構文規則
この章は、ObjectScript 構文の基本的な規則を説明します。項目は以下のとおりです。
大文字と小文字の区別
ObjectScript には、大文字と小文字を区別する場合とそうでない場合があります。通常、ObjectScript のユーザ定義部は、大文字と小文字を区別しますが、キーワードは区別しません。
-
大文字と小文字の区別あり:変数名 (ローカル、グローバル、およびプロセス・プライベート・グローバル) および変数の添え字、クラス名、メソッド名、プロパティ名、プロパティのインスタンス変数の i% 序文、ルーチン名、マクロ名、マクロ・インクルード・ファイル (.inc ファイル) 名、ラベル名、ロック名、パスワード、埋め込みコード指示文マーカ文字列、埋め込み SQL ホスト変数名。
-
大文字と小文字を区別しない:コマンド名、関数名、特殊変数名、ネームスペース名 (下記参照)、ユーザ名およびロール名、プリプロセッサ指示文 (#Include など)、文字コード (LOCK、OPEN、または USE)、キーワード・コード ($STACK)、パターン・マッチ・コード、埋め込みコード指示文 (&html、&js、&sql)。%ZLANG ルーチンをカスタマイズすることによって追加するカスタム言語要素は大文字と小文字を区別しませんが、作成するときは大文字を使用する必要があります。これらの言語要素を参照するときは、大文字でも小文字でもかまいません。iKnow のインデックス作成では、小文字に変換することでテキストを正規化しているので、ドメイン名も含め、大半の iKnow 値は大文字と小文字を区別しません。
-
通常は大文字と小文字を区別しない:デバイス名、ファイル名、ディレクトリ名、ディスク・ドライブ名で、大文字と小文字を区別するかどうかはプラットフォームによる。指数記号は、通常大文字と小文字を区別しません。大文字の “E” は、常に有効な指数記号です。小文字の “e” は、%SYSTEM.ProcessOpens in a new tab の ScientificNotation()Opens in a new tab メソッドを使用している現在のプロセス、または Config.MiscellaneousOpens in a new tab クラスの ScientificNotationOpens in a new tab プロパティを使用しているシステム全体に対して、有効または無効に構成できます。
識別子
ユーザ定義の 識別子 (変数、ルーチン名、ラベル名) は、大文字と小文字を区別します。String、string、STRING はすべて異なる変数を指しています。グローバル変数名は、ユーザが定義する場合も、あるいはシステムが提供する場合も大文字と小文字を区別します。
キーワード名
コマンド、関数、システム変数キーワード (およびその省略形) は、大文字と小文字を区別しません。例えば、Write、write、WRITE、W、w は同じ Write コマンドを示しています。
クラス名
クラスに関連するすべての識別子 (クラス名、プロパティ名、メソッド名など) は大文字と小文字を区別します。しかし、一意性を確保するためには、このような名前では大文字と小文字は区別されないと見なします。つまり、2 つのクラス名は大文字小文字だけでは区別できません。
ネームスペース名
ネームスペース名は、大文字と小文字を区別しません。つまり、ネームスペース名は、大文字と小文字を好きなように組み合わせて入力することができます。ただし、Caché は常に、ネームスペース名を大文字で格納することに注意してください。したがって、Caché は、ユーザが指定した小文字ではなく、大文字でネームスペース名を返す場合があります。ネームスペース名の名前付け規約の詳細は、"ネームスペース" を参照してください。
Unicode
