfo",1031949277,3,3,0,1)=
^%SYS("JRNINFO",1032803946,"seqinfo",1031949277,160,160,1,2)=
^%SYS("JRNINFO",1032803946,"seqinfo",1031949277,292,292,0,3)=
^%SYS("JRNINFO",1032803946,"seqinfo",1032188507,3,3,1,5)=
^%SYS("JRNINFO",1032803946,"seqinfo",1032188507,3,417,0,4)=
^%SYS("JRNINFO",1032803946,"seqinfo",1032188507,3,422,0,7)=
^%SYS("JRNINFO",1032803946,"seqinfo",1032188507,131,131,1,6)=
^%SYS("JRNINFO",1032803946,"seqinfo",1032197355,3,4,0,8)=
^%SYS("JRNINFO",1032803946,"seqinfo",1032197355,3,7,0,9)=
^%SYS("JRNINFO",1032803946,"seqinfo",1032197355,3,10,0,10)=
^%SYS("JRNINFO",1032803946,"seqinfo",1032197355,3,17,0,11)=
12)=
^%SYS("JRNINFO",1032803946,"seqinfo",1032197355,3,27,0,13)=
^%SYS("JRNINFO",1032803946,"seqinfo",1032197355,39,39,1,14)=
^%SYS("JRNINFO",1032803946,"seqinfo",1032803946,3,3,1,16)=
^%SYS("JRNINFO",1032803946,"seqinfo",1032803946,3,133,0,15)=
Shadow Information Global and Utilities
The global node ^SYS("shdwcli”) is where shadow client information is maintained. Most of the values are available through the utilities ShowState^SHDWX, ShowError^SHDWX, and ShowWhere^SHDWX.
Running ShowState^SHDWX displays most of the data contained in the global:
%SYS>d ShowState^SHDWX("clutest",1)
Shadow ID PrimaryServerIP Port R S Err
------------------------------------------------------------------------
clutest rodan 42009 0 1 1
\_ clutest~0 192.9.202.5 42009 0 1
\_ clutest~1 192.9.202.5 42009 0 1
\_ clutest~2 rodan 42009 0 1
Redirection of Global Sets and Kills:
^^_$1$DKB300:[TEST.CLU.5X] -> ^^_$1$DKA0:[TEST.CLU.5X]
Redirection of Master Journal Files:
Base directory for auto-redirection: _$1$DKA0:[TEST.5X.SHADOW]
_$1$DRA2:[TEST.5X.JOURNAL] -> _$1$DKA0:[TEST.5X.SHADOW.1]
_$1$DRA2:[TEST.5Y.JOURNAL] -> _$1$DKA0:[TEST.5X.SHADOW.2]
_$1$DRA2:[TEST.5Z.JOURNAL] -> _$1$DKA0:[TEST.5X.SHADOW.3]
Primary Server Cluster ID: _$1$DKB400:[TEST.5X]CACHE.PIJ
Primary Server Candidates (for failover):
192.9.202.5 42009
rodan 42009
192.9.202.5 42019
192.9.202.5 42029
When to purge a shadow journal file: after it's dejournaled
The output displayed from the ^SYS("shdwcli”) global has the following components:
-
Shadow ID — the ID of a copier shadow is partially inherited from the parent shadow. The clu subnode of a copier contains the ID of the parent, and the sys subnode of the parent contains a list of the IDs of the copiers.
-
PrimaryServerIP and Port — for a copier, these specify the system from which it gets journal files; for the dejournaler, the system from which it gets journal information (JRNINFO server). The values are stored in the ip and port0 subnodes.
-
R — has the value 1 if the shadow is running; from the stat subnode.
-
S — has the value 1 if the shadow is requested to stop (due to latency, it is possible that both R and S have the value 1 if the shadow has yet to check for the stop request); from the stop subnode.
-
Err — number of errors encountered. See details through ShowError^SHDWX, which displays the information from the err subnode.
-
Redirection of Global Sets and Kills — referred to as database mapping in the Management Portal; from the dbmap subnode of the cluster shadow.
-
Redirection of Master Journal Files — discussed in the Using Caché Routines section; stored in the jrndir subnode of the cluster shadow. The value of the jrndir subnode is the number of journal directories that have been automatically redirected (in the preceding example output, the next new journal directory is redirected to a subdirectory [.4]). (jrndir,0) is the base shadow directory and everything else indicates a redirection of journal directories with the server journal directory being the key and the shadow journal directory being the value.
