基本概念
この章では、DeepSee モデルで最も重要な概念であるキューブ、サブジェクト領域、およびそのコンテンツについて説明します。以下のトピックについて説明します。
モデルには、"DeepSee 上級モデリング・ガイド" で説明している多数の追加要素を含めることができます。オプションの完全な比較は、次の章を参照してください。
キューブの概要
キューブは、MDX の概念であり、アナライザで使用される MDX 要素を定義します。これらの要素によって、データ、具体的には特定のレコード (患者レコード、トランザクション・レコードなど) に対するクエリの実行方法が決定されます。レコードのセットは、キューブのソース・クラスによって決まります。
キューブには、以下のすべての定義を組み込むことができます。
-
レベル : レコードのグループ化を可能にする。
-
階層 : レベルを格納。
-
ディメンジョン : 階層を格納。
-
レベル・プロパティ : レベルのメンバに固有の値。
-
メジャー : レコードの集約値を表示。
-
リスト : ソース・データへのアクセスを可能にするクエリ。
-
計算メンバ : 他のメンバに基づくメンバ。
-
名前付きセット : メンバおよびその他の MDX 要素の再使用可能なセット。
これらの項目の多くについては、後続のセクションで説明します。名前付きセットの詳細は、"DeepSee での MDX の使用法" を参照してください。
キューブのソース・クラス
ほとんどの場合、キューブのソース・クラスは永続クラスです。
データ・コネクタもソース・クラスになる可能性があります。データ・コネクタは、%DeepSee.DataConnectorOpens in a new tab を拡張するクラスです。データ・コネクタは、任意の SQL クエリの結果を、キューブのソースとして使用可能なオブジェクトにマップします。データ・コネクタは、通常は外部の非 Caché データにアクセスしますが、データ・コネクタを使用して Caché に対する SQL クエリ (ビューに対する SQL クエリを含む) を指定することもできます。詳細は、"DeepSee 実装ガイド" の “データ・コネクタの定義と使用” を参照してください。
子コレクション・クラスもソース・クラスとして使用できます。
ディメンジョン、階層およびレベル
ここでは、ディメンジョン、階層およびレベルについて説明します。
レベルとメンバ
レベルはメンバで構成され、メンバはレコードのセットです。City レベルの場合、メンバ Juniper では、出身地が Juniper である患者が選択されます。逆に、キューブ内の各レコードは、1 つ以上のメンバに属します。
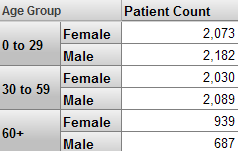
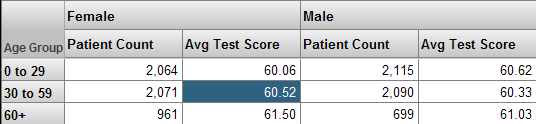
ピボット・テーブルの多くは、単純に 1 つ以上のレベルのメンバのデータを表示します。例えば、Age Group レベルには、メンバ 0 to 29、30 to 59、および 60+ があります。次のピボット・テーブルは、これらのメンバのデータを示しています。

別の例として、以下のピボット・テーブルは、Age Group と Gender レベルのデータを示しています (それぞれ 1 列目と 2 列目に示されています)。
個別のメンバをドラッグ・アンド・ドロップして行または列に使用できます。以下はその例です。
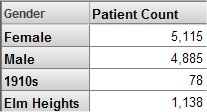
オプションの詳細は、"DeepSee アナライザの使用法" を参照してください。
メンバ名とキー
各メンバには、名前と内部キーの両方があります。コンパイラでは、同じレベル内にあっても、これらのいずれかが一意である必要はありません。状況によってはメンバ名に重複があることが正当な場合もありますが、メンバ・キーは重複しないように注意してください。
メンバ名の重複が正当である例として、同名異人を単一のメンバに結合しない場合を考えてみます。ユーザがメンバをドラッグ・アンド・ドロップすると、DeepSee で生成されるクエリでは名前でなくメンバ・キーが使用されるため、常に目的のメンバにアクセスできます。
ただし、メンバ・キーの重複があると、個別メンバの参照が不可能になります。メンバ・キーを指定すると、DeepSee はそのキーを持つ最初のメンバのみを返します。モデルのメンバ・キーは重複しないように確認することができ、またそうする必要があります。