Caché でサポートされている Unicode 文字は 16 ビット文字であり、ワイド文字と呼ばれることもあります。Caché のインストール時に Unicode オプションを選択した場合、Caché のインスタンスは Unicode 国際文字セットをサポートします。Caché インストール時に 8 ビット・オプションを選択すると、$CHAR(255) を超える文字はサポートされません。$CHAR 関数は 255 を超える整数に空の文字列を返します。Caché インストールで Unicode がサポートされている場合は、$ZVERSION 特殊変数および $SYSTEM.Version.IsUnicode()Opens in a new tab メソッドが表示されます。
ほとんどの用途に、Caché は Unicode 基本多言語面 (16 進数 0000 から FFFF) のみをサポートします。これには、最も一般的に使用される国際文字が含まれています。内部的に、Caché では UCS-2 エンコーディングを使用します。これは基本多言語面の場合、UTF-16 と同じです。すべての文字は 16 ビット (2 バイト) でエンコードされます。ただし、文字列をグローバルのディスクに保存する際に、文字列内のすべての文字の数値が 255 以下 (ASCII 値) の場合、Caché は 1 文字あたり 1 バイトを使用して文字列を格納します。$WCHAR、$WISWIDE、および関連する関数を使用することで、Unicode 基本多言語面に存在しない文字で作業できます。
Unicode と UTF-8 間の変換、および他の文字エンコーディングへの変換については、$ZCONVERT 関数を参照してください。ZZDUMP を使用して、文字列の 16 進エンコーディングを表示できます。$CHAR を使用して、文字 (または文字列) をその 10 進数 (10 進法) エンコーディングで指定することができます。$ZHEX を使用して、16 進数を 10 進数に、または 10 進数を 16 進数に変換することができます。
Unicode の文字
Caché の Unicode インストール時には、Unicode 文字を使用できる名前もありますが、Unicode 文字を含めることができない名前もあります。Unicode 文字は 255 より大きな ASCII 値のアルファベット文字として定義されます。例えば、小文字のギリシャ文字ラムダは Unicode 文字で $CHAR(955) になります。
Caché では、以下の例外を除き、どのような場合でも Unicode 文字を使用できます。
-
変数名:ローカル変数名には Unicode 文字を使用できます。一方、グローバル変数名とプロセス・プライベート・グローバル変数名には、Unicode 文字を使用できません。あらゆるタイプの変数の添え字が Unicode 文字で指定できます。
-
データベースを暗号化する際に管理者が使用するユーザ名とパスワードには Unicode 文字を使用できません。
日本語ロケールでは、Caché の名前におけるアクセント記号付きラテン文字がサポートされていません。日本語の名前には、(日本語の文字の他に) ラテン文字 A-Z と a-z (65-90 と 97-122) 、およびギリシャ語の大文字 (913-929 と 931-937) を使用できます。
空白
特定の環境では、ObjectScript は構文的に意味のあるものとして空白を処理します。指定がない限り、空白はブランク、タブ、改行と同じ意味を示します。以下はその規則の概要です。
-
コードの各行または 1 行コメントの先頭には空白を記述する必要があります。以下の場合には先頭の空白が不要となります。
-
ラベル (タグまたはエントリ・ポイントとも呼ばれる): ラベルは直前の空白文字なしで列 1 にて記述する必要があります。行にラベルがある場合、そのラベルと同一行上の他のコードやコメントの間には空白が必要です。ラベルがパラメータ・リストを有する場合、ラベル名とパラメータ・リストの最初の括弧の間にある空白をなくすこともできます。パラメータ・リスト内のパラメータの前、間、または後には空白を入れることができます。
-
マクロ指示文: #Define などのマクロ指示文は直前の空白文字なしで列 1 にて記述することができます。これは推奨の規約となりますが、マクロ指示文の前の空白は認められています。
-
