グローバル構造
この章では、グローバルの論理的 (プログラミングからの観点) な説明と、物理的にグローバルがどのようにディスクに格納されるかについての概要を説明します。セクションは以下のとおりです。
グローバルの論理構造
グローバルとは名前付きの多次元配列で、物理 Caché データベースに格納されます。アプリケーションでは、現在のネーム・スペースに基づいて、グローバルが物理データベースにマッピングされます。ネーム・スペースは、1 つ以上の物理データベースの論理的な統一ビューを提供します。
グローバルの論理構造に関する項目は以下のとおりです。
グローバルの名前付け規約と制限
グローバルの名前は、その目的と使用法を明示します。2 つのタイプのグローバルと、“プロセス・プライベート・グローバル” と呼ばれる個別の変数のセットがあります。
-
グローバル — これは、標準グローバルと呼ばれることがあります。通常、これらは、単にグローバルと呼ばれます。現在のネームスペースに存在する永続的な多次元の配列です。
-
"拡張グローバル参照" — これは、現在のネームスペース以外のネームスペースにあるグローバルです。
-
"プロセス・プライベート・グローバル" — これは、これを作成したプロセスによってのみアクセス可能な配列変数です。
グローバルの命名規約は、以下のとおりです。
-
グローバル名はキャレット文字 (^) で開始します。このキャレット文字は、ローカル変数とグローバルを区別します。
-
グローバル名の先頭にあるキャレット (^) 文字の直後には、以下を使用できます。
-
文字またはパーセント記号 (%) — 標準グローバル用のみです。“%” で始まる名前を持つグローバル (ただし、“%Z” または “%z” で始まるものを除く) は、Caché システム用です。% グローバルは、通常 CACHESYS データベースまたは CACHELIB データベースに格納されます。% 文字およびインターシステムズの命名の詳細は、"Caché プログラミング入門ガイド" の “識別子のルールとガイドライン” を参照してください。
-
垂直バー (|) または左角括弧 ([) — 拡張グローバル参照またはプロセス・プライベート・グローバル用。使用法は、後続の文字によって異なります。このリストに続く例を参照してください。
-
-
上記以外のグローバル名には、文字、数字、またはピリオド記号 (.) を使用できます。パーセント記号 (%) は、グローバル名の最初の文字としてのみ使用できます。またピリオド記号 (.) は、グローバル名の最後の文字としては使用できません。
-
グローバル名の長さは、先頭のキャレット文字を除いて最大 31 文字とします。それ以上に長い名前を付けることも可能ですが、Caché でグローバル名として処理されるのは 31 文字までです。
-
グローバル名は、大文字と小文字を区別します。
-
Caché では、グローバル参照の合計の長さに制限を課しています。同様に、この制限によってあらゆる添え字の値の長さにも制限が課されます。詳細は、“グローバル参照の最大長” を参照してください。
CACHESYS データベースでは、グローバル名はすべて予約されていますが、先頭に “z”、“Z”、“%z”、および “%Z” が付くものについては例外です。他のすべてのデータベースでは、先頭に “ISC.” および “%ISC.” が付くグローバル名はすべて予約されています。
サンプル・グローバル名とその使用法
以下に、各種グローバル名とそれぞれの使用法の例を示します。
-
^globalname — 標準グローバル
-
^||globalname — プロセス・プライベート・グローバル
-
^|"^"|globalname — プロセス・プライベート・グローバル
-
^[directory,system]globalname — 拡張グローバル参照における暗示的ネームスペースのブラケット構文
-
^["^"]globalname — プロセス・プライベート・グローバル
-
^["^",""]globalname — プロセス・プライベート・グローバル
既定では、グローバル名には上記の説明にある識別子文字のみを使用できます。ただし、NLS (各国言語サポート) の設定により、異なる識別子文字を定義することもできます。グローバル名には Unicode 文字を使用できません。
したがって、以下はすべて有効なグローバル名です。
SET ^a="The quick "
SET ^A="brown fox "
SET ^A7="jumped over "
SET ^A.7="the lazy "
SET ^A1B2C3="dog's back."
