クラスタ・ジャーナリング
この章では、Caché 内の ECP ベースの共有ディスク・クラスタ・システムにおけるジャーナリング情報について説明します。以下のトピックについて説明します。
関連情報は、次の章を参照してください。
-
このドキュメントの “バックアップとリストア”
-
このドキュメントの “ジャーナリング”
-
このドキュメントの “シャドウイング”
-
"Caché システム管理ガイド" の “Caché の構成” の章にある "クラスタ設定の構成"
クラスタ上のジャーナリング
ジャーナリングは、クラスタ・フェイルオーバーが最新のデータベースを取得し、トランザクション処理を実行するために必要です。クラスタ内の各ノードには、固有のジャーナル・ファイルがあります。復元可能性を確保するために、あるノードのジャーナル・ファイルには、クラスタにある他のすべてのノードからアクセスできる必要があります。クラスタ・セッション ID (CSI) は、セッションが始まる時間です。つまり、クラスタの開始時間であり、クラスタ化されたシステム内のそれぞれのジャーナル・ファイルのヘッダに格納されています。
クラスタ化されないシステム上のジャーナル情報に加え、以下の特定の事項がクラスタ化されたシステムに適用されます。
-
クラスタ化されたデータベースの更新は、スクラッチ・グローバル以外は常にジャーナル (通常、マスタ・ノード上のみ) されます。クラスタ・データベースでは、データベースのジャーナリング属性が No に設定されているグローバルもジャーナルされます。これは、そのジャーナルの更新が、トランザクションの内部で行われるか、外部で行われるかという点には関係ありません。
-
$Increment 関数によるデータベース更新は、マスタ・ノード上と同様に、ノードがマスタでない場合はローカル・ノード上でジャーナルされます。
-
その他の更新は、そのように設定されている場合には、ローカルでジャーナルされます。
クラスタ化されたシステム上のジャーナル・ファイルは、以下を使用して構成されます。
ジャーナル・ファイルの既定の位置は、Caché インスタンスの install-dir\Mgr\journal ディレクトリです。ただし、データベース・ファイルおよび CACHE.WIJ ファイルが配置されるストレージ・デバイスと別のストレージ・デバイス上にジャーナル・ファイルを配置することをお勧めします。ジャーナル・ストレージの分離の詳細は、このドキュメントの “ジャーナリング” の章の "ジャーナリングの最善の使用方法" を参照してください。
ジャーナリングは、^JOURNAL ルーチンを使用して停止できますが、クラスタ環境では停止しないでください。クラスタ環境で停止すると、次のバックアップまでの間、リカバリ手順は攻撃に対して脆弱になります。
クラスタ・ジャーナル・ログ
クラスタのメンバで使用されるジャーナル・ファイルは、クラスタの Pre-Image Journal (PIJ) ディレクトリにあるファイル CACHEJRN.LOG に記録されます。ノードがクラスタを構成している場合、このファイルは、そのノードによって管理されているジャーナル・ファイルのリストを保持しています。ノードがクラスタを構成していない場合、そのノードによって管理されるジャーナル・ファイルは、クラスタ・ジャーナル・ログに記録されないことがあります。詳細は、このドキュメントの “ジャーナリング” の章の "ジャーナル履歴ログ" を参照してください。
以下はクラスタ・ジャーナル・ログの一部の例です。
0,_$1$DRA1:[TEST.50.MGR.JOURNAL]20030913.004
1,_$1$DKA0:[TEST.50.MGR.JOURNAL]20030916.002
0,_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.001
0,_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.002
1,_$1$DRA1:[TEST.5A.MGR.JOURNAL]20030916.002
1,_$1$DRA1:[TEST.5A.MGR.JOURNAL]20030916.003
コンマ区切りの各行の最初の値は、2 番目のフィールドであるジャーナル・ファイルが属するノードのクラスタ・システム番号 (CSN) です。このログは、クラスタのすべてのメンバ、特にクラスタから除外されたメンバのジャーナル・ファイルを確認するときに便利です。ノードが再起動するとノードの CSN は変更されることがあります。
ノードがクラスタに結合すると、現在のジャーナル・ファイルがジャーナル・ログに追加されます。ジャーナルを開始する処理、あるいはジャーナル・ファイルを切り替える処理もエントリを追加します。このログは、クラスタ・ジャーナル・リストア内で、シャドウイングやジャーナル・ダンプ・ユーティリティによって使用されます。
クラスタ・ジャーナルのシーケンス番号
更新順序を示す記録を必要とする場合は、クラスタにマウントされたデータベースでグローバルをロックすることをお勧めします。Caché はこの方法で、クラスタ・ノードのジャーナル・ファイルに更新順序を記録します。クラスタ・フェイルオーバーが発生した場合、すべてのノードのジャーナルが適切な順序で提供されます。更新は、それが発生した順序ではデジャーナルされませんが、Lock コマンドと $Increment 関数によって保証された同期化に対しては有効です。
クラスタ化されたデータベースをジャーナル・ファイルから適切にリストアするには、更新が発生した順序でそれを適用する必要があります。データベース更新の各ジャーナル・エントリの一部であるクラスタ・ジャーナルのシーケンス番号と、ジャーナル・ヘッダの一部のクラスタ・セッション ID は、すべてのクラスタ・メンバのジャーナル・ファイルからトランザクションを順番に並べる方法を提供します。各クラスタ・セッションで、シーケンス番号は 1 から始まり、18446744073709551619 (つまり、2**64-1) まで続けることができます。
クラスタのマスタ・ノードは、シーケンス番号のマスタ・コピーを保持します。マスタ・コピーは、データベースのマウント中、および Lock と $Increment の使用ごとにインクリメントされます。シーケンスのマスタ値は、処理の種類によって、1 つあるいはすべてのクラスタ・ノードに送信されます。
シーケンス番号は、ジャーナル・リストアの特別な形式であるクラスタ・ジャーナル・リストアとシャドウイングで使用されます。両方のユーティリティは、シーケンス番号がクラスタ・セッション中に単調増加するという前提で動作します。
バックアップの最後に、すべてのクラスタ・ノード上のクラスタ・ジャーナルのシーケンス番号が増加し、前のマスタ・クラスタ・ジャーナルのシーケンス番号より大きくなります。次に、新しいクラスタ・ジャーナルのシーケンス番号を持つジャーナル・マーカが、現在のローカル・ジャーナル・ファイルに配置されます。ある意味では、ジャーナル・マーカはクラスタ・ジャーナルのシーケンス番号のバリアとして働き、バックアップの対象であるジャーナルされたデータベース更新を、バックアップされなかったものから分離します。バックアップのリストアに続き、ジャーナル・マーカのクラスタ・ジャーナルのシーケンス番号からクラスタ・ジャーナルのリストアが始まり、番号が増加する方向に処理が進みます。
また、^JRNMARK ユーティリティを使って独自のジャーナル・マーカを設定することもできます。詳細は、"クラスタ化されたシステムでのジャーナル・マーカの設定" を参照してください。
クラスタ・フェイルオーバー
あるクラスタ・メンバで障害が発生した場合、Caché クラスタ・フェイルオーバー処理は、他のクラスタ・ノード上のデータの整合性を維持します。これにより、残ったクラスタ・メンバは機能を継続できます。クラスタ・フェイルオーバーが正常に動作するには、以下の条件を満足している必要があります。
-
CACHE.DAT ファイルを含むすべてのディレクトリには、動作中のすべてのノードからアクセス可能であること。
-
Caché の実行中は、ジャーナリングが常に有効であること。
-
ネットワーキングが適切に構成されていること。
クラスタ・メンバで障害が発生した場合、クラスタ・マスタはクラスタ・フェイルオーバーを実行します。マスタが障害ノードである場合、そのクラスタでの所属期間が最も長いクラスタ・メンバが新しいマスタになり、フェイルオーバーを実行します。クラスタ・フェイルオーバーには、2 つのフェーズがあります。
1 番目のフェーズでは、クラスタ・マスタは以下を実行します。
-
それぞれのノード上にあるクラスタ PIJ とライト・イメージ・ファイル(CACHE.WIJ) を確認し、どのリカバリが必要であるかを判断します。
-
WIJ ファイルから、クラスタ・モードでマウントされたすべてのデータベースにリカバリを実行します。
このフェーズ中にエラーが発生した場合、クラスタがクラッシュし、さらにクラスタ・リカバリを実行する必要があります。
2 番目のフェーズでは、クラスタ・マスタは以下を実行します。
-
すべてのクラスタ・メンバのジャーナルをリストアするために、必要に応じて、プライベート・モードでデータベースを個別にマウントします。
-
プライベート・モードでマウントできない場合、クラスタ・モードでデータベースのマウントを試行します。
-
それぞれのクラスタ・メンバのジャーナル用に CACHE.WIJ ファイルに保存され、現在のインデックスの後ろに存在する Caché ジャーナル・エントリをすべてリストアします。詳細は、"クラスタ・リストア" を参照してください。
-
ノードで失敗したジャーナル・ファイルにある不完全なトランザクションをロールバックします。
-
新しいクラスタ・マスタの場合、ロック・テーブルを変更します。それ以外の場合は、失敗したノードのロックを破棄します。
フェイルオーバー中、すべてのクラスタ・メンバからのジャーナルは、データベースに適用され、不完全なトランザクションはすべてロールバックされます。クラスタ・フェイルオーバーが適切に完了したら、データベースの劣化や残りのノードからのデータの損失がなくなります。失われるデータはわずか (通常は、最後の 1 秒未満) であり、障害が発生したノードから他のクラスタ・メンバには認識できない程度ですみます。
フェイルオーバーが正常に動作しない場合、クラスタがクラッシュするため、すべてのクラスタ・ノードを停止してからクラスタを再開する必要があります。詳細は、"フェイルオーバーのエラー条件" のセクションを参照してください。
クラスタ・リカバリ
Caché がクラスタ・メンバ上で停止するとリカバリが発生します。どのように Caché が停止したかによって、手順が変わります。正常なフェイルオーバーでは、リカバリ手順は極めて簡単で自動的に行われます。しかし、クラスタ化されたシステムがクラッシュした場合、リカバリはより複雑になります。
クラスタでクラッシュが発生すると、クラスタ化された Caché のノードは、クラスタ内のすべてのノードが停止されるまでリストアされません。他のすべてのクラスタ・メンバが停止される前に、クラスタ・メンバが Caché スタートアップや、ディスクをクラスタ・マウントすることによってクラスタに結合しようとする場合、以下のメッセージが表示されます。
ENQ daemon failed to start because cluster is crashed.
