システム・フェイルオーバーの方法
Caché には、高可用性 (HA) ソリューションがいくつか用意されており、オペレーティング・システム・プロバイダが提供して広く使用されているすべての HA 構成と容易に統合できます。
システムの高い可用性を維持するための主要機能は、フェイルオーバーと呼ばれています。この手法では、障害が発生したプライマリ・システムをバックアップ・システムと入れ替えることで、処理をバックアップ・システムへ障害回避 (フェイルオーバー) します。多くの HA 構成は災害復旧の機能も備えています。これは、フェイルオーバー機能でシステムを利用可能な状態に維持できなくなったときに、システムの可用性を復元する機能です。
Caché のインスタンスで HA を確保するためのフェイルオーバーには、5 種類の一般的な手法があります (その 1 つは、HA 対策を導入しないというものです)。この章では、これらの手法の概要を説明し、このドキュメントの残りの部分では、その実装手順を説明します。
ミラーリングを除き、これらのすべての手法では、1 台のストレージに障害が発生しただけで深刻な状況になる可能性があることを銘記しておく必要があります。このことから、ディスクの冗長化、データベースのジャーナリング ("Caché データ整合性ガイド" の “ジャーナリング” の章を参照)、および優れたバックアップ手順 ("Caché データ整合性ガイド" の “バックアップとリストア” の章を参照) を、これらの手法と必ず組み合わせます。このような対応が、ディスクの障害による影響を軽減するうえで重要であるからです。
ご使用の環境に適切なフェイルオーバーや災害復旧方法の構築や現在の方法の見直しのための詳細情報が必要な場合は、インターシステムズのサポート窓口Opens in a new tabまでお問い合わせください。
フェイルオーバー方法なし
Caché データベースの整合性は、"Caché データ整合性ガイド" の説明にある機能により、プロダクション・システムの障害から常に保護されています。構造的なデータベースの整合性は Caché のライト・イメージ・ジャーナル (WIJ) テクノロジによって維持され、論理的な整合性はジャーナリングとトランザクション処理によって維持されています。自動的な WIJ およびジャーナルのリカバリは、インターシステムズの “防弾型” データベース・アーキテクチャの基本的な構成要素です。
一方、フェイルオーバー対策を講じていないと、システムの障害の原因およびそれを見極めて解決する能力によっては、その障害が重大なダウンタイムを引き起こすことがあります。業務上それほど重要ではない多くのアプリケーションでは、このリスクは許容できるかもしれません。
この方法を採用するには、システムのすべての利用者が以下の特質を備えている必要があります。
-
ジャーナリング、バックアップとリストアなどの明確で詳細な運用面のリカバリ手順
-
ディスクの冗長性 (RAID、もしくはディスク・ミラーリング)
-
ハードウェアを素早く入れ替えることができる能力
-
すべてのベンダとの年中無休のメンテナンス契約
-
障害に起因して発生するある程度のダウンタイムに対する管理上の受容とアプリケーション・ユーザの許容
フェイルオーバー・クラスタ
HA を実現する手法として広く使用されているものにフェイルオーバー・クラスタがあります。この手法では、共有ストレージおよびアクティブなメンバをフォローするクラスタ IP アドレスを使用し、プライマリ・プロダクション・システムを (一般的に同じ構成の) スタンバイ・システムで補完します。プロダクション・システムに障害が発生すると、スタンバイ・システムがプロダクションの作業負荷を引き受けて、障害が発生したプライマリ・システムでそれまで実行されていた Caché などのプログラムとサービスを引き継ぎます。