複数行コメント: 複数行コメントの最初の行の前には 1 つ以上のスペースを配置する必要があります。複数行コメントの 2 行目以降には、先頭に空白を置く必要はありません。
-
空白行: 行に文字がない場合は、スペースを含める必要はありません。空白文字のみで構成される行も認められており、コメントとして扱われます。
-
-
コマンドと最初の引数の間には、必ずスペース文字を 1 つだけ記述する必要があります (タブ文字ではありません)。コマンドで後置条件を使用する場合、コマンドとその後置条件との間にはスペース文字を記述しません。
-
後置条件式にスペースがある場合、式全体を括弧で囲む必要があります。
-
組になったコマンド引数の間には、いくつもの空白を置くことができます。
-
1 行にコードと 1 行のコメントが含まれる場合は、その間に空白を置く必要があります。
-
通常、それぞれのコマンドは独自の行に記述されますが、同じ行に複数のコマンドを入力することができます。この場合、これらのコマンドの間には空白が必要です。引数がないコマンドの後には、空白を 2 つ (スペース文字を 2 つ、タブ文字を 2 つ、またはスペース文字とタブ文字をそれぞれ 1 つずつ) 記述する必要があります。これら必須の空白の後に、さらに空白を記述してもかまいません。
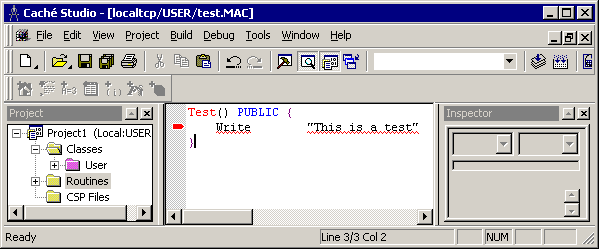
スタジオでは、組み込みの構文チェック機能が提供されます。例えば以下のように、コマンドの最初の引数の前に複数のスペースを挿入するなど、不正に使用している空白にマークが付きます。
コメント
コードでコメントを使用してインラインのドキュメントを提供するのは適切な方法です。コメントは、コードの変更またはメンテナンス時に大切な情報源になります。ObjectScript では、いくつかの種類のコメントをサポートしており、さまざまな場所で使用できます。
INT コードのルーチンおよびメソッドに使用するコメント
INT コードでは、いくつかの種類のコメントを使用できます。これらのコメントはすべて 2 列目以降から開始する必要があります。
-
/* */ コメントは、1 行または複数行にわたって記述できます。/* は、行の最初の要素として、または他の要素の後に配置できます。*/ は、行の最後の要素として、または他の要素の前に配置できます。
-
// コメントは、行の残りの部分がコメントであることを示します。このコメントは、行の最初の要素として、または他の要素の後に配置できます。
-
; コメントは、行の残りの部分がコメントであることを示します。このコメントは、行の最初の要素として、または他の要素の後に配置できます。
-
; コメントの特殊なケースである ;; コメントは、ルーチンがオブジェクト・コードとして配信される場合にのみ、$TEXT 関数で使用できます。行内でこのコメントの前にコマンドがない場合に、$TEXT 関数でのみ使用可能です。
Note:Caché は、;; コメントをオブジェクト・コード (実際に解釈され、実行されるコード) に保持するため、このコメントを挿入するとパフォーマンスに影響します。そのため、ループ内には配置しないでください。
複数行コメント (/* comment */) はコンマ区切り文字前後の、コマンドもしくは関数の引数の間に置くことができます。複数行コメントを引数内に置いたり、コマンドのキーワードと最初の引数の間、もしくは関数キーワードと最初の括弧の間に置くことはできません。同一行で複数行コメントを 2 つのコマンドの間に置くことはできます。その場合、コマンドを区切るために必要な 1 つの空白として機能します。同一行で複数行コメント (*/) の直後にコマンドを続けたり、同一行で単数行コメントを続けることもできます。行中に /* comment */ を挿入する例を以下に示します。
WRITE $PIECE("Fred&Ginger"/* WRITE "world" */,"&",2),!
WRITE "hello",/* WRITE "world" */" sailor",!
SET x="Fred"/* WRITE "world" */WRITE x,!