重複メンバ名および重複メンバ・キーの発生するシナリオの詳細は、次の章の “メンバ・キーおよび名前の適切な定義” を参照してください。
ソース値
各レベルは、ソース値に基づいています。この値は、クラス・プロパティまたは ObjectScript 式のいずれかになります。例えば、Gender レベルは、患者の Gender プロパティに基づきます。別の例として、Age Group レベルは、年齢に応じて患者の Age プロパティを文字列 (0 to 29、30 to 59、または 60+) に変換する式に基づいています。
階層およびディメンジョン
DeepSee では、レベルは階層に属し、階層はディメンジョンに属します。階層とディメンジョンを使用することで、レベルで提供される機能を超えた機能が実現されます。
階層は、データを特に空間および時間を軸に組織化する、現実的で便利な方法です。例えば、市区町村を郵便番号でグループ化したり、郵便番号を地方でグループ化できます。
DeepSee での階層定義には、3 つの現実的な理由があります。
-
DeepSee には、階層を利用した最適化機能があります。例えば、年を期間の親として定義しているモデルで、期間 (年および月) を行または列として表示し、フィルタ処理して特定の年に絞り込むと、クエリの速度が向上します。
-
ピボット・テーブル内では、レベルのメンバをダブルクリックすると、DeepSee でドリルダウンが実行され、そのメンバに子メンバが存在する場合は、その子メンバが表示される、というように階層を使用できます。例えば、年をダブルクリックすると、DeepSee はその年に含まれる期間にドリルダウンします。詳細は、"DeepSee アナライザの使用法" を参照してください。
-
MDX には、階層で使用できる関数があります。例えば、特定の国の子郵便番号に対するクエリや、同じ国内の別の郵便番号に対するクエリを実行できます。
これらの関数は、手書きのクエリで使用できます。アナライザでは、ドラッグ・アンド・ドロップでこのようなクエリを作成できません。
ディメンジョンには、レコードを類似の方法で組織化する 1 つ以上の親子階層があります。例えば、アレルギーに関連する複数の階層を 1 つのディメンジョンに包含できます。2 つの異なる階層間、またはある階層のレベルと別の階層のレベルとの間に、形式化されたリレーションシップはありません。ディメンジョンの実際的な用途は、ディメンジョンに格納されるレベル、特に All レベルの既定の動作を定義することです。これについては次のサブセクションで説明します。
All レベルと All メンバ
各ディメンジョンでは、そのディメンジョンの全階層に表示される All レベルという特殊な任意のレベルを定義できます。このレベルを定義した場合、このレベルには、All メンバという、キューブ内のすべてのレコードに対応するメンバ 1 つが格納されます。
例えば、AgeD ディメンジョンに、下図に示すようなレベルで構成される 1 つの階層が組み込まれます。

特定のディメンジョンについて、All メンバがその論理名と表示名と共に存在しているかどうかを指定します。このディメンジョン内の All メンバは All Patients と命名されています。
リスト・ベースのレベル
DeepSee では、他の多くの BI ツールと異なり、レベルのベースにリスト値を使用できます。例えば、1 人の患者に複数の診断が存在する場合があります。Diagnoses レベルで患者を診断別にグループ化します。以下はその例です。
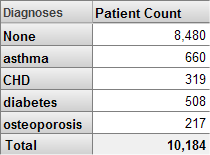
リスト・ベースのレベルでは、特定のソース・レコードが複数のメンバに属する場合があります。ここに示すピボット・テーブルでは、一部の患者が複数回含まれています。
関連項目
“ディメンジョン、階層およびレベルの定義” の章を参照してください。
プロパティ
各レベルで、任意の数のプロパティを定義できます。レベルにプロパティが設定されていると、そのレベルのメンバそれぞれにそのプロパティ値が存在します。その他のレベルにはそのプロパティの値が存在しません。
Patients サンプルで、City レベルにプロパティ Population と Principal Export が含まれているとします。