すべてのメンバが停止されると、それぞれのノードを開始します。開始する最初のノードは、異常なシステム・シャットダウンを検知すると、Caché リカバリ手順を実行します。このノードが新しいクラスタ・マスタになります。クラスタ・マスタではないクラスタ・メンバは、スレーブ・ノードとも呼ばれます。
リカバリ・デーモン (RCVRYDMN) は、クラッシュしたノードがマスタかスレーブかにより、動作中のマスタ・ノードあるいは新規のマスタ・ノード上でリカバリを実行します。リカバリを有効にするには、ノードのデータベースと WIJ ファイルをクラスタ全体でアクセス可能にする必要があります。マスタは、それぞれのノード上の WIJ ファイルを基に、クラスタ全体のリカバリを管理します。
スレーブがクラッシュすると、マスタ・ノード上のリカバリ・デーモンが以下を実行します。
-
WIJ ファイルによって提供されるジャーナル情報を使用して、すべてのクラスタ・ジャーナル・リストアと同様に、共通の起動ポイントからすべてのクラスタ・ノード (クラッシュしたノードを含む) にジャーナル・ファイルを適用します。
-
クラッシュしたシステムのすべての不完全なトランザクションがロールバックされます。この場合には、リカバリ・デーモンのホスト・システム上にロールバックがジャーナルされます。このため、ジャーナル・ファイルをリストアする場合、あるノードのジャーナルの不完全なトランザクションのロールバックが別のノード上にジャーナルされるので、スタンドアロン・ジャーナル・リストアよりクラスタ・ジャーナル・リストアを実行する方が安全です。
(前の) マスタがクラッシュすると、リカバリ・デーモンが以下を実行します。
-
前述の手順 1 にあるように、すべてのクラスタ・ノード上でジャーナル・ファイルが適用されます。
-
前述の 2 つの手順の間で、新しいマスタであるホスト・システム上のクラスタ・ジャーナルのシーケンス番号が調整され、古いマスタであるクラッシュしたシステム上の最後のジャーナル・エントリのシーケンス番号より大きくなるように設定されます。これにより、クラスタ全体のジャーナル・ファイルにおいてクラスタ・ジャーナル・シーケンスの単調増加プロパティが保証されます。
-
前述のように、クラッシュしたシステムですべての不完全なトランザクションがロールバックされます。
クラスタの最後のノードがクラッシュした場合、クラスタの最初のノードの再開にクラスタ・ジャーナル・リカバリが含まれます。これには、クラッシュした時点でオープンしていた (コミットされていない) トランザクションのロールバックが含まれています。
クラスタ・リストア
通常、バックアップがリストアされてデータベースを最新の状態にするか、クラッシュの時点の状態に復元した後に、ジャーナル・ファイルが適用されます。最後のバックアップ以降にクラスタから離脱したノードまたは新たに参加したノードがない場合は、そのバックアップに対応するマーカからジャーナル・ファイルのリストアを開始できます。最後のバックアップ以降に 1 つ以上のノードがクラスタに参加している場合は、リストアはかなり複雑になります。
ノードは、ノードが適切な構成で再開するか、起動後にクラスタがデータベースをマウントすると、クラスタに接続します (起動時に PIJ ディレクトリなどのその他のパラメータを適切に設定している場合)。後者の場合にジャーナル・リストアを簡単に行うには、ノードがクラスタに接続するとすぐにノード上のジャーナル・ファイルを切り替えます。
クラスタの最後のバックアップ以降にクラスタに参加した各ノードについては、以下を実行します。
-
ノードの最新バックアップをリストアします。
-
ノードがクラスタに参加する前にバックアップが発生していた場合、そのバックアップの終了時点からノードがクラスタに参加した時点までの、個別のジャーナル・ファイルをリストアします (ノードがクラスタに参加したときにジャーナル・ファイルを切り替えておくと、この手順が容易になります)。
-
最新のクラスタ・バックアップをリストアします。
-
バックアップが終了したところからクラスタ・ジャーナル・ファイルをリストアします。
このユーティリティの実行に関する詳細は、"クラスタ・ジャーナル・リストア" を参照してください。
クラスタに参加する前のノードで個別にマウントされたデータベースが、そのノードがクラスタに参加した後でクラスタにマウントされている場合は、この手順によるデータベースのリストアが最適です。これは、以下の点を前提にしています。
-
クラスタ・バックアップではすべてのクラスタ・マウントされているデータベースを扱い、システムのみのバックアップでは個別のデータベースを扱っていること。定義上、個別のデータベースとは、クラスタの別のシステムからはアクセスできないものを指します。
-
目的のノードが、最後のクラスタ・バックアップ以降にクラスタを離脱したものではなく、それ以降にクラスタに参加したものでもないこと。
さらに複雑なシナリオでは、これらの前提が成り立たないことがあります。例えば、すべてのクラスタ・マウント・データベースを 1 つのノードで集中的にバックアップするのではなく、個別のデータベースと選択したクラスタ・マウント・データベースを各ノードでバックアップするように構成している場合、1 番目の前提は成り立たなくなります。
この場合、一度に 1 つのデータベースをリストアすることによって分散型の方法を採る必要があります。それぞれのデータベースでは、リストア手順は基本的に同じです。
-
そのデータベースを扱う最新バックアップをリストアします。
-
バックアップ後にクラスタに参加したノードについては、その参加時点までの個別のジャーナル・ファイルをリストアします。
-
その時点から時間順にクラスタ・ジャーナル・ファイルをリストアします。
データベースが常に同じノード上に個別にマウントされているとしても、そのノードのジャーナル・ファイルのみを適用するよりも、クラスタ・ジャーナル・ファイルをリストアするほうが安全です。ノードがクラスタの一部であると、ノードがクラッシュまたは終了した場合に、ノード上のオープン・トランザクションは、クラスタの動作中のノードによってロールバックされ、クラスタの動作中のノード上にジャーナルされます。クラスタ・ジャーナル・ファイルをリストアすることにより、別のノードのジャーナル・ファイルでロールバックし続けることができます。
インターシステムズでは、ノードが何度もクラスタに参加したり、クラスタから離脱するシナリオをお勧めしていませんし、サポートしていません。
フェイルオーバーのエラー条件
クラスタ・メンバで障害が発生した場合、他のクラスタ・メンバは、フェイルオーバーにより生じた短い休止を認識します。まれな状況下では、動作中のクラスタ・ノード上のプロセスが、<CLUSTERFAILED> エラーを受信することがあります。$ZTRAP エラー・トラッピング機能により、これらのエラーをトラップできます。
以下のいずれかの条件が存在する場合、クラスタ・フェイルオーバーは実行されません。
-
1 つ以上のクラスタ・メンバがフェイルオーバー処理中に中断した場合
-
ディスク・ドライブに障害が発生し、フェイルオーバーの最初のフェーズでエラーが発生した場合
-
動作中のクラスタ・メンバの 1 つが、リカバリ・デーモンを持たない場合
フェイルオーバーが失敗した場合、クラスタはクラッシュし、以下のメッセージがオペレータのコンソールに表示されます。
****** Caché : CLUSTER CRASH - ALL Caché SYSTEMS ARE SUSPENDED ******
Caché の処理が Set コマンドや Kill コマンドに到達すると、他のクラスタ・メンバはフリーズします。
クラスタ・マスタのコンソール・ログ (通常、管理者のディレクトリにある cconsole.log) に含まれるフェイルオーバー・ログを検証して、フェイルオーバー処理中に発生したエラー・メッセージを参照します。
以下のメッセージは、失敗したクラスタ・メンバの起動を試みたり、クラスタがフェイルオーバー中にデータベースをクラスタ・マウントすることによって、ノードがクラスタに接続しようとする場合に表示されます。
The cluster appears to be attempting to recover from the failure of one or more members at this time. Waiting 45 seconds for failover to complete...
実行中のリカバリ・フェーズが完了するまで、5 秒ごとにピリオド (.) が表示されます。その後、マウントまたは起動が開始されます。
この間にクラスタがクラッシュすると、以下のメッセージが表示されます。
ENQ daemon failed to start because cluster is crashed.
