Syntax Rules
This chapter describes the basic rules of ObjectScript syntax. Topics include:
Case Sensitivity
Some parts of ObjectScript are case-sensitive while others are not. Generally speaking, the user-definable parts of ObjectScript are case-sensitive while keywords are not:
-
Case-sensitive: variable names (local, global, and process-private global) and variable subscripts, class names, method names, property names, the i% preface for an instance variable for a property, routine names, macro names, macro include file (.inc file) names, label names, lock names, passwords, embedded code directive marker strings, Embedded SQL host variable names.
-
Not case-sensitive: command names, function names, special variable names, namespace names (see below), user names and role names, preprocessor directives (such as #include), letter codes (for LOCK, OPEN, or USE), keyword codes (for $STACK), pattern match codes, and embedded code directives (&html, &js, &sql). Custom language elements that you add by customizing the %ZLANG routine are not case-sensitive; when you create them you must use uppercase, when you refer to them you can use any case. Because iKnow indexing normalizes text by converting it to lowercase, most iKnow values, including domain names, are not case-sensitive.
-
Usually not case-sensitive: Case sensitivity of the following is platform-dependent: device names, file names, directory names, disk drive names. The exponent symbol is usually not case-sensitive. Uppercase “E” is always a valid exponent symbol; lowercase “e” can be configured as valid or invalid for the current process using the ScientificNotation()Opens in a new tab method of the %SYSTEM.ProcessOpens in a new tab, or system-wide using the ScientificNotationOpens in a new tab property of the Config.MiscellaneousOpens in a new tab class.
Identifiers
User-defined identifiers (variable, routine, and label names) are case-sensitive. String, string, and STRING all refer to different variables. Global variable names are also case-sensitive, whether user-defined or system-supplied.
Keyword Names
Command, function, and system variable keywords (and their abbreviations) are not case-sensitive. You can use Write, write, WRITE, W, or w; all refer to the same command.
Class Names
All identifiers related to classes (class names, property names, method names, etc.) are case-sensitive. For purposes of uniqueness, however, such names are considered to be not case-sensitive; that is, two class names cannot differ by case alone.
Namespace Names
Namespace names are not case-sensitive, meaning that you can input a namespace name in any combination of uppercase and lowercase letters. Note however, that Caché always stores namespace names in uppercase. Therefore, Caché may return a namespace name to you in uppercase rather than in the case which you specified. For further details on namespace naming conventions, see Namespaces.
Unicode
The Unicode characters supported by Caché are 16-bit characters, also known as wide characters. Your instance of Caché supports the Unicode international character set if you selected the Unicode option during Caché installation. If you selected the 8-bit option during Caché installation, characters beyond $CHAR(255) are not supported; the $CHAR function returns the empty string for integers larger than 255. The $ZVERSION special variable and the $SYSTEM.Version.IsUnicode()Opens in a new tab method show if your Caché installation supports Unicode.
For most purposes, Caché only supports the Unicode Basic Multilingual Plane (hex 0000 through FFFF), which contains the most commonly-used international characters. Internally, Caché uses the UCS-2 encoding, which for the Basic Multilingual Plane, is the same as UTF-16. All characters are encoded using 16 bits (two bytes). However, when saving a string to disk in a global, if all the characters in the string have numerical values of 255 or lower (ASCII values), Caché stores the string using one byte per character. You can work with characters that are not in the Unicode Basic Multilingual Plane by using $WCHAR, $WISWIDE, and related functions.
For conversion between Unicode and UTF-8, and conversions to other character encodings, refer to the $ZCONVERT function. You can use ZZDUMP to display the hexadecimal encoding for a string of characters. You can use $CHAR to specify a character (or string of characters) by its decimal (base 10) encoding. You can use $ZHEX to converts a hexadecimal number to a decimal number, or a decimal number to a hexadecimal number.
Letters in Unicode
On a Unicode installation of Caché, some names can contain Unicode letter characters, while other names cannot contain Unicode letters. Unicode letters are defined as alphabetic characters with ASCII values higher than 255. For example, the Greek lowercase lambda is $CHAR(955), a Unicode letter.
Unicode letter characters are permitted throughout Caché, with the following exceptions:
-
Variable names: local variable names can contain Unicode letters. However, global variable names and process-private global names cannot contain Unicode letters. Subscripts for variables of all types can be specified with Unicode characters.
-
Administrator user names and passwords used for database encryption cannot contain Unicode characters.
