Global Structure
This chapter describes the logical (programmatic) view of globals and provides an overview of how globals are physically stored on disk. Its sections are:
Logical Structure of Globals
A global is a named multidimensional array that is stored within a physical Caché database. Within an application, the mapping of globals to physical databases is based on the current namespace — a namespace provides a logical, unified view of one or more physical databases.
Topics related to the logical structure of globals are:
Global Naming Conventions and Limits
The name of a global specifies its purpose and use. There are two types of globals and a separate set of variables, called “process-private globals”:
-
A global — This is what might be called a standard global; typically, these are simply referred to as globals. It is a persistent, multidimensional array that resides in the current namespace.
-
An extended global reference — This is a global located in a namespace other than the current namespace.
-
A process-private global — This is an array variable that is only accessible to the process that created it.
The naming conventions for globals are:
-
A global name begins with a caret character (^) prefix. This caret distinguishes a global from a local variable.
-
The first character after the caret (^) prefix in a global name can be:
-
A letter or the percent character (%) — For standard globals only. For global names, a letter is defined as being an alphabetic character within the range of ASCII 65 through ASCII 255. If a global’s name begins with “%” (but not “%Z” or “%z”), then this global is for Caché system use. % globals are typically stored within either the CACHESYS or CACHELIB databases. For more details on the % character and InterSystems naming, see “Rules and Guidelines for Identifiers” in the Caché Programming Orientation Guide.
-
The vertical bar (|) or the left bracket ([) — For extended global references or process-private globals. The use depends on subsequent characters. See the examples that follow this list.
-
-
The other characters of a global name may be letters, numbers, or the period (.) character. The percent (%) character cannot be used, except as the first character of a global name. The period (.) character cannot be used as the last character of a global name.
-
A global name may be up to 31 characters long (exclusive of the caret character prefix). You can specify global names that are significantly longer, but Caché treats only the first 31 characters as significant.
-
Global names are case-sensitive.
-
Caché imposes a limit on the total length of a global reference, and this limit, in turn, imposes limits on the length of any subscript values. See “Maximum Length of a Global Reference” for details.
In the CACHESYS database, InterSystems reserves to itself all global names except those starting with “z”, “Z”, “%z”, and “%Z”. In all other databases, InterSystems reserves all global names starting with “ISC.” and “%ISC.”.
Sample Global Names and Their Uses
The following are examples of the various kinds of global names and how each is used:
-
^globalname — a standard global
-
^|"environment"|globalname — environment syntax for an extended global reference
-
^||globalname — a process-private global
-
^|"^"|globalname — a process-private global
-
^[namespace]globalname — bracket syntax for an explicit namespace in an extended global reference
-
^[directory,system]globalname — bracket syntax for an implied namespace in an extended global reference
-
^["^"]globalname — a process-private global
-
^["^",""]globalname — a process-private global
Global names can contain only valid identifier characters; by default, these are as specified above. However, your NLS (National Language Support) settings may define a different set of valid identifier characters. Global names cannot contain Unicode characters.
Thus, the following are all valid global names:
SET ^a="The quick "
SET ^A="brown fox "
SET ^A7="jumped over "
SET ^A.7="the lazy "
SET ^A1B2C3="dog's back."
WRITE ^a,^A,^A7,!,^A.7,^A1B2C3
KILL ^a,^A,^A7,^A.7,^A1B2C3 // keeps the database clean Introduction to Global Nodes and Subscripts
A global typically has multiple nodes, generally identified by a subscript or set of subscripts. For a basic example:
set ^Demo(1)="Cleopatra"This statement refers to the global node ^Demo(1), which is a node within the ^Demo global. This node is identified by one subscript.
For another example:
set ^Demo("subscript1","subscript2","subscript3")=12This statement refers to the global node ^Demo("subscript1","subscript2","subscript3"), which is another node within the same global. This node is identified by three subscripts.
For yet another example:
set ^Demo="hello world"This statement refers to the global node ^Demo, which does not use any subscripts.