クラスタがクラッシュした場合の結果に関する説明は、"クラスタ・リカバリ" のセクションを参照してください。
クラスタ・シャドウイング
クラスタ化されたシステム内でジャーナリングを使用すると、Caché クラスタをシャドウイングすることもできます。クラスタ内で、それぞれのノードはそれ自身のジャーナル・ファイルを管理しています。ジャーナル・ファイルには、個別データベースあるいはクラスタ・マウントされたデータベースに関連するデータが含まれています。シャドウは、TCP 経由でクラスタに接続されている Caché システム上のデータベースへの変更をミラーします (すべての変更がジャーナルされていることを前提としています)。以下の図では、クラスタ・シャドウイング処理の概要を表しています。
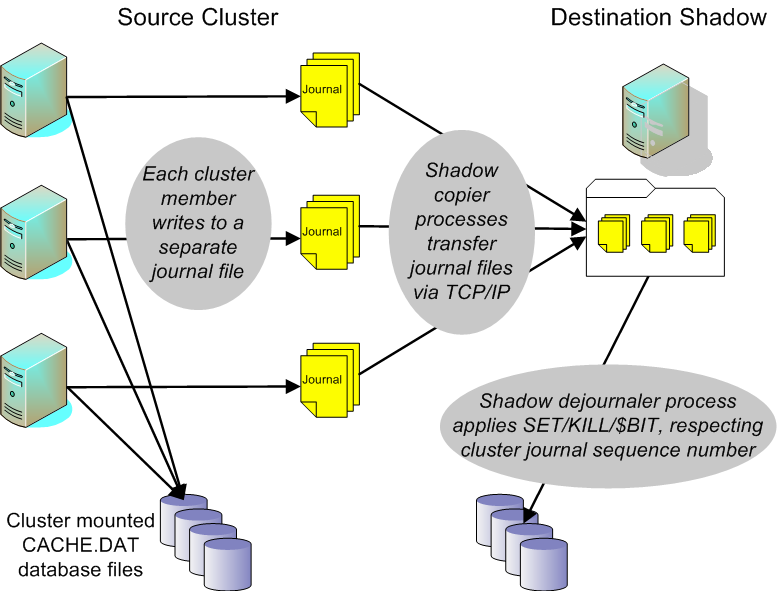
宛先のシャドウは、クラスタ上の指定された Caché スーパーサーバに接続して、指定された開始位置 (クラスタの開始時間とクラスタ・ジャーナルのシーケンス番号の組み合わせ) 以降のジャーナル・ファイルのリストを要求します。ジャーナル・ファイルは、クラスタ・メンバごとに 1 つ存在する開始ファイルです。
ソース・クラスタから返されるそれぞれのノード (一意のCSN を持つ) に対して、シャドウは、ジャーナル・ファイルをサーバからシャドウにコピーするコピー側処理を、返されたファイルから順に開始します。それぞれのコピー側は、クラスタ化されていないブロック・モードのシャドウと類似した、なかば独立したシャドウとして動作します。
すべてのコピー側が起動され実行中になると、クラスタ・シャドウはデジャーナリング処理を開始します。デジャーナリング処理は、各ジャーナル・レコードのクラスタ・ジャーナルのシーケンス番号に従って、コピー元のジャーナル・ファイルからシャドウ側のデータベースにジャーナル・エントリを適用します。クラスタ・シャドウは、ソース・クラスタから受信するクラスタの現在動作中のメンバのリスト (ポート番号と IP アドレスを含む) を保持します。
以下のセクションでは、クラスタ・シャドウの設定に必要な情報と関連するプロシージャについて説明すると同時に、シャドウ・データベースの完全性と適時性の限界についても説明します。
シャドウは、クラスタ化されたシステムである必要はありません。クラスタ・シャドウイングにおける “クラスタ” は、シャドウではなくソース・データベース・サーバを表しています。
クラスタ・シャドウの構成
クラスタ・シャドウを適切に構成するには、複数のタイプの情報が必要です。必要なデータ項目の概要は、以下のカテゴリに分類されます。
クラスタは、すべてのメンバ・ノードが共有する PIJ ディレクトリによって識別されますが、この識別子の一意性は、Caché クラスタをホストする物理クラスタの範囲にとどまります。シャドウでは、ソース・クラスタに TCP 接続する方法が必要です。したがって、シャドウ上では、Caché クラスタのあるメンバの IP アドレスまたはホスト名と、そのメンバ上で稼動するスーパーサーバのポート番号を指定する必要があります。さらに、同じ Caché インスタンス内でそのシャドウを別のシャドウ (存在する場合) から区別する一意の ID を提供する必要があります。
デジャーナリングのためにジャーナルの開始位置として、クラスタの開始時間 (CSI) および必要に応じてクラスタ・ジャーナルのシーケンス番号を識別するようにシャドウを構成します。クラスタ・ジャーナルのシーケンス番号を指定しない場合は、デジャーナリングはクラスタ・セッションの最初から開始されます。
非クラスタ・シャドウイングと同様に、クラスタからコピーするジャーナル・ファイルの保存先とするディレクトリを指定します。ただし、1 つのディレクトリでは不十分です。クラスタの異なるメンバからのジャーナル・ファイルは、それぞれ別のディレクトリに保存する必要があります。指定したディレクトリは、ジャーナル・ファイルのシャドウ・コピー用の親ディレクトリとして機能します。実際に、シャドウは進行中にディレクトリを作成して、クラスタ・コンポーネントの動的特性に対応できるようにします。
実行時、シャドウは、サーバ・クラスタ上のそれぞれのジャーナル・ディレクトリに対して、ユーザ指定の親ディレクトリの下に個別のサブディレクトリを設定し、サーバ上のジャーナル・ディレクトリからシャドウ上の対応するディレクトリにジャーナル・ファイルをコピーします。これをジャーナル・ファイルのリダイレクトと呼びます。サブディレクトリには 1 から始まる連番の名前が付けられます。サーバ上のジャーナル・ディレクトリにシャドウ上の別のディレクトリを指定してリダイレクトを上書きすることはできません。
クラスタ化されていないシャドウイングでは、データベース・マッピングか、デジャーナルされた Set トランザクションと Kill トランザクションのリダイレクトを指定します。
クラスタの宛先シャドウを設定する情報を提供するには、以下の 2 つの方法があります。
管理ポータルの使用
管理ポータルを使用してシャドウ・サーバを構成できます。以下の手順を実行します。
-
管理ポータルの システム管理, 構成, 接続性, シャドウサーバ設定 ページから、“シャドウイング” の章にある "宛先のシャドウ・サーバの構成" のセクションで説明する手順を実行します。クラスタ・シャドウイングに固有の以下の特性を使用します。
-
[データベースサーバ] — シャドウが接続するソース・クラスタのあるメンバの IP アドレスあるいはホスト名 (DNS) を入力します。
-
[データベースサーバポート番号] — 前の手順で指定したソースのポート番号を入力します。
-
-
ソース・インスタンスの位置情報を入力後、[ソースイベントを選択] をクリックして、シャドウイングを開始する位置を選択します。ページには、クラスタ・ジャーナル・ファイル・ディレクトリにある利用可能なクラスタ・イベントが表示されます。
-
[詳細] をクリックし、[ジャーナル・ファイル・ディレクトリ] フィールドに入力します。シャドウ・ジャーナル・ファイルのサブディレクトリの親ディレクトリとして機能する、宛先シャドウ・システムのジャーナル・ファイル・ディレクトリのフルパス名を入力します。このディレクトリは、ソース・クラスタ上の各ジャーナル・ディレクトリに対してシャドウが自動的に作成したものです。適切なディレクトリを検索するには、[参照] をクリックします。
-
この構成設定を正常に保存した後、クラスタからシャドウへのデータベース・マッピングを追加します。
-
[このシャドウのデータベース・マッピング] の横にある [追加] をクリックし、[シャドウ・マッピングの追加] ダイアログ・ボックスを使用して、ソース・システムのデータベースを宛先システムのディレクトリに関連付けます。
-
[ソース・データベース・ディレクトリ] ボックスに、ソース・データベース・ファイル CACHE.DAT の物理パス名を入力します。[シャドウ・データベース・ディレクトリ] ボックスに、ソース・データベース・ファイルに対応する宛先のシャドウ・データベース・ファイルのパス名を入力して、[保存] をクリックします。
-
事前に入力されたマッピングがあるかどうかを確認して、無効または不要なマッピングの横にある [削除] をクリックします。シャドウイングを開始するには、少なくとも 1 つのデータベース・マッピングが必要です。
-
シャドウイングを開始します。
Caché ルーチンの使用
さらに、Caché が提供するシャドウイング・ルーチンを使用して、クラスタ・シャドウを構成できます。このセクションの各例では、ルーチンを実行した結果の返りコードを設定する方法を使います。エラーの返りコードあるいは成功の 1 を確認します。
クラスタ・シャドウを最初に構成するには、以下の手順を実行します。
Set rc=$$ConfigCluShdw^SHDWX(shadow_id,server,jrndir,begloc)| 要素 | 説明 |
|---|---|
| shadow_id | シャドウを一意に識別する文字列。 |
| server | スーパーサーバのポート番号および 1 つのクラスタ・ノードの IP アドレスまたはホスト名をコンマで区切って記述した文字列。 |
| jrndir | シャドウ・ジャーナル・ファイルのサブディレクトリの親ディレクトリ。ソース・クラスタから取り出されたジャーナル・ファイルが宛先のシャドウ上で格納される場所であり、ソース・クラスタ上の各ジャーナル・ディレクトリに対して 1 つのサブディレクトリがあります。 |
| begloc | コンマで区切られたクラスタ・セッション ID (YYYYMMDD HH:MM:SS 形式のクラスタ起動時間) とクラスタ・シーケンス番号で構成される開始位置。 |
ルーチンを再度実行して、server、jrndir、begloc の値を変更できます。新しい値を jrndir に指定した場合、ソースから取り出された後続のジャーナル・ファイルのみが新しい位置に格納されます。既に古い位置にあるジャーナル・ファイルは、そのままになります。
さらに、シャドウに指示して、jrndir の既定のサブディレクトリではなく、ローカル・リポジトリ locdir のソースにあるジャーナル・ディレクトリ remdir から取り出したジャーナル・ファイルを格納できます。ここでの変更は、これから取り出すジャーナル・ファイルにのみ影響を与え、これまで取り出したジャーナル・ファイルには影響を与えません。
Set rc=$$ConfigJrndir^SHDWX(shadow_id,locdir,remdir)シャドウについての最後の必須情報である Set および Kill のトランザクション・リダイレクトは、以下のように指定できます。
Set rc=$$ConfigDbmap^SHDWX(shadow_id,locdir,remdir)これは、ソース・ディレクトリ remdir からの Set トランザクションと Kill トランザクションが、シャドウ・ディレクトリ locdir にリダイレクトされることを指定しています。ジャーナル・ファイルと異なり、ソース・データベースには既定のリダイレクトは存在しません。明示的にリダイレクトされない場合は、データベースからの Set トランザクションと Kill トランザクションは、シャドウのデジャーナリング処理によって無視されます。
最後に、シャドウイングを開始および終了するには、以下を実行します。
Set rc=$$START1^SHDWCLI("test")
Set rc=$$STOP1^SHDWCLI("test")
詳細は、"シャドウ情報のグローバルとユーティリティ" を参照してください。
クラスタ・シャドウイングの限界
クラスタ・シャドウイング処理にはいくつかの限界があります。
クラスタ外でジャーナルされるデータベースの更新は、シャドウイングされません。以下は、その 2 つの例です。
-
クラスタが停止した後で、クラスタの以前のメンバが、スタンドアロン・システムとして起動し、いくつかの (以前にクラスタ化された) データベースに対して更新を発行する場合、更新はシャドウに反映されません。
-
以前のスタンドアロン・システムがクラスタに参加した後、個別のデータベースに発生した新しい更新は、シャドウに反映されます (データベース・マッピングで定義されている場合) が、システムがクラスタに参加する前に発生した更新はシャドウには反映されません。したがって、実行中のクラスタにシステムを参加させる場合 (データベースのクラスタ・マウントによる) は、クラスタのすべてのシャドウとの調整を注意して計画する必要があります。
クラスタ・シャドウイングでは、デジャーナル機能に影響を与える待ち時間があります。宛先のシャドウ側のジャーナル・ファイルは、ソース・クラスタ上でジャーナルされるものと同様に最新にする必要はありません。シャドウは、プロダクション・サーバ上で性能に影響しないように、プロダクション・ジャーナルを非同期的に適用します。これにより、シャドウ・サーバに適用されるデータに、待ち時間が発生します。
1 つのマシンには複数のシャドウがありますが、一度に 1 つの Caché クラスタのみが、クラスタ・シャドウのターゲットとなります。複数のシャドウの相互処理は保証されていません。したがって、ユーザは、複数のシャドウを相互排他的に使用する必要があります。異なるクラスタをポイントする複数のシャドウを持つ 1 つのインスタンスの場合、シャドウのデータセットを相互排他的に使用する必要があります。例えば、1 台のマシン上にシャドウイングされる 2 つのクラスタ (A および B) があると仮定します。クラスタ A はデータセット X、Y、Z を持ち、クラスタ B はデータセット L、M、N を持ちます。Caché では、データセット X (クラスタ A) とデータセット L (クラスタ B) がデジャーナリング・プロセスで相互排他的に使用されること (つまり、1 つのシャドウがデータセット X をデジャーナリングする間、別のシャドウがデータセット L をデジャーナリングすること) は保証されないため、ユーザはデータセットが重複しないようにする必要があります。
Symantec Antivirus ソフトウェアを使用する場合、RTVScan から Caché データベースを除外して、Windows XP上でクラスタ・シャドウが停止することを防止します。詳細は、"Release Notes for Symantec AntiVirus Corporate Edition 8.1.1 Opens in a new tab" を参照してください。
ツールとユーティリティ
以下のツールとユーティリティは、クラスタ・ジャーナリング処理に役立ちます。
-
クラスタ・ジャーナル・リストア — ^JRNRESTO
-
ジャーナル・ダンプ・ユーティリティ — ^JRNDUMP
-
スタートアップ・リカバリ・ルーチン — ^STURECOV
-
クラスタ化されたシステムでのジャーナル・マーカの設定 — ^JRNMARK
-
クラスタ・ジャーナル情報のグローバル — ^%SYS(“JRNINFO”)
-
シャドウ情報のグローバルとユーティリティ — ^SYS(“shdwcli”)
クラスタ・ジャーナル・リストア
クラスタ・ジャーナル・リストアの手順では、Caché バックアップによってジャーナル・ファイルに配置されたジャーナル・マーカを使用して、リストアを開始または終了できます。クラスタ・ジャーナル・リストアは、バックアップ・リストアの一部として、あるいはスタンドアロン・プロシージャとして実行できます。
Caché には、特定のクラスタ・ジャーナル・リストア処理を実行するためのジャーナル・リストア・インタフェースへのエントリ・ポイントが含まれます。%SYS ネームスペースから、以下を実行します。
Do CLUMENU^JRNRESTOこれにより、以下のオプションを含むメニューが呼び出されます。
クラスタ・ジャーナル・リストアの実行
クラスタ・ジャーナル・リストア・メニューの最初のオプションを使用すると、クラスタ化された、あるいはクラスタ化されていないシステム上で、一般的なジャーナル・リストアを実行できます。これは、^JRNRESTO を実行し、Cluster journal restore? プロンプトに Yes と応答することと同じです。
%SYS>Do ^JRNRESTO
This utility uses the contents of journal files
to bring globals up to date from a backup.