The Japanese locale does not support accented Latin letter characters in Caché names. Japanese names may contain (in addition to Japanese characters) the Latin letter characters A-Z and a-z (65–90 and 97–122), and the Greek capital letter characters (913–929 and 931–937).
Whitespace
Under certain circumstances, ObjectScript treats whitespace as syntactically meaningful. Unless otherwise specified, whitespace refers to blank spaces, tabs, and line feeds interchangeably. In brief, the rules are:
-
Whitespace must appear at the beginning of each line of code and each single-line comment. Leading whitespace is not required for:
-
Label (also known as a tag or an entry point): a label must appear in column 1 with no preceding whitespace character. If a line has a label, there must be whitespace between the label and any code or comment on the same line. If a label has a parameter list, there can be no whitespace between the label name and the opening parenthesis for the parameter list. There can be whitespace before, between, or after the parameters in the parameter list.
-
Macro directive: a macro directive such as #define can appear in column 1 with no preceding whitespace character. This is a recommended convention, but whitespace is permitted before a macro directive.
-
Multiline comment: the first line of a multiline comment must be preceded by one or more spaces. The second and subsequent lines of a multiline comment do not require leading whitespace.
-
Blank line: if a line contains no characters, it does not need to contain any spaces. A line consisting only of whitespace characters is permitted and treated as a comment.
-
-
There must be one and only one space (not a tab) between a command and its first argument; if a command uses a postconditional, there are no spaces between the command and its postconditional.
-
If a postconditional expression includes any spaces, then the entire expression must be parenthesized.
-
There can be any amount of whitespace between any pair of command arguments.
-
If a line contains code and then a single-line comment, there must be whitespace between them.
-
Typically, each command appears on its own line, though you can enter multiple commands on the same line. In this case, there must be whitespace between them; if a command is argumentless, then it must be followed by two spaces (two spaces, two tabs, or one of each). Additional whitespace may follow these two required spaces.
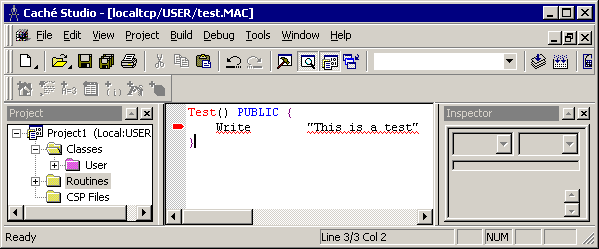
The Studio provides built-in syntax checking, so that it will mark any illegal use of whitespace, such as the following insertion of multiple spaces before a command’s first argument:
Comments
It is good practice to use comments to provide in-line documentation in code, as they are a valuable resource when modifying or maintaining code. ObjectScript supports several types of comments which can appear in several kinds of locations:
Comments in INT Code for Routines and Methods
ObjectScript code is written as MAC code, from which INT (intermediate) code is generated. Comments written in MAC code are generally available in the corresponding INT code. You can use the ZLOAD command to load an INT code routine, then use the ZPRINT command or the $TEXT function to display INT code, including these comments. The following types of comments are available, all of which must start in column 2 or greater:
-
The /* */ multiline comment can appear within a line or across lines. /* can be the first element on a line or can follow other elements; */ can be the final element on the line or can precede other elements. All lines in a /* */ appear in the INT code, including lines that consist of just the /* or */, with the exception of completely blank lines. A blank line within a multi-line comment is omitted from the INT code, and can thus affect the line count.
-
The // comment specifies that the remainder of the line is a comment; it can be the first element on the line or follow other elements.
-
The ; comment specifies that the remainder of the line is a comment; it can be the first element on the line or can follow other elements.
-
The ;; comment — a special case of the ; comment type — makes the comment available to the $TEXT function when the routine is distributed as object code only; the comment is only available to $TEXT if no commands precede it on the line.
Note:Because InterSystems IRIS retains ;; comments in the object code (the code that is actually interpreted and executed), there is a performance penalty for including them and they should not appear in loops.
A multiline comment (/* comment */) can be placed between command or function arguments, either before or after a comma separator. A multiline comment cannot be placed within an argument, or be placed between a command keyword and its first argument or a function keyword and its opening parenthesis. It can be placed between two commands on the same line, in which case it functions as the single space needed to separate the commands. You can immediately follow the end of a multiline comment (*/) with a command on the same line, or follow it with a single line comment on the same line. The following example shows these insertions of /* comment */ within a line:
WRITE $PIECE("Fred&Ginger"/* WRITE "world" */,"&",2),!
