Caché での PMML モデルの使用
この項目では、Caché PMML (Predictive Modelling Markup Language) の実行時サポートの使用方法について説明します。以下のトピックについて説明します。
背景
PMML (Predictive Modelling Markup Language) は、分析モデルを表すための XML ベースの標準です。アプリケーションが統計およびデータ・マイニング・モデルを簡単に再使用および共有できるように定義するための方法を提供します。モデルを生成するために使用される分析ツール (PMML:R、KNIME、SAS、および SPSS などのツール) は Caché または Ensemble 運用環境で使用されるツールとはアーキテクチャが大きく異なるため、この標準が特に役立ちます。
一般的なシナリオでは、データ・サイエンティストは分析ツールを使用して大量の履歴データに基づいてデータ・マイニング・モデルを生成します。このモデルはその後 PMML にエクスポートされます。このモデルは、実行時環境に配置して、受信状態で実行し、モデルのターゲット・メトリックの値を予測することができます。
詳細は、http://www.dmg.org/Opens in a new tab を参照してください。
Caché の PMML のサポート
Caché は以下のように PMML 4.1Opens in a new tab および 4.2Opens in a new tab の実行時サポートを提供します。
-
既存の PMML 定義を、%DeepSee.PMML.DefinitionOpens in a new tab のサブクラスである特殊 Caché クラス定義に配置することができます。
そのクラスがコンパイルされるときに、システムはその中に記述されているモデルを実行するために必要なコードを生成します。
-
Caché は、指定したデータ入力に基づいて、モデルを実行するための API を提供します。
-
Caché は、API を使用するサンプルのテスト・ページを提供します。
サポートされているモデル
Caché は PMML 4.1Opens in a new tab、4.2Opens in a new tab および以下の PMML モデルをサポートします。
-
Naive Bayes モデル (http://www.dmg.org/v4-1/NaiveBayes.htmlOpens in a new tab)
-
回帰モデル (http://www.dmg.org/v4-1/Regression.htmlOpens in a new tab)
-
プロビット・リンク関数およびコントラスト行列を除く一般回帰モデル (http://www.dmg.org/v4-1/GeneralRegression.htmlOpens in a new tab)
-
入れ子モデルを除くツリー・モデル (http://www.dmg.org/v4-1/TreeModel.htmlOpens in a new tab)
-
基本的なサポートであるテキスト・モデル (http://www.dmg.org/v4-1/Text.htmlOpens in a new tab)
-
サポート・ベクター・マシン (SVM) モデル (http://www.dmg.org/v4-1/SupportVectorMachine.htmlOpens in a new tab)
-
クラスタリング・モデル (http://www.dmg.org/v4-1/ClusteringModel.htmlOpens in a new tab)
-
RuleSet モデル (http://www.dmg.org/v4-1/RuleSet.htmlOpens in a new tab)
-
NeuralNetwork モデル (http://www.dmg.org/v4-1/NeuralNetwork.htmlOpens in a new tab)
Caché は <MiningModel> 要素もサポートします。これは、“モデルのセグメンテーション” — (予測のバランスを向上するために複数のモデルの出力を結合するプロセス) を提供します。http://www.dmg.org/v4-1/MultipleModels.htmlOpens in a new tab を参照してください。Caché は “モデル構造” の手法をサポートしません。この手法は非推奨となっています。
あやめサンプル
SAMPLES ネームスペースは、PMML をよく知るために使用することができるサンプルを提供します。
このサンプルには、予測分析に使用される既知のサンプルである Iris データセットのコピーが含まれます。Iris データセットは、異なる 3 種のあやめ約 50 本における花弁およびがく片測定の測定値を提供します。これらの測定値は、あやめの種を強く予測します。
このサンプルをセットアップするには、以下のコマンドを使用します。