Replication is not enabled.
Restore the Journal? Yes => Yes
Cluster journal restore? Yes
ジャーナルからリストアするデータベースと、リストアの開始ポイントと終了ポイントを記述するように求められます。開始ポイントと終了ポイントは、バックアップ、ジャーナル・マーカ一式、クラスタ開始、あるいはジャーナル内の任意のポイントに基づきます。
インタフェースでは、リダイレクトの特性を含むディレクトリ情報について、およびすべてのデータベースとグローバルが処理されるかどうかについて尋ねるプロンプトが表示されます。以下はその例です。
Directory: _$1$DKB300:[TEST.CLU.5X]
Redirect to Directory: _$1$DKB300:[TEST.CLU.5X] => _$1$DKB300:[TEST.CLU.5X]
--> _$1$DKB300:[TEST.CLU.5X]
Restore all globals in _$1$DKB300:[TEST.CLU.5X]? Yes => Yes
Directory:
入力する各ディレクトリで、リダイレクトするかどうかを尋ねられます。デジャーナルされるグローバルをリストアするディレクトリの名前を入力します。これが同じディレクトリの場合、ピリオド記号 (.) を入力するか、Enter を押します。
さらに、ジャーナルされたすべてのグローバルをリストアするかどうかを、ディレクトリごとに指定します。Yes を入力するか Enter を押して、すべてのグローバル変更をデータベースに適用し、次のディレクトリに進みます。それ以外の場合は、No を入力して選択したグローバルのみをリストアします。
Global ^ プロンプトで、ジャーナルからリストアする特定のグローバル名を入力します。任意の文字数に一致するアスタリスク (*) と、任意の単一文字に一致する疑問符 (?) を使用して、グローバルのパターンを選択することができます。?L を入力して現在選択されているグローバルのリストを表示します。
選択したすべてのグローバルを入力した場合は、Global^ プロンプトで Enter を押して、次のディレクトリを入力します。すべてのディレクトリを入力した場合は、Directory プロンプトで Enter を押します。リストア指定が、以下の例に示すように表示されます。
Restoring globals from the following clustered datasets:
1. _$1$DKB300:[TEST.CLU.5X] All Globals
Specifications for Journal Restore Correct? Yes => Yes
Updates will not be replicated
クラスタ・ジャーナル・リストアを継続する前に入力した情報を検証します。設定が正しい場合、Yes と応答するか Enter を押します。ディレクトリとグローバルの入力処理を繰り返すには、No と応答します。
ディレクトリおよびグローバル指定を検証すると、クラスタ・ジャーナル・リストア設定処理のメイン設定メニューが、以下の例に示すように、現在の既定の設定と共に表示されます。
Cluster Journal Restore - Setup - Main Settings
1. To LOCATE journal files using cluster journal log
_$1$DKB400:[TEST.5X]CACHEJRN.LOG
with NO redirections of journal files
2. To START restore at the beginning of cluster session <20030319 15:35:37>
3. To STOP restore at sequence #319 of cluster session <20030319 15:35:37>
134388,_$1$DRA2:[TEST.5Y.JOURNAL]20030320.005
4. To SWITCH journal file before journal restore
5. To DISABLE journaling the dejournaled transactions
Select an item to modify ('Q' to quit or ENTER to accept and continue):
このメニューから、メニュー項目番号を入力することにより、5 つの設定のすべての既定値を選択して変更できます。
それぞれの変更後に、メイン設定メニューが再び表示され、リストアを開始する前に入力した情報を検証するように求められます。以下は、いくつかの変更後のメニューの表示例です。
Cluster Journal Restore - Setup - Main Settings
1. To LOCATE journal files using cluster journal log
_$1$DKB400:[TEST.5Y.MGR]CACHEJRN.TXT
with redirections of journal files
_$1$DKB400:[TEST.5X.JOURNAL] -> _$1$DRA2:[TEST.5X.JOURNAL]
_$1$DKB400:[TEST.5Y.JOURNAL] -> _$1$DRA2:[TEST.5Y.JOURNAL]
_$1$DKB400:[TEST.5Z.JOURNAL] -> _$1$DRA2:[TEST.5Z.JOURNAL]
2. To START restore at the journal marker located at
138316,_$1$DKB400:[TEST.5X.JOURNAL]20030401.001
-> _$1$DRA2:[TEST.5X.JOURNAL]20030401.001
3. To STOP restore at the journal marker located at
133232,_$1$DKB400:[TEST.5X.JOURNAL]20030401.003
-> _$1$DRA2:[TEST.5X.JOURNAL]20030401.003
4. NOT to SWITCH journal file before journal restore
5. To DISABLE journaling the dejournaled transactions
Select an item to modify ('Q' to quit or ENTER to accept and continue):
Start journal restore?
Enter を押して、設定を受け入れて継続します。現在のクラスタのジャーナル・ログを使用している場合、リストアが現在マークされたジャーナル位置で停止することを通知され、リストアを開始するかどうかを尋ねられます。
Select an item to modify ('Q' to quit or ENTER to accept and continue):
To stop restore at currently marked journal location
offset 134168 of _$1$DRA1:[TEST.50.MGR.JOURNAL]20031002.008
Start journal restore?
Yes と入力し、クラスタ・ジャーナル・リストアを開始します。リストアが完了すると、システムはいつでも動作できる状態になります。
No と入力し、クラスタ・ジャーナル・リストア設定への変更を続けるためメイン・メニューに戻るか、Q を入力して、クラスタ・ジャーナル・リストアを中止します。クラスタ・ジャーナル・リストアを中止後、個別のジャーナル・リストアを実行するか、完全にリストア処理を中止できます。
Select an item to modify ('Q' to quit or ENTER to accept and continue): Q
Run private journal restore instead? No
[Journal restore aborted]
Replication Enabled
リストアのソースを変更する
メイン設定メニューの最初の項目には、すべてのクラスタ・メンバ用のジャーナル・ファイルを検出するために必要な情報が含まれています。情報には、2 つの要素があります。
-
クラスタ・ジャーナル・ログ — ジャーナル・ファイルのリストとそれらの元のフルパス。
-
ジャーナル・ファイルのリダイレクト — リストアを実行中のシステムがジャーナル・ログと関連するクラスタの一部ではない場合にのみ必要。
既定では、リストアは、現在のクラスタ化されたシステムに関連するクラスタ・ジャーナル・ログを使用します。クラスタ化されていないシステムでリストアを実行する場合には、メイン・メニューが表示される前にクラスタ・ジャーナル・ログを求められます。
このオプションを選択して、ジャーナル・ファイルを持つクラスタから異なる Caché クラスタ上のジャーナル・ファイルをリストアします。以下のいずれかを実行できます。
-
元のクラスタによって使用されるクラスタ・ジャーナル・ログを識別する。
-
ジャーナル・ファイルを配置する位置を指定するクラスタ・ジャーナル・ログを作成する。
ジャーナル・ファイルをリダイレクトするオプションは、指定したクラスタ・ジャーナル・ログが現在のクラスタのログではない場合にのみ利用可能です。
クラスタ・ジャーナル・ログを識別する
[ジャーナル・ファイル情報] メニューには、クラスタ・ジャーナル・リストアで使用するクラスタ・ジャーナル・ログ・ファイルが表示されます。元のクラスタのジャーナル・ファイルが現在のクラスタにアクセスできない場合、それらのジャーナル・ファイルを現在のクラスタにアクセスできる位置にコピーし、リダイレクト情報を入力して、それらを配置する方法を指定します。
I と入力して、元のクラスタで使用するジャーナル・ログを識別します。
Select an item to modify ('Q' to quit or ENTER to accept and continue): 1
Cluster Journal Restore - Setup - Journal File Info
[I]dentify an existing cluster journal log to use for the restore
Current: _$1$DRA1:[TEST.50]CACHEJRN.LOG
- OR -
[C]reate a cluster journal log by specifying where journal files are
Selection ( if no change): I
*** WARNING ***
If you specify a cluster journal log different from current one, you
may need to reenter info on journal redirection, restore range, etc.
