インデックスの定義と構築
この章では、テーブル内のフィールドの値にインデックスを定義し、構築する方法を説明します。ここでは、以下のトピックについて説明します。
インデックスの定義:
インデックスに対する操作の実行:
この章では、インデックスの定義方法と構築方法について説明します。どのフィールドにインデックスを生成するかについて、および定義されたインデックスの効率性を分析する方法については説明していません。どのフィールドにインデックスを生成すると特定のクエリのパフォーマンスが最適化されるかについては、“インデックスの対象” を参照してください。現在のネームスペース内のすべてのクエリに対するインデックス使用を分析するツールについては、“インデックス使用の分析” を参照してください。
概要
インデックスとは、Caché がクエリや他の操作の最適化に使用できる、永続クラスにより管理される構造のことです。
インデックスは、テーブル内のフィールドの値に対して定義することも、クラス内の対応するプロパティに対して定義することもできます (また、インデックスは複数のフィールド/プロパティを組み合わせた値に対して定義することもできます)。SQL フィールドとテーブルの構文、またはクラス・プロパティ構文を使用して定義されているかどうかに関係なく、同じインデックスが作成されます。特定のタイプのフィールド (プロパティ) が定義されていると、Caché はインデックスを自動的に定義します。データを格納するフィールドや、データを確実に派生できるフィールドに、追加のインデックスを定義できます。Caché は、いくつかのタイプのインデックスを提供します。同じフィールド (プロパティ) に対して複数のインデックスを定義して、目的が異なるさまざまなタイプのインデックスを提供することができます。
Caché は、データベースに対してデータの挿入、更新、または削除の操作が実行される場合はいつでも、SQL フィールドとテーブルの構文またはクラス・プロパティ構文を使用しているかどうかに関係なく、既定ではインデックスを生成して維持します。この既定はデータへの変更を迅速に実行するためにオーバーライドできます (%NOINDEX キーワードを使用)。その後で、個別の操作として対応するインデックスを構築または再構築します。インデックスは、テーブルにデータを移入する前に定義できます。さらに、既にデータが移入されているテーブルにインデックスを定義して、それから別の操作としてインデックスを生成 (構築) することもできます。
Caché は、SQL クエリを作成、実行するときに、利用可能なインデックスを活用します。既定では、クエリのパフォーマンスを最適化するために使用するインデックスを選択します。必要に応じて、特定のクエリまたはすべてのクエリに 1 つ以上のインデックスが使用されないようにするために、この既定はオーバーライドできます。インデックス使用の最適化の詳細は、このドキュメントの “クエリ・パフォーマンスの最適化” の章の "インデックスの使用" のセクションを参照してください。
インデックスの属性
各インデックスは、(そのクラスまたはテーブル内で) 一意の名前を持ちます。この名前は、(レポート、インデックス構築、インデックス削除など) データベース管理に使用します。インデックス名では大文字と小文字が区別されません。1 つのクラスまたはテーブル内に、大文字小文字のみが異なる名前が付いた 2 つのインデックスを作成することはできません。
インデックス・タイプは 2 つのインデックス・クラス・キーワード、Type および Extent により定義されます。Caché で使用可能なインデックスのタイプは以下のとおりです。
-
標準インデックス (Type = index) — インデックス値と、値を含む行の RowId を関連付ける永続配列です。ビットマップ・インデックス、ビットスライス・インデックス、またはエクステント・インデックスとして明示的に定義されていないインデックスは、すべて標準インデックスです。
-
ビットマップ・インデックス (Type = bitmap) — 指定されたインデックス値に対応する一連のオブジェクト ID 値を表すために一連のビット文字列を使用する特殊な種類のインデックスです。Caché には、ビットマップ・インデックス用のパフォーマンス最適化機能が数多く用意されています。
-
ビットスライス・インデックス (Type = bitslice) — 合計や値域条件など、特定の式について非常に高速な評価を可能にする特殊な種類のインデックスです。ビットスライス・インデックスは、特定の SQL クエリで自動的に使用されます。
-
エクステント・インデックス — エクステント内のすべてのオブジェクトのインデックスです。詳細は、"Caché クラス定義リファレンス" の "Extent" インデックス・キーワードのページを参照してください。
1 つのテーブル (クラス) のためのインデックスの最大数は 400 です。
ストレージ・タイプとインデックス
ここで説明するインデックス機能は、永続クラスに保存されたデータに適用されます。
Caché SQL は、Caché の既定のストレージ構造 %CacheStorage (CacheStorage にマップされたクラス) を使用して保存したデータに対応するインデックス機能をサポートしています。
また、Caché SQL は %CacheSQLStorage (CacheSQLStorageにマップされたクラス) を使用して保存したデータに対応するインデックス機能もサポートしています。CacheSQLStorage にマップされたクラスのインデックスは、機能インデックス・タイプを使用することで定義できます。このインデックスは、既定のストレージを使用するクラスのインデックスと同じ方法で定義しますが、以下の特別な考慮事項が付随します。
-
このクラスでは、IdKey 機能インデックスを定義する必要があります (システムによる自動的な割り当てがない場合)。
-
この機能インデックスは、INDEX として定義する必要があります。
詳細は %Library.FunctionalIndexOpens in a new tab を参照してください。
%CacheStorageOpens in a new tab および %CacheSQLStorageOpens in a new tab クラス・メソッドは直接呼び出さないでください。その代わりに、%PersistentOpens in a new tab クラス・メソッドと、この章で説明する操作を使用してインデックス機能を呼び出すようにします。
自動定義されたインデックス
テーブルを定義するときに、特定のインデックスが自動的に定義されます。以下のインデックスは、テーブルの定義時に自動的に生成され、テーブル・データの追加時または変更時に移入されます。以下の定義について説明します。
-
テーブルを定義すると、ID フィールド (RowID) にインデックスを作成する IdKey Data/Master マップが生成されます。
-
主キーを定義すると、指定された主キー名を使用して対応するインデックスが生成され、主キー・フィールド (1 つまたは複数) にインデックスが付けられます。
-
UNIQUE フィールドを定義すると、Caché によって、tablenameUNIQUE# という名前で UNIQUE フィールドごとにインデックスが生成されます (ここで、# は 1 から始まる連続する整数です)。
-
UNIQUE 制約を定義すると、指定された名前で UNIQUE 制約ごとにインデックスが生成され、一意の値を共に定義するフィールドにインデックスが付けられます。
これらのインデックスは、管理ポータルの SQL スキーマ・インタフェースを使用して表示できます。
既定では、RowID フィールドに IdKey インデックスが生成されます。IDENTITY フィールドを定義しても、インデックスは生成されません。ただし、IDENTITY フィールドを定義して、そのフィールドを主キーにすると、Caché は IDENTITY フィールドに IdKey インデックスを定義して主キー・インデックスにします。以下に例を示します。
CREATE TABLE Sample.MyStudents (
FirstName VARCHAR(12),
LastName VARCHAR(12),
StudentID IDENTITY,
CONSTRAINT StudentPK PRIMARY KEY (StudentID) )同様に、IDENTITY フィールドを定義して、そのフィールドに UNIQUE 制約を適用すると、Caché は IDENTITY フィールドに明示的に IdKey/Unique インデックスを定義します。以下に例を示します。
CREATE TABLE Sample.MyStudents (
FirstName VARCHAR(12),
LastName VARCHAR(12),
StudentID IDENTITY,
CONSTRAINT StudentU UNIQUE (StudentID) )こうした IDENTITY インデックスの作成処理は、明示的に定義された IdKey インデックスが存在しないことと、テーブルにデータが格納されていない場合にのみ実行されます。
ビットマップ・エクステント・インデックス
ビットマップ・エクステント・インデックスは、テーブルの特定のフィールドではなく、テーブルの行のビットマップ・インデックスです。ビットマップ・エクステント・インデックスでは、各ビットは連続した RowID の整数値を表し、各ビットの値は対応する行が存在しているかどうかを示します。Caché SQL はこのインデックスを使用して、テーブル内のレコード (行) 数を返す COUNT(*) のパフォーマンスを改善します。テーブルには最大 1 つのビットマップ・エクステント・インデックスを指定できます。複数のビットマップ・エクステント・インデックスを作成しようとすると、SQLCODE -400 エラーが発生し、%msg ERROR #5445: Multiple Extent indices defined: DDLBEIndex というメッセージが表示されます。
Caché 2015.2 以降では、CREATE TABLE を使用して定義されたすべてのテーブルでは、自動的にビットマップ・エクステント・インデックスが定義されます。この自動的に生成されたインデックスには、インデックス名 DDLBEIndex および SQL マップ名 %%DDLBEIndex が割り当てられます。クラスとして定義されたテーブルには、$ClassName のインデックス名と SQL マップ名で定義されたビットマップ・エクステント・インデックスを指定できます。
BITMAPEXTENT キーワードを指定した CREATE INDEX コマンドを使用して、テーブルにビットマップ・エクステント・インデックスを追加したり、自動的に生成されたビットマップ・エクステント・インデックスの名前を変更したりできます。詳細は、"CREATE INDEX" を参照してください。
多数の DELETE 操作が実行されるテーブルでは、ビットマップ・エクステント・インデックス用のストレージは徐々に効率が低下する可能性があります。%SYS.Maint.BitmapOpens in a new tab ユーティリティ・メソッドは、ビットマップ・インデックスおよびビットスライス・インデックスと同様にビットマップ・エクステント・インデックスを圧縮します。詳細は、“ビットマップ・インデックスの維持” を参照してください。
%BuildIndices() メソッドを呼び出したときに、%BuildIndices() の pIndexList 引数が指定されていない (すべての定義済みインデックスを構築する) 場合、pIndexList にビットマップ・エクステント・インデックスが名前で指定されている場合、または pIndexList に定義済みのビットマップ・インデックスが指定されている場合、このメソッドは既存のビットマップ・エクステント・インデックスを構築します。“プログラミングによるインデックスの構築” を参照してください。
インデックスの定義
インデックスを定義するには、以下の 2 つの方法があります。
-
クラス定義を使用したインデックスの定義。内容は以下のとおりです。
クラス定義を使用したインデックスの定義