d ##class(DataMining.IrisDataset).load()
このステップでは、DataMining.IrisDatasetOpens in a new tab内にレコードを作成します。
その後、 DataMining.PMML.IrisOpens in a new tab クラス内で PMML モデルを使用できます。このクラスは、以下のモデルを含む PMML 定義を含みます。
-
花弁およびがく片測定値に基づいて、あやめの種を予測するツリー・モデル
-
花弁幅、花弁測定値および種に基づいて、がく片の長さを予測する一般回帰モデル
PMML モデルを含むクラスの作成
PMML モデルを含むクラスの作成する手順は以下のとおりです。
-
PMML モデル・テスト・ページ (この項目で後述) にアクセスします。
-
[新規作成] をクリックします。
-
[クラス名] で、完全修飾クラス名を入力します。
-
[PMML ファイル] で、[参照] をクリックして、PMML ファイルを選択します。
-
[インポート] をクリックします。
または、スタジオを使用して、 %DeepSee.PMML.DefinitionOpens in a new tab のサブクラスを作成します。このクラスでは、PMML という名前の XData ブロックを作成し、その XData ブロックに PMML 定義を貼り付けます。この XData ブロックに対して、以下のように XMLNamespace キーワードを設定します。
XMLNamespace = "http://www.intersystems.com/deepsee/pmml"
例は、SAMPLES ネームスペースの DataMining.PMML.IrisOpens in a new tab を参照してください。以下は、部分的な抽出です。
Class DataMining.PMML.Iris Extends %DeepSee.PMML.Definition
{
XData PMML [ XMLNamespace = "http://www.intersystems.com/deepsee/pmml" ]
{
<PMML version="4.1">
<Header>
<Timestamp>03/07/2013 11:54:41</Timestamp>
</Header>
<DataDictionary numberOfFields="5">
<Extension name="isc:datasource">
<X-SQLDataSource name="Analysis dataset">
<X-FieldMap fieldName="PetalLength" spec="PetalLength" />
<X-FieldMap fieldName="PetalWidth" spec="PetalWidth" />
<X-FieldMap fieldName="SepalLength" spec="SepalLength" />
<X-FieldMap fieldName="SepalWidth" spec="SepalWidth" />
<X-FieldMap fieldName="Species" spec="Species" />
<X-SQL>SELECT PetalLength, PetalWidth, SepalLength, SepalWidth, UPPER(Species) Species
FROM DataMining.IrisDataset</X-SQL>
</X-SQLDataSource>
</Extension>
<DataField name="PetalLength" displayName="PetalLength" optype="continuous" dataType="double" />
<DataField name="PetalWidth" displayName="PetalWidth" optype="continuous" dataType="double" />
<DataField name="SepalLength" displayName="SepalLength" optype="continuous" dataType="double" />
<DataField name="SepalWidth" displayName="SepalWidth" optype="continuous" dataType="double" />
<DataField name="Species" displayName="Species" optype="categorical" dataType="string">
<Value value="IRIS-SETOSA" property="valid" />
<Value value="IRIS-VERSICOLOR" property="valid" />
<Value value="IRIS-VIRGINICA" property="valid" />
</DataField>
</DataDictionary>
...