-
Primary Server Cluster ID — used to prevent the shadow from following a node to a different cluster; from the DBServerClusterID subnode.
-
Primary Server Candidates (for failover) — the list of current live members of the cluster. If one member dies, a shadow (either the dejournaler or a copier) that gets information from the member tries other members on the list until it succeeds. A new member is added to the list as soon as the shadow knows its presence; from the servers subnode.
-
When to purge a shadow journal file — works in the same way as purging of local journal files. The age threshold is set by the lifespan subnode of the cluster shadow. Unlike purging of local journal files, however, if the value of lifespan is 0, the shadow journal files are purged as soon as they have been dejournaled completely. The purged journal files are listed in the jrndel subnode of the copiers.
The chkpnt subnode stores a list of checkpoints. A checkpoint is a snapshot of the work queue of the dejournaler—the current progress of dejournaling. The value of the chkpnt subnode indicates which checkpoint to use when the dejournaler resumes. This is the checkpoint displayed by ShowWhere^SHDWX. Updating the value of the chkpnt subnode after having completely updated the corresponding checkpoint, avoids having a partial checkpoint in the case of system failover in the middle of an update (in that case, dejournaler would use previous checkpoint).
The copiers keep the names of the copied (or being copied) journal files in the jrnfil subnode. This makes it possible to change the redirection of journal files by allowing the dejournaler to find the shadow journal files in the old directory while the copiers copy new journal files to the new location. Once a shadow journal file is purged, it is moved from the jrnfil list to the jrndel list.
Here is a sample of the ^SYS("shdwcli") contents for the nodes for the cluster shadow, clutest, and two of its copier shadows:
^SYS("shdwcli","clutest")=0
^SYS("shdwcli","clutest","DBServerClusterID")=_$1$DKB400:[TEST.5X]CACHE.PIJ
"at")=0
"chkpnt")=212
^SYS("shdwcli","clutest","chkpnt",1)=1,1012488866,-128
^SYS("shdwcli","clutest","chkpnt",1,1012488866,0,1)=0,,,,
^SYS("shdwcli","clutest","chkpnt",2)=2,1012488866,-128
^SYS("shdwcli","clutest","chkpnt",2,1012488866,-128,2)=
-128,_$1$DKA0:[TEST.5X.SHADOW.1]20020131.001,0,,0
^SYS("shdwcli","clutest","chkpnt",3)=6,1012488866,5
^SYS("shdwcli","clutest","chkpnt",3,1012488866,11,6)=
5,_$1$DKA0:[TEST.5X.SHADOW.1]20020131.001,-132252,,0
^SYS("shdwcli","clutest","chkpnt",4)=35,1012488866,85
^SYS("shdwcli","clutest","chkpnt",4,1012488866,95,35)=
85,_$1$DKA0:[TEST.5X.SHADOW.1]20020131.001,-136984,,0
^SYS("shdwcli","clutest","chkpnt",5)=594,1012488866,807
^SYS("shdwcli","clutest","chkpnt",5,1012488866,808,594)=
808,_$1$DKA0:[TEST.5X.SHADOW.1]20020131.001,262480,1,0
...