WRITE "hello"/* WRITE "world" */// WRITE " sailor"MAC コードのルーチンおよびメソッドに使用するコメント
INT コードで有効な種類のコメントはすべて MAC コードでも有効です。また、MAC コードでの動作も INT コードと同じです。この他に、以下の 2 種類のコメントも使用できます。
-
#; コメントは、任意の列から開始できますが、その行で最初の要素でなければなりません。また、#: コメントは、INT コードには表示されません。
-
##; コメントは任意の列から開始できます。また、その行で最初の要素になることができ、他の要素に続けることもできます。##; コメントは、INT コードには表示されません。##: は ObjectScript コード内や埋め込み SQL コード内、または #Define、#Def1Arg、もしくは ##Continue マクロ・プロプロセッサ指示文と同一行上で使用することができます。
-
/// コメントは、任意の列から開始できますが、その行の最初の要素でなければなりません。/// が列 1 から開始される場合、INT コードには表示されません。列 2 以降から /// が開始される場合は、INT コードに表示され、// コメントとして扱われます。
メソッド・コードの外部のクラス定義に使用するコメント
メソッド定義の外部のクラス定義で、いくつかの種類のコメントを使用できます。これらのコメントはすべて任意の列から開始できます。
-
// コメントおよび /* */ コメントは、クラス定義で使用するコメントです。
-
/// コメントには、その直後のクラスまたはクラス・メンバのクラスリファレンスのコンテンツが記述されます。クラス自体に対しては、クラス定義の開始前に配置される /// コメントには、クラスリファレンスのコンテンツとしてそのクラスの説明が記述されます。このコンテンツは、クラスに関する説明のキーワード値にもなります。クラス内では、メンバの直前 (クラス定義の開始位置以降、または前のメンバの後) に配置される /// コメントにはすべて、そのメンバのクラスリファレンスのコンテンツが記述されます。複数行の記述は、HTML の 1 つのブロックとして扱われます。/// コメントの規則およびクラス・リファレンスの詳細は、"Caché オブジェクトの使用法" の "クラスの定義とコンパイル" の章にある “クラス・ドキュメントの作成” または "インターシステムズ・クラス・リファレンス" の %CSP.DocumaticOpens in a new tab のエントリを参照してください。
リテラル
リテラルとは、以下の “Hello” と “5” のように、一連の文字で構成して特定の文字列や数値を表すようにした定数値です。
SET x = "Hello"
SET y = 5ObjectScript は、2 種類のリテラルがあります。
文字列リテラル
文字列リテラルは、0 個以上の文字を引用符で区切って記述したリテラルです (文字列リテラルと異なり、数値リテラルでは区切り文字を必要としません)。ObjectScript の文字列リテラルでは、区切り文字として二重引用符を使用し (例えば "myliteral")、Caché SQL の文字列リテラルでは、区切り文字として一重引用符を使用します (例えば 'myliteral')。このような区切り文字としての引用符は、文字列の長さには算入されません。
文字列リテラルには、スペース文字や制御文字を初めとして、任意の文字を使用できます。文字列リテラルの長さは、バイト数ではなく、文字列を構成する文字の数で表します。8 ビットの ASCII 文字のみを使用することもできます。Unicode システムでは、16 ビットの Unicode 文字 (ワイド文字) を文字列に使用することもできます。文字列にワイド文字を 1 つ使用しただけでも、Caché では、その文字列を構成するすべての文字が 16 ビット文字として表現されます。Caché では、ほとんどの状況で文字列がバイトの集合ではなく、文字の集合として扱われるので、ワイド文字が使用されていてもユーザ側ではそれを認識できないことが普通です (例外として、以下で説明する ZZDUMP コマンドがあります)。
文字列の最大サイズは構成可能です。長い文字列を有効にすると、文字列の最大サイズは 3,641,144 文字になります。長い文字列を有効にしていない場合、最大文字列サイズは 32,767 文字です。既定では長い文字列が有効になっています。“データ型とデータ値” の章の “長い文字列” のセクションを参照してください。