スタジオでは、新規インデックス・ウィザードを使用するか、クラス定義のテキストを編集することで、クラス定義にインデックス定義を追加できます。インデックスは、1 つ以上のインデックス・プロパティ式で定義され、必要に応じて 1 つ以上のオプションのインデックス・キーワードが続きます。以下の形式をとります。
INDEX index_name ON index_property_expression_list [index_keyword_list];
以下はその説明です。
-
index_name は、有効な識別子です。
-
index_property_expression_list は、インデックスの基準となる 1 つ以上のコンマ区切りのプロパティ式のリストです。
-
index_keyword_list は、角括弧で囲まれた、インデックス・キーワードのコンマ区切りリストです (オプション)。ビットマップ・インデックスまたはビットスライス・インデックスに、インデックスの Type を指定するために使用します。また、Unique インデックス、IdKey インデックス、または PrimaryKey インデックスを指定する場合にも使用します。(IdKey インデックスまたは PrimaryKey インデックスは、定義上、Unique インデックスでもあります)。インデックス・キーワードの完全なリストについては、"Caché クラス定義リファレンス" を参照してください。
index_property_expression_list 引数は、1 つ以上のインデックス・プロパティ式で構成されています。インデックス・プロパティ式の構成要素は以下のとおりです。
-
特定のプロパティの名前 (必要に応じて修飾)。プロパティを修飾する必要がある場合は、その名前は PackageName.PropertyName のような形式で表示されます。修飾が不要な場合は、その名前の形式は単に PropertyName になります。
-
(ELEMENTS) 式または (KEYS) 式。これは、コレクションのサブ値に対するインデックス作成手段となります。インデックス・プロパティがコレクションでない場合、ユーザは BuildValueArray() メソッドを使用して、キーと要素を格納する配列を生成できます。キーと要素の詳細は、“コレクションのインデックス作成” のセクションを参照してください。
-
オプションの照合式。この式は、照合名と、必要に応じてそれに続く 1 つ以上のコンマ区切りの照合パラメータのリストで構成されます。インデックス照合は、Unique インデックス、IdKey インデックス、または PrimaryKey インデックスには指定できません。Unique または PrimaryKey インデックスの照合は、インデックスを生成するプロパティ (フィールド) から取得します。IdKey インデックスの照合は、常に EXACT になります。有効な照合名のリストについては、"Caché SQL の使用法" の “照合” の章にある “照合タイプ” のセクションを参照してください。
例えば、以下のクラス定義は、2 つのプロパティとそれぞれのプロパティに基づくインデックスを定義しています。
Class MyApp.Student Extends %Persistent [DdlAllowed]
{
Property Name As %String;
Property GPA As %Float;
Index NameIDX On Name;
Index GPAIDX On GPA;
}より複雑なインデックス定義は以下のようになります。
Index Index1 On (Property1 As SQLUPPER(77), Property2 AS EXACT);インデックスを付けることができるプロパティ
インデックスを付けることができるのは、以下のようなプロパティのみです。
-
データベースに格納されているプロパティ
-
格納されているプロパティから確実に派生できるプロパティ
確実に派生できる (格納されていない) プロパティでは、SQLComputed キーワードを True に定義する必要があります。SQLComputeCode によって指定されるコードは、プロパティの値を派生させるための唯一の方法でなければならず、プロパティを直接設定することはできません。
Transient として定義されており、かつ Calculated として定義されていない単純な (非コレクション) プロパティのケースなど、派生したプロパティの値を直接設定することが可能な場合、プロパティの値を直接設定すると、SQLComputeCode で定義されている計算がオーバーライドされ、格納されているプロパティから値を確実に派生させることはできません。このようなタイプの派生プロパティは、"非決定性" と呼ばれます (Calculated キーワードは、実際には、インスタンス・メモリが割り当てられていないことを意味します)。一般的には、インデックスを付けることができるのは、Calculated および SQLComputed として定義されている派生プロパティのみです。ただし、派生コレクションには例外があります。それは、派生し (SQLComputed)、Transient であり (格納されていない)、かつ Calculated として定義されていない (つまり、インスタンス・メモリがない) コレクションにはインデックスを付けることができるということです。
IdKey インデックスによって使用されるどのプロパティの値においても、そのプロパティが永続クラスのインスタンスへの有効な参照でない限り、連続する 2 つの垂直バー (||) は使用しないでください。この制限は、Caché SQL の内部メカニズムで必要とされています。IdKey プロパティ で || を使用すると、予測できない動作を起こす場合があります。
複数のプロパティのインデックス
2 つ以上のプロパティ (フィールド) の組み合わせに対し、インデックスを定義できます。以下のように、クラス定義の中のインデックス定義の On 節を使用して、プロパティのリストを指定します。
Class MyApp.Employee Extends %Persistent [DdlAllowed]
{
Property Name As %String;
Property Salary As %Integer;
Property State As %String(MAXLEN=2);
Index MainIDX On(State,Salary);
}複数のプロパティに対するインデックスは、以下のように、フィールド値の組み合わせを使用したクエリを実行する場合に便利です。
SELECT Name,State,Salary
FROM Employee
ORDER BY State,Salaryインデックス照合
Unique インデックス、PrimaryKey インデックス、または IdKey インデックスには、照合タイプを指定できません。その他のタイプのインデックスの場合、オプションで、インデックス定義で指定した各プロパティに照合タイプを指定できます。インデックスが適用される場合、インデックスの照合タイプは、プロパティ (フィールド) の照合タイプと一致している必要があります。
-
インデックス定義に、明示的に指定されたプロパティの照合が含まれている場合、インデックスはその照合を使用します。
-
インデックス定義に、明示的に指定されたプロパティの照合が含まれていない場合、インデックスはプロパティ定義で明示的に指定された照合を使用します。
-
プロパティ定義に、明示的に指定された照合が含まれていない場合、インデックスはプロパティのデータ型の既定の照合を使用します。
例えば、Name プロパティが文字列として定義されていると、そのプロパティの既定は SQLUPPER 照合になります。Name に対するインデックスを定義すると、そのプロパティの照合が既定で取得され、そのインデックスも SQLUPPER を使用して定義されます。プロパティの照合とインデックスの照合が一致します。
ただし、異なる照合を適用する比較の場合 (例えば、WHERE %EXACT(Name)=%EXACT(:invar))、この使用法でのプロパティの照合タイプは、インデックスの照合タイプと一致しなくなります。プロパティ比較の照合タイプとインデックスの照合タイプの間に不一致があると、インデックスが使用されなくなる可能性があります。そのため、この場合は、Name プロパティのインデックスを照合 EXACT で定義することをお勧めします。JOIN 文の ON 節で照合タイプを指定すると (例えば、FROM Table1 LEFT JOIN Table2 ON %EXACT(Table1.Name) = %EXACT(Table2.Name))、ここで指定したプロパティの照合タイプとインデックスの照合タイプとの間の不一致が原因になり、Caché がインデックスを使用しなくなる可能性があります。
インデックスとプロパティとの間での照合の一致を制御するルールは以下のとおりです。
-
照合タイプが一致する場合は、常にインデックスが最大限使用されます。
-
照合タイプが不一致で、プロパティが EXACT 照合で指定されており (前述の説明を参照)、インデックスが別の照合を持っている場合は、インデックスが使用できるようにはなりますが、インデックス使用の効果は照合タイプが一致しているときよりも低下します。
-
照合タイプが不一致で、プロパティの照合が EXACT ではなく、プロパティの照合がインデックスの照合と一致しない場合は、インデックスが使用されなくなります。
インデックス定義でプロパティの照合を明示的に指定するには、以下の構文を使用します。
Index IndexName On PropertyName As CollationName;
以下はその説明です。
-
IndexName は、インデックスの名前です。
-
PropertyName はインデックスが付けられているプロパティです。
-
CollationName はインデックスに使用されている照合タイプです。
以下はその例です。
Index NameIDX On Name As Exact;異なるプロパティは、異なる照合タイプを持つことができます。例えば、以下の例では、F1 プロパティは SQLUPPER 照合を使用する一方で、F2 は EXACT 照合を使用します。
Index Index1 On (F1 As SQLUPPER, F2 As EXACT);推奨される照合タイプのリストについては、"Caché SQL の使用法" の “照合” の章にある “照合タイプ” のセクションを参照してください。
Unique、PrimaryKey、または IdKey として指定されたインデックスには、インデックス照合を指定できません。このインデックスの照合は、プロパティの照合から取得されます。
インデックスでの Unique、PrimaryKey、IdKey キーワードの使用
SQL では普通のことですが、Caché では一意キーと主キーの概念をサポートしています。また、Caché には ID キーを定義する機能もあります。ID キーとは、クラスのインスタンス (テーブルの行) に対して一意のレコード ID となるものです。これらの機能は、以下に示す Unique、PrimaryKey、IdKey の各キーワードを使用して実装されます。
-
Unique — インデックスのプロパティ・リストに含まれているプロパティに対する UNIQUE 制約を定義します。そのため、このプロパティ (フィールド) で一意のデータ値のみがインデックス化できるようになります。一意性は、プロパティの照合に基づいて判断されます。例えば、プロパティの照合が EXACT の場合、大文字/小文字の異なる値は一意になります。プロパティの照合が SQLUPPER の場合は、大文字/小文字が異なる値は一意にはなりません。しかし、未定義のプロパティに対してインデックスの一意性はチェックされないことに注意してください。SQL 標準に従い、未定義のプロパティは常に一意として扱われます。
-
PrimaryKey — インデックスのプロパティ・リストに含まれているプロパティに対する PRIMARY KEY 制約を定義します。
-
IdKey — 一意の制約を定義し、インスタンス (行) の一意の ID を定義するために使用するプロパティを指定します。IdKey は、常に EXACT 照合を持ちます (データ型が文字列でも同じ照合になります)。
