DeepSee キューブの統合 (非推奨フォーム)
この付録では、iKnow キューブと DeepSee キューブ間の統合で非推奨の古いフォームを使用する方法について説明します。以下のトピックについて説明します。
統合の新しいフォームの使用に関する詳細は、"DeepSee 上級モデリング・ガイド" の “構造化されていないデータのキューブでの使用” を参照してください。
あるいは、“iKnow KPI と DeepSee のダッシュボード” を参照してください。
概要
このセクションでは、iKnow キューブと DeepSee キューブ間の統合における非推奨の古いフォームの概要について説明します。
DeepSee は、iKnow と同じように Caché に組み込まれている分析エンジンおよびレポートのプラットフォームです。DeepSee の主な目的は、Zen ページに埋め込むことができるか、または DeepSee ユーザ・ポータル (DeepSee のユーザだけではなく、すべてのエンド・ユーザを対象にしたポータル) を経由してアクセスできる、インタラクティブなダッシュボードを作成可能にすることです。
背景
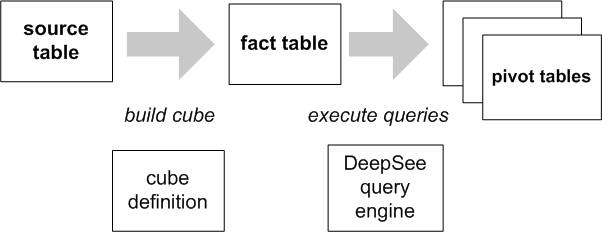
DeepSee キューブは、ドラッグ・アンド・ドロップ操作で DeepSee クエリを作成することが可能なデータ・モデルです。このクエリがピボット・テーブルです。作成したピボット・テーブルは、DeepSee ダッシュボードに表示できます。ダッシュボードが表示されると、クエリが実行されます。
各キューブは、ソース・テーブルに基づいています。キューブを構築するプロセスでは、ソース・テーブルと同じ数のレコードを持つファクト・テーブルが生成されます (モデルが一部のレコードを故意にスキップした場合は、レコード数がソース・テーブルより少なくなることもあります)。クエリはソース・テーブルではなくファクト・テーブルを使用します。DeepSee には、ファクト・テーブルとソース・テーブルの同期を保つための補完的なメカニズムが複数用意されています。
以下の図は、年齢および男女別に患者数と患者 1 人あたりが抱えるアレルギー数の平均値を表すピボット・テーブルの例を示しています。
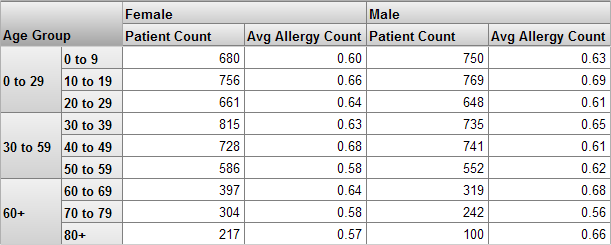
この例を参照しながら、DeepSee キューブの主要な用語について説明します。
-
レベルは、レコードをグループ化するために使用されます。この場合は、患者をグループに分けます。ファクト・テーブルの各レコードと同様に、ソース・テーブルの各レコードは、1 人の患者に対応します。
-
メジャーはピボット・テーブルの本文に表示される値で、つまるところはソース・データから取得された値に基づいています。指定されたコンテキストに対して、メジャーは該当するすべてのレコード値を集約し、これらを 1 つの値として表します (通常は合計します)。
例えば、メジャー Patient Count は患者数、メジャー Avg Allergy Count は患者 1 人あたりのアレルギー数の平均値です。
キューブでは、現在のコンテキストに関連付けられた最下位のデータを表示するための、詳細リストも定義できます。リストにアクセスするには、1 つ以上のセルを選択し、リスト・ボタンをクリックします (前の図には表示されていません)。すると DeepSee は、現在のコンテキストで使用されているすべてのレコードについて、選択されたフィールドをリストするテーブルを表示します。
キューブと iKnow ソースの関係
iKnow とキューブの統合によって、「キューブのソース・クラスの各レコードに 1 つの iKnow ソースが関連付けられている」と考えられます。つまり、キューブは iKnow ソースに関する追加の情報として機能します (または、iKnow ソースには、キューブのソース・クラスの各レコードに関連付けられた追加情報が含まれる、と言い換えることもできます)。
この目標は、可能であれば DeepSee と iKnow のフィルタを交換して使用できるようにすることです。
ユーティリティ・メソッドを使用して、以下のタスクを実行できます。
関連付けられた DeepSee キューブに対する iKnow ソース・メタデータ・フィールドの生成