WRITE ^a,^A,^A7,!,^A.7,^A1B2C3
KILL ^a,^A,^A7,^A.7,^A1B2C3 // keeps the database clean グローバル・ノードと添え字の概要
グローバルは一般的に複数のノードを有しており、通常は添え字または添え字のセットにより識別されます。基本的な例は、以下のようになります。
set ^Demo(1)="Cleopatra"この文はグローバル・ノード ^Demo(1) を参照しており、これは ^Demo グローバル内の 1 つのノードです。このノードは 1 つの添え字によって識別されます。
別の例を示します。
set ^Demo("subscript1","subscript2","subscript3")=12この文はグローバル・ノード ^Demo("subscript1","subscript2","subscript3") を参照しており、これは同一グローバル内の別のノードです。このノードは 3 つの添え字によって識別されます。
さらに別の例を以下に示します。
set ^Demo="hello world"この文はグローバル・ノード ^Demo を参照しており、これは添え字を使用していません。
グローバルのノードは階層構造を形成します。ObjectScript では、この構造を活用するコマンドが用意されています。例えば、ユーザは 1 つのノードを削除すること、または 1 つのノードとそのノードのすべての子を削除することができます。詳細は、次の章を参照してください。
グローバル添え字
添え字には、以下の規則があります。
-
添え字の値では大文字と小文字が区別されます。
-
添え字の値はあらゆる ObjectScript の式とすることができますが、式は NULL 文字列 ("") に評価されないという条件が付きます。
添え字の値には、空白、出力不能文字、Unicode 文字 (Unicode インストールの場合) など全種類の文字を使用できます。(出力不能文字は、添え字値において実用性が低いことに注意してください。)
-
グローバル参照を解決する前に、Caché はあらゆる他の式の評価と同じ方式で各添え字を評価します。以下の例では、^Demo グローバルの 1 つのノードを設定してから、いくつかの同等の方式にてそのノードを参照します。
SAMPLES>s ^Demo(1+2+3)="a value" SAMPLES>w ^Demo(3+3) a value SAMPLES>w ^Demo(03+03) a value SAMPLES>w ^Demo(03.0+03.0) a value SAMPLES>set x=6 SAMPLES>w ^Demo(x) a value -
Caché では、グローバル参照の合計の長さに制限を課しています。同様に、この制限によってあらゆる添え字の値の長さにも制限が課されます。詳細は、“グローバル参照の最大長” を参照してください。
上記の規則は、Caché でサポートしている照合のすべてに適用されます。“pre-ISM-6.1” など、互換性の理由から引き続き使用されている古い形式の照合については、添え字に対する規則上の制限が多くなっています。例えば、文字の添え字では先頭に制御文字を使用できず、整数の添え字に使用できる数字の桁数にも制限があります。
このような制限があることから、サポート対象の照合で使用している添え字が、Caché よりも前の形式の照合で有効に使用できる保証はありません。
グローバル・ノード
使用しているインストールで長い文字列を有効化していない限り、各グローバル・ノードには約 32 K の文字のテキストを含むことができます。長い文字列が有効である場合、この制限はさらに大きくなります。("Caché プログラミング入門ガイド" の “一般的なシステム制限” を参照してください。)
アプリケーションで、ノードは一般的に以下の構造タイプを含みます。
-
文字列、または数値データ。Caché の Unicode バージョンでは、文字列データに Unicode 本来の文字を使用できます。
-
特殊文字で区切られた複数のフィールドを持つ文字列。
^Data(10) = "Smith^John^Boston"ObjectScript の $PIECE 関数を使用して、このようなデータを個別の値に切り離すことができます。
-
Caché の $LIST 構造に含まれた複数のフィールド。$LIST 構造は、複数の長さのエンコード値を含む文字列です。専用の区切り文字は必要ありません。
-
NULL 文字列 ("")。添え字自身がデータとして使用される場合、データは実際のノードに格納されません。
-
ビット文字列。ビットマップ・インデックスの一部を格納するためにグローバルを使用する場合、ノードに格納される値はビット文字列です。ビット文字列は、論理的で、圧縮された一連の 1 と 0 の値を含む文字列です。$Bit 関数を使用して、ビット文字列を構築できます。
-
大規模な一連のデータの一部。例えば、オブジェクト・エンジンおよび SQL エンジンは、ストリーム (BLOB) を一連の 32 K シーケンシャル・ノードとしてグローバルに格納します。ストリーム・インタフェースにより、ストリームのユーザは、ストリームをこのように格納することを認識していません。
グローバルの照合
グローバル内で、ノードは照合 (ソート) 順序で格納されます。