このサンプルの設定および使用についての詳細は、この項目内の前述の “あやめサンプル” を参照してください。
サポートされているデータ・ディクショナリ拡張
InterSystems は、<DataDictionary> 要素内で 2 種類の <Extension> 要素をサポートします。
-
<X-SQLDataSource> は、SQL クエリに関するデータ・ソースを定義します。この要素は、SQL フィールドから PMML 定義内のデータ・フィールドへのマッピングを定義します。
例は、SAMPLES ネームスペースの DataMining.PMML.IrisOpens in a new tab を参照してください。
-
<X-DeepSeeDataSource> は、指定されたキューブのメジャーとディメンジョンから PMML 定義内のデータ・フィールドへのマッピングを定義します。
生成されたクラス
PMML クラス (PackageName.ClassName) をコンパイルすると、システムは以下のクラスを生成します。
-
PackageName.ClassName.Data は、モデルを実行するために必要なデータを表します。このクラスは、PMML 定義の <DataDictionary> 要素に対応しています。
-
PackageName.ClassName.ModelName は、モデルを表します。
このクラスはモデルを実行するためのメソッドを提供します。
-
PackageName.ClassName.ModelName.Input は、指定されたモデルの入力を表します。
-
PackageName.ClassName.ModelName.Output は、指定されたモデルの出力を表します。
Caché は、これらのクラスを使用してモデルを実行します。
PMML モデルを実行するためのテスト・ページ
Caché は、レコードのバッチまたは単一入力レコードに対する PMML モデルを実行するために使用できるテスト・ページを提供します。このページにアクセスする手順は以下のとおりです。
-
管理ポータルを開きます。
-
適切なネームスペースに切り替えます。
-
[DeepSee]→[ツール]→[PMML モデル・テスター] をクリックします。
サンプル・モデル・テスト・ページ
次のようなページが表示されます (部分的に表示)。
このページを使用する手順は以下のとおりです。
-
[開く] をクリックし、モデル・クラスを選択して、[OK] をクリックします。
-
[モデル] ドロップダウン・リストからモデルをクリックします。
-
[データソース] ドロップダウン・リストからオプションをクリックします。オプションには以下のものがあります。
-
[分析データセット] — モデルが開発されたソース・データを選択します。
-
[キューブ・マッピング] — モデルの <X-DeepSeeDataSource> 要素を選択します (ある場合)。この項目で前述した “サポートされているデータ・ディクショナリ拡張” を参照してください。
-
[カスタム・データ・ソース (SQL)] — レコードのセットを提供する SQL クエリを入力できるようにします。
-
-
[カスタム・データ・ソース (SQL)] を選択した場合、SQL SELECT クエリを [カスタム・データ・ソース] に入力します。
-
[実行] をクリックします。
Caché はレコードの繰り返し処理を行い、結果の概要を表示します。詳細はモデルによって異なります。以下に例を示します。
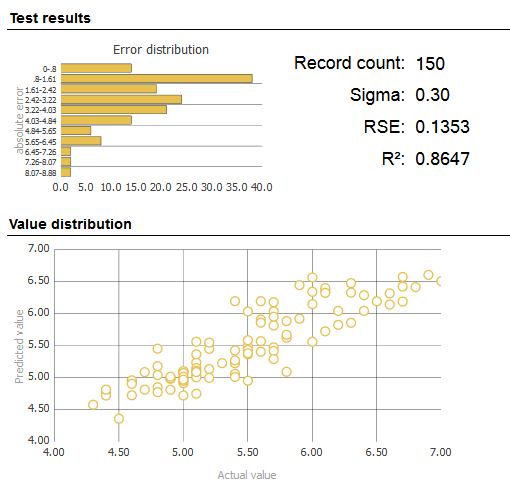
単一入力レコードのテスト・ページ
単一入力レコードでモデルをテストすることも可能です。そのためには、[テスト] を押します。以下のようなダイアログ・ボックスが表示されます。
[データ・オブジェクト] にリストされているフィールドは、PMML 定義のデータ・フィールドに対応します。
このページを使用するには、[モデル] ドロップダウン・リストからモデルを選択します。このモデルは、どのフィールドが入力フィールドであるか出力フィールドであるかを決定します。入力フィールドに値を入力します。すべての入力値を入力すると、ページに、指定されたモデルの出力フィールドの予測値が表示されます。以下はその例です。
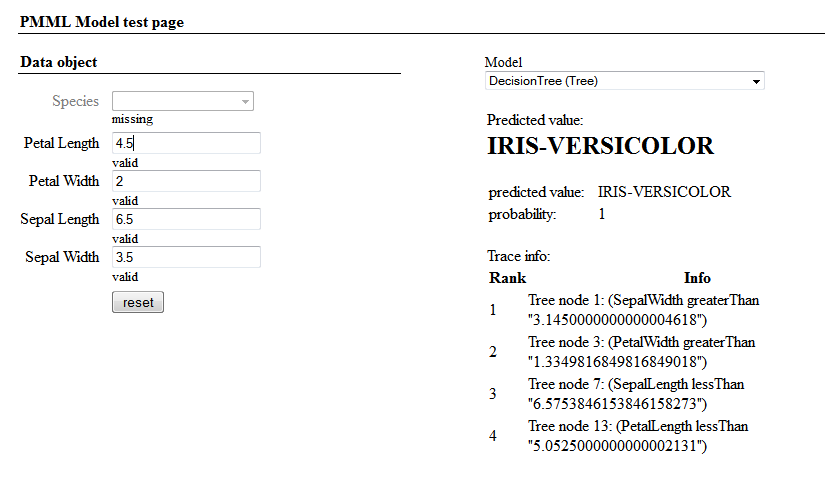