Enter the name of the cluster journal log ( if no change)
=> cachejrn.txt
Cluster Journal Restore - Setup - Journal File Info
[I]dentify an existing cluster journal log to use for the restore
Current: _$1$DRA1:[TEST.50.MGR]CACHEJRN.TXT
[R]edirect journal files in _$1$DRA1:[TEST.50.MGR]CACHEJRN.TXT
- OR -
[C]reate a cluster journal log by specifying where journal files are
リストア中のジャーナル・ファイルが元の位置にない場合、クラスタ・ジャーナル・ログで指定されるように、ジャーナル・ファイルをリダイレクトする必要があります。クラスタ・ジャーナル・ログに記載されているジャーナル・ファイルをリダイレクトするには、指示に従って元の位置と現在の位置を入力します。元の位置として、ディレクトリ名のすべてまたは一部を指定することができます。部分名に一致する開始文字を持つ元の位置は、すべて新しい位置と置き換わります。リダイレクト・ファイルの例は、以下のとおりです。
Selection ( if no change): R
Journal directories in _$1$DRA1:[TEST.50.MGR]CACHEJRN.TXT
_$1$DRA1:[TEST.50.MGR.JOURNAL]
_$1$DRA1:[TEST.5A.MGR.JOURNAL]
_$1$DRA1:[TEST.5B.MGR.JOURNAL]
Enter the original and current locations of journal files (? for help)
Journal files originally from: _$1$DRA1:
are currently located in: _$1$DRA2:
_$1$DRA1:[TEST.50.MGR.JOURNAL] -> _$1$DRA2:[TEST.50.MGR.JOURNAL]
_$1$DRA1:[TEST.5A.MGR.JOURNAL] -> _$1$DRA2:[TEST.5A.MGR.JOURNAL]
_$1$DRA1:[TEST.5B.MGR.JOURNAL] -> _$1$DRA2:[TEST.5B.MGR.JOURNAL]
Journal files originally from:
Cluster Journal Restore - Setup - Journal File Info
[I]dentify an existing cluster journal log to use for the restore
Current: _$1$DRA1:[TEST.50.MGR]CACHEJRN.TXT
[R]edirect journal files in _$1$DRA1:[TEST.50.MGR]CACHEJRN.TXT
- OR -
[C]reate a cluster journal log by specifying where journal files are
Selection ( if no change):
この例では、代替のクラスタ・ジャーナル・ログ CACHEJRN.TXT の選択が表示されています。このクラスタ・ジャーナル・ログには、本来 _$1$DRA1: にあったジャーナル・ファイルのリストが含まれています。リストア中に、これらのファイルは、新しい位置 _$1$DRA2: から取得され、リダイレクトされます。
リダイレクト情報の入力が完了したら、Enter を押して [メイン設定] メニューに戻ります。
ジャーナル・リダイレクトでは、ソース・ディレクトリとターゲット・ディレクトリの位置の間の一対一または多対一のリレーションシップを想定しています。つまり、1 つあるいは複数の元のディレクトリからのジャーナル・ファイルは、1 つの新しい位置に置かれることはありますが、複数の新しい位置に置かれることはありません。複数の新しい位置にあるジャーナル・ファイルからリストアするには、ジャーナル・ファイルの配置位置を指定するクラスタ・ジャーナル・ログを作成します。
クラスタ・ジャーナル・ログを作成する
元のクラスタにあるジャーナル・ファイルが現在のクラスタにアクセスできない場合、ジャーナル・ファイルの位置を指定するクラスタ・ジャーナル・ログを作成します。指定された位置にあるファイルは、すべてクラスタの一部である必要があります。それらのファイルを現在のクラスタにアクセスできる場所にコピーし、リダイレクト情報を入力して、それらの配置方法を指定します。
Selection ( if no change): C
*** WARNING ***
If you specify a cluster journal log different from current one, you
may need to reenter info on journal redirection, restore range, etc.
Enter the name of the cluster journal log to create (ENTER if none) =>
cachejrn.txt
How many cluster members were involved? (Q to quit) => 3
For each cluster member, enter the location(s) and name prefix (if any) of the
journal files to restore --
Cluster member #0 Journal File Name Prefix:
Directory: _$1$DRA1:[TEST.50.MGR.JOURNAL]
Directory:
Cluster member #1 Journal File Name Prefix:
Directory: _$1$DRA1:[TEST.5A.MGR.JOURNAL]
Directory:
Cluster member #2 Journal File Name Prefix:
Directory: _$1$DRA1:[TEST.5B.MGR.JOURNAL]
Directory:
この例では、元は _$1$DRA1: にあったジャーナル・ファイルを持つ 3 つのメンバから成るクラスタについて、クラスタ・ジャーナル・ログ CACHEJRN.TXT を作成しています。
次のメニューには、追加オプションが含まれており、作成したクラスタ・ジャーナル・ログにあるジャーナル・ファイルをリダイレクトすることができます。
Cluster Journal Restore - Setup - Journal File Info
[I]dentify an existing cluster journal log to use for the restore
Current: _$1$DRA1:[TEST.50.MGR]CACHEJRN.TXT
[R]edirect journal files in _$1$DRA1:[TEST.50.MGR]CACHEJRN.TXT
- OR -
[C]reate a cluster journal log by specifying where journal files are
Selection ( if no change):
R と入力して、"クラスタ・ジャーナル・ログを識別する" で説明しているようにファイルをリダイレクトします。リダイレクト情報の入力が完了したら、Enter を押して [メイン設定] メニューに戻ります。
リストアの開始ポイントを変更する
[メイン設定] メニューの 2 番目と 3 番目の項目では、ジャーナル・ファイルのリストアを開始する場所から終了する場所までの、リストアの範囲を指定します。開始ポイント情報には、ジャーナル・ファイルの開始と、それぞれのクラスタ・メンバのシーケンス番号が含まれています。既定の開始場所は、以下の順で決まります。
-
クラスタ・ジャーナル・リストアがバックアップ・リストア後に実行されると、最新のジャーナル・リストアの最後からジャーナルをリストアします。
-
バックアップ・リストアが現在のシステムで実行される場合、リストアされた最新のバックアップの最後からジャーナルをリストアします。
-
現在のシステムが使用中のクラスタ・ジャーナル・ログと関連付けられている場合、現在のクラスタ・セッションの最初からジャーナルをリストアします。
-
それ以外の場合、クラスタ・ジャーナル・ログの最初からジャーナルをリストアします。
Cluster Journal Restore - Setup - Main Settings
1. To LOCATE journal files using cluster journal log
_$1$DRA1:[TEST.50.MGR]CACHEJRN.TXT
with redirections of journal files
_$1$DRA1:[TEST.50.MGR.JOURNAL] -> _$1$DRA2:[TEST.50.MGR.JOURNAL]
_$1$DRA1:[TEST.5A.MGR.JOURNAL] -> _$1$DRA2:[TEST.5A.MGR.JOURNAL]
_$1$DRA1:[TEST.5B.MGR.JOURNAL] -> _$1$DRA2:[TEST.5B.MGR.JOURNAL]
2. To START restore at the end of last restored backup
_$1$DRA1:[TEST.50.MGR]CLUFULL.BCK
134120,_$1$DRA1:[TEST.50.MGR.JOURNAL]20031002.008
-> _$1$DRA1:[TEST.50.MGR.JOURNAL]20031002.008
3. To STOP restore at the end of the cluster journal log
4. To SWITCH journal file before journal restore
5. To DISABLE journaling the dejournaled transactions
Select an item to modify ('Q' to quit or ENTER to accept and continue): 2
Cluster Journal Restore - Setup - Where to Start Restore
1. At the beginning of a cluster session
2. At a specific journal marker
3. Following the restore of backup _$1$DRA1:[TEST.50.MGR]CLUFULL.BCK (*)
i.e., at the journal marker located at
134120,_$1$DRA1:[TEST.50.MGR.JOURNAL]20031002.008
Selection ( if no change): 1
To start journal restore at the beginning of cluster session ...
1. 20030904 09:47:01
2. 20031002 13:19:12
3. 20031002 13:26:40
4. 20031002 13:29:10
5. 20031002 13:51:31
6. 20031002 13:58:57
7. 20031002 14:29:42
8. 20031002 14:33:55
9. 20031002 14:35:48
=> 5
Cluster Journal Restore - Setup - Main Settings
1. To LOCATE journal files using cluster journal log
_$1$DRA1:[TEST.50.MGR]CACHEJRN.TXT
with redirections of journal files
_$1$DRA1:[TEST.50.MGR.JOURNAL] -> _$1$DRA2:[TEST.50.MGR.JOURNAL]
_$1$DRA1:[TEST.5A.MGR.JOURNAL] -> _$1$DRA2:[TEST.5A.MGR.JOURNAL]
_$1$DRA1:[TEST.5B.MGR.JOURNAL] -> _$1$DRA2:[TEST.5B.MGR.JOURNAL]
2. To START restore at the beginning of cluster session <20031002 13:51:31>
3. To STOP restore at the end of the cluster journal log
4. To SWITCH journal file before journal restore
5. To DISABLE journaling the dejournaled transactions
Select an item to modify ('Q' to quit or ENTER to accept and continue): 2
Cluster Journal Restore - Setup - Where to Start Restore
1. At the beginning of a cluster session (*): <20031002 13:51:31>
2. At a specific journal marker
3. Following the restore of backup _$1$DRA1:[TEST.50.MGR]CLUFULL.BCK
Selection ( if no change): 2
To start restore at a journal marker location (in original form)
journal file: _$1$DRA1:[TEST.50.MGR.JOURNAL]20031002.008
offset: 134120
You have chosen to start journal restore at
134120,_$1$DRA1:[TEST.50.MGR.JOURNAL]20031002.008
the journal location by the end of backup _$1$DRA1:[TEST.50.MGR]CLUFULL.BCK
サブメニューは、現在の設定に基づいて若干異なります。例えば、バックアップ・リストアが実行されていない場合、リストアの開始を指定するサブメニューには、最新のバックアップの最後からリストアするオプション 3 が表示されません。サブメニューでは、現在選択されているオプションは、アスタリスク (*) でマークされています。
リストアの終了ポイントを変更する
既定では、現在のシステムが、選択したクラスタ・ジャーナル・ログあるいはジャーナル・ログの最後に関連付けられる場合は、リストアは現在のジャーナル位置のいずれかで終了します。オプション 3 のサブメニューは、オプション 2 のサブメニューと類似しています。
Cluster Journal Restore - Setup - Main Settings
1. To LOCATE journal files using cluster journal log
_$1$DRA1:[TEST.50.MGR]CACHEJRN.TXT
with redirections of journal files