Note:すべてのクラス/テーブルには ID キーがあります。ID キーが (IdKey インデックスなどで) 明示的に定義されていない場合は、ID キー値が自動的に生成されます。
このようなキーワードの構文を表示すると、以下の例のようになります。
Class MyApp.SampleTable Extends %Persistent [DdlAllowed]
{
Property Prop1 As %String;
Property Prop2 As %String;
Property Prop3 As %String;
Index Prop1IDX on Prop1 [ Unique ];
Index Prop2IDX on Prop2 [ PrimaryKey ];
Index Prop3IDX on Prop3 [ IdKey ];
}IdKey、PrimaryKey、Unique の各キーワードは、標準インデックスで使用する場合にのみ有効です。ビットマップ・インデックスやビットスライス・インデックスで使用することはできません。
また、以下のように、IdKey と PrimaryKey の両方のキーワードを組み合わせて指定する構文も有効です。
Index IDPKIDX on Prop4 [ IdKey, PrimaryKey ];この構文では、IDPKIDX インデックスがクラス (テーブル) の IdKey であり、かつその主キーであることを指定します。これらのキーワードを上記以外の形で組み合わせた場合は、すべて冗長になります。
インデックスがこれらのキーワードのいずれかを使用して定義されていると、そのインデックスに関連付けられたプロパティに特定の値が指定されているクラスのインスタンスを開くことができるメソッドがあります。詳細は、“インデックス・キーによるインスタンスのオープン” のセクションを参照してください。
IdKey キーワードの詳細は、"Caché クラス定義リファレンス" の "IdKey" のページを参照してください。PrimaryKey キーワードの詳細は、"Caché クラス定義リファレンス" の "PrimaryKey" のページを参照してください。Unique キーワードの詳細は、"Caché クラス定義リファレンス" の "Unique" のページを参照してください。
iFind インデックスの定義
iFind インデックスは、次に示すようにテーブル・クラス定義内で定義します。
Class Sample.TextBooks Extends %Persistent [DdlAllowed]
{
Property BookName As %String;
Property SampleText As %String(MAXLEN=5000);
Index NameIDX On BookName [ IdKey ];
Index ifindIDXB On (SampleText) As %iFind.Index.Basic;
Index ifindIDXS On (SampleText) As %iFind.Index.Semantic;
Index ifindIDXA On (SampleText) As %iFind.Index.Analytic;
}詳細は、"iFind 検索ツール" を参照してください。
インデックスを使用したデータの保存
インデックスの Data キーワードを使用して、1 つ以上のデータ値のコピーをインデックスに保存するように指定できます。
Class Sample.Person Extends %Persistent [DdlAllowed]
{
Property Name As %String;
Property SSN As %String(MAXLEN=20);
Index NameIDX On Name [Data = Name];
}この場合、インデックス NameIDX には、さまざまな Name 値の照合値 (大文字) によって添え字が付けられます。Name の実際の (照合されていない) 値のコピーは、インデックスに保存されています。これらのコピーは、SQL を使用して Sample.PersonOpens in a new tab テーブルが変更された場合や、オブジェクトを使用して対応する Sample.PersonOpens in a new tab クラスまたはそのインスタンスが変更された場合も維持されます。
選択 (多数の行から数行を選ぶ) や抽出 (多数の列から数列を返す) を頻繁に実行する場合、インデックスにデータのコピーを維持する機能は大変便利です。
例えば、Sample.PersonOpens in a new tab テーブルに対する以下のクエリがあります。
SELECT Name FROM Sample.Person ORDER BY NameSQL エンジンは、テーブルのマスタ・データを読まずに、NameIDX を読むだけですべての要求を満たすことができます。
ビットマップ・インデックスでは、値を保存できません。
NULL のインデックス付け
インデックスが付けられたフィールドのデータに NULL (データが存在しない) が含まれている場合、対応するインデックスでは、このフィールドがインデックス NULL 標識を使用して表されます。既定では、インデックス NULL 標識の値は -1E14 です。インデックス NULL 標識を使用することで、NULL 以外のすべての値の前に NULL 値を照合するようになります。
%Library.BigIntOpens in a new tab データ型は、-1E14 より小さい負の数値を格納する可能性があります。既定では、%BigInt のインデックス NULL 標識値は -1E14 であるため、既存の %BigInt のインデックスとの互換性が保たれます。インデックスが作成された %BigInt データの値に極端に小さい負の数値が含まれる可能性がある場合は、特定のフィールドのインデックス NULL 指標の値をプロパティ定義の一部として変更できます。この場合、以下の例に示すように、INDEXNULLMARKER プロパティ・パラメータを使用します。
Property ExtremeNums As %Library.BigInt(INDEXNULLMARKER = "-1E19");
また、インデックス NULL 指標の既定値は、データ型のクラス定義で変更することもできます。詳細は、%Library.DataTypeOpens in a new tab を参照してください。
コレクションのインデックス作成
インデックス・プロパティ式にはトークンが含まれています。
プロパティにインデックスが付けられる場合、インデックスに配置される値は照合プロパティ値全体です。コレクションの場合は、プロパティ名に (ELEMENTS) または (KEYS) を追加することで、コレクションの要素値とキー値に対応するインデックス・プロパティを定義することができます。(ELEMENTS) と (KEYS) を使用すると、1 つのプロパティ値から複数の値を生成して、それらの各サブ値にインデックスを作成するように指定できます。プロパティがコレクションの場合、ELEMENTS トークンはコレクションの要素を値で参照し、KEYS トークンは位置で要素を参照します。1 つのインデックス定義に ELEMENTS と KEYS の両方が存在する場合、インデックスのキー値には、キーおよび関連付けられた要素の値が含まれます。
例えば、Sample.PersonOpens in a new tab クラスの FavoriteColors プロパティに基づくインデックスがあるとします。このプロパティのコレクション内の項目のインデックスのうち、最も単純な形式は以下のいずれかになります。
INDEX fcIDX1 ON (FavoriteColors(ELEMENTS));または
INDEX fcIDX2 ON (FavoriteColors(KEYS));ここで、FavoriteColor(ELEMENTS) は、FavoriteColors プロパティの要素を参照します。それは、このプロパティがコレクションであるためです。一般的な形式は、propertyName(ELEMENTS) または propertyName(KEYS) です。ここで、そのコレクションの内容は、いくつかのデータ型の List Of または Array Of として定義されたプロパティに含まれる一連の要素です。コレクションの詳細は、"Caché オブジェクトの使用法" の “コレクションを使用した作業” の章を参照してください。
リテラル・プロパティ ("Caché オブジェクトの使用法" の “リテラル・プロパティの定義と使用” の章を参照) にインデックスを作成するには、propertyNameBuildValueArray() メソッドでインデックス値配列を作成します (以下のセクションを参照)。固有のコレクションと同様、(ELEMENTS) 構文および (KEYS) 構文は、インデックス値配列と併用可能です。
プロパティ・コレクションが配列として投影される場合、インデックスがコレクション・テーブルに投影されるためには以下の制限に従う必要があります。インデックスには (KEYS) を含める必要があります。インデックスは、コレクション自体とオブジェクトの ID 値以外のプロパティを参照することはできません。投影されるインデックスが、インデックスに格納される DATA も定義する場合、格納されるデータ・プロパティも、そのコレクションと ID に制限される必要があります。そうしないと、インデックスは投影されません。この制限は、配列として投影されるコレクション・プロパティ上のインデックスに適用されます。リストとして投影されるコレクション上のインデックスには適用されません。詳細は、"Cache オブジェクトの使用法" の “コレクション・プロパティの SQL プロジェクションの制御” を参照してください。
コレクションの要素値またはキー値に対応するインデックスは、インデックスを使用したデータの保存やインデックス固有の照合など、標準インデックスのすべての機能を持つこともできます。
(ELEMENTS) および (KEYS) を使用したデータ型プロパティのインデックス作成
データ型プロパティのインデックスを作成するために、BuildValueArray() メソッドを使用してインデックス値配列を作成することもできます。このメソッドは、プロパティ値をキーおよび要素の配列に構文解析します。このメソッドは、それを行うために、関連付けられているプロパティの値から派生した要素値のコレクションを作成します。BuildValueArray() を使用してインデックス値配列を作成する場合、その構造はインデックス作成に適しています。
BuildValueArray() メソッドには propertyNameBuildValueArray() という名前があり、そのシグニチャは以下のようになります。
ClassMethod propertynameBuildValueArray(value, ByRef valueArray As %Library.String) As %Status
以下はその説明です。
-
BuildValueArray() メソッドの名前は、複合メソッドに対する一般的な方法でプロパティ名から派生します。
-
最初の引数はプロパティ値です。
-
2 番目の引数は、参照によって渡される配列です。これは、キーによって添え字が付けられた配列が要素と等しい、キーと要素のペアを含む配列です。
-
このメソッドは %Status 値を返します。
以下の例を考えてみます。
/// DescriptiveWords is a comma-delimited string of words
Property DescriptiveWords As %String;
/// Index based on DescriptiveWords
Index dwIDX On DescriptiveWords(ELEMENTS);
/// The DescriptiveWordsBuildValueArray() method demonstrates how to index on subvalues of a property.
///
/// (If DescriptiveWords were defined as a collection, this method would not be necessary.)