The nodes of a global form a hierarchical structure. ObjectScript provides commands that take advantage of this structure. You can, for example, remove a node or remove a node and all its children. For a full discussion, see the next chapter.
The following sections provide details on the rules for subscripts and for global nodes.
Global Subscripts
Subscripts have the following rules:
-
Subscript values are case-sensitive.
-
A subscript value can be any ObjectScript expression, provided that the expression does not evaluate to the null string ("").
The value can include characters of all types, including blank spaces, non-printing characters, and (if your installation is a Unicode installation) Unicode characters. (Note that non-printing characters are less practical in subscript values.)
-
Before resolving a global reference, Caché evaluates each subscript in the same way it evaluates any other expression. In the following example, we set one node of the ^Demo global, and then we refer to that node in several equivalent ways:
SAMPLES>s ^Demo(1+2+3)="a value" SAMPLES>w ^Demo(3+3) a value SAMPLES>w ^Demo(03+03) a value SAMPLES>w ^Demo(03.0+03.0) a value SAMPLES>set x=6 SAMPLES>w ^Demo(x) a value -
Caché imposes a limit on the total length of a global reference, and this limit, in turn, imposes limits on the length of any subscript values. See “Maximum Length of a Global Reference” for details.
The preceding rules apply for all Caché supported collations. For older collations still in use for compatibility reasons, such as “pre-ISM-6.1”, the rules for subscripts are more restrictive. For example, character subscripts cannot have a control character as their initial character; and there are limitations on the number of digits that can be used in integer subscripts.
Because of restrictions such as these, there is no guarantee that subscripts used for supported collations will be valid in pre-Caché collations.
Global Nodes
Unless long strings are enabled for your installation, each global node can contain approximately 32K characters of text. If long strings are enabled, the limit is much larger. (See “General System Limits” in the Caché Programming Orientation Guide.)
Within applications, nodes typically contain the following types of structure:
-
String or numeric data. With a Unicode version of Caché, string data may contain native Unicode characters.
-
A string with multiple fields delimited by a special character:
^Data(10) = "Smith^John^Boston"You can use the ObjectScript $PIECE function to pull such data apart.
-
Multiple fields contained within a Caché $LIST structure. The $LIST structure is a string containing multiple length-encoded values. It requires no special delimiter characters.
-
A null string (""). In cases where the subscripts are themselves used as the data, no data is stored in the actual node.
-
A bitstring. In cases where a global is used to store part of a bitmap index, the value stored within a node is a bitstring. A bitstring is a string containing a logical, compressed set of 1 and 0 values. You can construct a bitstring using the $BIT functions.
-
Part of a larger set of data. For example, the object and SQL engines store streams (BLOBs) as a sequential series of 32K nodes within a global. By means of the stream interface, users of streams are unaware that streams are stored in this fashion.
Collation of Globals
Within a global, nodes are stored in a collated (sorted) order.
Applications typically control the order in which nodes are sorted by applying a conversion to values used as subscripts. For example, the SQL engine, when creating an index on string values, converts all string values to uppercase letters and prepends a space character to make sure that the index is both not case-sensitive and collates as text (even if numeric values are stored as strings).
Maximum Length of a Global Reference
The total length of a global reference — that is, the reference to a specific global node or subtree — is limited to 511 encoded characters (which may be fewer than 511 typed characters).
For a conservative determination of the size of a given global reference, use the following guidelines:
-
For the global name: add 1 for each character.
-
For a purely numeric subscript: add 1 for each digit, sign, or decimal point.
-
For a subscript that includes nonnumeric characters: add 3 for each character.
If a subscript is not purely numeric, the actual length of the subscript varies depending on the character set used to encode the string. A multibyte character can take up to 3 bytes.
Note that an ASCII character can take up 1 or 2 bytes. If the collation does case folding, an ASCII character can take 1 byte for the character and 1 byte for the disambiguation byte. If the collation does not perform case folding, an ASCII character takes 1 byte.
-
For each subscript, add 1.
If the sum of these numbers is greater than 511, the reference may be too long.