^SYS("shdwcli","clutest","chkpnt",212)=24559,1021493730,5
^SYS("shdwcli","clutest","chkpnt",212,1021493730,37,24559)=
5,_$1$DKA0:[TEST.5X.SHADOW.1]20020515.001,-132260,,0
^SYS("shdwcli","clutest","cmd")=
^SYS("shdwcli","clutest","dbmap","^^_$1$DKB300:[TEST.CLU.5X]")=
^^_$1$DKA0:[TEST.CLU.5X]
^SYS("shdwcli","clutest","end")=0
"err")=1
^SYS("shdwcli","clutest","err",1)=
20020519 14:16:34 568328925 Query+8^SHDWX;-12;
reading ans from |TCP|42009timed out,Remote server is not responding
^SYS("shdwcli","clutest","err",1,"begin")=20020519 14:09:09
"count")=5
^SYS("shdwcli","clutest","errmax")=10
"intv")=10
"ip")=rodan
"jrndir")=3
^SYS("shdwcli","clutest","jrndir",0)=_$1$DKA0:[TEST.5X.SHADOW]
"_$1$DRA2:[TEST.5X.JOURNAL]")=_$1$DKA0:[TEST.5X.SHADOW.1]
"_$1$DRA2:[TEST.5Y.JOURNAL]")=_$1$DKA0:[TEST.5X.SHADOW.2]
"_$1$DRA2:[TEST.5Z.JOURNAL]")=_$1$DKA0:[TEST.5X.SHADOW.3]
^SYS("shdwcli","clutest","jrntran")=0
"lifespan")=0
"locdir")=
"locshd")=
"pid")=568328919
"port")=
"port0")=42009
"remjrn")=
^SYS("shdwcli","clutest","servers","42009,192.9.202.5")=
"42009,rodan")=
"42019,192.9.202.5")=
"42029,192.9.202.5")=
^SYS("shdwcli","clutest","stat")=0
"stop")=1
^SYS("shdwcli","clutest","sys",0)=
1)=
2)=
^SYS("shdwcli","clutest","tcp")=|TCP|42009
"tpskip")=1
"type")=21
^SYS("shdwcli","clutest~0")=0
^SYS("shdwcli","clutest~0","at")=0
"clu")=clutest
"cmd")=
"end")=132260
"err")=0
"intv")=10
"ip")=192.9.202.5
^SYS("shdwcli","clutest~0","jrndel",
"_$1$DKA0:[TEST.5X.SHADOW.1]20020131.001")=
"_$1$DKA0:[TEST.5X.SHADOW.1]20020131.002")=
"_$1$DKA0:[TEST.5X.SHADOW.2]20020510.010")=
^SYS("shdwcli","clutest~0","jrnfil")=36
^SYS("shdwcli","clutest~0","jrnfil",35)=
_$1$DRA2:[TEST.5X.JOURNAL]20020513.006
^SYS("shdwcli","clutest~0","jrnfil",35,"shdw")=
_$1$DKA0:[TEST.5X.SHADOW.1]20020513.006
^SYS("shdwcli","clutest~0","jrnfil",36)=
_$1$DRA2:[TEST.5X.JOURNAL]20020515.001
^SYS("shdwcli","clutest~0","jrnfil",36,"shdw")=
_$1$DKA0:[TEST.5X.SHADOW.1]20020515.001
^SYS("shdwcli","clutest~0","jrntran")=0
"locdir")=
"locshd")=
_$1$DKA0:[TEST.5X.SHADOW.1]20020515.001
"pause")=0
"pid")=568328925
"port")=42009
"port0")=42009
"remend")=132260
"remjrn")=
"stat")=0
"stop")=1
"tcp")=|TCP|42009
"tpskip")=1
"type")=12
^SYS("shdwcli","clutest~1")=0
^SYS("shdwcli","clutest~1","at")=0
"clu")=clutest
"cmd")=
"end")=132248
"err")=0
"intv")=10
"ip")=192.9.202.5
^SYS("shdwcli","clutest~1","jrndel",
"_$1$DKA0:[TEST.5X.SHADOW.1]20020510.003")=
"_$1$DKA0:[TEST.5X.SHADOW.2]20020131.001")=
"_$1$DKA0:[TEST.5X.SHADOW.2]20020510.008")=
^SYS("shdwcli","clutest~1","jrnfil")=18
^SYS("shdwcli","clutest~1","jrnfil",17)=
_$1$DRA2:[TEST.5X.JOURNAL]20020510.011
^SYS("shdwcli","clutest~1","jrnfil",17,"shdw")=
_$1$DKA0:[TEST.5X.SHADOW.1]20020510.011
^SYS("shdwcli","clutest~1","jrnfil",18)=
_$1$DRA2:[TEST.5Y.JOURNAL]20020510.011
^SYS("shdwcli","clutest~1","jrnfil",18,"shdw")=
_$1$DKA0:[TEST.5X.SHADOW.2]20020510.011
^SYS("shdwcli","clutest~1","jrntran")=0
"locdir")=
"locshd")=
_$1$DKA0:[TEST.5X.SHADOW.2]20020510.011
"pid")=568328925
"port")=42009
"port0")=42009
"remend")=132248
"remjrn")=
"stat")=0
"stop")=1
"tcp")=|TCP|42009
"tpskip")=1
"type")=12