ClassMethod DescriptiveWordsBuildValueArray(
Words As %Library.String = "",
ByRef wordArray As %Library.String)
As %Status {
If Words '= "" {
For tPointer = 1:1:$Length(Words,",") {
Set tWord = $Piece(Words,",",tPointer)
If tWord '= "" {
Set wordArray(tPointer) = tWord
}
}
}
Else {
Set wordArray("TODO") = "Enter keywords for this person"
}
Quit $$$OK
}
この場合、dwIDX インデックスは DescriptiveWords プロパティに基づいています。DescriptiveWordsBuildValueArray() メソッドは、Words 引数によって指定された値を取り、その値に基づいてインデックス値配列を作成して、それを wordArray に格納します。Caché では BuildValueArray() の実装が内部的に使用されるため、このメソッドは呼び出せません。
要素/キー値はプロパティ値に基づく必要はありません。指定された値がこのメソッドに渡されるたびに、要素とキーの同じ配列が作成されるようにすることだけが推奨されます。
さまざまなインスタンスの DescriptiveWords プロパティの値を設定し、それらの値を検証するには、以下のような処理が必要です。
SAMPLES>SET empsalesoref = ##class(MyApp.Salesperson).%OpenId(3) SAMPLES>SET empsalesoref.DescriptiveWords = "Creative" SAMPLES>WRITE empsalesoref.%Save() 1 SAMPLES>SET empsalesoref = ##class(MyApp.Salesperson).%OpenId(4) SAMPLES>SET empsalesoref.DescriptiveWords = "Logical,Tall" SAMPLES>WRITE empsalesoref.%Save() 1
この結果、サンプル・インデックスの内容は以下のようになります。
| DescriptiveWords(ELEMENTS) | ID | データ |
|---|---|---|
| " CREATIVE" | 3 | "" |
| " ENTER KEYWORDS FOR THIS PERSON" | 1 | "" |
| " ENTER KEYWORDS FOR THIS PERSON" | 2 | "" |
| " LOGICAL" | 4 | "" |
| " TALL" | 4 | "" |
このテーブルでは、インデックスの内容が、抽象化された形式で示されています。ディスク上のストレージの実際の形式は、変更される場合があります。
array(ELEMENTS) 上のインデックスの子テーブルへの投影
array(ELEMENTS) 上の親テーブル・インデックスを子テーブルに投影するには、子クラス/テーブルに、インデックスを適切に保持するために必要なすべての列を指定する必要があります。それには、子テーブルの行 ID の一部であるキーに関する情報も含める必要があります。各インデックス行には完全な行 ID 情報を含める必要があります。それによって、対応するマスタ・マップ行に戻れるようになります。
この完全な行 ID 情報が欠落していると、子テーブルへの INSERT で、関連付けられた親テーブル・インデックスを array(ELEMENTS) に生成できません。
クラス内に定義されたインデックスに関する注意事項
クラス定義のインデックスを処理する場合、ここに示すいくつかの点に注意してください。
-
インデックス定義は、プライマリ (最初の) スーパークラスからのみ継承されます。
-
スタジオを使用して、データベースにデータが保存されているクラスのインデックス定義を追加 (または削除) する場合、“インデックスの構築” で説明されている手順に従って、手動でインデックスを生成する必要があります。
DDL を使用したインデックスの定義
テーブルの定義に DDL 文を使用している場合、インデックスの生成および削除に以下の DDL コマンドを使用できます。
DDL インデックス・コマンドは以下を実行します。
-
インデックスが追加または削除される、対応するクラス定義およびテーブル定義を更新します。変更されたクラス定義は、再コンパイルされます。
-
必要に応じて、データベースのインデックス・データを追加または削除します。CREATE INDEX コマンドは、現在データベースに保存されているデータを使用してインデックスを生成します。同様に、DROP INDEX コマンドは、データベースからインデックス・データ (実際のインデックス) を削除します。
ビットマップ・インデックス
ビットマップ・インデックスは特殊なタイプのインデックスで、指定したインデックス付きのデータ値に対応する一連の ID 値を表す一連のビット文字列を使用します。テーブルの ID フィールドが正の整数として定義されている場合は、フィールドのビットマップ・インデックスを定義できます ("制限事項" を参照)。
ビットマップ・インデックスには以下のような重要な特長があります。
-
ビットマップは高圧縮されています。つまり、ビットマップ・インデックスは標準インデックスに比べ容量が非常に小さいため、ディスクおよびキャッシュの使用量を大幅に削減します。
-
ビットマップ演算は、トランザクション処理のために最適化されます。テーブル内でビットマップ・インデックスを使用すると、標準インデックスを使用する場合に比べ、パフォーマンスが低下しません。
-
ビットマップでの論理演算 (カウント、AND、OR) を使用すると、パフォーマンスが向上します。
-
SQL エンジンは、ビットマップ・インデックスを駆使する、特別な最適化機能を備えています。
ビットマップ・インデックスは、以下の制限事項に従って標準インデックスと同様に操作できます。インデックス値は照合されており、複数のフィールドの結合に対しインデックスを作成できます。
この章では、ビットマップ・インデックスに関連する以下の項目について説明します。
ビットマップ・インデックス演算
ビットマップ・インデックスは以下のように動作します。多数の列を持つ Person テーブルがあるとします。
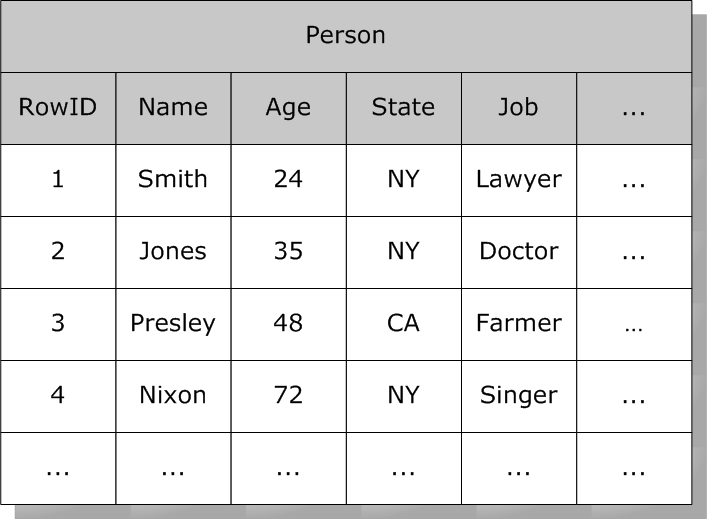
このテーブルの各行には、システムにより ID 番号 (増加する整数値) が割り当てられます。ビットマップ・インデックスは、一連のビット文字列 (1 または 0 を含む文字列) を使用します。ビット文字列では、ビットの順序の位置が、テーブルのインデックスの ID (行の番号) に対応します。上記のテーブルで State が “NY” である場合を例にとると、ビット文字列の “NY” を含む行に対応する各位置には 1 が、その他の位置には 0 が入ります。
例えば、State のビットマップ・インデックスは以下のとおりです。
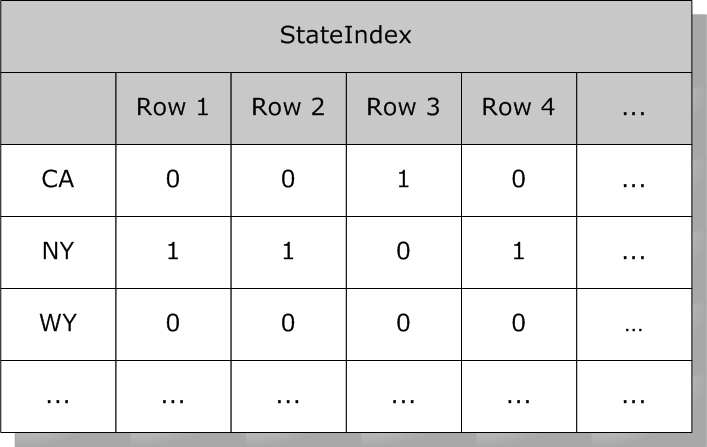
また、Age は以下のようになります。
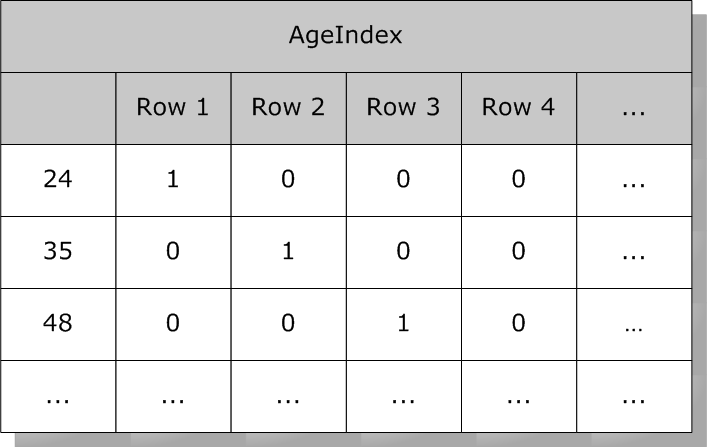
通常の演算にビットマップ・インデックスを使用する方法とは別に、SQL エンジンは、複数のインデックスの結合を使用した特別なセット・ベースの演算を、ビットマップ・インデックスを使用して効率的に実行できます。例えば、ニューヨークに住む 24 歳以上に当てはまる Person のすべてのインスタンスを得るために、SQL エンジンは Age と State の論理 AND を実行します。
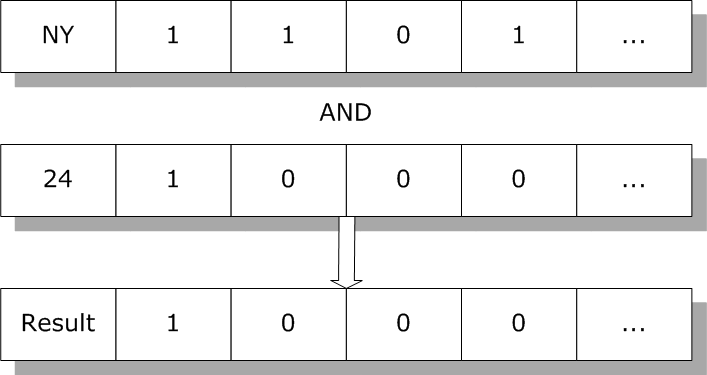
結果として得られたビットマップには、検索基準に当てはまるすべての行のセットが含まれます。SQL エンジンは、これを使用して行からデータを返します。
SQL エンジンは、ビットマップ・インデックスを以下の演算に使用します。
-
任意のテーブルの複数の条件について AND を実行
-
任意のテーブルの複数の条件について OR を実行
-
任意のテーブルの RANGE 条件
-
任意のテーブルの COUNT 演算
クラス定義を使用したビットマップ・インデックスの定義
スタジオでは、標準インデックスの場合と同様に、新規インデックス・ウィザードを使用するか、クラス定義のテキストを編集することで、ビットマップ・インデックス定義を追加できます。ただし、ビットマップ・インデックスの場合は、インデックスの Type を “bitmap” に指定する必要があります。
Class MyApp.SalesPerson Extends %Persistent [DdlAllowed]
{
Property Name As %String;
Property Region As %Integer;
Index RegionIDX On Region [Type = bitmap];
}DDL を使用したビットマップ・インデックスの定義
テーブルの定義に DDL 文を使用している場合、以下の DDL コマンドを使用して、ビットマップ・インデックスを生成および削除できます。
これは、CREATE INDEX 文に BITMAP キーワードを追加する必要がある点以外は、標準インデックスの生成とまったく同じです。
CREATE BITMAP INDEX RegionIDX ON TABLE MyApp.SalesPerson (Region)ビットマップ・エクステント・インデックスの生成
ビットマップ・インデックスを含むクラスをコンパイルする際、クラスにビットマップ・インデックスが含まれていて、そのクラスに対するビットマップ・エクステント・インデックスが定義されていない場合、クラス・コンパイラは、ビットマップ・エクステント・インデックスを生成します。クラスは、プライマリ・スーパークラスから、定義済みまたは生成されたビットマップ・エクステント・インデックスを継承します (存在する場合)。あるクラスのインデックスを作成する際、ビットマップ・エクステント・インデックスは、その作成が求められた場合、または別のビットマップ・インデックスが作成されており、ビットマップ・エクステント・インデックス構造が空である場合に作成されます。