Because of the way that the limitation is determined, if you must have long subscript or global names, it is helpful to avoid a large number of subscript levels. Conversely, if you are using multiple subscript levels, avoid long global names and long subscripts. Because you may not be able to control the character set(s) you are using, it is useful to keep global names and subscripts shorter.
When there are doubts about particular references, it is useful to create test versions of global references that are of equivalent length to the longest expected global reference (or even a little longer). Data from these tests provides guidance on possible revisions to your naming conventions prior to building your application.
Physical Structure of Globals
Globals are stored within physical files using a highly optimized structure. The code that manages this data structure is also highly optimized for every platform that Caché runs on. These optimizations ensure that operations on globals have high throughput (number of operations per unit of time), high concurrency (total number of concurrent users), efficient use of cache memory, and require no ongoing performance-related maintenance (such as frequent rebuilding, re-indexing, or compaction).
The physical structure used to store globals is completely encapsulated; applications do not worry about physical data structure in any way.
Globals are stored on disk within a series of data blocks; the size of each block (typically 8KB) is determined when the physical database is created. To provide efficient access to data, Caché maintains a sophisticated B-tree-like structure that uses a set of pointer blocks to link together related data blocks. Caché maintains a buffer pool — an in-memory cache of frequently referenced blocks — to reduce the cost of fetching blocks from disk.
While many database technologies use B-tree-like structures for data storage, Caché is unique in many ways:
-
The storage mechanism is exposed via a safe, easy-to-use interface.
-
Subscripts and data are compressed to save disk space as well as valuable in-memory cache space.
-
The storage engine is optimized for transaction processing operations: inserts, updates, and deletes are all fast. Unlike relational systems, Caché never requires rebuilding indices or data in order to restore performance.
-
The storage engine is optimized for maximum concurrent access.
-
Data is automatically clustered for efficient retrieval.
How Globals Are Stored
Within data blocks, globals are stored sequentially. Both subscripts and data are stored together. There is a special case for large node values (long strings) which are stored within separate blocks. A pointer to this separate block is stored along with the node subscript.
For example, suppose you have a global with the following contents:
^Data(1999) = 100
^Data(1999,1) = "January"
^Data(1999,2) = "February"
^Data(2000) = 300
^Data(2000,1) = "January"
^Data(2000,2) = "February"Most likely, this data would be stored within a single data block with a contiguous structure similar to (the real representation is a series of bytes):
Data(1999):100|1:January|2:February|2000:300|1:January|2:February|...
An operation on ^Data can retrieve its entire contents with a minimum number of disk operations.
There are a number of additional techniques used to ensure that inserts, updates, and deletes are performed efficiently.
Referencing Globals
A global resides within a particular Caché database. Portions of a global can reside in different databases if appropriate mappings are used. A database can be physically located on the current system, or on a remote system accessed through Caché networking. The term dataset refers to the system and the directory that contain a Caché database. For further details on networking, see the “Distributed Data Management Guide”.
A namespace is a logical definition of the datasets and global mappings that together form a set of related information.
A simple global reference applies to the currently selected namespace. The namespace definition can cause this to physically access a database on the local system or a remote system. Different globals can be mapped to different locations or datasets (where a dataset refers to the system and the directory that contain a Caché database).
For example, to create a simple reference to the global ORDER in the namespace to which it currently has been mapped, use the following syntax:
^ORDER
This section describes two topics:
Setting Global Mappings
You can map globals and routines from one database to another on the same or different systems. This allows simple references to data which can exist anywhere and is the primary feature of a namespace. You can map whole globals or pieces of globals; mapping a piece of a global (or a subscript) is known as subscript-level mapping (SLM). Because you can map global subscripts, data can easily span disks.
To establish this type of mapping, see the “Add Global, Routine, and Package Mapping to a Namespace” section of the “Configuring Caché” chapter of the Caché System Administration Guide.