アプリケーションは通常、添え字として使用する値に変換を適用して、ノードを格納する順序を制御します。例えば、SQL エンジンで文字列値に対するインデックスを生成するとき、すべての文字列値は大文字に変換され、先頭に空白が付加されます。これにより、インデックスでは大文字と小文字が区別されず、数値が文字列として格納されていても、テキストとして照合されるようになります。
グローバル参照の最大長
グローバル参照 (つまり、特定のグローバル・ノードやサブツリーへの参照) の合計の長さは、エンコード文字数で最長 511 文字です (入力文字数で考えると、511 文字より少ない場合があります)。
任意のグローバル参照のサイズを慎重に決定する場合は、以下のガイドラインを使用します。
-
グローバル名の場合、1 文字ごとに 1 を加算します。
-
純粋な数字の添え字の場合、1 桁、符号、または小数点ごとに、1 を加算します。
-
数値以外の文字を含む添え字の場合、1 文字ごとに、3 を加算します。
添え字が純粋な数字ではない場合、添え字の実際の長さは、文字列をエンコードするために使用される文字セットによって異なります。マルチバイトの文字は 3 バイトまでとすることができます。
ASCII 文字は 1 または 2 バイトとなる可能性があることに注意してください。照合で大文字と小文字を区別する場合、ASCII 文字は、文字に対して 1 バイト、および曖昧性解消のバイトに対して 1 バイトとすることができます。照合で大文字と小文字を区別しない場合、ASCII 文字は 1 バイトとなります。
-
添え字ごとに、1 を追加します。
これらの数の合計が 511 より大きくなった場合、その参照は長過ぎということになります。
制限は決まっているため、長い添え字名やグローバル名にする必要がある場合、多数の添え字レベルを避けることをお勧めします。反対に、複数の添え字レベルを使用している場合は、長いグローバル名や添え字を避けます。使用している文字セットを制御できない場合があるので、グローバル名や添え字は短くすることが有用となります。
特定の参照について懸念がある場合、最長となりそうなグローバル参照と同等の長さか、それより若干長いテスト・バージョンのグローバル参照を作成することをお勧めします。それらテストのデータにより、アプリケーション構築前に、名前付け規約の修正についてのヒントが得られます。
グローバルの物理構造
グローバルは、最適化された構造を使用して、物理ファイルに格納されます。このデータ構造を管理するコードも、Caché が起動するプラットフォームごとに最適化されています。この最適化により、グローバルの処理では高いスループット (単位時間あたりの処理能力)、高水準の並行処理 (同時アクセスの総数)、そして Caché メモリの有効利用が可能となり、性能に対するメンテナンス (頻繁に行われてきた再構築、再度のインデックス付けや圧縮作業など) も一切必要ありません。
グローバルの格納に使用する物理構造は完全にカプセル化されるため、アプリケーションはどのような状況でも、物理データ構造に注意する必要はありません。
グローバルは、ディスク上の一連のデータ・ブロックに格納されます。各ブロックのサイズ (通常 8 KB) は、物理データベースを生成するときに決まります。データに効率的なアクセスを提供するため、Caché は、ポインタ・ブロックを使用して関連したデータにリンクする、高性能な B ツリーに類似した構造を保持します。Caché はバッファ・プール (頻繁に参照されるブロックを収めたメモリ内キャッシュ) を保持し、ディスクからブロックを取得するために要する負荷を軽減します。
多くのデータベース技術でデータ・ストレージには B ツリーに類似した構造が使用されていますが、Caché は多くの面で他とは異なる独自性を持っています。この独自性には次のようなものがあります。
-
ストレージのメカニズムは、安全で利用しやすいインタフェースを通して公開されます。
-
添え字とデータは、ディスク・スペースと貴重なメモリ内キャッシュ・スペースを節約するために圧縮されます。
-
ストレージ・エンジンは、トランザクション処理操作向けに最適化されているので、挿入、更新、削除の高速処理が可能です。リレーショナル・システムとは異なり、パフォーマンスのリストアのときのインデックスやデータの再構築は一切必要ありません。
-
ストレージ・エンジンは、最適化により、できる限り多くの同時アクセスを可能にします。
-
効率よく変換するために、データを自動的にクラスタ化します。
グローバルの格納法
データ・ブロック内で、グローバルは順番に格納されます。添え字とデータの両方は、一緒に格納されます。独立したブロックに格納する大きなノード値 (長い文字列) に適用される特例もあります。この独立したブロックのポインタは、ノード添え字と共に格納されます。
例えば、以下の内容のグローバルがあるとします。
^Data(1999) = 100
^Data(1999,1) = "January"
^Data(1999,2) = "February"
^Data(2000) = 300
^Data(2000,1) = "January"
^Data(2000,2) = "February"このデータは、以下の例のような連続構造で、単独のデータ・ブロックに格納されます (実際の表現は一連のバイトです)。
Data(1999):100|1:January|2:February|2000:300|1:January|2:February|...