Caché では、ビットマップ・インデックスが存在しない限り、ビットマップ・エクステント・インデックスは生成されません。ビットマップ・エクステント・インデックスは、type = bitmap、extent = true として定義されます。つまり、プライマリ・スーパークラスから継承されたビットマップ・エクステント・インデックスは、ビットマップ・インデックスと見なされ、サブクラスでのビットマップ・エクステント・インデックスの生成をトリガします (そのサブクラスで、ビットマップ・エクステント・インデックスが明示的に定義されていない場合)。
Caché では、将来の可能性を考慮してスーパークラスでビットマップ・エクステント・インデックスは生成されません。つまり、Caché では、type = bitmap であるインデックスが存在しない限り、永続クラスでビットマップ・エクステント・インデックスが作成されることはありません。将来一部のサブクラスで type = bitmap のインデックスが導入されるかもしれないという推定だけでは不十分です。
運用システム (ユーザが特定のクラスを頻繁に使用し、そのクラスをコンパイルし、続いてビットマップ・インデックス構造を作成しているような環境) でクラスにビットマップ・インデックスを追加するプロセスでは、特別な注意が必要です。そのようなシステムでは、ビットマップ・エクステント・インデックスは、コンパイルの完了とインデックスの作成手順の中間で生成される可能性があります。これにより、インデックス作成手順では、ビットマップ・エクステント・インデックスが暗黙的に作成されず、ビットマップ・エクステント・インデックスの処理が部分的に完了することがあります。
インデックス・タイプの選択
以下は、ビットマップ・インデックス、または標準インデックスの選択方法を示す一般的な指針です。通常、次のあらゆる種類のキーおよび参照にインデックスを作成するには標準インデックスを使用します。
-
主キー
-
外部キー
-
一意のキー
-
リレーションシップ
-
単純オブジェクト参照
上記以外のキーまたは参照の場合、一般的にはビットマップ・インデックスの使用をお勧めします (システムによって割り当てられた数値 ID 番号をテーブルで使用していることが前提となります)。
その他の要素
-
通常、複数のプロパティに対するビットマップ・インデックスよりも、プロパティごとに個別のビットマップ・インデックスの方がパフォーマンスが高くなります。これは、SQL エンジンは AND 演算と OR 演算を使用して個別のビットマップ・インデックスを効率的に結合できるためです。
-
プロパティ (または、まとめてインデックスを作成する必要がある複数のプロパティ) の個別値 (または値の組み合わせ) が 10,000 ~ 20,000 個を超える場合は、標準インデックスの使用を検討してください。しかし、これらの値が不均一に分散されているために多数の行に対する値の数が非常に少ない場合は、ビットマップ・インデックスを使用した方が有利です。常に、インデックスによる要求の全体量が少しでも少なくなる方法を使用します。
ビットマップ・インデックスに関する制限事項
ビットマップ・インデックスには以下のような制限事項があります。
-
正の整数値の ID を持つレコード内のフィールドに対してのみ、ビットマップ・インデックスを定義できます。ビットマップ・インデックスを定義できるテーブル (クラス) は、システムによって割り当てられた数値の ID 値を使用しているものか、カスタム ID 値の定義に IdKey を使用しているもの (IdKey が %Integer タイプで MINVAL が 0 より大きい単一のプロパティ、または %Numeric タイプで SCALE が 0 と等しく MINVAL が 0 より大きい単一のプロパティに基づいている場合) に限られます。
$SYSTEM.SQL.SetBitmapFriendlyCheck()Opens in a new tab メソッドを使用すると、この制限をコンパイル時にチェックし、定義されたビットマップ・インデックスが %CacheSQLStorage クラス内で許可されるかどうかを判断するようにシステム全体用の構成パラメータを設定できます。このチェックは、%CacheSQLStorage を使用するクラスにのみ適用されます。$SYSTEM.SQL.GetBitmapFriendlyCheck()Opens in a new tab を使用すると、このオプションの現在の構成を特定できます。
-
複数フィールドの ID キーを使用するレコードには、ビットマップ・インデックスを定義できません。
-
UNIQUE 列にビットマップ・インデックスを定義することはできません。
-
ビットマップ・インデックスを親子リレーションシップにある子テーブル上で使用することはできません。
-
ビットマップ・インデックスには、値を保存できません。
格納しているレコード数が 1,000,000 個を超えるテーブルでは、一意の値の数が 10,000 個を超えたときに、標準インデックスよりもビットマップ・インデックスの方が効率が低下します。そのため、巨大なテーブルについては、10,000 個を超える一意の値が含まれている (またはその可能性のある) フィールドに対してビットマップ・インデックスを使用しないようにしてください。また、テーブルのサイズにかかわらず、20,000 個を超える一意の値が含まれている可能性のあるフィールドにはビットマップ・インデックスを使用しないでください。これらは一般的な概数であり、正確な数ではありません。
アプリケーション・ロジックの制限事項
ビットマップ構造は、ビット文字列の配列で表現できます。この配列の各要素が固定のビット数による 1 つの「チャンク」を表しています。未定義はすべてのビットが 0 のチャンクと同等であるため、配列はスパースになることがあります。すべてのビットが 0 のチャンクを表す配列要素は、存在している必要は一切ありません。このため、アプリケーション・ロジックでは、0 値のビットの $BITCOUNT(str,0) カウントに依存しないようにする必要があります。
ビット文字列は内部フォーマットを含んでいるため、アプリケーション・ロジックでは、ビット文字列の物理長に依存することや、同じビット値を持つ 2 のビット文字列の等価性に依存することは絶対に避けてください。ロールバック操作後、ビット文字列はトランザクション前のビット値にリストアされます。ただし、内部フォーマットのために、ロールバックされたビット文字列はトランザクション前のビット文字列と等しくならないことや、同じ物理長にならないことがあります。
ビットマップ・インデックスの維持
揮発性のテーブル (多数の INSERT 操作および DELETE 操作が実行されるもの) では、ビットマップ・インデックス用のストレージは徐々に効率が低下する可能性があります。ビットマップ・インデックスを維持するには、%SYS.Maint.BitmapOpens in a new tab ユーティリティ・メソッドを実行してビットマップ・インデックスを圧縮し、それらを最適な効率に復元します。OneClass()Opens in a new tab メソッドを使用すると、1 つのクラスのビットマップ・インデックスを圧縮できます。または、Namespace()Opens in a new tab メソッドを使用して、ネームスペース全体のビットマップ・インデックスを圧縮できます。これらの維持メソッドは、実働システム上で実行できます。
%SYS.Maint.BitmapOpens in a new tab ユーティリティ・メソッドを実行した結果は、このメソッドを呼び出したプロセスに書き込まれます。これらの結果は、クラス %SYS.Maint.BitmapResultsOpens in a new tab にも書き込まれます。
ビットスライス・インデックス
ビットスライス・インデックスは、フィールドが SUM、COUNT、または AVG 集約計算で使用される場合に数値データ・フィールドに対してのみ使用されます。ビットスライス・インデックスは、各数値データをバイナリのビット文字列として表します。ビットスライス・インデックスは、ビットマップ・インデックスのようにブーリアン・フラグを使用して数値データのインデックスを作成するのではなく、バイナリの各数値を表し、バイナリ値の桁ごとにビットマップを作成してそのバイナリの桁が 1 である行を記録します。これは、SUM、COUNT、または AVG 集約計算のパフォーマンスを著しく向上できる非常に特殊なタイプのインデックスです (ビットスライス・インデックスは COUNT(*) 計算には使用できません)。ビットスライス・インデックスは、その他の集約関数またはその他の SQL 数値演算には使用されません。SQL オプティマイザは、定義されたビットスライス・インデックスを使用するべきかどうかを決定します。
文字列データ・フィールドにビットスライス・インデックスを作成できますが、ビットスライス・インデックスでは、これらのデータ値は、キャノニック形式の数値として表されます。つまり、"abc" などの非数値文字列はすべて 0 としてインデックス付けされます。このタイプのビットスライス・インデックスは、文字列フィールドに値があり、NULL としてカウントされないレコードに迅速に COUNT を実行する際に使用できます。
以下の例では、Salary はビットスライス・インデックスの候補となります。
SELECT AVG(Salary) FROM SalesPersonビットスライス・インデックスは、WHERE 節を使用するクエリで集約計算に使用できます。これは、WHERE 節に多数のレコードが含まれる場合に最も効果的です。以下の例では、SQL オプティマイザは多くの場合、Salary にビットスライス・インデックス (定義されている場合) を使用します。その場合、Region でも、定義されたビットマップを使用するか、Region にビットマップ一時ファイルを生成して、ビットマップ・インデックスが使用されます。
SELECT AVG(Salary) FROM SalesPerson WHERE Region=2ただし、WHERE 条件がインデックスにより満たされず、集約されるフィールドを含むテーブルを読み取ることによって実行されなければならない場合には、ビットスライス・インデックスは使用されません。以下の例では、Salary でビットスライス・インデックスを使用しません。
SELECT AVG(Salary) FROM SalesPerson WHERE Name LIKE '%Mc%'ビットスライス・インデックスは、数値を含むすべてのフィールドに対して定義できます。InterSystems SQL では、ObjectScript $FACTOR 関数で説明されているように、scale パラメータを使用して小数をビット文字列に変換します。ビットスライス・インデックスをデータ型文字列のフィールドに定義できます。この場合、非数値文字列のデータ値は、ビットスライス・インデックス用に 0 として扱われます。