Global mapping is applied hierarchically. For example, if the NSX namespace has an associated DBX database, but maps the ^x global to the DBY database and ^x(1) to the DBZ database, then any subscripted form of the ^x global — except those that are part of the ^x(1) hierarchy — is mapped to DBY; those globals that are part of the ^x(1) hierarchy are mapped to DBZ. The following diagram illustrates this hierarchy:
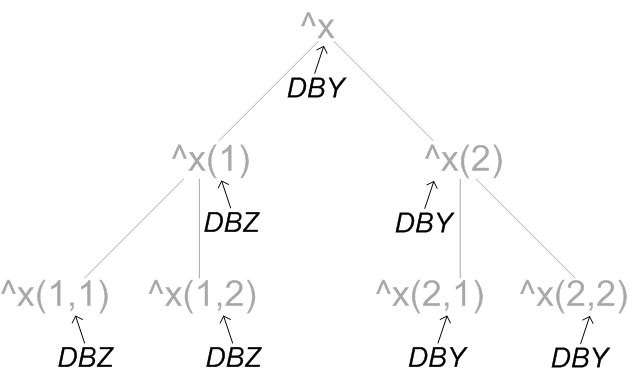
In this diagram, the globals and their hierarchy appear in gray, and the databases to which they are mapped appear in black.
It is also possible to map part of a mapped, subscripted global to another database, or even back to the database to which the initial global is mapped. Suppose that the previous example had the additional mapping of the ^x(1,2) global back to the DBY database. This would appear as follows:
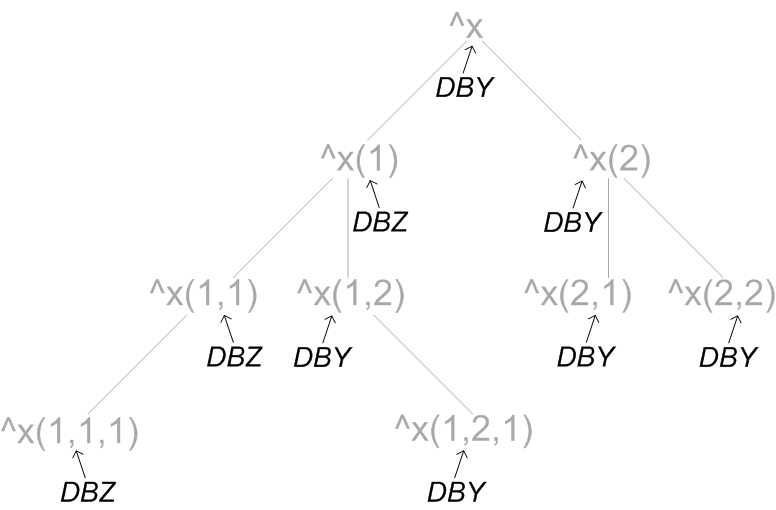
Again, the globals and their hierarchy appear in gray, and the databases to which they are mapped appear in black.
Once you have mapped a global from one namespace to another, you can reference the mapped global as if it were in the current namespace — with a simple reference, such as ^ORDER or ^X(1).
When establishing subscript-level mapping ranges, the behavior of string subscripts differs from that of integer subscripts. For strings, the first character determines the range, while the range for integers uses numeric values. For example, a subscript range of ("A"):("C") contains not only AA but also AC and ABCDEF; by contrast, a subscript range of (1):(2) does not contain 11.
Using Distinct Ranges of Globals and Subscripts
Each of a namespace’s mappings must refer to distinct ranges of globals or subscripts. Mapping validation prevents the establishment of any kind of overlap. For example, if you attempt to use the Management Portal to create a new mapping that overlaps with an existing mapping, the Portal prevents this from occurring and displays an error message.
Logging Changes
Successful changes to the mappings through the Portal are also logged in cconsole.log; unsuccessful changes are not logged. Any failed attempts to establish mappings by hand-editing the Caché parameter (CPF) file are logged in cconsole.log; for details on editing the CPF file, see the section “Editing the Active CPF File” in the “Introduction to the Caché Parameter File” chapter of the Caché Parameter File Reference.