以下の Unicode の例は、8 ビット文字による文字列、16 ビット文字による文字列、および 8 ビット文字と 16 ビット文字を組み合わせた文字列を示しています。
DO AsciiLetters
IF $SYSTEM.Version.IsUnicode() {
DO GreekUnicodeLetters
DO CombinedAsciiUnicode
RETURN }
ELSE { WRITE "Unicode not supported"
RETURN }
AsciiLetters()
SET a="abc"
WRITE a
WRITE !,"the length of string a is ",$LENGTH(a)
ZZDUMP a
GreekUnicodeLetters()
SET b=$CHAR(945)_$CHAR(946)_$CHAR(947)
WRITE !!,b
WRITE !,"the length of string b is ",$LENGTH(b)
ZZDUMP b
CombinedAsciiUnicode()
SET c=a_b
WRITE !!,c
WRITE !,"the length of string c is ",$LENGTH(c)
ZZDUMP c入力不能文字を文字列に使用することもできます。以下の Unicode の例のように、$CHAR 機能を使用すると、入力不能文字を指定できます。
SET greekstr=$CHAR(952,945,955,945,963,963,945)
WRITE greekstr表示不能文字を文字列に使用することもできます。このような文字として、出力不能文字 (制御文字) があります。WRITE コマンドでは、出力不能文字がボックス記号で表示されます。WRITE コマンドを使用すると、制御文字が実行されます。以下の例の文字列では、NULL 文字 ($CHAR(0))、タブ文字 ($CHAR(9))、キャリッジ・リターン文字 ($CHAR(13)) に入れ替わる出力可能な文字を使用しています。
SET a="a"_$CHAR(0)_"b"_$CHAR(9)_"c"_$CHAR(13)_"d"
WRITE !,"the length of string a is ",$LENGTH(a)
ZZDUMP a
WRITE !,aプログラムで実行している WRITE では印刷不能文字として表示される制御文字が、ターミナルのコマンドラインから実行した WRITE では実行されることがあります。ベル文字 ($CHAR(7)) と垂直タブ文字 ($CHAR(11)) はその例です。
引用符文字 (") を文字列に含めるには、次の例に示すようにその文字を重複して使用します。
SET x="This quote"
SET y="This "" quote"
WRITE x,!," string length=",$LENGTH(x)
ZZDUMP x
WRITE !!,y,!," string length=",$LENGTH(y)
ZZDUMP y値を含まない文字列は NULL 文字列と呼ばれ、2 つの引用符 ("") で示されます。NULL 文字列は、定義済みの値と見なされます。その長さは 0 です。以下の例にあるように、NULL 文字列は、NULL 文字 ($CHAR(0)) で構成した文字列とは異なります。
SET x=""
WRITE "string=",x," length=",$LENGTH(x)," defined=",$DATA(x)
ZZDUMP x
SET y=$CHAR(0)
WRITE !!,"string=",y," length=",$LENGTH(y)," defined=",$DATA(y)
ZZDUMP y文字列の詳細は、このドキュメントの “データ型とデータ値” の章にある "文字列" を参照してください。
数値リテラル
数値リテラルとは、ObjectScript が数値として計算する値のことです。このリテラルでは区切り文字が不要です。Caché では、数値リテラルがキャノニック形式 (数値リテラルの最も単純な数値形式) に変換されます。
SET x = ++0007.00
WRITE "length: ",$LENGTH(x),!
WRITE "value: ",x,!
WRITE "equality: ",x = 7,!
WRITE "arithmetic: ",x + 1引用符で区切った文字列リテラルとして数値を表現することもできます。数値の文字列リテラルはキャノニック形式に変換されませんが、演算操作では数値として使用できます。
SET y = "++0007.00"
WRITE "length: ",$LENGTH(y),!
WRITE "value: ",y,!
WRITE "equality: ",y = 7,!