各プロパティは、ソース値に基づきます。この値は、クラス・プロパティまたは ObjectScript 式のいずれかです。City レベルでは、プロパティ Population と Principal Export は、直接クラス・プロパティに基づいています。
クエリでは、メジャーを使用する場合とほとんど同様に、プロパティを使用できます。例えば、アナライザではプロパティを列として使用できます (この例では 2 つのプロパティを示しています)。
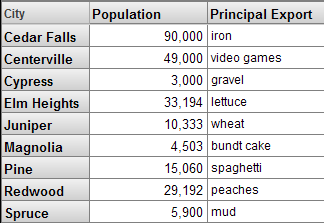
ただし、メジャーとは異なり、プロパティは集約できません。プロパティは、属するレベル以外のすべてのレベルで NULL になります。
“プロパティの定義” の章を参照してください。
メジャー
キューブは、ピボット・テーブルのデータ・セルに集約値を示すメジャーも定義します。
各メジャーは、ソース値に基づきます。これは、クラス・プロパティまたは ObjectScript 式のいずれかです。例えば、Avg Test Score メジャーは、患者の TestScore プロパティに基づきます。
メジャーの定義には、集約関数も組み込まれ、これによってそのメジャーの値の集約方法が指定されます。関数には、SUM および AVG が含まれます。
例えば、次のピボット・テーブルは、Patient Count メジャーと Avg Test Score メジャーを示しています。Patient Count メジャーは、任意のコンテキストで使用される患者をカウントし、Avg Test Score メジャーは、任意のコンテキストで使用される患者のテスト・スコアの平均値を示します。このピボット・テーブルは、Age Group レベルのメンバに関する、これらのメジャーの値を示します。
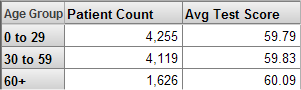
“メジャーの定義” を参照してください。
リスト
キューブには、リストも含めることができます。各リストは名前を持ち、ユーザがそのリストを要求したときに表示されるフィールドを指定します。以下に例を示します。

表示されるレコードは、ユーザがリストを要求する際のコンテキストによって異なります。
キューブでリストを定義しない場合にユーザがリストを要求すると、アナライザでは以下のメッセージが表示されます。
Error #5001: %ExecuteListing: this cube does not support drill through
“リストの定義” の章を参照してください。
以下のことも可能です。
-
キューブでは個別のリスト・フィールドを定義できます。ユーザはアナライザでこれらのリスト・フィールドを使用してカスタム・リストを作成できます。“リスト・フィールドの定義” の章を参照してください。
-
キューブ定義の外部で (アーキテクトにアクセスすることなく) リストを定義できます 。“リスト・グループの定義” の章を参照してください。
計算メンバ
計算メンバは、他のメンバに基づきます。以下の 2 種類の計算メンバを定義できます。
-
計算メジャーは、他のメジャーに基づくメジャーです(MDX では、各メジャーは Measures ディメンジョンのメンバです)。
例えば、あるメジャーを、第 2 のメジャーをさらに第 3 のメジャーで除算した結果として定義することができます。
計算メジャーという語句は、MDX で標準的な語句ではありませんが、このドキュメントでは簡潔にするためにこれを使用します。
-
一般に、非メジャーの計算メンバは、他の非メジャーのメンバと結合します。他の非メジャーのメンバと同様、この計算メンバはファクト・テーブル内のレコードのグループです。
計算メンバは、基にするメンバの後で評価されます。
キューブ定義では、いずれの種類の計算メンバも作成でき、アナライザでは、いずれの種類の計算メンバも追加作成できます。
計算メジャー
他のメジャーに基づいて新規メジャーを定義することは大変便利です。例えば、Patients サンプルの場合、Test Score メジャーを Count メジャーで除算した結果として Avg Test Score メジャーを定義することができます。次のようなピボット・テーブルがあるとします。
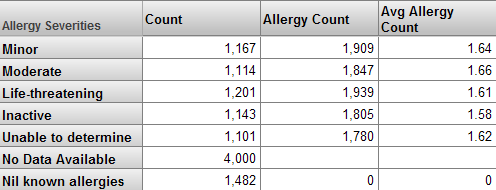
