サブジェクト領域の作成
サブジェクト領域は、オプションによる項目名のオーバーライドを持つサブキューブです。サブジェクト領域を定義すると、セキュリティ上の理由およびその他の理由により、より小さなデータ・セットに焦点を当てることができます。以下の項目について説明します。
はじめに
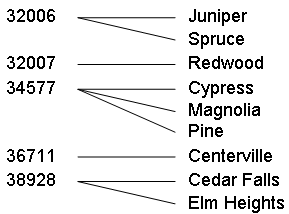
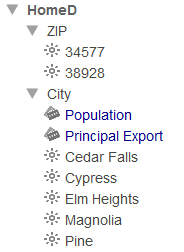
このチュートリアルでは、患者のデータを郵便番号によって分割する 2 つのサブジェクト領域を作成します。Patients サンプルの郵便番号には、以下のように小さい市区町村が含まれています。
以下のサブジェクト領域を作成します。
| サブジェクト領域名 | コンテンツ |
|---|---|
| Patient Set A | 郵便番号 32006、32007、または 36711 に居住する患者 |
| Patient Set B | 郵便番号 34577、または 38928 に居住する患者 |
サブジェクト領域の作成
サブジェクト領域を作成する手順は以下のとおりです。
-
アーキテクトで、[新規作成] をクリックします。
-
[サブジェクト領域] をクリックします。
-
[サブジェクト領域名] に Patient Set A と入力します。
-
[サブジェクト領域のクラス名] に Tutorial.SubjectA と入力します。
-
[ベース・キューブ] で、[参照] をクリックして [Tutorial] を選択します。
-
[OK] をクリックします。
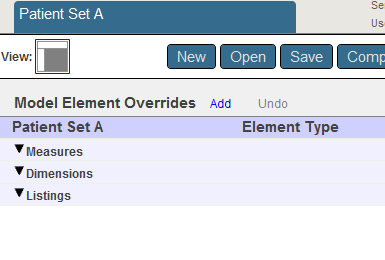
サブジェクト領域が作成され、クラスが保存されます。
以下のように表示されます。
アーキテクトには、フィルタを定義するユーザ・インタフェースがありません。適切なフィルタ式を入力するか、アナライザからコピーして貼り付ける必要があります。
-
別のブラウザ・タブまたはウィンドウで、アナライザにアクセスして、以下を実行します。
-
[HomeD] を展開します。
-
[ZIP Code] を [フィルタ] ボックスにドロップします。これによって、フィルタ・ボックスがピボット・テーブルのすぐ上に追加されます。
-
そのフィルタ・ボックスで、検索ボタンをクリックし、[32006]、[32007]、および [36711] を選択します。
チェック・マークをクリックします。
この操作により、ピボット・テーブルがフィルタ処理されます。
Important:[32006]、[32007]、および [36711] を個別に [フィルタ] ボックスにドラッグ・アンド・ドロップしないでください。代わりに、ここでの説明に従ってレベルをドラッグし、メンバを選択します。
-
クエリ文字列ボタン
 をクリックします。
をクリックします。これで、アナライザで使用している MDX クエリを示すダイアログ・ボックスが表示されます。
SELECT FROM [Patients] %FILTER %OR({[HOMED].[H1].[ZIP Code].&[32006],[HOMED].[H1].[ZIP Code].&[32007],[HOMED].[H1].[ZIP Code].&[36711]}) -
%FILTER 以降のテキストをシステムのクリップボードにコピーします。
-
[OK] をクリックします。
-
-
アーキテクトで、Patient Set A のラベルが付けられた行をクリックします。
-
[詳細] ペインで、コピーしたテキストを [フィルタ] に貼り付けます。
%OR({[HOMED].[H1].[ZIP Code].&[32006],[HOMED].[H1].[ZIP Code].&[32007],[HOMED].[H1].[ZIP Code].&[36711]}) -
[保存] をクリックして、[OK] をクリックします。
-
サブジェクト領域をコンパイルします。
-
2 番目のサブジェクト領域についても、前述の手順を繰り返しますが、以下の変更点があります。
-
[サブジェクト領域名] に Patient Set B と入力します。
-
[サブジェクト領域のクラス名] に Tutorial.SubjectB と入力します。
-
他の 2 つの郵便番号についても前述の手順を繰り返します。そのため、[フィルタ] には以下を使用します。
%OR({[HOMED].[H1].[ZIP Code].&[34577],[HOMED].[H1].[ZIP Code].&[38928]})
-
サブジェクト領域の検証
次に、作成したサブジェクト領域を検証します。実際に表示される数は、ここでの表示と異なる場合もあります。