WRITE "arithmetic: ",y + 1詳細は、このドキュメントの “データ型とデータ値” の章にある "数値としての文字列" を参照してください。
ObjectScript では、以下の値を使用した値が数値として扱われます (ここにない値を使用すると数値扱いにはなりません)。
| 値 | 数量 |
|---|---|
| 0 から 9 までの数字。 | 1 個以上の任意の個数。 |
| 符号演算子、単項マイナス演算子 (-)、単項プラス演算子 (+)。 | 個数は任意ですが、他のすべての文字の前に記述する必要があります。 |
| decimal_separator 文字 (既定ではピリオドまたは小数点文字、ヨーロッパのロケールではコンマ)。 | 最大 1 個。 |
| 文字 “E” (科学的記数法で使用)。 | 最大 1 個。2 つの数値の間に記述する必要があります。 |
これらの文字の使用と解釈の詳細は、“データ型とデータ値” の章の "数値の基本" を参照してください。
ObjectScript は、以下の種類の数値を使用できます。
識別子
識別子 とは、変数、ルーチン、またはラベルの名前です。一般に、正当な識別子は文字や数字で構成されています。まれな例外を除き、句読点文字は識別子に使用できません。識別子は大文字と小文字を区別します。
ユーザ定義のコマンド、関数、および特殊変数に対する名前付け規約は、識別子の名前付け規約よりも制限 (許可された文字のみ) を受けます。"Caché 専用のシステム/ツールおよびユーティリティ" の "^%ZLANG ルーチンによる言語の拡張" を参照してください。
ローカル変数、プロセス・プライベート・グローバル、およびグローバルの名前付け規則は、このドキュメントの “変数” の章に示されています。
識別子の句読点文字
特定の識別子は、1 つ以上の句読点文字を持つことができます。以下はその概要です。
-
識別子の最初の文字をパーセント (%) 記号にすることができます。% 文字で始まる Caché 名 (%Z または %z で始まるものは除く) は、システム要素として予約されています。詳細は、"Caché プログラミング入門ガイド" の “識別子のルールとガイドライン” を参照してください。
-
(ローカル変数名ではなく) グローバルまたはプロセス・プライベート・グローバルの名前は、1 つ以上のピリオド (.) 文字を持つ場合があります。ルーチン名は、1 つ以上のピリオド (.) 文字を持つ場合があります。ピリオドを、識別子の最初または最後の文字にすることはできません。
グローバルおよびプロセス・プライベート・グローバルは、次に示すような 1 文字以上のキャレット (^) 文字で識別されることに注意してください。
Globals: Process-Private Globals: ^globname ^||ppgname ^|""|globname ^|"^"|ppgname ^|"mynspace"|globname ^|"^",""|ppgname ^["mynspace"]globname ^["^"]ppgname
これらの接頭文字は変数名を構成するものではなく、ストレージのタイプと (グローバルの場合は) このストレージで使用されるネームスペースを識別します。実際の名前は、最後の垂直バーまたは閉じ角括弧の後から始まります。
ラベル
ObjectScript コードの行は、オプションでラベル (タグとして) を含むことができます。ラベルは、コード内の行の場所を参照するハンドルとして機能します。ラベルはインデントされない識別子で、列 1 で指定されます。すべての ObjectScript コマンドは、インデントする必要があります。
ラベルには以下の名前付け規約があります。
-
最初の文字は、英数字またはパーセント記号 (%) でなくてはなりません。ラベルは、先頭を数字とすることができる唯一の ObjectScript 名であることに注意してください。2 番目以降の文字はすべて英数字でなくてはなりません。ラベルは Unicode 文字を含めることができます。
-
最大長は 31 文字です。ラベルは、31 文字よりも長くすることができますが、最初の 31 文字は一意である必要があります。ラベル参照は、ラベルの最初の 31 文字のみと一致します。ただし、ラベルまたはラベル参照 (最初の 31 文字だけでなく) の文字はすべて、ラベル文字の名前付け規約に従う必要があります。
-
ラベルは大文字と小文字を区別します。
CREATE PROCEDURE や CREATE TRIGGER などの SQL コマンドで指定した ObjectScript コードのブロックではラベルを使用できます。この場合は、ラベルの先頭文字の前の 1 カラムに、接頭文字としてコロン (:) を記述します。ラベルのそれ以降の部分は、ここで説明する命名と使用方法の要件に従います。
ラベルではパラメータの括弧を含めたり省略することができます。括弧を含めた場合、その中を空にしたり、またはコンマ区切りのパラメータ名を 1 つ以上含めることができます。括弧付きのラベルによりプロシージャ・ブロックが識別されます。