iKnow データ・ソースへの参照を含むソース・クラスを DeepSee キューブが使用する場合は、そのキューブのレベルをこれらのソースの iKnow ソース・メタデータ・フィールドとして使用できます。つまり、iKnow クエリ内で DeepSee フィルタを使用できるようになります ("DeepSee 上級モデリング・ガイド" の “構造化されていないデータのキューブでの使用” で説明したとおり、DeepSee の KPI メカニズムを介してこれらのクエリにアクセスする場合を含みます)。
このセクションでは、キューブが定義および構築済みであることを前提とします。キューブを変更または再構築する必要はありません。
前提条件
キューブの iKnow ソース・メタデータ・フィールドを生成する前に、以下を行うことが必要です。
-
iKnow ソースをロードします。
これを行う際は、各ソースの外部 ID を、キューブのソース・クラスの特定レコードと容易に関連付けられることを確認してください。
以下に例を示します。
-
ファイル・リスタを使用している場合は、ファイル名が患者 ID と一致していることを確認します。
-
SQL リスタを使用している場合は、レコード ID が患者 ID と一致していることを確認します。
-
-
キューブのソース・クラスに、対応する iKnow ソースの外部 ID を値として持つプロパティが含まれていることを確認します。
例えば、このクラスには、先行する手順で確立された名前付け規約に従った値を持つ、計算されたプロパティを含めることができます。
Property DocumentId As %String [ Calculated ]; Method DocumentIdGet() As %String { quit ":FILE:c:\patient-data\patient"_..PatientNumber_".txt" }
キューブからのメタデータ・フィールドの生成
メタデータ・フィールドを生成するには、%iKnow.DeepSee.Utils の GenerateMDFieldsFromDSDims() メソッドを使用します。このメソッドには、以下のシグニチャがあります。
ClassMethod GenerateMDFieldsFromDSDims(domainId As %Integer,
cubeClassName As %String,
ByRef levels = 1,
extIdProperty = "",
killExistingMDFields As %Boolean = 0) As %Status
以下はその説明です。
-
domainId は、iKnow ドメインの 整数 ID です。
-
cubeClassName は、キューブ・クラスの名前です。
-
levels は、処理するレベルを制御します。この引数を省略すると、iKnow エンジンがサポートしないものを除き、すべてのレベルが処理されます。
この引数を指定する場合は、次の形式の多次元配列にする必要があります。
ノード 値 arrayname(level_name)。level_name は、レベルの完全な MDX 識別子を二重引用符で囲んで示します。例 : "[DocD].[H1].[Doctor]" 0 または 1 のうち、1 を指定すると、iKnow メタデータ・フィールドはビット文字列として生成されます。ビット文字列は、小さな数値のみが予想される場合に適しています。 -
extIdProperty は、前のサブセクションで追加したプロパティです。例 : DocumentId
より一般的には、extIdProperty は、指定されたドメインの iKnow ソースの外部 ID に値が等しい (キューブのソース・クラスの) プロパティです。
-
killExistingMDFields は、既存の iKnow メタデータ・フィールドを削除するかどうかを指定します。
iKnow の KPI と共に DeepSee フィルタを使用する方法
また、KPI とキューブの両方が同じ iKnow ドメインで関連付けられている場合は、このドメインに iKnow KPI を作成して、KPI で DeepSee フィルタを使用できます。
このメカニズムを使用するには、以下の手順に従います。
-
ダッシュボードのウィジェットで KPI を表示します。
-
DeepSee アナライザで、ピボット・テーブルを作成します。
-
同じダッシュボードに、ピボット・テーブルを表示するウィジェットを追加します。フィルタとして 1 つ以上のキューブ・レベルを使用するようにこのウィジェットを構成し、フィルタのターゲットを * (全ウィジェット) と指定します。
iKnow ドメインの DeepSee キューブの生成