このピボット・テーブルを実行すると、DeepSee は、Allergy Severities レベルのメンバごとに Count および Test Score メジャーの値を決定します。この章の後続のセクションで、DeepSee がこれをどのように実行するかを説明します。その後、各メンバの Avg Test Score 値を求めるため、Test Score 値が Count 値で除算されます。
非メジャーの計算メンバ
非メジャーの計算メンバは、MDX 集約関数を使用して他の非メジャーのメンバと結合します。最も便利な関数は %OR です。
非メジャー・メンバのそれぞれが一連のレコードを参照することを忘れないでください。複数のメンバを新規メンバに結合する際は、そのコンポーネント・メンバが使用するすべてのレコードを参照するメンバを作成します。
簡単な例として、ColorD ディメンジョンを考えてみます。このディメンジョンには、メンバ Red、Yellow、および Blue が組み込まれています。これらのメンバは、赤、黄、青をそれぞれ好む患者にアクセスします。%OR を使用して、3 つの患者グループすべてにアクセスする新規メンバを 1 つ作成することができます。
以下はその例です。
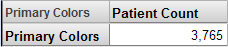
関連項目
“計算メンバの定義” の章を参照してください。
サブジェクト領域
サブジェクト領域は、オプションによる項目名のオーバーライドを持つサブキューブです。サブジェクト領域を定義すると、複数のキューブを構築することなく、より小さなデータ・セットに焦点を当てることができます。サブジェクト領域では、以下の操作を実行できます。
-
サブジェクト領域で使用可能なデータを制限するフィルタを指定します。フィルタの詳細は、次のセクションを参照してください。
このフィルタはハードコードすることも、プログラムによって指定することもできます。これは、例えばユーザの $roles に基づいてこれを指定できることを意味します。
-
キューブに定義されている要素を非表示にし、これらのサブセットがアナライザで表示されるようにします。
-
表示する要素に新しい名前、キャプション、および説明を定義します。
-
サブジェクト領域の既定のリストを指定します。
-
キューブで定義されたリストを再定義または非表示にします。
-
新規リストを定義します。
これで、キューブの使用が可能な場所と同じすべての場所でこのサブジェクト領域を使用できます。例えば、このサブジェクト領域をアナライザで使用して、この領域を対象とする MDX クエリをシェルで、または API を使用して実行できます。
“サブジェクト領域の定義” の章を参照してください。
フィルタ
BI アプリケーションでは、ピボット・テーブルおよびその他の場所でデータのフィルタ処理が可能であることが非常に重要です。ここでは、DeepSee のフィルタ・メカニズムとアプリケーションでの使用方法について説明します。
フィルタ・メカニズム
DeepSee には、データのフィルタ処理にメンバ・ベース・フィルタとメジャー・ベース・フィルタという 2 つの簡単な方法が用意されています。これらを組み合わせてより複雑なフィルタを作成することもできます。これは特に MDX クエリを直接作成する際に使用できます。
メンバ・ベース・フィルタ
メンバはレコードのセットです。最も単純なメンバ・ベース・フィルタでは、メンバを使用して、ピボット・テーブルをフィルタ処理します (例えば、このセクションで後述するように他のコンテキストを使用できます)。つまり、ピボット・テーブルはそのメンバに属するレコードのみにアクセスすることになります。
例えば、次のようなピボット・テーブルがアナライザで表示されるとします。
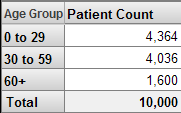
Age Group レベルの 0 to 29 メンバを使用するフィルタを適用するとします。フィルタ適用後のピボット・テーブルは次のようになります。
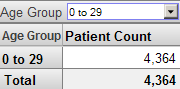
アナライザには、NULL の行と列を表示するオプションがあります。NULL 行を表示すると、ピボット・テーブルは次のようになります。
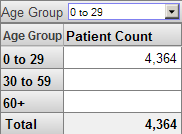