-
アナライザの変更ボタン
 をクリックします。
をクリックします。 -
[Patient Set A] をクリックします。
-
[OK] をクリックします。
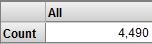
選択したサブジェクト領域の内容がアナライザに表示されます。
合計レコード数が、ベース・キューブほど多くないことに注意してください。
-
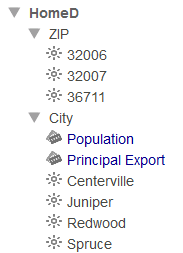
[モデル・コンテンツ] 領域で、[HomeD] ディメンジョン、[ZIP Code] レベル、および [City] レベルを展開します。以下のように表示されます。
-
Patient Set B についても前述の手順を繰り返します。
[HomeD] ディメンジョン、[ZIP Code] レベル、および [City] レベルを展開します。以下のように表示されます。
一般的なフィルタ式
ここでは、アナライザで一般的なフィルタを試して、生成されたクエリに対する影響を確認します。
-
アナライザで [Tutorial] キューブを開きます。
アナライザでは、キューブとサブジェクト領域の両方をサブジェクト領域と呼びます。これらの形式的な区別は、作成時にのみ関係します。
-
[新規作成] をクリックします。
アナライザにカウント (レコード数) が表示されます。
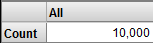
フィルタを追加する前に、クエリが現在どのように定義されているかを確認し、比較の基盤とします。
-
クエリ文字列ボタン
をクリックします。これで、アナライザで使用している MDX クエリを示すダイアログ・ボックスが表示されます。
SELECT FROM [TUTORIAL] -
[OK] をクリックします。
-
[ColorD] および [Favorite Color] を展開します。
-
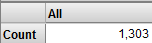
[Orange] を [フィルタ] にドラッグ・アンド・ドロップします。
これでアナライザは、好きな色がオレンジの患者のみを使用します。これは、以下のようになります。
-
クエリ文字列ボタン
をクリックします。これで、以下のクエリが表示されます。
SELECT FROM [TUTORIAL] %FILTER [COLORD].[H1].[FAVORITE COLOR].&[ORANGE]%FILTER キーワードはクエリを制限します。%FILTER より後の部分はフィルタ式です。
[COLORD].[H1].[FAVORITE COLOR].&[ORANGE]このフィルタ式は、メンバ (Favorite Color レベルの Orange メンバ) を参照するため、メンバ式です。メンバはレコード・セットであり、メンバ式はそのレコード・セットを参照します。
この式はディメンジョン、階層およびレベルの名前を使用します。&[ORANGE] フラグメントは、Orange メンバのキーを参照します。アナライザは名前ではなくキーを使用しますが、メンバ名が一意であれば、どちらを使用してもかまいません。
-
[OK] をクリックします。
-
フィルタに別の色を追加します。そのためには、以下の操作を実行します。
-
[フィルタ] で [Orange] の横にある [X] をクリックします。
これによって、そのフィルタが削除されます。
-
[Favorite Color] を [フィルタ] にドラッグ・アンド・ドロップします。これによって、フィルタ・ボックスがピボット・テーブルのすぐ上に追加されます。
-
そのフィルタ・ボックスで、検索ボタンをクリックし、[Orange] と [Purple] を選択します。
-
チェック・マークをクリックします。
この操作により、ピボット・テーブルがフィルタ処理されます。
Important:[Orange] および [Purple] を個別に [フィルタ] ボックスにドラッグ・アンド・ドロップしないでください。代わりに、ここでの説明に従ってレベルをドラッグし、メンバを選択します。
アナライザの表示は以下のようになります。
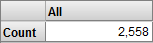
システムは、好きな色がオレンジまたは紫の患者のみを使用するようになりました (オレンジのみの場合よりカウントが増えていることに注意してください)。
-
-
クエリ・テキストを再度表示します。以下のように表示されます。
SELECT FROM [TUTORIAL] %FILTER %OR({[COLORD].[H1].[FAVORITE COLOR].&[ORANGE],[COLORD].[H1].[FAVORITE COLOR].&[PURPLE]})この場合、フィルタ式は以下のようになります。