このリリースでは、iKnow エンジンの結果から DeepSee キューブを生成するユーティリティの暫定版を提供しています。生成されたキューブを使用すると、エンティティ、エンティティの出現箇所、およびさまざまな方法でグループ化された一致結果を表示できます。DeepSee キューブでは、DeepSee アナライザでドラッグ・アンド・ドロップ操作によって分析と探索を実行できます。
これらの DeepSee キューブは、他の DeepSee キューブと同じように使用できます。つまり、アナライザでこれらを探索し、ピボット・テーブルを作成し、これらのピボット・テーブルを DeepSee ダッシュボードに追加できます。
このセクションでは、iKnow ドメインを考慮して DeepSee キューブを生成する方法を説明するほか、DeepSee キューブの使用方法について簡単に説明します。以下のトピックについて説明します。
既存の iKnow クエリを通して必要な結果を得ることができる場合は、生成されたキューブを使用して同じようなクエリを作成する代わりに、そのクエリを使用してください。iKnow クエリは、事前に計算された内部インデックスを使用するように最適化されており、その結果、より高速です。
キューブの生成
iKnow ドメインの DeepSee キューブを生成するには、%iKnow.DeepSee.Utils の GenerateSourceObjectAndCubes() メソッドを使用します。このメソッドには、以下のシグニチャがあります。
classmethod GenerateSourceObjectAndCubes(domainId,
packageName="User",
createCube=2,
overwriteExisting=0,
buildCubes=0) as %Status
以下はその説明です。
-
domainId は、iKnow ドメインの 整数 ID です。
-
packageName は、生成されたクラスを配置するパッケージです。
-
createCube は、生成するクラスを制御します。
-
createCube が 0 の場合は、キューブが基づくクラスがシステムによって生成およびコンパイルされますが、他のクラスは生成されません。DeepSee アーキテクトで DeepSee を手動で作成したい場合は、このオプションを使用できます。
これらのクラスは、iKnow データにアクセスするためのマッピングを定義します。
-
createCube が 1 の場合は、iKnow ソースを示すキューブも Caché によって生成およびコンパイルされます。
-
createCube が 2 の場合は、一意のエンティティを示すキューブに加え、エンティティの出現を示す別のキューブも Caché によって生成およびコンパイルされます。
-
createCube が 3 の場合は、一致結果を示すキューブも Caché によって生成およびコンパイルされます。
-
-
overwriteExisting は、既存のクラスを上書きするかどうかを指定します。
-
buildCubes は、生成されたキューブを構築するかどうかを指定します。createCube が 0 の場合、これは無効になります。
キューブの構築とは、キューブが使用する構造を生成するプロセスを示します。このプロセスにより、キューブを使用することが可能になります。
アナライザとキューブの概要
このセクションでは、アナライザと生成されたキューブについて簡単に説明します。アナライザにアクセスして生成されたキューブの 1 つを表示するには、以下の手順に従います。
-
[ホーム]、[DeepSee]、[アナライザ] をクリックします。
-
変更ボタン
 をクリックします。
をクリックします。 -
キューブ名をクリックします。
-
[OK] をクリックします。
例えば、エンティティ出現キューブは、ソース・ドキュメントでのエンティティの出現に関する情報を提供します。このキューブの名前は EntityOccurrences で終わります。このキューブを表示すると、ページの左の領域に、そのコンテンツが以下のように表示されます。
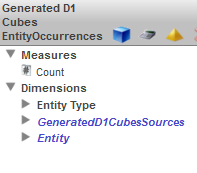
このキューブは、エンティティの出現をカウントする Count という 1 つのメジャーを定義します。既定では、このメジャーが使用されます。
[ディメンジョン] セクションには、3 つのディメンジョンが表示されます。GeneratedD1CubesSource と Entity は、Entity Type とは異なる方法で定義されているため、表示も異なります。このディメンジョンは、以下のように使用できます。