ビットスライス・インデックスは、システムが割り当てた、正の整数値の行 ID を持つフィールドにのみ定義できます。ビットスライス・インデックスは、複数のフィールドの連結ではなく、単一のフィールド名にのみ定義できます。WITH DATA 節は指定できません。
次に示す例では、ビットスライス・インデックスとビットマップ・インデックスを比較しています。行 1、2、および 3 の値 1、5、および 22 にビットマップ・インデックスを作成すると、ビットマップ・インデックスは以下の値に対してインデックスを作成します。
^gloI("bitmap",1,1)= "100"
^gloI("bitmap",5,1)= "010"
^gloI("bitmap",22,1)="001"
行 1、2、および 3 の値 1、5、および 22 にビットスライス・インデックスを作成すると、まず、その値が以下のビット値に変換されます。
1 = 00001 5 = 00101 22 = 10110
その後で、以下に示すビットに対してインデックスを作成します。
^gloI("bitslice",1,1)="110"
^gloI("bitslice",2,1)="001"
^gloI("bitslice",3,1)="011"
^gloI("bitslice",4,1)="000"
^gloI("bitslice",5,1)="001"
この例では、ビットマップ・インデックスの値 22 には 1 つのグローバル・ノードの設定が必要になります。ビットスライス・インデックスの値 22 には 3 つのグローバル・ノードの設定が必要になります。
INSERT または UPDATE では、単一のビット文字列ではなく、すべての n ビットスライスでビットを設定する必要があることに注意してください。このような追加のグローバル設定操作は、ビットスライス・インデックスの入力に関連する INSERT 操作と UPDATE 操作のパフォーマンスに影響を及ぼすことがあります。INSERT、UPDATE、または DELETE 操作を使用してビットスライス・インデックスを生成および維持すると、ビットマップ・インデックスや通常のインデックスを使用する場合よりも速度が遅くなります。複数のビットスライス・インデックスを維持したり、頻繁に更新されるフィールドでビットスライス・インデックスを維持すると、パフォーマンス・コストが増える可能性があります。
揮発性のテーブル (多数の INSERT 操作、UPDATE 操作および DELETE 操作が実行されるもの) では、ビットスライス・インデックス用のストレージは徐々に効率が低下する可能性があります。%SYS.Maint.BitmapOpens in a new tab ユーティリティ・メソッドは、ビットマップ・インデックスとビットスライス・インデックスの両方を圧縮し、効率を復元します。詳細は、“ビットマップ・インデックスの維持” を参照してください。
インデックスの構築
現在のデータベース・アクセスが次のどれであるかに応じて、既存のインデックスの再構築方法が決定されます。
-
非アクティブ・システム (インデックスの構築または再構築中に、他のプロセスはデータにアクセスしない)
-
READONLY アクティブ・システム (インデックスの構築または再構築中に、他のプロセスはデータのクエリを実行できる)
-
READ および WRITE アクティブ・システム (インデックスの構築または再構築中に、他のプロセスはデータの変更やクエリを実行できる)
非アクティブ・システム上でのインデックスの構築
クラス (テーブル) に定義される各インデックスを構築または削除する (%PersistentOpens in a new tab クラスにより提供される) メソッドが自動的に生成されます。それらのメソッドは、以下の 2 つの方法のいずれかで使用できます。
インデックスの構築は、以下を実行します。
-
現在のインデックスの内容を削除します。
-
メインのテーブルをスキャンし (各行を読み取り)、テーブルの各行にインデックスのエントリを追加します。可能であれば、特別な $SortBegin および $SortEnd 関数を使用して、大規模なインデックスの構築が効率的であることを確認してください。標準インデックスを構築する際に、このように $SortBegin/$SortEnd を使用すると、メモリ内のキャッシュ・データのほかに、CACHETEMP データベース内のスペースも使用できます。したがって、非常に大きな標準インデックスを構築するときは、最終的なインデックスとほぼ等しいサイズのスペースが CACHETEMP 内に必要になる可能性があります。
インデックス構築メソッドは、Caché の既定のストレージ構造を使用しているクラス (テーブル) でのみ使用できます。従来の保存構成にマップされたクラスは、従来のアプリケーションがインデックスの作成を管理すると見なし、インデックス構築をサポートしません。
管理ポータルによるインデックスの構築
テーブルに既存のインデックスを構築 (インデックスを再構築) するには、以下の操作を実行します。
-
管理ポータルで [システム・エクスプローラ] を選択し、[SQL] (システム, SQL) を選択します。ページ上部の [切り替え] オプションを使ってネームスペースを選択します。利用可能なネームスペースのリストが表示されます。ネームスペースの選択後に、画面の左側にある [スキーマ] ドロップダウン・リストを選択します。これには、現在のネームスペースのスキーマのリストと、各スキーマに関連付けられているテーブルまたはビューがあるかどうかを示すブーリアン・フラグが表示されます。
-
このリストからスキーマを選択すると、[スキーマ] ボックスに表示されます。上記と同様に、ドロップダウン・リストでは、テーブル、システム・テーブル、ビュー、プロシージャ、またはスキーマに属するすべてを選択できます。[テーブル] または [すべて] を選択し、[テーブル] フォルダを開いて、このスキーマのテーブルのリストを開きます。テーブルがない場合は、フォルダを開くと空白ページが表示されます ([テーブル] または [すべて] を選択しない場合は、[テーブル] フォルダを開くとネームスペース全体のテーブルがリストされます)。
-
一覧表示されているテーブルのいずれかを選択します。これにより、テーブルの [カタログの詳細] が表示されます。
-
すべてのインデックスを再構築する場合:[アクション] ドロップダウン・リストをクリックし、[テーブルのインデックスを再構築] を選択します。
-
1 つのインデックスを再構築する場合:[インデックス] ボタンをクリックして、既存のインデックスを表示します。リストの各インデックスに、[インデックス再構築] のオプションがあります。
-
他のユーザがテーブルのデータにアクセスしている間は、インデックスを再構築しないでください。アクティブなシステム上にインデックスを再構築する場合は、以下を参照してください。
プログラミングによるインデックスの構築
非アクティブなテーブルのインデックスを作成するための推奨方法は、テーブルの永続クラスに付属する %BuildIndices() メソッドを使用することです。プログラムでインデックス (1 つまたは複数) を構築するには、%Library.Persistent.%BuildIndices()Opens in a new tab メソッドを使用します。
-
すべてのインデックスの構築:引数を指定せずに %BuildIndices() を呼び出すと、指定したクラス (テーブル) を対象として定義されたすべてのインデックスが構築されます (さらにその値も設定されます)。
SET sc = ##class(MyApp.SalesPerson).%BuildIndices() IF sc=1 {WRITE !,"Successful index build" } ELSE {WRITE !,"Index build failed",! DO $System.Status.DisplayError(sc) QUIT} -
指定されたインデックスの構築:最初の引数としてインデックス名の $List を指定して %BuildIndices() を呼び出すと、指定したクラス (テーブル) を対象とした、指定されて定義されたインデックスが構築されます (さらにその値も設定されます)。
SET sc = ##class(MyApp.SalesPerson).%BuildIndices($ListBuild("NameIDX","SSNKey")) IF sc=1 {WRITE !,"Successful index build" } ELSE {WRITE !,"Index build failed",! DO $System.Status.DisplayError(sc) QUIT} -
指定された以外すべてのインデックスの構築:7 番目の引数としてインデックス名の $List を指定して %BuildIndices() を呼び出すと、指定したインデックスを除く指定したクラス (テーブル) を対象とした、すべての定義されたインデックスが構築されます (さらにその値も設定されます)。
SET sc = ##class(MyApp.SalesPerson).%BuildIndices("",,,,,,$ListBuild("NameIDX","SSNKey")) IF sc=1 {WRITE !,"Successful index build" } ELSE {WRITE !,"Index build failed",! DO $System.Status.DisplayError(sc) QUIT}
%BuildIndices() メソッドは以下を実行します。
-
再構築されるあらゆるインデックス上で (ビットマップを除く) $SortBegin 関数を呼び出します (これにより、そのインデックスに対し高性能な並べ替え操作を開始することができます)。
-
クラス (テーブル) のメイン・データを繰り返し、インデックスに使用された値を集め、これらの値を (適切に照合変換して) インデックスに追加します。
-
インデックスのソート処理を終了させるために、$SortEnd 関数を実行します。
インデックスが既に値を保持している場合は、2 つの引数の 2 番目の引数に値 1 を指定した %BuildIndices() を呼び出す必要があります。この引数に 1 を指定すると、このメソッドはインデックスの構築前に値を削除します。以下に例を示します。
SET sc = ##class(MyApp.SalesPerson).%BuildIndices(,1)
IF sc=1 {WRITE !,"Successful index build" }
ELSE {WRITE !,"Index build failed",!