WRITE "hello",/* WRITE "world" */" sailor",!
SET x="Fred"/* WRITE "world" */WRITE x,!
WRITE "hello"/* WRITE "world" */// WRITE " sailor"Comments in MAC Code for Routines and Methods
The following comment types can be written in MAC code but have different behaviors in the corresponding INT code:
-
The #; comment can start in any column but must be the first element on the line. #: comments do not appear in INT code. Neither the comment nor the comment marker (#;) appear in the INT code and no blank line is retained. Therefore, the #; comment can change INT code line numbering.
-
The ##; comment can start in any column. It can be the first element on the line or can follow other elements. ##; comments do not appear in INT code. ##: can be used in ObjectScript code, in Embedded SQL code, or on the same line as a #define, #def1arg or ##continue macro preprocessor directive.
If the ##; comment starts in column 1, neither the comment nor the comment marker (##;) appear in the INT code and no blank line is retained. However, if the ##; comment starts in column 2 or greater, neither the comment nor the comment marker (##;) appear in the INT code, but a blank line is retained. In this usage, the ##; comment does not change INT code line numbering.
-
The /// comment can start in any column but must be the first element on the line. If /// starts in column 1, it does not appear in INT code and no blank line is retained. If /// starts in column 2 or greater, the comment appears in INT code and is treated as if it were a // comment.
Comments in Class Definitions Outside of Method Code
Within class definitions, but outside of method definitions, several comment types are available, all of which can start in any column:
-
The // and /* */ comments are for comments within the class definition.
-
The /// comment serves as class reference content for the class or class member that immediately follows it. For classes themselves, the /// comment preceding the beginning of the class definition provides the description of the class for the class reference content which is also the value of description keyword for the class). Within classes, all /// comments immediately preceding a member (either from the beginning of the class definition or after the previous member) provide the class reference content for that member, where multiple lines of content are treated as a single block of HTML. For more information on the rules for /// comments and the class reference, see either “Creating Class Documentation” in the chapter Defining and Compiling Classes in Defining and Using Classes or the %CSP.DocumaticOpens in a new tab entry in the InterSystems Class Reference.
Literals
A literal is a constant value consisting of a series of characters that represents a particular string or numeric value, such as “Hello” and “5” below:
SET x = "Hello"
SET y = 5ObjectScript recognizes two types of literals:
String Literals
A string literal is a set of zero or more characters delimited by quotation marks (unlike string literals, numeric literals do not need delimiters). ObjectScript string literals are delimited with double quotation marks (for example, "myliteral"); Caché SQL string literals are delimited with single quotation marks (for example, 'myliteral'). These quotation mark delimiters are not counted in the length of the string.
A string literal can contain any characters, including whitespace and control characters. The length of a string literal is measured as the number of characters in the string, not the number of bytes. A string can contain just 8-bit ASCII characters. On Unicode systems, a string can also contain 16-bit Unicode characters (known as wide characters). If you include a single wide character in a string, Caché will represent all characters in the string as 16-bit characters. Because Caché almost always treats a string as characters, not bytes, this use of wide characters is usually invisible to the user. (One exception is the ZZDUMP command, as shown below.)
The maximum string size is configurable. If long strings are enabled, the maximum string size to 3,641,144 characters. Otherwise, the maximum string size is 32,767 characters. Long strings are enabled by default. See the “Long Strings” section in the “Data Types and Values” chapter.
The following Unicode example shows a string of 8-bit characters, a string of 16-bit characters (Greek letters), and a combined string:
DO AsciiLetters
IF $SYSTEM.Version.IsUnicode() {
DO GreekUnicodeLetters
DO CombinedAsciiUnicode
RETURN }
ELSE { WRITE "Unicode not supported"
RETURN }
AsciiLetters()
SET a="abc"
WRITE a
WRITE !,"the length of string a is ",$LENGTH(a)
ZZDUMP a
GreekUnicodeLetters()
SET b=$CHAR(945)_$CHAR(946)_$CHAR(947)
WRITE !!,b
WRITE !,"the length of string b is ",$LENGTH(b)
ZZDUMP b
CombinedAsciiUnicode()
SET c=a_b
WRITE !!,c
WRITE !,"the length of string c is ",$LENGTH(c)
ZZDUMP cNot all string characters are typeable. You can specify non-typeable characters using the $CHAR function, as shown in the following Unicode example:
SET greekstr=$CHAR(952,945,955,945,963,963,945)
WRITE greekstrNot all string characters are displayable. They can be non-printing characters or control characters. The WRITE command represents non-printing characters as a box symbol. The WRITE command causes control characters to execute. In the following example, a string contains printable characters alternating with the Null ($CHAR(0)), Tab ($CHAR(9)) and Carriage Return ($CHAR(13)) characters:
SET a="a"_$CHAR(0)_"b"_$CHAR(9)_"c"_$CHAR(13)_"d"
WRITE !,"the length of string a is ",$LENGTH(a)
ZZDUMP a
WRITE !,aNote that the WRITE command executes some control characters from the Terminal command line which WRITE executing in a program displays as non-printing characters. For example, the Bell ($CHAR(7)) and Vertical Tab ($CHAR(11)) characters.