_$1$DRA1:[TEST.50.MGR.JOURNAL] -> _$1$DRA2:[TEST.50.MGR.JOURNAL]
_$1$DRA1:[TEST.5A.MGR.JOURNAL] -> _$1$DRA2:[TEST.5A.MGR.JOURNAL]
_$1$DRA1:[TEST.5B.MGR.JOURNAL] -> _$1$DRA2:[TEST.5B.MGR.JOURNAL]
2. To START restore at the end of last restored backup
_$1$DRA1:[TEST.50.MGR]CLUFULL.BCK
134120,_$1$DRA1:[TEST.50.MGR.JOURNAL]20031002.008
-> _$1$DRA1:[TEST.50.MGR.JOURNAL]20031002.008
3. To STOP restore at the end of the cluster journal log
4. To SWITCH journal file before journal restore
5. To DISABLE journaling the dejournaled transactions
Select an item to modify ('Q' to quit or ENTER to accept and continue): 3
Cluster Journal Restore - Setup - Where to Stop Restore
1. At the end of a cluster session
2. At the end of _$1$DRA1:[TEST.50.MGR]CACHEJRN.TXT
3. At a specific journal marker
ジャーナル・ログが現在のクラスタ用のジャーナル・ログである場合、以下のメニューが表示されます。
Select an item to modify ('Q' to quit or ENTER to accept and continue): 3
Cluster Journal Restore - Setup - Where to Stop Restore
1. At the end of a cluster session
2. At current journal location (*)
3. At a specific journal marker
サブメニューは、現在の設定に基づいて若干異なります。例えば、ジャーナル・ログが現在のクラスタ用のジャーナル・ログであるかどうかにより、リストアの最後を指定するメニューのオプション 2 は、現在のジャーナル位置かジャーナル・ログの最後かのいずれかになります。サブメニューでは、現在選択されているオプションは、アスタリスク (*) でマークされています。
ジャーナル・ファイルの切り替え設定を切り替える
4 番目のメニュー項目では、リストアの前にジャーナル・ファイルを切り替えるかどうかを指定します。この項目番号を選択した場合、値は、ジャーナル・ファイルの値 To SWITCH と NOT to SWITCH の間で切り替わり、メニューは新規の設定で再表示されます。
Select an item to modify ('Q' to quit or ENTER to accept and continue): 4
Cluster Journal Restore - Setup - Main Settings
1. To LOCATE journal files using cluster journal log
_$1$DRA1:[TEST.50.MGR]CACHEJRN.TXT
with redirections of journal files
_$1$DRA1:[TEST.50.MGR.JOURNAL] -> _$1$DRA2:[TEST.50.MGR.JOURNAL]
_$1$DRA1:[TEST.5A.MGR.JOURNAL] -> _$1$DRA2:[TEST.5A.MGR.JOURNAL]
_$1$DRA1:[TEST.5B.MGR.JOURNAL] -> _$1$DRA2:[TEST.5B.MGR.JOURNAL]
2. To START restore at the end of last restored backup
_$1$DRA1:[TEST.50.MGR]CLUFULL.BCK
134120,_$1$DRA1:[TEST.50.MGR.JOURNAL]20031002.008
-> _$1$DRA1:[TEST.50.MGR.JOURNAL]20031002.008
3. To STOP restore at the end of the cluster journal log
4. NOT to SWITCH journal file before journal restore
5. To DISABLE journaling the dejournaled transactions
既定では、リストアの前にジャーナル・ファイルを切り替えます。ここでは、クリーン・スタートが提供されるので、リストアの後に発生する更新は新規のジャーナル・ファイルに配置されます。
ジャーナリングを無効にする設定を切り替える
5 番目のメニュー項目では、リストア中にデジャーナルされたトランザクションのジャーナリングを無効にするかどうかを指定します。この項目を選択した場合、値は、デジャーナルされたトランザクションをジャーナリングする値 DISABLE と NOT to DISABLE の間で切り替わり、メニューは新規の設定で表示されます。
Select an item to modify ('Q' to quit or ENTER to accept and continue): 5
Cluster Journal Restore - Setup - Main Settings
1. To LOCATE journal files using cluster journal log
_$1$DRA1:[TEST.50.MGR]CACHEJRN.TXT
with redirections of journal files
_$1$DRA1:[TEST.50.MGR.JOURNAL] -> _$1$DRA2:[TEST.50.MGR.JOURNAL]
_$1$DRA1:[TEST.5A.MGR.JOURNAL] -> _$1$DRA2:[TEST.5A.MGR.JOURNAL]
_$1$DRA1:[TEST.5B.MGR.JOURNAL] -> _$1$DRA2:[TEST.5B.MGR.JOURNAL]
2. To START restore at the end of last restored backup
_$1$DRA1:[TEST.50.MGR]CLUFULL.BCK
134120,_$1$DRA1:[TEST.50.MGR.JOURNAL]20031002.008
-> _$1$DRA1:[TEST.50.MGR.JOURNAL]20031002.008
3. To STOP restore at the end of the cluster journal log
4. NOT to SWITCH journal file before journal restore
5. NOT to DISABLE journaling the dejournaled transactions
パフォーマンスの向上のため、既定の設定では、デジャーナルされたトランザクションのジャーナリングは無効になっています。しかし、クラスタ・シャドウを実行中の場合は、ジャーナリングを無効にしない選択をすることができます。
ジャーナリングを無効にしない選択をした場合、デジャーナルされたトランザクションは、ジャーナルの条件を別途満たしている場合にのみジャーナルされます。
一般的なジャーナル・ファイルの生成
このオプションのユーザ・インタフェースは、出力ファイルのコンテンツと形式に関する追加質問の最初のものに類似しています。ただし、ジャーナル・ファイルのリストアの代わりに、このオプションは、Caché システムの ^%JREAD ユーティリティで読み取りが可能な一般的な形式のジャーナル・ファイルを生成します (システムでクラスタ・ジャーナル・リストアまたは DSM などの他のプラットフォームをサポートしない場合)。
^JCONVERT は、Cluster Journal Convert? の質問に Yes と応答する場合と同じ機能を提供します。
2 番目のオプションは、クラスタ・ジャーナル・ファイルから 1 つの一般的な形式の出力ファイルを生成します。これは、^JCONVERT ユーティリティを呼び出します。このユーティリティは、単一のシステムからジャーナル・ファイルを取り出し、%JREAD ルーチンで読み取られる一般的な形式で書き出します。これは、ジャーナル・ファイルに互換性がない (例えば、“almost rolling” アップグレード) 場合、または初期リリースへのフェイルバックの一環としての Caché のバージョン全体で、ジャーナル・ファイルをリストアするために役立ちます。また、このオプションを使用して、DSM などの別のプラットフォームにロードできる形式でジャーナル・ファイルを書き出すことができます。
Cluster Journal Restore Menu
--------------------------------------------------------------
1) Cluster journal restore
2) Generate common journal file from specific journal files
3) Cluster journal restore after backup restore
4) Cluster journal restore corresponding to Caché backups
--------------------------------------------------------------
H) Display Help
E) Exit this utility
--------------------------------------------------------------
Enter choice (1-4) or [E]xit/[H]elp? 2
バックアップ・リストア後のクラスタ・ジャーナル・リストアの実行
オプション 3 では、Caché バックアップをリストア後にジャーナル・ファイルをリストアします。これは、クラスタ・バックアップ・リストアをバックアップのリストアから独立して実行する方法がない場合に、クラスタ・バックアップ・リストアを実行した後に、インクリメンタル・バックアップのリストア・ルーチン ^DBREST によって実行されるリストアと類似しています (例えば、ジャーナル・リストアを再起動します)。このオプションと ^DBREST を使用するリストアとの 1 つの違いは、このオプションはバックアップに含まれるデータベースのリストを使用して開始しないことです。したがって、データベース・リストを入力する必要があります。
ルーチンでは、リストア内の現在のクラスタ・マウントされたデータベースをすべて含めることができますが、バックアップのリストア後に実行中の場合には、バックアップによりリストアされたデータベースは、マウント状態を変更しない限り個別にマウントされます (リストアはデータベースを個別にマウントし、リストアが終了するときに個別にマウントされたままにします)。バックアップによってジャーナル・ファイルに記録されたマーカから開始し、ジャーナル・データの最後で終了します。
Caché バックアップに基づくクラスタ・ジャーナル・リストアの実行
4 番目のメニュー・オプションでは、開始ポイントと終了ポイント (オプション) を指定するために Caché バックアップにより追加されたジャーナル・マーカを使用して、ジャーナル・ファイルをリストアします。このオプションは、リストアされたバックアップではなく、開始位置を指定するために実行されたバックアップを使用することを除けば、オプション 3 に類似しています。機能的には、これらのオプションは同じです。両方とも、開始ポイントとして Caché バックアップによりジャーナル・ファイルに配置されたマーカを使用します。異なるのは、開始する場所を選択するリストの内容です。
ジャーナル・ダンプ・ユーティリティ
Caché のクラスタ化されたシステムでは、^JRNDUMP ルーチンは、単語 JRNSTART の代わりに、ジャーナル・ファイルのクラスタ・セッション ID (クラスタ起動時間) を表示します。^JRNDUMP ルーチンは、ジャーナル・ファイル・サイズと共にクラスタ・セッション ID を示す、ジャーナル・ファイルのレコード・リストを表示します。
ユーティリティは、ローカル・システムが保持するジャーナル・ファイルのみでなく、Caché クラスタの別のシステムが保持するジャーナル・ファイルをリストします。リストは、クラスタ起動時間 (クラスタ・セッション ID) とジャーナル・ファイルの最初と最後のクラスタ・ジャーナルのシーケンス番号の順で表示されます。^JRNSTART で作成されたジャーナル・ファイルには、アスタリスク (*) が付いています。利用できなくなったジャーナル・ファイル (例えば削除されるなど) は、D (deleted の D) でマークされます。ジャーナル・ファイル名は、CSN に対応するインデントが付いて表示されます。つまり、システム 0 のジャーナル・ファイルにはインデントなし、システム 1 には 1 つのスペース、システム 2 には 2 つのスペースのようになります。
^JRNDUMP クラスタ・バージョンのサンプル出力は、以下のとおりです。既定では、クラスタ化されたシステム上に表示されるレベル 1 は、クラスタ化されていないシステムのものとまったく異なります。
FirstSeq LastSeq Journal Files
Session 20030820 11:02:43
0 0 D /bench/test/cache/50a/mgr/journal/20030820.003
0 0 /bench/test/cache/50b/mgr/journal/20030820.004
Session 20030822 10:55:46
3 3 /bench/test/cache/50b/mgr/journal/20030822.001
(N)ext,(P)rev,(G)oto,(E)xamine,(Q)uit =>
各クラスタ・ノード (停止したノードも含む) のジャーナル・ファイル・リストの他にも、各ジャーナル・ファイルのクラスタ・セッション ID と、各ジャーナル・ファイルの最初と最後のクラスタ・ジャーナルのシーケンス番号があります。クラスタ・セッション ID (Session に続く日付時刻文字列) は、クラスタの最初のノードが開始する時間です。クラスタの最後のノードが停止すると、クラスタ・セッションが終了します。ファイルのノードが異なる場合、異なるインデントが使用されます。CSN 0 のノードにはインデントが使用されず、CSN 1 のノードには 1 つのスペースが使用されるというようになります。ノードの CSN は、所定の時間にクラスタ内のノードを一意に識別します。D ラベルが付いたファイルは、ホスト・システムから削除されている可能性があります。
クラスタの ^JRNDUMP の以前のバージョンは、その出力が必要な場合に OLD^JRNDUMP として利用できました。
スタートアップ・リカバリ・ルーチン
以下は、スタートアップ・リカバリ・ルーチン ^STURECOV の表示に役立ちます。
%SYS>Do ^STURECOV
Enter error type (? for list) [^] => ?