^Data に対する処理では、最小限のディスク処理ですべてのコンテンツを検索できます。
その他にも、挿入、更新、削除を効率化する方法があります。
グローバルの参照
グローバルは、特定の Caché データベースに格納します。適切にマッピングされている場合、グローバルの一部を別のデータベースに置くことも可能です。データベースは、現在のシステム、または Caché のネットワーク経由でアクセスできるリモート・システムに物理的に格納できます。データセットとは、Caché データベースを含むシステムとディレクトリを指します。ネットワーキングの詳細は、“分散データ管理ガイド” を参照してください。
ネームスペースとは、関連性のある情報を構成するデータセットとグローバル・マッピングの論理的な定義です。
単純グローバル参照は、現在選択されているネームスペースに適用します。ネームスペースを定義することで、ローカル・システムあるいはリモート・システム上のデータベースに物理的にアクセスできるようになります。各グローバルは、それぞれ異なる位置やデータセットにマップされます (データセットは、Caché データベースを含むシステムとディレクトリを参照します)。
例えば、以下の構文を使用して、現在マップされているネームスペース内のグローバル ORDER へ単純参照を生成します。
^ORDER
このセクションでは、以下の 2 つのトピックについて説明します。
グローバル・マッピングの設定
同じシステムあるいは異なるシステム上に存在するデータベースから別のデータベースにグローバルとルーチンをマップできます。これによって、さまざまな場所に存在するデータを、簡単に参照できるようになります。グローバルは、その全体でも一部でもマップできます。グローバルの一部 (または添え字) のマッピングは、添え字レベル・マッピング (SLM)と呼ばれます。グローバル添え字をマップできるので、データはディスクを簡単に行き来できます。
このタイプのマッピングを行うには、"Caché システム管理ガイド" の "Caché の構成" の章の "ネームスペースへのグローバル、ルーチン、およびパッケージ・マッピングの追加" のセクションを参照してください。
グローバル・マッピングは、階層的に適用されます。例えば、NSX ネームスペースに関連付けられた DBX データベースがある一方、このネームスペースでは、^x グローバルを DBY データベースに、^x(1) を DBZ データベースにそれぞれマッピングしているとします。この場合、^x グローバルの添え字が付いたあらゆる形式のうち、^x(1) 階層に属していないものは DBY にマッピングされ、^x(1) 階層に属するグローバルは DBZ にマッピングされます。以下の図は、この階層を示しています。
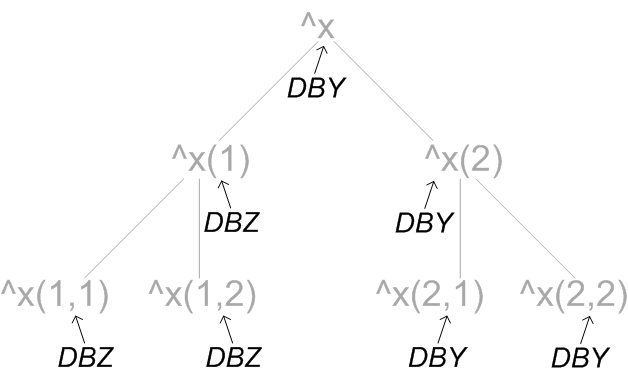
この図では、グローバルおよびその階層はグレーで表示され、これらのマッピング先のデータベースは黒で表示されています。
マッピング済みの添え字付きグローバルの一部を別のデータベースにマッピングすることも可能です。また、最初にグローバルがマッピングされていたデータベースにマッピング先を戻すことも可能です。前述の例で、^x(1,2) グローバルの追加のマッピング先を、元の DBY データベースに戻したとします。この場合は、以下のような状態になります。
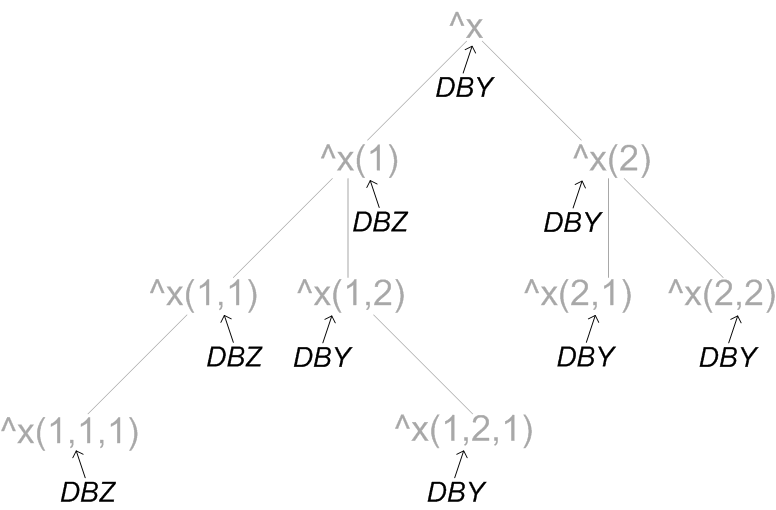
ここでも、グローバルおよびその階層はグレーで表示され、これらのマッピング先のデータベースは黒で表示されています。
あるネームスペースから別のネームスペースにグローバルをマップしておけば、そのグローバルが現在のネームスペースに存在するかのように、マップされたグローバルを ^ORDER や ^X(1) のように容易に参照できます。