どのピボット・テーブルでも同じフィルタを使用できます。例えば、フィルタ処理されていない次のようなピボット・テーブルがあるとします。
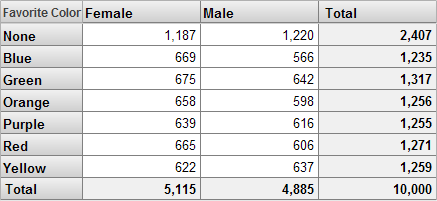
見出しには示されていませんが、このピボット・テーブルには、Patient Count メジャーが表示されます。このピボット・テーブルに前と同様にフィルタを適用すると、次のように表示されます。
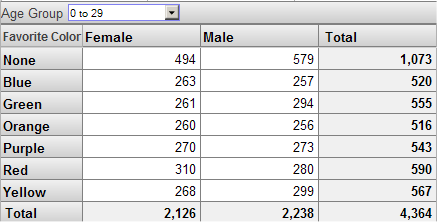
いずれの場合も、合計レコード数は同じであることに注意してください。どちらの場合も、0 to 29 メンバに属する患者にのみアクセスしています。
また、1 つのフィルタで複数のメンバをまとめて使用することも、異なるレベルのメンバを参照する複数のフィルタを結合することもできます。また、含めるメンバを選択するのではなく、除外するメンバを選択することもできます。
メンバ・ベース・フィルタは作成が容易でかつ強力であるため、フィルタでの使用専用のレベルを作成するだけの価値があります。
メジャー・ベース・フィルタ
DeepSee では、検索可能メジャーがサポートされます。このメジャーを使用すると、ソース・レコード自体のレベルで値を評価するフィルタを適用できます。
Patients サンプルに対して、受診回数が 10 回以上の患者のみにアクセスするフィルタを設定できます。このフィルタをピボット・テーブルで使用すると、以下のようになります。
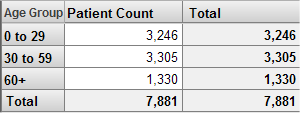
同じフィルタを別のピボット・テーブルで使用すると、以下のようになります。
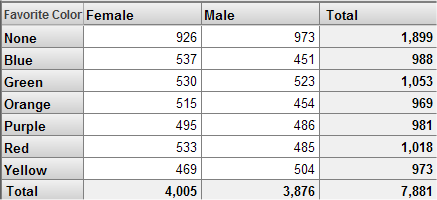
いずれの場合も、ピボット・テーブルでは受診回数が 10 回以上の患者のみが使用されるため、患者の合計数は同じです。
検索可能メジャーにはテキスト値が含まれることもあります。このようなメジャーでは、=、<、>、および LIKE 演算子を使用してレコードをフィルタ処理できます。
より複雑なフィルタ
メンバ・ベース・フィルタとメジャー・ベース・フィルタを結合して、より複雑なフィルタも作成できます。以下は、アナライザで作成したフィルタの例です。
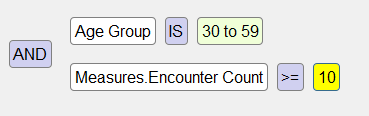
内部的には、クエリでは AND や OR が使用されるのではなく、MDX 構文が使用されます。DeepSee フィルタはすべて MDX 構文を使用します。
MDX 関数を使用するフィルタも作成できます。以下はその例です。
-
FILTER 関数は、メジャー・ベースのフィルタが使用する最下位レベルの値ではなく、メジャーの集約値を使用します。例えば、これを使用して、患者数が 1000 未満の市区町村に属する患者をフィルタで除外することができます。
アナライザでは、行または列に対する Levels オプションでこの関数が内部的に使用されています。
-
EXCEPT 関数は、特定のメンバの削除に使用できます。選択したメンバを除外するメンバ・ベース・フィルタを作成する際に、DeepSee ではこの関数が使用されます。
DeepSee MDX には、このほかにも、SET 演算を実行する関数が多数用意されています。
-
TOPCOUNT およびその他の関数は、ランキングに基づいてメンバにアクセスします。
MDX の概要およびオプションの概要は、"DeepSee での MDX の使用法" を参照してください。"DeepSee MDX リファレンス" も参照してください。
フィルタの使用
ピボット・テーブルの定義時には、フィルタ方法を指定できます。ただし実際は、ピボット・テーブルの管理が困難になるため、フィルタの異なる類似した複数のピボット・テーブルを作成することは推奨されません。この代わりに、以下のツールのいずれかまたはすべてを使用できます。
-
アナライザで、名前付きフィルタを定義し、それを複数のピボット・テーブルで使用できます。名前付きフィルタは、アナライザでキューブまたはサブジェクト領域のコンテンツと共に使用できます (次の項目を参照してください)。
-
アーキテクトでは、ベース・キューブのフィルタ適用済みビューであるサブジェクト領域を定義できます。この定義後にピボット・テーブルを作成し、キューブ自体ではなくサブジェクト領域から開始します。これらのピボット・テーブルは、ピボット・テーブル自体に固有のフィルタに加え、サブジェクト領域フィルタによって常にフィルタ処理されます。