Supported error types are:
JRN - Journal restore and transaction rollback
CLUJRN - Cluster journal restore and transaction rollback
Enter error type (? for list) [^] => CLUJRN
Cluster journal recovery options
--------------------------------------------------------------
1) Display the list of errors from startup
2) Run the journal restore again
4) Dismount a database
5) Mount a database
6) Database Repair Utility
7) Check Database Integrity
--------------------------------------------------------------
H) Display Help
E) Exit this utility
--------------------------------------------------------------
Enter choice (1-8) or [E]xit/[H]elp? H
--------------------------------------------------------------
Before running ^STURECOV you should have corrected the
errors that prevented the journal restore or transaction rollback
from completing. Here you have several options regarding what
to do next.
Option 1: The journal restore and transaction rollback procedure
tries to save the list of errors in ^%SYS(). This is not always
possible depending on what is wrong with the system. If this
information is available, this option displays the errors.
Option 2: This option performs the same journal restore and
transaction rollback which was performed when the system was
started. The amount of data is small so it should not be
necessary to try and restart from where the error occurred.
Option 3 is not enabled for cluster recovery
Option 4: This lets you dismount a database. Generally this
would be used if you want to let users back on a system but
you want to prevent them from accessing a database which still
has problems (^DISMOUNT utility).
Option 5: This lets you mount a database (^MOUNT utility).
Option 6: This lets you edit the database structure (^REPAIR utility).
Option 7: This lets you validate the database structure (^INTEGRIT utility).
Option 8 is not enabled for cluster recovery. Shut the system
down using the bypass option with ccontrol stop and then start it
with ccontrol start. During startup answer YES when asked if you
want to continue after it displays the message related to errors
during recovery.
Press <enter> continue
Cluster journal recovery options
--------------------------------------------------------------
1) Display the list of errors from startup
2) Run the journal restore again
4) Dismount a database
5) Mount a database
6) Database Repair Utility
7) Check Database Integrity
--------------------------------------------------------------
H) Display Help
E) Exit this utility
--------------------------------------------------------------
Enter choice (1-8) or [E]xit/[H]elp?
クラスタ化されたシステムでのジャーナル・マーカの設定
クラスタ全体に有効なジャーナル・マーカを設定するには、以下のルーチンを使用します。
$$CLUSET^JRNMARK(id,text,swset)
| 要素 | 説明 |
|---|---|
| id | マーカ ID (例 : バックアップは -1) |
| text | マーカ・テキスト (例 : バックアップ : “timestamp”) |
| swset | 1 — データベースの読み取りと書き込みを抑制するスイッチ (switch 10) が、呼び出し側からクラスタ全体 (およびローカル) に設定されている場合。呼び出し側は、後でこれを消去する必要があります。 |
| 0 — スイッチが設定されていない場合。ルーチンはスイッチの設定と消去を適切に管理します。 |
ジャーナル・マーカの整合性を確実にするために、ローカルおよびクラスタ全体にスイッチ 10 を設定する必要があることに注意してください。成功した場合、ルーチンは、コンマで区切られたマーカの位置 (ジャーナル・ファイルのマーカのオフセットとジャーナル・ファイル名) を返します。それ以外の場合、コンマで区切られたエラー・コード (<=0) とエラー・メッセージを返します。
クラスタ・ジャーナル情報のグローバル
グローバル・ノード ^%SYS("JRNINFO") には、クラスタ・ジャーナル情報が保持されています。現在のクラスタ・セッション ID でインデックスが付けられ、クラスタが再開するたびに再作成されます。これを使用すると、2 つのクラスタ・セッションの間で (更新アルゴリズムでは 1 つのクラスタ・セッションではクラスタ・ジャーナル・ログを変更しないという条件があるため) クラスタ・ジャーナル・ログを (ジャーナル・ファイルを削除した後で) 変更または削除できます。
^%SYS("JRNINFO") グローバルには 3 つのサブコンポーネントがあります。
-
jrninfo テーブルには、ジャーナル・ファイル名でインデックスが付けられています。ジャーナル・ファイル名には、クラスタ・ジャーナル・ログ内のエントリ数である最上位ノードの値と、そのジャーナル・ファイルのコンマで区切られた属性リスト (CSN、クラスタ・ジャーナル・ログ内のジャーナル・ファイルの行番号、CSI、最初と最後のシーケンス番号) である各サブノードの値が付いています。
-
jrninfor (reverse の r) テーブルは、ジャーナル・ファイルのリストです。主キーとして CSN、セカンダリ・キーとしてクラスタ・ジャーナル・ログ内のジャーナル・ファイルの行番号が付いています。
-
seqinfo テーブルには、CSI、最初と最後のシーケンス番号、CSN、クラスタ・ジャーナル・ログ内のジャーナル・ファイルの行番号の添え字が含まれています。
以下は、^%SYS("JRNINFO") コンテンツのサンプルです。
^%SYS("JRNINFO",1032803946,"jrninfo")=16
^%SYS("JRNINFO",1032803946,"jrninfo",
"_$1$DKA0:[TEST.50.MGR.JOURNAL]20030916.002")=1,2,1031949277,160,160
"_$1$DRA1:[TEST.50.MGR.JOURNAL]20030913.004")=0,1,1031949277,3,3
"_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.001")=0,3,1031949277,292,292
"_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.002")=0,4,1032188507,3,417
"_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.003")=0,7,1032188507,3,422
"_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.004")=0,8,1032197355,3,4
"_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.005")=0,9,1032197355,3,7
"_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.006")=0,10,1032197355,3,10
"_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.007")=0,11,1032197355,3,17
"_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.008")=0,12,1032197355,3,17
"_$1$DRA1:[TEST.50.MGR.JOURNAL]20030918.001")=0,13,1032197355,3,27
"_$1$DRA1:[TEST.50.MGR.JOURNAL]20030923.001")=0,15,1032803946,3,133
"_$1$DRA1:[TEST.5A.MGR.JOURNAL]20030916.002")=1,5,1032188507,3,3
"_$1$DRA1:[TEST.5A.MGR.JOURNAL]20030916.003")=1,6,1032188507,131,131
"_$1$DRA1:[TEST.5A.MGR.JOURNAL]20030923.001")=1,14,1032197355,39,39
"_$1$DRA1:[TEST.5A.MGR.JOURNAL]20030923.002")=1,16,1032803946,3,3
^%SYS("JRNINFO",1032803946,"jrninfor",0,
1)=_$1$DRA1:[TEST.50.MGR.JOURNAL]20030913.004
3)=_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.001
4)=_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.002
7)=_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.003
8)=_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.004
9)=_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.005
10)=_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.006
11)=_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.007
12)=_$1$DRA1:[TEST.50.MGR.JOURNAL]20030916.008
13)=_$1$DRA1:[TEST.50.MGR.JOURNAL]20030918.001
15)=_$1$DRA1:[TEST.50.MGR.JOURNAL]20030923.001
^%SYS("JRNINFO",1032803946,"jrninfor",1,
2)=_$1$DKA0:[TEST.50.MGR.JOURNAL]20030916.002
5)=_$1$DRA1:[TEST.5A.MGR.JOURNAL]20030916.002
6)=_$1$DRA1:[TEST.5A.MGR.JOURNAL]20030916.003
14)=_$1$DRA1:[TEST.5A.MGR.JOURNAL]20030923.001
16)=_$1$DRA1:[TEST.5A.MGR.JOURNAL]20030923.002
^%SYS("JRNINFO",1032803946,"seqinfo",1031949277,3,3,0,1)=
^%SYS("JRNINFO",1032803946,"seqinfo",1031949277,160,160,1,2)=
^%SYS("JRNINFO",1032803946,"seqinfo",1031949277,292,292,0,3)=
^%SYS("JRNINFO",1032803946,"seqinfo",1032188507,3,3,1,5)=
^%SYS("JRNINFO",1032803946,"seqinfo",1032188507,3,417,0,4)=
^%SYS("JRNINFO",1032803946,"seqinfo",1032188507,3,422,0,7)=
^%SYS("JRNINFO",1032803946,"seqinfo",1032188507,131,131,1,6)=
^%SYS("JRNINFO",1032803946,"seqinfo",1032197355,3,4,0,8)=
^%SYS("JRNINFO",1032803946,"seqinfo",1032197355,3,7,0,9)=
^%SYS("JRNINFO",1032803946,"seqinfo",1032197355,3,10,0,10)=
^%SYS("JRNINFO",1032803946,"seqinfo",1032197355,3,17,0,11)=
12)=
^%SYS("JRNINFO",1032803946,"seqinfo",1032197355,3,27,0,13)=
^%SYS("JRNINFO",1032803946,"seqinfo",1032197355,39,39,1,14)=
^%SYS("JRNINFO",1032803946,"seqinfo",1032803946,3,3,1,16)=
^%SYS("JRNINFO",1032803946,"seqinfo",1032803946,3,133,0,15)=
シャドウ情報のグローバルとユーティリティ