行は、ラベルだけで構成できます。ラベルの次に 1 以上のコマンド、またはラベルの次に 1 コメントなどです。コマンドまたはコメントが、同じ行のラベルの後に続く場合、スペースまたはタブ記号を使って両者を区別する必要があります。
以下は、すべて一意のラベルです。
maximum
Max
MAX
86
agent86
86agent
%control$ZNAME 関数を使用すれば、ラベル名を検証することができます。ラベル名を検証する場合には、パラメータの括弧を含めないでください。
ZINSERT コマンドを使用すれば、ラベル名をソース・コードに挿入できます。
ラベルの使用法
ラベルは、コード・セクションの認識およびフロー・コントロールの管理に役立ちます。
DO および GOTO コマンドでは、ターゲットの場所をラベルとして指定することができます。$ZTRAP 特殊変数では、エラー・ハンドラの場所をラベルとして指定することができます。JOB コマンドでは、実行されるルーチンをラベルとして指定することができます。
また、ソース・コード行を特定するには、PRINT、ZPRINT、ZZPRINT、ZINSERT、ZREMOVE、および ZBREAK コマンド、さらには $TEXT 関数によりラベルを使用します。
ただし、CATCH コマンドと同一のコード行にて、または TRY ブロックと CATCH ブロックの間にてラベルを指定することはできません。
ラベル付けされたコード・セクションの終了
ラベルはエントリ・ポイントを提供しますが、カプセル化されたコード・ユニットを定義しません。これは、ラベル付けされたコードが実行されれば、実行が停止またはリダイレクトされない限り、次のラベル付けされたコード・ユニットへと実行が続くことを意味します。コード・ユニットの実行を停止するには、以下の 3 つの方法があります。
-
コード実行が TRY の閉じ中括弧に (“}”) に遭遇する。これが発生すると、関連付けられた CATCH ブロックに続くコードの次の行へと実行を継続します。
-
コード実行が次のプロシージャ・ブロック (パラメータの括弧付きラベル) に遭遇する。括弧付きラベル行と遭遇すると、括弧内にパラメータがない場合においても、実行が停止します。
以下の例では、“label0” 以下から “label1” 以下までコードが連続して実行されます。
SET x = $RANDOM(2)
IF x=0 {DO label0
WRITE "Finished Routine0",!
QUIT }
ELSE {DO label1
WRITE "Finished Routine1",!
QUIT }
label0
WRITE "In Routine0",!
FOR i=1:1:5 {
WRITE "x = ",x,!
SET x = x+1 }
WRITE "At the end of Routine0",!
label1
WRITE "In Routine1",!
FOR i=1:1:5 {
WRITE "x = ",x,!
SET x = x+1 }
WRITE "At the end of Routine1",!以下の例では、ラベル付けされたコード・セクションが QUIT または RETURN コマンドのいずれかで終了します。これによって実行が止まります。RETURN は常に実行を止めて、QUIT は現在のコンテキストの実行を止めることに注意してください。
SET x = $RANDOM(2)
IF x=0 {DO label0
WRITE "Finished Routine0",!
QUIT }
ELSE {DO label1
WRITE "Finished Routine1",!
QUIT }
label0
WRITE "In Routine0",!
FOR i=1:1:5 {
WRITE "x = ",x,!
SET x = x+1
QUIT }
WRITE "Quit the FOR loop, not the routine",!
WRITE "At the end of Routine0",!
QUIT
WRITE "This should never print"
label1
WRITE "In Routine1",!
FOR i=1:1:5 {
WRITE "x = ",x,!
SET x = x+1 }
WRITE "At the end of Routine1",!
RETURN
WRITE "This should never print"以下の例では、2 番目と 3 番目のラベルがプロシージャ・ブロック (パラメータの括弧にて指定されたラベル) を指定します。プロシージャ・ブロックのラベルと遭遇すると、実行が停止します。
SET x = $RANDOM(2)
IF x=0 {DO label0
WRITE "Finished Routine0",!
QUIT }
ELSE {DO label1
WRITE "Finished Routine1",!
QUIT }
label0
WRITE "In Routine0",!
FOR i=1:1:5 {
WRITE "x = ",x,!
SET x = x+1 }
WRITE "At the end of Routine0",!
label1()
WRITE "In Routine1",!
FOR i=1:1:5 {
WRITE "x = ",x,!