-
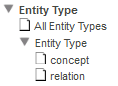
Entity Type — このディメンジョンを使用すると、エンティティの出現をエンティティ・タイプ別に分類できます。このフォルダとその中の Entity Type フォルダを展開すると、以下のように表示されます。
-
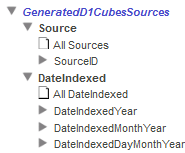
GeneratedD1CubesSource — このディメンジョンを使用すると、エンティティの出現をそれが属するソース・ドキュメント別に分類できます。このフォルダを展開すると、以下のように表示されます。
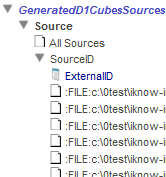
SourceID フォルダを展開すると、データに応じて以下のように表示されます。
-
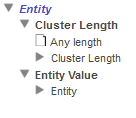
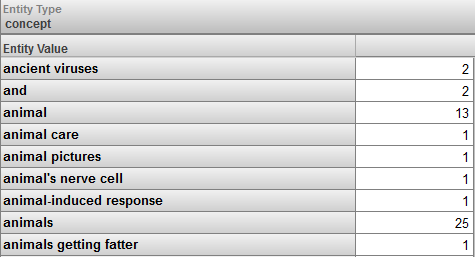
Entity — このディメンジョンを使用すると、エンティティの出現をエンティティ値別に分類できます。このフォルダとその中の最上位フォルダを展開すると、以下のように表示されます。
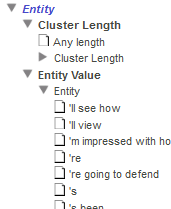
Entity フォルダを展開すると、データに応じて以下のように表示されます。
ページの右の領域は以下のようになります。
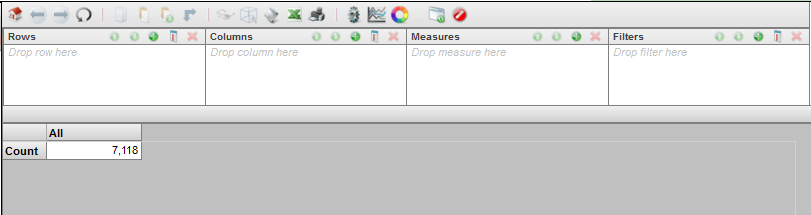
下部の領域は、シンプルなピボット・テーブルです。これは Count の合計値を表示します。この例では、ドメインの 7118 か所にエンティティが出現します。
上部の領域を使用してピボット・テーブルを作成できます。左の領域からこの領域に項目をドラッグ・アンド・ドロップすると、ピボット・テーブルが自動的に変更されます。例えば、Entity (内側の Entity フォルダ) を [行] ボックスにドラッグすると、以下のように表示されます。
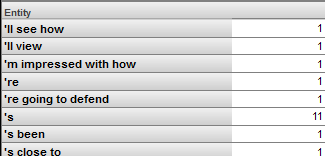
フィルタはまったく適用していないため、ピボット・テーブルには関係と概念の両方が表示されます。概念だけを表示するようにピボット・テーブルをフィルタするには、以下の手順に従います。
-
左側の [エンティティ・タイプ] ディメンジョンを展開します。
-
[概念] をドラッグして、右側の [フィルタ] ボックスにドロップします。
これにより、表示が即座に更新されます。
これで、以下のような表示になります。
EntityOccurrences キューブは、詳細なリストを定義します。リストにアクセスするには、1 つ以上のセルを選択し、リスト・ボタン  をクリックします (この例では、ancient viruses のセルをクリックしています)。すると、以下のように表示されます。
をクリックします (この例では、ancient viruses のセルをクリックしています)。すると、以下のように表示されます。

キューブの再構築
この iKnow ドメインのソースをさらに処理した後、クラスを再生成する必要はありませんが、DeepSee キューブを再構築することが必要です。また、キューブは特定の順序で再構築する必要があります。
-
ソース・キューブを再構築します。このキューブは名前が Sources で終わるキューブです。
-
任意の順序で他のキューブを再構築します。
キューブを再構築するには、アーキテクトでこれを開き、[再構築] をクリックします。
関連項目
-
Zen ページの詳細は、"Zen の使用法" を参照してください。
-
DeepSee ダッシュボードの作成に関する詳細は、"DeepSee ダッシュボードの作成" を参照してください。
-
アプリケーションからダッシュボードへのアクセスに関する詳細は、"DeepSee 実装ガイド" の “アプリケーションからダッシュボードへのアクセス” を参照してください。
-
ダッシュボード定義のクラスへのパッケージ化に関する詳細は、"DeepSee 実装ガイド" の “クラスへの DeepSee 要素のパッケージ化” を参照してください。
-
DeepSee ユーザ・ポータルおよびダッシュボードの詳細は、"DeepSee エンド・ユーザ・ガイド" を参照してください。
-
DeepSee アーキテクトの詳細は、"DeepSee モデルの作成" を参照してください。