Extended Global References
You can refer to a global located in a namespace other than the current namespace. This is known as an extended global reference or simply an extended reference.
There are two forms of extended references:
-
Explicit namespace reference — You specify the name of the namespace where the global is located as part of the syntax of the global reference.
-
Implied namespace reference — You specify the directory and, optionally, the system name as part of the syntax of the global reference. In this case, no global mappings apply, since the physical dataset (directory and system) is given as part of the global reference.
The use of explicit namespaces is preferred, because this allows for redefinition of logical mappings externally, as requirements change, without altering your application code.
Caché supports two forms of extended references:
-
Bracket syntax, which encloses the extended reference with square brackets ([ ]).
-
Environment syntax, which encloses the extended reference with vertical bars (| |).
The examples of extended globals references use the Windows directory structure. In practice, the form of such references is operating-system dependent.
Bracket Syntax
You can use bracket syntax to specify an extended global reference with either an explicit namespace or an implied namespace:
Explicit namespace:
^[nspace]glob
Implied namespace:
^[dir,sys]glob
In an explicit namespace reference, nspace is a defined namespace that the global glob has not currently been mapped or replicated to. In an implied namespace reference, dir is a directory (the name of which includes a trailing backslash: “\”), sys is a system, and glob is a global within that directory. If nspace or dir is specified as a carat (“^”), the reference is to a process-private global.
You must include quotation marks around the directory and system names or the namespace name unless you specify them as variables. The directory and system together comprise an implied namespace. An implied namespace can reference either:
-
The specified directory on the specified system.
-
The specified directory on your local system, if you do not specify a system name in the reference. If you omit the system name from an implied namespace reference, you must supply a double caret (^^) within the directory reference to indicate the omitted system name.
To specify an implied namespace on a remote system:
["dir","sys"]
To specify an implied namespace on the local system:
["^^dir"]
For example, to access the global ORDER in the C:\BUSINESS\ directory on a machine called SALES:
SET x = ^["C:\BUSINESS\","SALES"]ORDERTo access the global ORDER in the C:\BUSINESS\ directory on your local machine:
SET x = ^["^^C:\BUSINESS\"]ORDERTo access the global ORDER in the defined namespace MARKETING:
SET x = ^["MARKETING"]ORDERTo access the process-private global ORDER:
SET x = ^["^"]ORDERWhen creating an implied namespace extended reference involving a mirrored database, you can use its mirrored database path, in the format :mirror:mirror_name:mirror_DB_name. For example, when referring to the database with the mirror database name mirdb1 in the mirror CORPMIR, you could form an implied reference as follows:
["^^:mirror:CORPMIR:mirdb1"]
The mirrored database path can be used for both local and remote databases.
Environment Syntax
The environment syntax is defined as:
^|"env"|global
"env" can have one of five formats:
-
The null string ("") — The current namespace on the local system.
-
"namespace" — A defined namespace that global is not currently mapped to. Namespace names are not case-sensitive. If namespace has the special value of "^", it is a process-private global.
-
"^^dir" — An implied namespace whose default directory is the specified directory on your local system, where dir includes a trailing backslash (“\”).
-
"^system^dir" — An implied namespace whose default directory is the specified directory on the specified remote system, where dir includes a trailing backslash (“\”).
-
omitted — If there is no "env" at all, it is a process-private global.
To access the global ORDER in your current namespace on your current system, when no mapping has been defined for ORDER, use the following syntax:
SET x = ^|""|ORDERThis is the same as the simple global reference:
SET x = ^ORDERTo access the global ORDER mapped to the defined namespace MARKETING:
SET x = ^|"MARKETING"|ORDERYou can use an implied namespace to access the global ORDER in the directory C:\BUSINESS\ on your local system:
SET x = ^|"^^C:\BUSINESS\"|ORDERYou can use an implied namespace to access the global ORDER in the directory C:\BUSINESS on a remote system named SALES:
SET x = ^|"^SALES^C:\BUSINESS\"|ORDERTo access the process-private global ORDER:
SET x = ^||ORDER
SET x=^|"^"|ORDER