添え字レベル・マッピングの範囲を構築する場合、文字列の添え字の機能は整数の添え字の場合と異なります。文字列による添え字の場合は、最初の文字で範囲が決まりますが、整数の範囲は数値で指定します。例えば、添え字範囲 ("A"):("C") には、AA だけでなく AC や ABCDEF も含まれます。一方、添え字範囲 (1):(2) には 11 は含まれません。
グローバルおよび添え字の独立した範囲の使用
それぞれのネームスペースのマッピングでは、グローバルまたは添え字の独立した範囲を参照する必要があります。範囲に重複があるとマッピング検証で検出され、マッピングはできません。例えば、管理ポータルを使用して既存のマッピングと重複する新しいマッピングを作成しようとしても、ポータルによってこの重複が拒否され、エラー・メッセージが表示されます。
ログの変更
ポータルを使用してマッピングを正常に変更すると、それも cconsole.log に記録されますが、失敗した変更は記録されません。Caché パラメータ (CPF) ファイルの手動編集でマッピングを設定しようとして失敗した場合は、cconsole.log に記録されます。CPF ファイルの編集に関する詳細は、"Caché パラメータ・ファイル・リファレンス" の “Caché パラメータ・ファイルの概要” の章の “アクティブな CPF ファイルの編集” を参照してください。
拡張グローバル参照
現在のネームスペース以外のネームスペースに格納されているグローバルの参照も可能です。これを拡張グローバル参照、または省略して拡張参照と呼びます。
拡張参照には以下の 2 つの形式があります。
-
明示的なネームスペース参照 — グローバル参照構文の中で、グローバルを格納するネームスペース名を指定します。
-
暗黙のネームスペース参照 — グローバル参照構文の中でディレクトリを指定し、さらに必要に応じてシステム名を指定します。この場合、物理データセット (ディレクトリとシステム) がグローバル参照の一部として割り当てられるため、グローバル・マッピングは適応されません。
明示的なネームスペースを優先的に使用します。 これにより、必要に応じて、アプリケーション・コードを変更せずに外部的に論理マッピングを再定義できます。
Caché は以下の 2 つの拡張参照形式をサポートします。
-
ブラケット構文 - 角括弧 ([ ]) で拡張参照を囲みます。
-
環境構文 - 垂直バー (| |) で拡張参照を囲みます。
拡張グローバル参照の例では、Windows のディレクトリ構造を使用しています。実用面では、このような参照の形式は、使用するオペレーティング・システムで決まります。
ブラケット構文
ブラケット構文を使用して、明示的あるいは暗黙のネームスペースで拡張グローバル参照を指定できます。
明示的なネームスペース
^[nspace]glob
暗黙ネームスペース
^[dir,sys]glob
明示的なネームスペース参照にある nspace は、現在、グローバル glob のマップ先にも複製先にもなっていない定義済みのネームスペースです。また、暗黙のネームスペース参照において、dir はディレクトリ (ディレクトリ名の最後には円記号 “\” を追加)、sys はシステム、glob はディレクトリ内のグローバルです。nspace または dir がキャレット (“^”) で指定されている場合、プロセス・プライベート・グローバルへの参照です。
ディレクトリとシステム名またはネームスペース名は、変数として指定しない限り引用符で囲みます。ディレクトリとシステムは共に暗黙のネームスペースを構成します。また、暗黙のネームスペースは以下のいずれかを参照できます。
-
指定されたシステムの指定ディレクトリ
-
参照でシステム名を指定していない場合、ローカル・システムで指定したディレクトリ。システム名を暗黙のネームスペース参照から削除する場合、ディレクトリ参照内に二重キャレット文字 (^^) を置き、削除したシステム名であることを示す必要があります。