グローバル・ノード ^SYS("shdwcli”) には、シャドウ・クライアント情報が保持されています。多くの値は、ユーティリティ ShowState^SHDWX、ShowError^SHDWX、ShowWhere^SHDWX から利用可能です。
ShowState^SHDWX を実行すると、グローバルに保持されている大部分のデータが表示されます。
%SYS>d ShowState^SHDWX("clutest",1)
Shadow ID PrimaryServerIP Port R S Err
------------------------------------------------------------------------
clutest rodan 42009 0 1 1
\_ clutest~0 192.9.202.5 42009 0 1
\_ clutest~1 192.9.202.5 42009 0 1
\_ clutest~2 rodan 42009 0 1
Redirection of Global Sets and Kills:
^^_$1$DKB300:[TEST.CLU.5X] -> ^^_$1$DKA0:[TEST.CLU.5X]
Redirection of Master Journal Files:
Base directory for auto-redirection: _$1$DKA0:[TEST.5X.SHADOW]
_$1$DRA2:[TEST.5X.JOURNAL] -> _$1$DKA0:[TEST.5X.SHADOW.1]
_$1$DRA2:[TEST.5Y.JOURNAL] -> _$1$DKA0:[TEST.5X.SHADOW.2]
_$1$DRA2:[TEST.5Z.JOURNAL] -> _$1$DKA0:[TEST.5X.SHADOW.3]
Primary Server Cluster ID: _$1$DKB400:[TEST.5X]CACHE.PIJ
Primary Server Candidates (for failover):
192.9.202.5 42009
rodan 42009
192.9.202.5 42019
192.9.202.5 42029
When to purge a shadow journal file: after it's dejournaled
^SYS("shdwcli”) グローバルからの出力には、以下のコンポーネントがあります。
-
Shadow ID — コピー側シャドウの ID は親シャドウから部分的に継承されます。コピー側の clu サブノードには、親の ID が含まれており、親の sys サブノードには、コピー側の ID リストが含まれています。
-
PrimaryServerIP と Port — コピー側では、ジャーナル・ファイルを取得するシステムを指定します。デジャーナル側では、ジャーナル情報を取得するシステムを指定します (JRNINFO サーバ)。値は、ip サブノードおよび port0 サブノードに格納されます。
-
R — シャドウが実行される場合、値 1 を持ちます (stat サブノードから)。
-
S — シャドウを停止する要求があった場合、値 1 を持ちます (待ち時間が発生するので、シャドウが停止要求を確認する必要がある場合は、R と S の両方の値 1 になっていることもあり得ます) (stop サブノードから)。
-
Err — エラーの発生回数です。ShowError^SHDWX で詳細を参照してください。err サブノードからの情報が表示されています。
-
Redirection of Global Sets and Kills — 管理ポータルのデータベース・マッピングです (クラスタ・シャドウの dbmap サブノードからのマッピング)。
-
Redirection of Master Journal Files — "Caché ルーチンの使用" セクションで説明されています。クラスタ・シャドウの jrndir サブノードに格納されます。jrndir サブノードの値は、自動的にリダイレクトされたジャーナル・ディレクトリ数です (前述の出力例では、次の新しいジャーナル・ディレクトリは、サブディレクトリ [.4] にリダイレクトされます)。(jrndir,0) は、ベース・シャドウ・ディレクトリであり、その他のすべては、キーであるサーバ・ジャーナル・ディレクトリと、値としてのシャドウ・ジャーナル・ディレクトリを持つジャーナル・ディレクトリのリダイレクトを示します。
-
Primary Server Cluster ID — 異なるクラスタにノードが移行する際、シャドウがそれを追従するのを防止するために使います (DBServerClusterID サブノードから)。
-
Primary Server Candidates (フェイルオーバー用) — クラスタの現在動作中のメンバのリストです。1 つのメンバがエラーになると、そのメンバから情報を取得する (デジャーナル側またはコピー側のいずれかの) シャドウは、成功するまでリストの他のメンバを試行します。シャドウが新規メンバの存在を見つけると、すぐにリストに追加されます (servers サブノードから)。
-
When to purge a shadow journal file — ローカル・ジャーナル・ファイルの削除と同じように動作します。年数しきい値は、クラスタ・シャドウの lifespan サブノードで設定されます。ローカル・ジャーナル・ファイルの削除とは異なり、lifespan の値が 0 の場合、シャドウ・ジャーナル・ファイルは、完全にデジャーナルされるとすぐに削除されます。削除されたジャーナル・ファイルは、コピー側の jrndel サブノードにリストされます。
chkpnt サブノードには、チェックポイントのリストが格納されます。チェックポイントは、デジャーナル側の作業キューのスナップショット (デジャーナリングの現在の進行状況) です。chkpnt サブノードの値は、デジャーナル側が再開するときに使用するチェックポイントを示します。これが、ShowWhere^SHDWX で表示されるチェックポイントです。対応するチェックポイントを完全に更新した後で chkpnt サブノードの値を更新することにより、更新中にシステム・フェイルオーバーが発生した場合に部分的なチェックポイントを取得することを防止します (その場合、デジャーナル側は以前のチェックポイントを使用します)。
コピー側は、コピーした (またはコピー中の) ジャーナル・ファイル名を jrnfil サブノードに保持します。これにより、コピー側が新しい位置に新しいジャーナル・ファイルをコピーする間に、デジャーナル側が古いディレクトリのシャドウ・ジャーナル・ファイルを探せるようにして、ジャーナル・ファイルのリダイレクトの変更を可能にします。シャドウ・ジャーナル・ファイルが削除されると、jrnfil リストから jrndel リストに移されます。
以下は、クラスタ・シャドウ clutest とその 2 つのコピー側シャドウのノードの ^SYS("shdwcli") コンテンツの例です。
^SYS("shdwcli","clutest")=0
^SYS("shdwcli","clutest","DBServerClusterID")=_$1$DKB400:[TEST.5X]CACHE.PIJ
"at")=0
"chkpnt")=212
^SYS("shdwcli","clutest","chkpnt",1)=1,1012488866,-128
^SYS("shdwcli","clutest","chkpnt",1,1012488866,0,1)=0,,,,
^SYS("shdwcli","clutest","chkpnt",2)=2,1012488866,-128
^SYS("shdwcli","clutest","chkpnt",2,1012488866,-128,2)=
-128,_$1$DKA0:[TEST.5X.SHADOW.1]20020131.001,0,,0
^SYS("shdwcli","clutest","chkpnt",3)=6,1012488866,5
^SYS("shdwcli","clutest","chkpnt",3,1012488866,11,6)=
5,_$1$DKA0:[TEST.5X.SHADOW.1]20020131.001,-132252,,0
^SYS("shdwcli","clutest","chkpnt",4)=35,1012488866,85
^SYS("shdwcli","clutest","chkpnt",4,1012488866,95,35)=
85,_$1$DKA0:[TEST.5X.SHADOW.1]20020131.001,-136984,,0
^SYS("shdwcli","clutest","chkpnt",5)=594,1012488866,807
^SYS("shdwcli","clutest","chkpnt",5,1012488866,808,594)=
808,_$1$DKA0:[TEST.5X.SHADOW.1]20020131.001,262480,1,0
...
^SYS("shdwcli","clutest","chkpnt",212)=24559,1021493730,5
^SYS("shdwcli","clutest","chkpnt",212,1021493730,37,24559)=
5,_$1$DKA0:[TEST.5X.SHADOW.1]20020515.001,-132260,,0
^SYS("shdwcli","clutest","cmd")=
^SYS("shdwcli","clutest","dbmap","^^_$1$DKB300:[TEST.CLU.5X]")=
^^_$1$DKA0:[TEST.CLU.5X]
^SYS("shdwcli","clutest","end")=0
"err")=1
^SYS("shdwcli","clutest","err",1)=
20020519 14:16:34 568328925 Query+8^SHDWX;-12;
reading ans from |TCP|42009timed out,Remote server is not responding
^SYS("shdwcli","clutest","err",1,"begin")=20020519 14:09:09
"count")=5
^SYS("shdwcli","clutest","errmax")=10
"intv")=10
"ip")=rodan
"jrndir")=3
^SYS("shdwcli","clutest","jrndir",0)=_$1$DKA0:[TEST.5X.SHADOW]
"_$1$DRA2:[TEST.5X.JOURNAL]")=_$1$DKA0:[TEST.5X.SHADOW.1]
"_$1$DRA2:[TEST.5Y.JOURNAL]")=_$1$DKA0:[TEST.5X.SHADOW.2]
"_$1$DRA2:[TEST.5Z.JOURNAL]")=_$1$DKA0:[TEST.5X.SHADOW.3]
^SYS("shdwcli","clutest","jrntran")=0
"lifespan")=0
"locdir")=
"locshd")=
"pid")=568328919
"port")=
"port0")=42009
"remjrn")=
^SYS("shdwcli","clutest","servers","42009,192.9.202.5")=
"42009,rodan")=
"42019,192.9.202.5")=
"42029,192.9.202.5")=
^SYS("shdwcli","clutest","stat")=0
"stop")=1
^SYS("shdwcli","clutest","sys",0)=
1)=
2)=
^SYS("shdwcli","clutest","tcp")=|TCP|42009
"tpskip")=1
"type")=21
^SYS("shdwcli","clutest~0")=0
^SYS("shdwcli","clutest~0","at")=0
"clu")=clutest
"cmd")=
"end")=132260
"err")=0
"intv")=10
"ip")=192.9.202.5
^SYS("shdwcli","clutest~0","jrndel",
"_$1$DKA0:[TEST.5X.SHADOW.1]20020131.001")=
"_$1$DKA0:[TEST.5X.SHADOW.1]20020131.002")=
"_$1$DKA0:[TEST.5X.SHADOW.2]20020510.010")=
^SYS("shdwcli","clutest~0","jrnfil")=36
^SYS("shdwcli","clutest~0","jrnfil",35)=
_$1$DRA2:[TEST.5X.JOURNAL]20020513.006
^SYS("shdwcli","clutest~0","jrnfil",35,"shdw")=
_$1$DKA0:[TEST.5X.SHADOW.1]20020513.006
^SYS("shdwcli","clutest~0","jrnfil",36)=
_$1$DRA2:[TEST.5X.JOURNAL]20020515.001
^SYS("shdwcli","clutest~0","jrnfil",36,"shdw")=
_$1$DKA0:[TEST.5X.SHADOW.1]20020515.001
^SYS("shdwcli","clutest~0","jrntran")=0
"locdir")=
"locshd")=
_$1$DKA0:[TEST.5X.SHADOW.1]20020515.001
"pause")=0
"pid")=568328925
"port")=42009
"port0")=42009
"remend")=132260
"remjrn")=
"stat")=0
"stop")=1
"tcp")=|TCP|42009
"tpskip")=1
"type")=12
^SYS("shdwcli","clutest~1")=0
^SYS("shdwcli","clutest~1","at")=0
"clu")=clutest
"cmd")=
"end")=132248
"err")=0
"intv")=10
"ip")=192.9.202.5
^SYS("shdwcli","clutest~1","jrndel",
"_$1$DKA0:[TEST.5X.SHADOW.1]20020510.003")=
"_$1$DKA0:[TEST.5X.SHADOW.2]20020131.001")=
"_$1$DKA0:[TEST.5X.SHADOW.2]20020510.008")=
^SYS("shdwcli","clutest~1","jrnfil")=18
^SYS("shdwcli","clutest~1","jrnfil",17)=
_$1$DRA2:[TEST.5X.JOURNAL]20020510.011
^SYS("shdwcli","clutest~1","jrnfil",17,"shdw")=
_$1$DKA0:[TEST.5X.SHADOW.1]20020510.011
^SYS("shdwcli","clutest~1","jrnfil",18)=
_$1$DRA2:[TEST.5Y.JOURNAL]20020510.011
^SYS("shdwcli","clutest~1","jrnfil",18,"shdw")=
_$1$DKA0:[TEST.5X.SHADOW.2]20020510.011
^SYS("shdwcli","clutest~1","jrntran")=0
"locdir")=
"locshd")=
_$1$DKA0:[TEST.5X.SHADOW.2]20020510.011
"pid")=568328925
"port")=42009
"port0")=42009
"remend")=132248
"remjrn")=
"stat")=0
"stop")=1
"tcp")=|TCP|42009
"tpskip")=1
"type")=12