To include the quotation mark character (") within a string, double the character, as shown in the following example:
SET x="This quote"
SET y="This "" quote"
WRITE x,!," string length=",$LENGTH(x)
ZZDUMP x
WRITE !!,y,!," string length=",$LENGTH(y)
ZZDUMP yA string that contains no value is known as a null string. It is represented by two quotation mark characters (""). A null string is considered to be a defined value. It has a length of 0. Note that the null string is not the same as a string consisting of the null character ($CHAR(0)), as shown in the following example:
SET x=""
WRITE "string=",x," length=",$LENGTH(x)," defined=",$DATA(x)
ZZDUMP x
SET y=$CHAR(0)
WRITE !!,"string=",y," length=",$LENGTH(y)," defined=",$DATA(y)
ZZDUMP yFor further details on strings, refer to Strings in the “Data Types and Values” chapter of this manual.
Numeric Literals
Numeric literals are values that ObjectScript evaluates as numbers. They do not require delimiters. Caché converts numeric literals to canonical form (their simplest numeric form):
SET x = ++0007.00
WRITE "length: ",$LENGTH(x),!
WRITE "value: ",x,!
WRITE "equality: ",x = 7,!
WRITE "arithmetic: ",x + 1You can also represent a number as a string literal delimited with quotation marks; a numeric string literal is not converted to canonical form, but can be used as a number in arithmetic operations:
SET y = "++0007.00"
WRITE "length: ",$LENGTH(y),!
WRITE "value: ",y,!
WRITE "equality: ",y = 7,!
WRITE "arithmetic: ",y + 1For further details refer to Strings as Numbers in the “Data Types and Values” chapter of this manual.
ObjectScript treats as a number any value that contains the following (and no other characters):
| Value | Quantity |
|---|---|
| The digits 0 through 9. | Any quantity, but at least one. |
| Sign operators: Unary Minus (-) and Unary Plus (+). | Any quantity, but must precede all other characters. |
| The decimal_separator character (by default this is the period or decimal point character; in European locales this is the comma character). | At most one. |
| The Letter “E” (used in scientific notation). | At most one. Must appear between two numbers. |
For further details on the use and interpretation of these characters, refer to Fundamentals of Numbers in the “Data Types and Values” chapter.
ObjectScript can work with the following types of numbers:
-
Integers (whole numbers such as 100, 0, or -7).
-
Fractional numbers: decimal numbers (real numbers such as 3.767) and decimal fractions (real numbers such as .0442). ObjectScript supports two internal representations of fractional numbers: standard Caché floating point numbers ($DECIMAL numbers) and IEEE double-precision floating point numbers ($DOUBLE numbers). For further details, refer to the $DOUBLE function.
-
Scientific notation: numbers placed in exponential notation (such as 2.8E2).
Identifiers
An identifier is the name of a variable, a routine, or a label. In general, legal identifiers consist of letter and number characters; with few exceptions, punctuation characters are not permitted in identifiers. Identifiers are case-sensitive.
The naming conventions for user-defined commands, functions, and special variables are more restrictive (only letters permitted) than identifier naming conventions. Refer to Extending Languages with ^%ZLANG Routines in Caché Specialized System Tools and Utilities.
Naming conventions for local variables, process-private globals, and globals are provided in the Variables chapter of this document.
Punctuation Characters within Identifiers
Certain identifiers can contain one or more punctuation characters. These include:
-
The first character of an identifier can be a percent (%) character. Caché names beginning with a % character (except those beginning with %Z or %z) are reserved as system elements. For further details, see “Rules and Guidelines for Identifiers” in the Caché Programming Orientation Guide.
-
A global or process-private global name (but not a local variable name) may include one or more period (.) characters. A routine name may include one or more period (.) characters. A period cannot be the first or last character of an identifier.