DO $System.Status.DisplayError(sc) QUIT} この場合、すべてのインデックスがいったん削除され、その後再構築されます。また次の例のように、特定のインデックスを削除し、再構築することもできます。
SET sc = ##class(MyApp.SalesPerson).%BuildIndices($ListBuild("NameIDX","SSNKey"),1)
IF sc=1 {WRITE !,"Successful index build" }
ELSE {WRITE !,"Index build failed",!
DO $System.Status.DisplayError(sc) QUIT} 他のユーザがテーブルのデータにアクセスしている間は、インデックスを再構築しないでください。アクティブなシステム上にインデックスを再構築する場合は、以下を参照してください。
%BuildIndices() は、実行のロックの種類、およびロック構築時にジャーナリングを無効にするかどうかを指定する引数も提供します。
既定では、%BuildIndices() は、すべての ID のためのインデックス・エントリを構築します。ただし、ID の範囲を指定して、%BuildIndices() でその範囲内の ID のみのインデックス・エントリを構築することもできます。例えば、INSERT を %NOINDEX 制限を指定して使用し、一連の新規レコードをテーブルに追加する場合は、後から %BuildIndices() を ID の範囲を指定して使用し、それらの新規レコードのためのインデックス・エントリを構築できます。
%BuildIndices() は %Status 値を返します。%BuildIndices() がデータの取得の問題により失敗すると、SQLCODE エラー、およびエラーが発生した %ROWID を含むメッセージ (%msg) が生成されます。
READONLY アクティブ・システム上でのインデックスの構築
その時点でテーブルがクエリ操作にのみ使用されている場合 (READONLY)、クエリ操作を中断することなく新しいインデックスの構築または既存のインデックスの再構築を実行できます。1 つ以上のインデックスを構築するクラスのすべてが、その時点で READONLY になっている場合は、“READ および WRITE アクティブ・システム上でのインデックスの構築” の説明と同じ操作手順を使用しますが、%BuildIndices()Opens in a new tab を使用するときに pLockFlag=3 (共有エクステント・ロック) を設定する点が異なります。
READ および WRITE アクティブ・システム上でのインデックスの構築
その時点で永続クラス (テーブル) が使用されていて、READ/WRITE アクセス (クエリおよびデータ変更) に使用できる場合、それらの操作を中断することなく新しいインデックスの構築または既存のインデックスの再構築を実行できます。1 つ以上のインデックスを再構築するクラスが、その時点で READ/WRITE アクセスが可能な場合、インデックスの再構築に推奨される方法は、テーブルの永続クラスに用意されている %BuildIndices() メソッドを使用することです。
同時 READ/WRITE アクセス時に 1 つ以上のインデックスを構築する場合、推奨される操作手順は以下のとおりです。
-
構築するインデックスを、SetMapSelectability()Opens in a new tab を使用して非アクティブ化します。これにより、クエリ・オプティマイザはこのインデックスを使用できなくなります。この操作は、既存のインデックスを再構築する場合と新しいインデックスを作成する場合の両方で実行する必要があります。例えば、以下のようにします。
WRITE $SYSTEM.SQL.SetMapSelectability("Sample.MyStudents","StudentNameIDX",0)各項目の内容は以下のとおりです。
-
最初の引数は、スキーマ.テーブル名 SqlTableName で、永続クラス名ではありません。例えば、既定のスキーマは SQLUser で、User ではありません。この値では大文字と小文字が区別されます。
-
2 番目の引数は、SQL インデックス・マップ名です (またはインデックス・マップ名のコンマ区切りリストです)。これは通常はインデックスの名前であり、ディスクにインデックスを保存する際の名前を指します。新規インデックスの場合、インデックスを作成するときに、この名前を使用することになります。この値では大文字と小文字は区別されません。
-
3 番目の引数は、MapSelectability フラグです。0 はインデックス・マップが選択不可能 (オフ) であることを示し、1 はインデックス・マップが選択可能 (オン) であることを示します。0 を指定します。
インデックスが選択不可であるかどうかを判断するには、GetMapSelectability()Opens in a new tab メソッドを呼び出します。このメソッドは、インデックスが選択不可であるというフラグを明示的に設定している場合に 0 を返します。それ以外の場合はすべて 1 を返します。テーブルまたはインデックスの有無に関する検証チェックは実行されません。スキーマ.テーブル名は SqlTableName であり、大文字小文字が区別されることに注意してください。
SetMapSelectability() と GetMapSelectability() は、現在のネームスペース内のインデックス・マップにのみ適用されます。このテーブルが複数のネームスペースにマップされているときに、それぞれのネームスペースでインデックスを作成する必要がある場合は、それぞれのネームスペースで SetMapSelectability() を呼び出す必要があります。
-
-
インデックス構築中の同時操作を確立します。
-
新規インデックスの場合、クラスのインデックス定義 (またはクラスの %CacheSQLStorageOpens in a new tab の新しい SQL Index Map 仕様) を作成します。クラスをコンパイルします。この時点で、インデックスはテーブル定義に存在します。つまり、オブジェクトの保存、SQL INSERT 操作、および SQL UPDATE 操作がすべてインデックスに整理されます。ただし、手順 1 での SetMapSelectability() 呼び出しにより、このインデックス・マップはデータの取得には選択されません。SetMapSelectability() はクエリでエクステント・インデックスを使用しないようにしますが、インデックス・グローバルとデータ・グローバルを使用するようデータ・マップが SQL に投影されます。新規インデックスの場合、これはインデックスがまだ生成されていないため、適切な処置です。テーブルに対してクエリを実行できるようになる前に、エクステント・インデックスの生成が行われる必要があります。
-
既存のインデックスの場合、テーブルを参照するクエリ・キャッシュを削除します。インデックスの構築で最初に実行される操作はインデックスの削除です。そのため、インデックスの再構築中は、インデックスを使用するように最適化されたコードに依存することができません。
-
-
インデックスの構築には、pLockFlag=2 を指定して、目的のクラスの %BuildIndices()Opens in a new tab メソッドを使用します。
-
インデックスの構築が完了したら、クエリ・オプティマイザによるマップの選択を可能にします。以下の例に示すように、3 番目の引数 MapSelectability フラグを 1 に設定します。
WRITE $SYSTEM.SQL.SetMapSelectability("Sample.MyStudents","StudentNameIDX",1) -
もう一度、テーブルを参照するクエリ・キャッシュを削除します。これにより、このプロセス中に作成されたクエリ・キャッシュを削除します。このクエリ・キャッシュは、インデックスを使用できなかったために、インデックスを使用する同じクエリよりも劣ったものになります。
これによりプロセスが完了します。インデックスは完全に生成され、クエリ・オプティマイザは、インデックスに対応します。
%BuildIndices() は、正の整数 ID 値があるテーブルのインデックスの再構築にのみ使用できます。その他のテーブルには、%ValidateIndices() メソッドを使用します。これについては "インデックスの検証" で説明されています。%ValidateIndices() は、最も速度が遅いインデックス構築メソッドであるので、他の選択肢がない場合にのみ使用してください。
%ConstructIndicesParallel() メソッド
%ConstructIndicesParallel()Opens in a new tab メソッドは、%Library.IndexBuilderOpens in a new tab クラスのクラス・メソッドであり、INDEXBUILDERFILTER パラメータによって指定されるインデックスを構築します。インデックスを構築するインスタンスのセットを指定できます (クラス/テーブルのインスタンスの ID/行番号に基づきます)。インデックスを生成するバックグラウンド・ジョブの数、操作中のロックおよびジャーナリング動作も指定できます。
%ConstructIndicesParallel() は、%Library.IndexBuilder から継承して INDEXBUILDERFILTER クラス・パラメータを定義するようクラスを変更する必要があります。INDEXBUILDERFILTER クラス・パラメータは、%Library.IndexBuilder.%ConstructIndicesParallel() のメソッドに認識され、構築または再構築するインデックスを指定します。INDEXBUILDERFILTER は、インデックス名の文字列値またはインデックス名のコンマ区切りリストです。指定された各インデックスが構築または再構築されます。INDEXBUILDERFILTER が定義されていないか、または "" に設定されている場合は、クラス内のすべてのインデックスが構築されます。
例えば、NameIDX を MyApp.SalesPerson クラスに追加し、このインデックスのみを構築するとします。次に、INDEXBUILDERFILTER パラメータを以下のように定義します。
Parameter INDEXBUILDERFILTER = "NameIDX";アクティブな READ/WRITE システム上でインデックスを構築する場合には、引数値、(Sortbegin=0 と LockFlag=2) または (LockFlag=1) のいずれかが必須です。この引数の詳細は、%ConstructIndicesParallel()Opens in a new tab のクラス・ドキュメントを参照してください。
%ConstructIndicesParallel() は、進捗状況に関する出力を表示します。すべてのジョブが作業を完了すると、メソッドは終了します。次に、出力の例を示します。
SAMPLES>SET sc=##class(MyApp.SalesPerson).%ConstructIndicesParallel(,,,1,,1,1) Building 32 chunks and will use parallel build algorithm with 2 drone processes. SortBegin is requested. Started drone process: 48938 Started drone process: 48939 Expected time to complete is 17 secs to build 32 chunks of 64,000 objects using 2 processes. Waiting for processes to complete....done. Elapsed time using 2 processes was 28.126064. SAMPLES>
インデックス再構築中の大規模なデータ変更:インデックスの再構築の進行中に、単一のトランザクション内でテーブルの多数の行を変更するというプロセスの場合には、ロック・テーブル競合の問題が発生する可能性があります。
部分的なインデックスの生成