サブジェクト領域では、ハードコードされたフィルタを指定したり、コールバック・メソッドをカスタマイズして実行時にフィルタを (例えば、$roles などの値に基づくように) 指定できます。
-
ユーザ・ポータルでは、ダッシュボードの作成時にフィルタ・コントロールを組み込むことができます (これは単純なメンバ・ベース・フィルタの場合にのみ適用されます)。その後、ユーザは包含または除外する 1 つ以上のメンバを選択できます。
フィルタは常に累積的です。
DeepSee におけるファクト・テーブルの構築および使用方法
キューブのコンパイル時に、DeepSee は、ファクト・テーブルと関連テーブルを生成します。キューブの構築時に、DeepSee は、これらのテーブルに値を入力し、インデックスを生成します。実行時に DeepSee はこれらのテーブルを使用します。ここでは、このプロセスについて説明しています。ここでは、以下のトピックについて説明します。
DeepSee は、サブジェクト領域に対するテーブルを生成しません。サブジェクト領域は、サブジェクト領域の基となるキューブに対して生成されたテーブルを使用します。
ファクト・テーブルの構造
一般にファクト・テーブルには、ベース・テーブルのレコードごとに 1 つのレコードが存在します。この行がファクトです。ファクトには、レベルおよびメジャーごとに、それぞれ 1 つのフィールドが含まれます。以下は、部分的な例です。
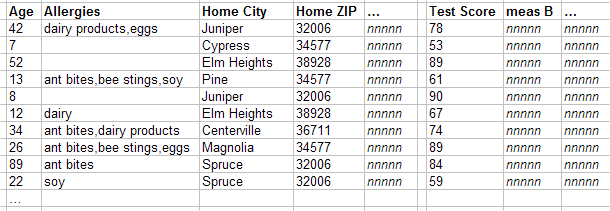
指定されたレベルのフィールドには、値が含まれていない場合もあれば、値が 1 つ、または複数含まれている場合もあります。個別値はそれぞれ、このレベルのメンバに対応します。任意のメジャーに対するフィールドには NULL 値、または単一値が含まれます。
DeepSee はこのファクト・テーブルを構築するときに、対応するインデックスも生成します。
ファクト・テーブルには、階層およびディメンジョンに関する情報は含まれません。ファクト・テーブルでは、レベル間のリレーションシップに関係なく、各レベルが同様に処理されます。ファクト・テーブルには各レベルに列が 1 つ含まれ、その列には各ソース・レコードに適用される 1 つ以上の値が含まれます。
既定で、ファクト・テーブルには、ベース・テーブルと同じ数の行が存在します。スタジオでキューブ・クラスを編集する際は、OnProcessFact() コールバックをオーバーライドできます。これにより、ベース・テーブルの選択行を無視できます。このようにした場合、ファクト・テーブルの行がベース・テーブルより少なくなります。
ファクト・テーブルへのデータ入力
キューブの構築時に、システムはベース・テーブルのレコードを繰り返し処理します。各レコードに対して以下の処理が実行されます。
-
各レベルの定義を調査し、0 個、1 個または複数の値を取得します。
この手順では、システムによって、レコードの分類方法が決定されます。
-
各メジャーの定義を調査し、0 個、または 1 個の値を取得します。
その後、このデータがファクト・テーブルの対応する行に書き込まれ、インデックスが適切に更新されます。
レベルに対する値の決定
各レベルは、ソース・プロパティ、またはソース式として指定されます。ソース式の大部分は指定のレコードに対して単一の値を返しますが、タイプがリストのレベルの場合、その値は複数の値の Caché のリストです。
ベース・テーブル内の特定のレコードについて、システムは構築時にそのプロパティまたは式を評価し、対応する値をファクト・テーブルに格納し、インデックスを適宜更新します。
例えば、Age Bucket レベルを、0-9、10-19、20-29 などの文字列のいずれか 1 つを返す式として定義します。返される値は、患者の年齢によって異なります。システムは返された値をファクト・テーブルの Age Bucket レベルに対応するフィールドに書き込みます。
別の例の場合、Allergy レベルは患者の複数のアレルギーのリストです。
メジャーに対する値の決定
DeepSee はファクト・テーブルを構築するときに、メジャーの値も決定して格納します。各メジャーは、ソース・プロパティ、または ObjectScript ソース式として指定されます。