%OR({[COLORD].[H1].[FAVORITE COLOR].&[ORANGE],[COLORD].[H1].[FAVORITE COLOR].&[PURPLE]})%OR 関数はインターシステムズの最適化関数です。この関数の引数はセットです。
セットは中括弧 {} で囲まれ、要素のコンマ区切りリストから構成されます。この場合、セットには 2 つのメンバ式が含まれています。セット式は、セットの要素で示されたすべてのレコードを参照します。この場合、セットは、好きな色がオレンジであるすべての患者と、好きな色が紫であるすべての患者を参照します。
-
[OK] をクリックします。
-
フィルタのドロップダウン・リストを使用して、[Purple] の横にあるチェック・ボックスのチェックを外します。
これでアナライザは、好きな色がオレンジの患者のみを使用します。
-
[AllerD] および [Allergies] を展開します。
-
[mold] を [フィルタ] の [Orange] の下にドラッグ・アンド・ドロップします。
アナライザの表示は以下のようになります。
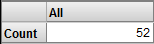
Orange のみを使用した場合よりカウントが少ないことに注意してください。このピボット・テーブルには、好きな色がオレンジで、カビに対するアレルギーがある患者のみが表示されます。
-
クエリ・テキストを再度表示します。以下のように表示されます。
SELECT FROM [TUTORIAL] %FILTER NONEMPTYCROSSJOIN([ALLERD].[H1].[ALLERGIES].&[MOLD],[COLORD].[H1].[FAVORITE COLOR].&[ORANGE])この場合、フィルタ式は以下のようになります。
NONEMPTYCROSSJOIN([ALLERD].[H1].[ALLERGIES].&[MOLD],[COLORD].[H1].[FAVORITE COLOR].&[ORANGE])MDX 関数 NONEMPTYCROSSJOIN は、2 つのメンバを結合して、生成されたタプルを返します。このタプルは、指定されたメンバの両方に属するレコードにのみアクセスします。
これで、最も一般的な以下の 3 つのフィルタ式を確認しました。
メンバ式をフィルタとして使用すると、システムはそのメンバに属するレコードにのみアクセスします。
メンバ式は以下のように作成できます。
[dimension name].[hierarchy name].[level name].&[member key]
または以下のようにします。
[dimension name].[hierarchy name].[level name].[member name]
以下はその説明です。
-
dimension name は、ディメンジョン名です。
-
hierarchy name は階層名です。階層名は省略できます。省略すると、クエリでは、このディメンジョン内の定義に従って、指定された名前の最初のレベルが使用されます。
-
level name は、その階層内のレベル名です。レベル名は省略できます。省略すると、クエリでは、このディメンジョン内の定義に従って、指定された名前の最初のメンバが使用されます。
-
member key は、指定されたレベル内のメンバのキーです。多くの場合、これはメンバ名と同じです。
-
member name は、指定されたレベル内のメンバの名前です。
メンバ・セットをフィルタとして使用すると、システムは指定のメンバのいずれかに属するレコードにアクセスします。つまり、メンバは論理 OR で結合されています。
メンバを参照するセット式は、以下のように作成できます。
{member_expression,member_expression,member_expression...}
member_expression はメンバ式です。
タプルをフィルタとして使用すると、システムは指定のメンバのすべてに属するレコードにアクセスします。つまり、メンバは論理 AND で結合されています。
タプル式は以下のように作成できます。
NONEMPTYCROSSJOIN(member_expression,member_expression)
または以下のようにします。
(member_expression,member_expression)
その他のバリエーションについては、"DeepSee での MDX の使用法" および "DeepSee MDX リファレンス" を参照してください。