SET x = x+1 }
WRITE "At the end of Routine1",!
label2()
WRITE "This should never print"ネームスペース
ネームスペース名は、明示的なネームスペース名または暗黙的なネームスペース名になります。明示的なネームスペース名は大文字と小文字を区別しません。入力時においての大文字と小文字に関係なく、常に大文字で格納と返送が行われます。
明示的なネームスペース名では、最初の文字は、英字またはパーセント記号 (%) に限られます。残りの文字は、英字、数字、ハイフン (–)、またはアンダースコア (_) にする必要があります。この名前は、255 文字以内にする必要があります。
Caché で、明示的なネームスペース名をルーチン名またはクラス名に変換するとき (キャッシュしたクエリ・クラス/ルーチン名の作成時など) は、句読文字が % = p、_ = u、– = d のように小文字に置き換えられます。暗黙のネームスペース名には、これら以外の句読文字が使用されていることがありますが、そのようなネームスペース名の変換では、それらの句読文字が小文字の "s" に置き換えられます。したがって、 7 つの句読点文字は次のようになります。@ = s、: = s、/ = s、\ = s、[ = s、] = s、^ = s。
予約済みのネームスペース名は、%SYS、BIN、BROKER、DOCBOOK、および DOCUMATIC です。
Caché SQL CREATE DATABASE コマンドを使用した場合、SQL データベースの作成により、対応する Caché ネームスペースが作成されます。
Caché MultiValue を使用した場合、MultiValue アカウントの作成により、対応する Caché ネームスペースが作成されます。MultiValue アカウントと Caché ネームスペースの名前付け規約は異なります。MultiValue アカウント名のネームスペース名への変換方法についての詳細は、"Caché MultiValue コマンド・リファレンス" の "CREATE.ACCOUNT" コマンドを参照してください。
ネームスペースの使用については、"Caché プログラミング入門ガイド" の "ネームスペースとデータベース" を参照してください。ネームスペース名の作成については、"Caché システム管理ガイド" の "ネームスペースの構成" を参照してください。
拡張参照
拡張参照とは他のネームスペースにあるエンティティへの参照のことです。ネームスペース名は引用符で囲んだ文字列リテラル、ネームスペース名に解決する変数、暗黙的なネームスペース名、または現在のネームスペースを指定するプレースホルダである NULL 文字列 ("") として指定できます。拡張参照には、以下の 3 つのタイプがあります。
-
拡張グローバル参照: 他のネームスペースのグローバル変数を参照します。次の構文形式をサポートしています。^["namespace"]global および ^|"namespace"|global。詳細は、このドキュメントの “変数” の章の "グローバル変数" のセクションを参照してください。
-
拡張ルーチン参照: 他のネームスペースのルーチンを参照します。
-
DO コマンド、$TEXT 関数、およびユーザ定義関数は次の構文形式をサポートしています。|"namespace"|routine。
-
JOB コマンドは次の構文形式をサポートしています。routine|"namespace"|、routine["namespace"]、または routine:"namespace"。
これらのすべての場合において、拡張ルーチン参照の開始には ^ (キャレット) 文字を使用し、指定したエンティティが (ラベルやオフセットではなく) ルーチンであることを示します。このキャラットはルーチン名の一部ではありません。例えば、DO ^|"SAMPLES"|fibonacci は、SAMPLES ネームスペースに置かれている fibonacci という名のルーチンを呼び出します。WRITE $$fun^|"SAMPLES"|house コマンドは、SAMPLES ネームスペースに置かれている、ルーチン house のユーザ定義関数 fun() を呼び出します。
-
-
拡張 SSVN 参照: 他のネームスペースの構造化システム変数 (SSVN) を参照します。次の構文形式をサポートしています。^$["namespace"]ssvn および ^$|"namespace"|ssvn。詳細は、^$GLOBAL、^$LOCK、および ^$ROUTINE 構造化システム変数を参照してください。
もちろん、すべての拡張参照は名前によって明示的に、もしくは NULL 文字列のプレースホルダ指定により、現在のネームスペースを指定できます。
予約語
ObjectScript に予約語はありません。したがって、あらゆる有効な識別子を、変数名、関数名、ラベルとして使用できます。同時に、コマンド名、関数名、他の文字列である識別子の使用を避けるのが適切です。また、ObjectScript コードは埋め込み SQL をサポートするため、関数、オブジェクト、変数、SQL 予約語である他のエンティティの名前を避けることが賢明です。そうしなければ、障害が発生する原因となります。