Note that globals and process-private globals are identified by a caret (^) prefix of one or more characters, such as the following:
Globals: Process-Private Globals: ^globname ^||ppgname ^|""|globname ^|"^"|ppgname ^|"mynspace"|globname ^|"^",""|ppgname ^["mynspace"]globname ^["^"]ppgname
These prefix characters are not part of the variable name; they identify the type of storage and (in the case of globals) the namespace used for this storage. The actual name begins after the final vertical bar or closing square bracket.
Labels
Any line of ObjectScript code can optionally include a label (also known as a tag). A label serves as a handle for referring to that line location in the code. A label is an identifier that is not indented; it is specified in column 1. All ObjectScript commands must be indented.
Labels have the following naming conventions:
-
The first character must be an alphanumeric character or the percent character (%). Note that labels are the only ObjectScript names that can begin with a number. The second and all subsequent characters must be alphanumeric characters. A label may contain Unicode letters.
-
They can be up to 31 characters long. A label may be longer than 31 characters, but must be unique within the first 31 characters. A label reference matches only the first 31 characters of the label. However, all characters of a label or label reference (not just the first 31 characters) must abide by label character naming conventions.
-
They are case-sensitive.
A block of ObjectScript code specified in an SQL command such as CREATE PROCEDURE or CREATE TRIGGER can contain labels. In this case, the first character of the label is prefixed by a colon (:) specified in column 1. The rest of the label follows the naming and usage requirements describe here.
A label can include or omit parameter parentheses. If included, these parentheses may be empty or may include one or more comma-separated parameter names. A label with parentheses identifies a procedure block.
A line can consist of only a label, a label followed by one or more commands, or a label followed by a comment. If a command or a comment follows the label on the same line, they must be separated from the label by a space or tab character.
The following are all unique labels:
maximum
Max
MAX
86
agent86
86agent
%controlYou can use the $ZNAME function to validate a label name. Do not include parameter parentheses when validating a label name.
You can use the ZINSERT command to insert a label name into source code.
Using Labels
Labels are useful for identifying sections of code and for managing flow of control.
The DO and GOTO commands can specify their target location as a label. The $ZTRAP special variable can specify the location of its error handler as a label. The JOB command can specify the routine to be executed as a label.
Labels are also used by the PRINT, ZPRINT, ZZPRINT, ZINSERT, ZREMOVE, and ZBREAK commands and the $TEXT function to identify source code lines.
However, you cannot specify a label on the same line of code as a CATCH command, or between a TRY block and a CATCH block.
Ending a Labelled Section of Code
A label provides an entry point, but it does not define an encapsulated unit of code. This means that once the labelled code executes, execution continues into the next labelled unit of code unless execution is stopped or redirected elsewhere. There are three ways to stop execution of a unit of code:
-
Execution encounters the closing curly brace (“}”) of a TRY. When this occurs, execution continues with the next line of code following the associated CATCH block.
-
Execution encounters the next procedure block (a label with parameter parentheses). Execution stops when encountering a label line with parentheses, even if there are no parameters within the parentheses.
In the following example, code execution continues from the code under “label0” to that under “label1”:
SET x = $RANDOM(2)
IF x=0 {DO label0
WRITE "Finished Routine0",!
QUIT }
ELSE {DO label1
WRITE "Finished Routine1",!
QUIT }
label0
WRITE "In Routine0",!
FOR i=1:1:5 {
WRITE "x = ",x,!
SET x = x+1 }
WRITE "At the end of Routine0",!
label1
WRITE "In Routine1",!
FOR i=1:1:5 {
WRITE "x = ",x,!
SET x = x+1 }
WRITE "At the end of Routine1",!In the following example, the labeled code sections end with either a QUIT or RETURN command. This causes execution to stop. Note that RETURN always stops execution, QUIT stops execution of the current context:
SET x = $RANDOM(2)
IF x=0 {DO label0
WRITE "Finished Routine0",!
QUIT }
ELSE {DO label1
WRITE "Finished Routine1",!
QUIT }
label0
WRITE "In Routine0",!
FOR i=1:1:5 {
WRITE "x = ",x,!
SET x = x+1
QUIT }
WRITE "Quit the FOR loop, not the routine",!
WRITE "At the end of Routine0",!
QUIT
WRITE "This should never print"
label1
WRITE "In Routine1",!
FOR i=1:1:5 {
WRITE "x = ",x,!