この種類のインデックスを作成する場合は、インデックス全体を一度に生成する必要はありません。マップを選択可能にする前は、インデックスは見えないので、部分的なデータでクエリが操作を行うことはありません。
例えば、インデックス・ビルダを実行できる時間が、毎晩の短い時間に限られているとします。テーブルに含まれている行が 300,000,000 行あるとすると、3 日間、夜ごとに 100,000,000 行を構築することになります。最初の夜には、以下のような呼び出しを作成します。
SET sc=##class(Sample.Person).%ConstructIndicesParallel(,1,100000000,0,0,2,0)2 日目の夜には、以下のような呼び出しを作成します。
SET sc=##class(Sample.Person).%ConstructIndicesParallel(,100000001,200000000,0,0,2,0)3 日目の夜には、以下のような呼び出しを作成します。
SET sc=##class(Sample.Person).%ConstructIndicesParallel(,200000001,-1,0,0,2,0)インデックスの検証
以下のメソッドのいずれかを使用して、インデックスを検証できます。
-
$SYSTEM.OBJ.ValidateIndices()Opens in a new tab は、テーブルのインデックスを検証し、そのテーブルのコレクション子テーブル内の任意のインデックスを検証することもできます。
-
%Library.Storage.%ValidateIndices()Opens in a new tab は、テーブルのインデックスを検証します。コレクション子テーブルのインデックスは、別個の %ValidateIndices() 呼び出しで検証する必要があります。
両方のメソッドは、指定されたテーブルの 1 つまたは複数のインデックスのデータ整合性を確認し、オプションで、検出されたインデックス整合性の問題を修正します。インデックス検証は、以下の 2 つの手順で実行されます。
-
テーブル (クラス) 内のすべての行 (オブジェクト) のインデックス・エンティティが適切に定義されていることを確認します。
-
各インデックスを詳しく調べて、インデックスが付いたすべてのエントリに対して、テーブル (クラス) 内に値および一致するエントリがあることを確認します。
いずれかのメソッドで不一致が見つかった場合は、そのメソッドでインデックスの構造またはコンテンツを修正できます。標準インデックス、ビットマップ・インデックス、ビットマップ・エクステント・インデックス、およびビットスライス・インデックスを検証し、オプションで修正できます。
一般に、%ValidateIndices() はターミナルから実行します。出力は現在のデバイスに表示されます。このメソッドは、指定されたインデックス名の %List、または指定されたテーブル (クラス) に対して定義されたすべてのインデックスに適用できます。これは、指定されたクラスに由来するインデックスにのみ機能します。インデックスがスーパークラスに由来している場合は、そのスーパークラスで %ValidateIndices() を呼び出すことで、そのインデックスを検証できます。%ValidateIndices() は、READONLY クラスではサポートされません。
以下の例では、%ValidateIndices() を使用して、テーブル Sample.Person のすべてのインデックスを検証して修正します。
ZNSPACE "Samples"
SET status=##class(Sample.Person).%ValidateIndices("",1,2,1)
IF status=1 {WRITE !,"Successful index validation/correction" }
ELSE {WRITE !,"Index validation/correction failed",!
DO $System.Status.DisplayError(status) QUIT}この例では、1 つ目の引数 ("") はすべてのインデックスが検証対象であることを指定し、2 つ目の引数 (1) はインデックスの不一致を修正する必要があることを指定します。また、3 つ目の引数 (2) はテーブル全体を排他的にロックすることを指定し、4 つ目の引数 (1) は複数のプロセスを使用して (使用可能な場合) 検証を実行することを指定します。このメソッドは %Status 値を返します。
名前によるインデックスの検証
%ValidateIndices() の1 つ目の引数、または $SYSTEM.OBJ.ValidateIndices() の 2 つ目の引数は、どのインデックスを %List 構造として検証するか指定します。IdKey インデックスは、1 つ目の引数の値に関係なく必ず検証されます。空の文字列値 ("") を指定すると、テーブルのすべてのインデックスを検証できます。リスト構造を指定すると、テーブルの個々のインデックスを検証できます。以下の例では、IdKey インデックス、および指定された 2 つのインデックス NameIDX と SSNKey を検証します。
ZNSPACE "Samples"
SET IndList=$LISTBUILD("NameIDX","SSNKey")
SET status=##class(Sample.Person).%ValidateIndices(IndList,1,2,1)
SET status=##class(Sample.Person).%ValidateIndices(IndList,1,2,1)
IF status=1 {WRITE !,"Successful index validation/correction" }
ELSE {WRITE !,"Index validation/correction failed",!
DO $System.Status.DisplayError(status) QUIT}どちらのメソッドでも、存在しないインデックス名がインデックス・リストに含まれている場合、メソッドはインデックス検証を実行せず、%Status エラーを返します。重複する有効なインデックス名がインデックス・リストに含まれている場合は、メソッドは指定されたインデックスを検証し、重複を無視して、エラーは発行しません。
インデックスのリスト
INFORMATION.SCHEMA.INDEXESOpens in a new tab 永続クラスは、現在のネームスペース内のすべての列インデックスに関する情報を表示します。この永続クラスは、インデックス付けされた列ごとに 1 つのレコードを返します。レコードでは、インデックスの名前、スキーマ名、テーブル名、インデックスのマップ先の列名などのさまざまなインデックス・プロパティを提供します。それぞれの列レコードは、インデックス・マップにおけるその列の順序位置も提供します。この値は、インデックスが複数の列にマップされていない限り 1 です。
次の例では、インデックス名、対応するテーブル・スキーマ名、テーブル名、列名、および現在のネームスペース内のすべての非システム・インデックス向けのインデックス定義における列の順序位置が返されます。
SELECT Index_Name,Table_Schema,Table_Name,Column_Name,Ordinal_Position FROM INFORMATION_SCHEMA.INDEXES WHERE NOT Table_Schema %STARTSWITH '%'メソッドのオープン、存在確認、および削除
Caché インデックス作成機能は、以下の操作をサポートします。
-
インデックス・キーによるインスタンスのオープン
-
インスタンスが存在するかどうかの確認
-
インスタンスの削除
インデックス・キーによるインスタンスのオープン
ID キー、主キー、または一意のインデックスの場合、indexnameOpen() メソッド (indexname はインデックスの名前) を使用することによって、インデックスのプロパティ値が指定値と一致するオブジェクトを開くことができます。このメソッドには、インデックス内の各プロパティに対応する 1 つの引数があるため、メソッドには 3 つ以上の引数があります。
-
最初の引数は、それぞれインデックス内のプロパティに対応します。
-
最後から 2 番目の引数は、オブジェクトを開くときに使用される並行処理値を指定します (使用可能な並行処理の設定は、"Caché オブジェクトの使用法" の “オブジェクト同時処理” に示されています)。
-
最後の引数は、メソッドがインスタンスを開くことに失敗した場合に、%Status コードを受け取ることができます。
このメソッドは、一致するインスタンスを見つけると OREF を返します。
例えば、クラスに以下のインデックス定義が含まれているとします。
Index SSNKey On SSN [ Unique ];そして、参照されたオブジェクトがディスクに保存され、一意の ID 値を持つ場合、以下のようにメソッドを呼び出すことができます。
SET person = ##class(Sample.Person).SSNKeyOpen("111-22-3333",2,.sc)正常に完了すると、このメソッドによって、SSN プロパティの値が 111–22–3333 である Sample.PersonOpens in a new tab のインスタンスの OREF に、person の値が設定されます。
メソッドへの 2 番目の引数は並行処理値を指定し、上の例では 2 (共有) です。3 番目の引数は、オプションの %Status コードを保持します。指定された値と一致するオブジェクトをメソッドが見つけられなかった場合、エラー・メッセージがステータス・パラメータ sc に書き込まれます。
このメソッドは、%Library.CacheIndex.Open()Opens in a new tab メソッドとして実装されます。このメソッドは、%Persistent.Open()Opens in a new tab メソッドおよび %Persistent.OpenId()Opens in a new tab メソッドに似ています。異なるのは、このメソッドが、OID 引数や ID 引数ではなくインデックス定義内のプロパティを使用する点です。
インスタンスが存在するかどうかの確認
indexnameExists() メソッド (indexname はインデックスの名前) は、メソッドの引数で指定されているインデックス・プロパティ値を持つインスタンスが存在するかどうかを確認します。このメソッドには、インデックス内の各プロパティに対応する 1 つの引数があり、その最後のオプションの引数は、オブジェクトの ID が指定値と一致する場合に、その ID を受け取ることができます。このメソッドは、ブーリアン値を返し、成功 (1) または失敗 (0) を示します。このメソッドは、%Library.CacheIndex.Exists()Opens in a new tab メソッドとして実装されます。
例えば、クラスに以下のインデックス定義が含まれているとします。
Index SSNKey On SSN [ Unique ];そして、参照されたオブジェクトがディスクに保存され、一意の ID 値を持つ場合、以下のようにメソッドを呼び出すことができます。
SET success = ##class(Sample.Person).SSNKeyExists("111-22-3333",.id)正常に完了すると、success が 1 になり、id には、検出されたオブジェクトと一致する ID が含まれます。
このメソッドは、以下を除くすべてのインデックスの値を返します。
-
ビットマップ・インデックス、またはビットマップ・エクステント・インデックス。
-
インデックスに (ELEMENTS) 式または (KEYS) 式が含まれている場合。そのようなインデックスの詳細は、“コレクションのインデックス作成” のセクションを参照してください。
インスタンスの削除
indexnameDelete() メソッド (indexname はインデックスの名前) は、Unique、PrimaryKey、IdKey の各インデックスに使用します。このメソッドは、指定されたキーのプロパティ/列の値に一致するインスタンスを削除します。オプションの引数が 1 つあり、これを指定して操作の並行処理を指定できます。このメソッドは %Status コードを返します。%Library.CacheIndex.Delete()Opens in a new tab メソッドとして実装されます。