以下はリモート・システムに暗黙のネームスペースを指定します。
["dir","sys"]
以下はローカル・システムに暗黙のネームスペースを指定します。
["^^dir"]
例えば、以下は SALES というマシンの C:\BUSINESS\ ディレクトリにあるグローバル ORDER にアクセスします。
SET x = ^["C:\BUSINESS\","SALES"]ORDER以下は、ローカル・マシンの C:\BUSINESS\ ディレクトリにあるグローバル ORDER にアクセスします。
SET x = ^["^^C:\BUSINESS\"]ORDERMARKETING として定義済みのネームスペースでグローバル ORDER にアクセスします。
SET x = ^["MARKETING"]ORDERプロセス・プライベート・グローバル ORDER にアクセスするには:
SET x = ^["^"]ORDERミラーリングされるデータベースを含む暗黙のネームスペース拡張参照を作成するときには、「:mirror:mirror_name:mirror_DB_name」の形式で、そのミラーリングされるデータベースのパスを使用できます。例えば、ミラー CORPMIR に含まれる mirdb1 というミラー・データベース名のデータベースを参照する場合は、以下に示すように暗黙の参照を作成できます。
["^^:mirror:CORPMIR:mirdb1"]
ミラーリングされるデータベースのパスは、ローカル・データベースとリモート・データベースの両方に使用できます。
環境構文
環境構文は以下のように定義されます。
^|"env"|global
"env" は、次の 5 つの形式のうちのいずれかです。
-
NULL 文字列 ("") — ローカル・システムの現在のネームスペース
-
"namespace" — global が現在マップされていない定義済みのネームスペース。ネームスペース名は、大文字と小文字を区別しません。namespace が "^" の特殊値である場合、これはプロセス・プライベート・グローバルとなります。
-
"^^dir" — 暗黙のネームスペースであり、既定のディレクトリはローカル・システムの指定ディレクトリです。dir の最後には円記号 (“\”) を追加します。
-
"^system^dir" — 暗黙のネームスペースであり、既定のディレクトリは指定リモート・システムの指定ディレクトリです。dir の最後には円記号 (“\”) を追加します。
-
省略 — "env" がまったくない場合、これはプロセス・プライベート・グローバルです。
ORDER にマッピングが定義されていない場合、以下の構文を使用し、現システムのネームスペースでグローバル ORDER にアクセスします。
SET x = ^|""|ORDERこれは、単純グローバル参照と同じです。
SET x = ^ORDERMARKETING として定義済みのネームスペースにマップされたグローバル ORDER にアクセスします。
SET x = ^|"MARKETING"|ORDER暗黙のネームスペースを使用して、ローカル・システムの C:\BUSINESS\ ディレクトリにあるグローバル ORDER にアクセスします。
SET x = ^|"^^C:\BUSINESS\"|ORDER暗黙のネームスペースを使用して、SALES というリモート・システムの C:\BUSINESS ディレクトリにあるグローバル ORDER にアクセスします。
SET x = ^|"^SALES^C:\BUSINESS\"|ORDERプロセス・プライベート・グローバル ORDER にアクセスするには:
SET x = ^||ORDER
SET x=^|"^"|ORDER