ほぼ同じページにアクセスするには、スタジオで PMML モデル・クラスを開き、F5 を押します (または 表示, ウェブページ をクリックします)。ここに示したようなページが表示されますが、そこには [バッチ・テスト・ページに移動] へのリンクもあり、メインの PMML モデル・テスト・ページにアクセスできます。
プログラムによる PMML モデルの実行
Caché では、PMML モデルを実行するために使用できる ダイレクト API も提供します。
単一入力レコードを持つモデルの実行
単一レコードの予測モデルを実行するには、以下の手順に従います。
-
生成されたクラス PackageName.ClassName.ModelName のインスタンスを作成します。このクラスは、モデルを実行するために使用できるメソッドを定義します。
-
生成されたクラス PackageName.ClassName.Data のインスタンスを作成し、そのプロパティを設定します。このインスタンスの目的は、入力値を含めることです。
-
モデル・インスタンスの %ExecuteModel() メソッドを呼び出します。
Method %ExecuteModel(ByRef pData As %DeepSee.PMML.Data, Output pOutput As %DeepSee.PMML.ModelOutput) as %StatuspData では、ステップ 2 で作成したデータ・オブジェクトを使用します。
このメソッドは、出力引数として、モデルの出力を含む %DeepSee.PMML.ModelOutputOpens in a new tab のインスタンスを返します。具体的には、これは指定されたモデルの生成されたクラス PackageName.ClassName.ModelName.Output のインスタンスです。
-
出力の詳細を表示するには、ZWRITE を使用します。pOutput オブジェクトは、モデル定義の Output> 要素内の各 OutputField> に対して 1 つのプロパティを含みます。<Output> 要素がない場合は、 pOutput は、予測された MiningField> 要素の後に指定された単一フィールドを含みます。
あるいは、PMML 定義内に <X-DeepSeeDataSource> を指定した場合は、%ExecuteModelDeepSee()を使用します。クラス・リファレンスを参照してください。
入力レコードのバッチを持つモデルの実行
入力レコードのバッチを持つ予測モデルを実行するには、%DeepSee.PMML.UtilsOpens in a new tab の %RunModel()、%RunModelFromResultSet、または %RunModelFromSQL を使用します。これらのメソッドは、予測結果を %DeepSee_PMML_Utils.TempResult テーブルに保存します。
DeepSee 内で PMML を使用するためのオプション
このセクションでは、その他のオプションについて説明します。
DeepSee ピボット・テーブルからのモデルの呼び出し
PMML モデルを DeepSee ピボット・テーブルから呼び出すことができます。そのためには、%KPI 関数を使用する計算メンバを定義して %DeepSee.PlugIn.PMMLOpens in a new tab プラグインを呼び出します。以下の構文を使用します。
%KPI("%DeepSee.PMML",fieldName,series,"PMML",modelClassName,parmName1,parmValue1,parmName2,parmValue2,"%CONTEXT")
以下はその説明です。
-
fieldName は、Caché PMML モデル・クラスの出力フィールドの引用符付き名です。
-
series は、プラグインの系列 (行) の数 (オプション) です。1 を指定するかまたはこの引数を省略します。
-
modelClassName は、Caché PMML モデル・クラスの引用符付き名です。
-
parmName1、parmName2(以降同様) は、%DeepSee.PlugIn.PMMLOpens in a new tab プラグインのパラメータの引用符付き名 (オプション) です。このパラメータ名は大文字と小文字を区別しますので、注意してください。%DeepSee.PlugIn.PMMLOpens in a new tab プラグインには、以下のパラメータが用意されています。
-
"%cube" — この KPI が実行されるキューブを指定します。
-