ベース・テーブルの指定の行について、システムはメジャーの定義を確認および評価し、値があれば、その値を適切なメジャー・フィールドに格納します。
例えば、Test Score メジャーは、患者の TestScore プロパティに基づいています。
プロパティに対する値の決定
DeepSee がファクト・テーブルを構築するとき、プロパティに対する値も決定しますが、この値をファクト・テーブルには格納しません。ファクト・テーブル以外に、システムは各レベルのテーブルも生成します (一部の例外があります。付録 “ファクト・テーブルおよびディメンジョン・テーブルの詳細” を参照)。システムは、ファクト・テーブルを構築するとき、適切なディメンジョンのテーブルにプロパティの値を格納します。
ファクト・テーブルの使用法
次のようなピボット・テーブルがあるとします。
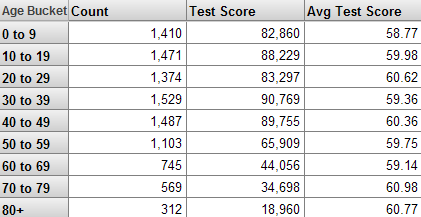
最初の列には Age Bucket レベルのメンバの名前が表示されます。最初のデータ列には Patient Count メジャー、2 番目の列には Test Score メジャー、最後の列には Avg Test Score メジャーが表示されます。Avg Test Score メジャーは計算メンバです。
これらの値は、次のようにして決定されます。
-
最初の行は、Age Bucket レベルの 0-9 メンバを参照しています。システムでは、インデックスを使用して、ファクト・テーブル内の関連する患者 (ここでは赤でハイライト表示) をすべて検出します。
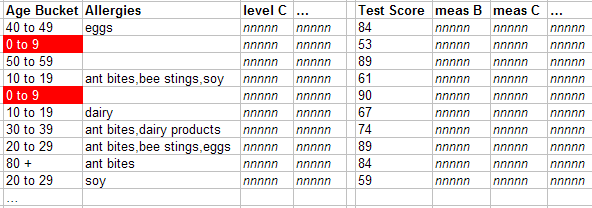
-
ピボット・テーブルの Patient Count 列には、特定のコンテキストで使用される患者数が表示されます。
この列の最初のセルでは、0-9 メンバに対して検出されたファクト・テーブル内のレコードの数がカウントされます。
-
ピボット・テーブルの Test Score 列には、特定のコンテキストにおける患者の累積テスト・スコアが表示されます。
この列の最初のセルに対して、DeepSee はまず、0-9 メンバに対して検出されたファクト・テーブルで Test Score の値を検索します。
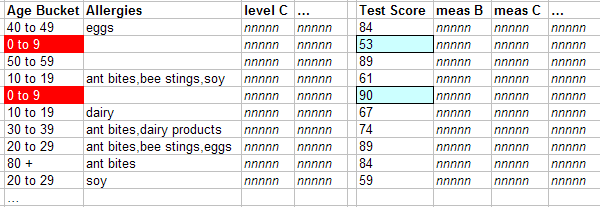
次に、これらの数値を集計します。この例では加算します。
-
ピボット・テーブルの Average Test Score 列には、特定のコンテキストにおける患者のテスト・スコアの平均値が表示されます。
Avg Test Score メジャーは計算メンバで、Test Score を Patient Count で除算して算出されます。
結果セットのすべてのセルについて、この手順を繰り返します。
DeepSee におけるリストの生成方法
ここでは、キューブで定義されたリストをシステムで使用する方法について説明します。
ピボット・テーブル内で、ユーザは 1 つ以上のセルを選択します。
次に、ユーザがリスト・ボタン  をクリックすると、リストが表示されます。このリストには、選択したセルに関連付けられた最下位レベルのレコードの値が示されます (このセルに作用するすべてのフィルタも反映されます)。
をクリックすると、リストが表示されます。このリストには、選択したセルに関連付けられた最下位レベルのレコードの値が示されます (このセルに作用するすべてのフィルタも反映されます)。
この表示を生成するために、システムでは以下の処理が行われます。
-
選択したセルで使用されたファクトに対応するソース ID 値のセットを含む一時リスト・テーブルが作成されます。
-
リストの定義と共にこのリスト・テーブルを使用する SQL クエリが生成されます。
-
この SQL クエリが実行され、結果が表示されます。
キューブには複数のリストを含めることができます (用途の異なる複数のフィールドを表示するため)。アナライザでピボット・テーブルを作成する際には、そのピボット・テーブルで使用するリストを指定できます。
リスト・クエリは実行時に実行され、ファクト・テーブルではなくソース・データを使用します。このため、ファクト・テーブルが完全に最新でない場合でも、リストではファクト・テーブルの表示とは異なるレコード・セットを表示することができます。