SET x = x+1 }
WRITE "At the end of Routine1",!
RETURN
WRITE "This should never print"In the following example, the second and third labels identify procedure blocks (a label specified with parameter parentheses). Execution stops when encountering a procedure block label:
SET x = $RANDOM(2)
IF x=0 {DO label0
WRITE "Finished Routine0",!
QUIT }
ELSE {DO label1
WRITE "Finished Routine1",!
QUIT }
label0
WRITE "In Routine0",!
FOR i=1:1:5 {
WRITE "x = ",x,!
SET x = x+1 }
WRITE "At the end of Routine0",!
label1()
WRITE "In Routine1",!
FOR i=1:1:5 {
WRITE "x = ",x,!
SET x = x+1 }
WRITE "At the end of Routine1",!
label2()
WRITE "This should never print"Namespaces
A namespace name may be an explicit namespace name or an implied namespace name. An explicit namespace name is not case-sensitive; regardless of the case of the letters with which it is input, it is always stored and returned in uppercase letters.
In an explicit namespace name, the first character must be a letter or a percent sign (%). The remaining characters must be letters, numbers, hyphens (–), or underscores (_). The name cannot be longer than 255 characters.
When Caché translates an explicit namespace name to a routine or class name (for example, when creating a cached query class/routine name), it replaces punctuation characters with lowercase letters, as follows: % = p, _ = u, – = d. An implied namespace name may contain other punctuation characters; when translating an implied namespace name, these punctuation characters are replaced by a lowercase "s". Thus the following seven punctuation characters are replaced as follows: @ = s, : = s, / = s, \ = s, [ = s, ] = s, ^ = s.
The following namespace names are reserved: %SYS, BIN, BROKER, DOCBOOK and DOCUMATIC.
When using the Caché SQL CREATE DATABASE command, creating an SQL database creates a corresponding Caché namespace.
When using Caché MultiValue, creating a MultiValue account creates a corresponding Caché namespace. The naming conventions for MultiValue accounts and Caché namespaces differ. For details about how MultiValue account names are translated to namespace names, refer to the CREATE.ACCOUNT command in the Caché MultiValue Commands Reference.
A namespace exists as a directory in your Caché instance. To return the full pathname of the current namespace, you can invoke the NormalizeDirectory()Opens in a new tab method, as shown in the following example:
WRITE ##class(%Library.File).NormalizeDirectory("")For information on using namespaces, see Namespaces and Databases in the Caché Programming Orientation Guide. For information on creating namespaces, see Configuring Namespaces in the Caché System Administration Guide.
Extended References
An extended reference is a reference to an entity that is located in another namespace. The namespace name can be specified as a string literal enclosed in quotes, as a variable that resolves to a namespace name, as an implied namespace name, or as a null string ("") a placeholder that specifies the current namespace. There are three types of extended references:
-
Extended Global Reference: references a global variable in another namespace. The following syntactic forms are supported: ^["namespace"]global and ^|"namespace"|global. For further details, refer to Global Variables section of the “Variables” chapter of this manual.
-
Extended Routine Reference: references a routine in another namespace.
-
The DO command, the $TEXT function, and user-defined functions support the following syntactic form: |"namespace"|routine.
-
The JOB command supports the following syntactic forms: routine|"namespace"|, routine["namespace"], or routine:"namespace".
In all these cases, the extended routine reference is prefaced by a ^ (caret) character to indicate that the specified entity is a routine (rather than a label or an offset). This caret is not part of the routine name. For example, DO ^|"SAMPLES"|fibonacci invokes the routine named fibonacci, which is located in the SAMPLES namespace. The command WRITE $$fun^|"SAMPLES"|house invokes the user-defined function fun() in the routine house, located in the SAMPLES namespace.
-
-
Extended SSVN Reference: references a structured system variable (SSVN) in another namespace. The following syntactic forms are supported: ^$["namespace"]ssvn and ^$|"namespace"|ssvn. For further details, refer to the ^$GLOBAL, ^$LOCK, and ^$ROUTINE structured system variables.
All extended references can, of course, specify the current namespace, either explicitly by name, or by specifying a null string placeholder.
Reserved Words
There are no reserved words in ObjectScript; you can use any valid identifier as a variable name, function name, or label. At the same time, it is best to avoid using identifiers that are command names, function names, or other such strings. Also, since ObjectScript code includes support for embedded SQL, it is prudent to avoid naming any function, object, variable, or other entity with an SQL reserved word, as this may cause difficulties elsewhere.