"ModelName" — 実行するモデルの名前を指定します。指定する場合、これは指定されたモデル・クラスのモデルである必要があります。空白のままにすると、このクラスの最初のモデルが実行されます。
-
"aggregate" — さまざまなファクトを越えて予測される値を集計する方法を指定します。 使用可能な値は、"average" (既定値)、"sum"、"max"、"min"、"maxFreqValue"、"maxProbValue"、"minFreqValue" および "minProbValue" です。
各出力フィールドの集計がすべて意味を持つとは限りません。
-
"NullValues" — 結果を集計するときに NULL 予測値を含めるかどうかを指定します。使用可能な値は、"ignore" (既定) または "count" です。
パラメータをリストする順序は、結果には影響しません。
16 個までのパラメータとその値を指定できます。
-
-
parmValue1、parmValue2 (以降同様) は、名前付きフィルタの対応値です。
特殊な %CONTEXT パラメータを使用すると、プラグインでクエリのコンテンツを考慮できます。それ以外の場合には無視されます。詳細は、"DeepSee MDX リファレンス" の %KPI 関数の参照を参照してください。
例えば、以下の構文を使用して、単一モデルのみが含まれている Test.MyModel という名前のPMML モデル・クラスの出力フィールド MyField の平均値を取得します。
%KPI("%DeepSee.PMML", "MyField",,"PMML","Test.MyModel","aggregate","average","%CONTEXT")
DeepSee リストに PMML 予測を含める
レコード・レベル予測を DeepSee リストに含めるには、リスト・クエリに $$$PMML トークンを使用します。このトークンは、PMML 定義クラス名およびモデル名をプライマリ・パラメータとして使用します。オプションの 3 番目の引数として、クエリに含める予測機能の名前を渡すことができます (この引数は既定で "predictedValue" に設定されています)。
以下は、このトークンを使用するリスト・クエリの定義を示しています。
UserID, TotalWagered, PercentLost "Lost %" , $$$PMML[MyPMML.Poker,PercentLost] "Predicted Loss %"
DeepSee キューブへのバッチ結果のエクスポート
入力レコードのバッチを持つ予測モデルを実行した後に、結果を DeepSee キューブにエクスポートすることができます。このオプションにより、結果を別の方法で視覚化することができます。キューブには、ActualValue と PredictedValue の 2 つのレベルがあります。
結果をキューブにエクスポートするには、PMML テスト・ページを使用して [エクスポート] をクリックします。Caché により、以下の情報が求められます。
-
[エクスポート] — [データのみ] または [クラスとデータ]を選択します。
-
[結果クラス名] — 結果が書き込まれる永続クラスの名前を指定します。これは、キューブのソース・クラスとして使用されます。
-
[ソース・クラスへのリンク] — ソース・レコードを含むクラスを指定します。結果クラスには、このクラスを指す Record という名前のプロパティが含まれています。
-
[データを削除] — エクスポートを実行する前に結果クラス ([結果クラス名]) を空にする場合にこれを選択します。新しくエクスポートするデータを結果クラス・テーブルの末尾に追加する場合にはこれをクリアします。
-
[キューブ名] — キューブの論理名を指定します。
-
[キューブ・クラス名] — キューブのクラス名を指定します。
-
[クラスを上書き] — このエクスポートを以前に実行済みで、新しいデータと定義でそれらのクラスを上書きする場合にこれを選択します。
指定されたキューブを作成できる [キューブの作成] ダイアログ・ボックスが表示されます。[ビルド] または [キャンセル] をクリックします。後から DeepSee アーキテクトを介してこのキューブにアクセスし、そこから作成することもできます。
キューブを作成した後に、DeepSee アナライザを使用してキューブを調べます。以下に例を示します。ActualValue レベルが行として、PredictedValue レベルが列として使用されます。