Caché は、Microsoft Windows Server Clusters、IBM PowerHA SystemMirror、Red Hat Enterprise Linux HA など、オペレーティング・システム・レベルで提供されるフェイルオーバー・ソリューションと簡単に統合できるように設計されています。共有ストレージ・デバイスに Caché のインスタンスを 1 つだけインストールして、両方のクラスタ・メンバでそのインスタンスを認識するようにします。続いて、このインスタンスをフェイルオーバー・クラスタ構成に追加して、フェイルオーバーの構成要素として自動的に起動するようにします。アクティブ・ノードを使用できない期間が指定の時間数に達すると、クラスタ IP アドレスと共有ストレージのコントロールがフェイルオーバー・テクノロジによってスタンバイ・システムに移管され、新しいプライマリ・システムで Caché が再起動します。ここで再起動するシステムでは、通常の起動リカバリが自動的に実行され、WIJ、ジャーナリング、およびトランザクション処理によって、障害が発生したシステム上で Caché が再起動した場合とまったく同様に構造上の整合性とデータの整合性が維持されます。
スタンバイ・サーバには、障害が発生したプライマリ・システムがリストアされるまでの間、通常のプロダクション作業負荷を処理できる能力が必要です。スタンバイ・システムがプライマリ・システムとなり、障害からリストアされたプライマリ・システムがスタンバイ・システムとなる構成も可能です。
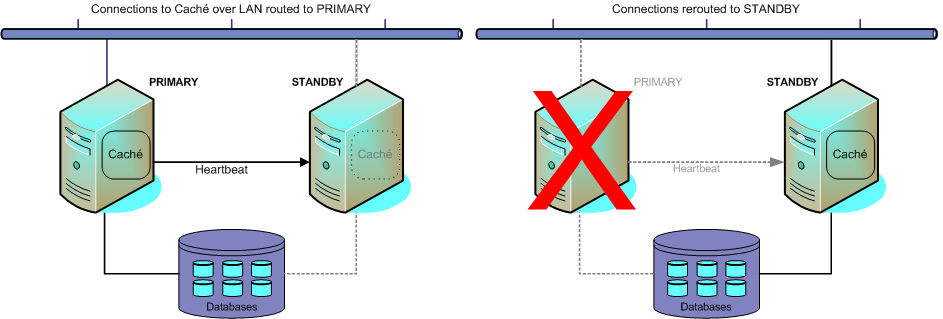
この手法では、共有ストレージ・デバイスに障害が発生すると深刻な状況となります。このことから、十分なリカバリ機能を実現するうえで、ディスクの冗長化、ジャーナリング、およびバックアップとリストアの良好な手順がきわめて重要です。
仮想化 HA
仮想化プラットフォームには HA 機能が用意されていることが一般的で、多くの場合、ゲスト・オペレーティング・システムとそこで稼働しているハードウェアの両方のステータスを HA 機能で監視します。いずれかで障害が発生すると、障害が発生した仮想マシンが仮想化プラットフォームによって自動的に再起動します。必要に応じて、代替のハードウェア上で再起動することもあります。Caché インスタンスが再起動するときは、通常の起動リカバリが自動的に実行され、WIJ、グローバルなジャーナリング、およびトランザクション処理によって、物理サーバ上で Caché が再起動した場合とまったく同様に構造上の整合性とデータの整合性が維持されます。
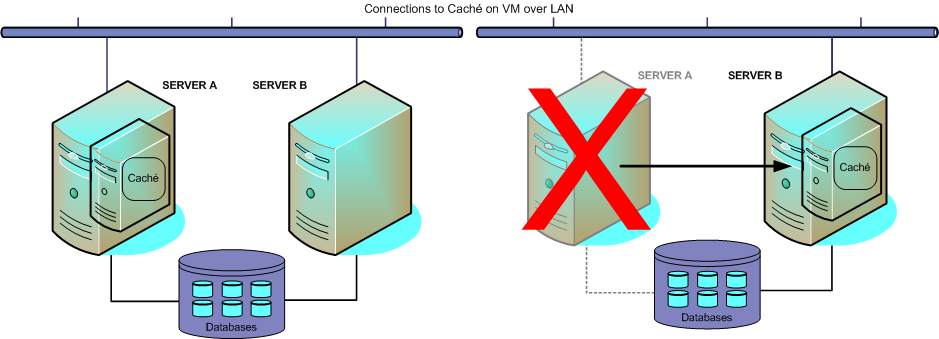
仮想化プラットフォームでは、保守上の目的で仮想マシンを代替のハードウェアに再配置することもできます。これによって、例えばダウン・タイムを発生させずに物理サーバをアップグレードできます。一方、仮想化 HA はフェイルオーバー・クラスタと並行クラスタの主な欠点も併せ持っているので、共有ストレージに障害が発生すると深刻な状況になります。
Caché ミラーリング
自動的なフェイルオーバーを組み合わせた Caché データベースのミラーリングでは、計画上の中断と計画外の中断に対応できる効果的で低コストの高可用性ソリューションを実現できます。ミラーリングはデータのレプリケーションに基づいており、共有ストレージに依存していないので、ストレージの障害に起因する深刻なサービスの中断を回避できます。
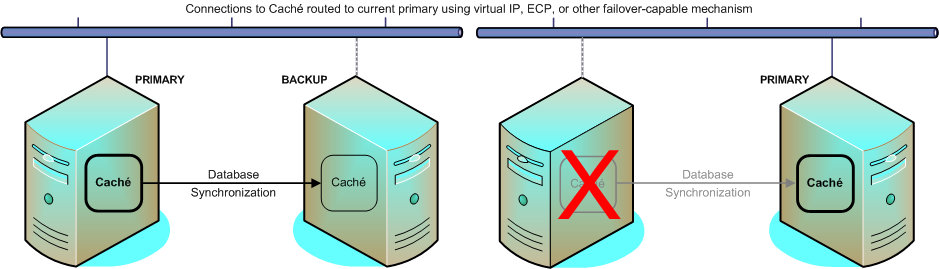
Caché ミラーは、フェイルオーバー・メンバと呼ばれる物理的に独立した 2 つの Caché システムで構成されます。各フェイルオーバー・メンバは、各ミラーされたデータベースのコピーをミラーに維持します。アプリケーションの更新はプライマリ・フェイルオーバー・メンバ上で実行され、バックアップ・フェイルオーバー・メンバのデータベースは、プライマリのジャーナル・ファイルを適用することでプライマリとの同期状態を維持します。(ジャーナリングの詳細は、"Caché データ整合性ガイド" の “ジャーナリング” の章を参照してください。)
ミラーでは、2 つのフェイルオーバー・メンバの一方にプライマリのロールが自動的に割り当てられます。これにより、もう一方のフェイルオーバー・メンバは自動的にバックアップ・システムになります。プライマリ Caché インスタンスに障害が発生するか、使用不可になると、バックアップ・インスタンスが短時間で自動的に引き継いでプライマリ・インスタンスとなります。
アービターと呼ばれる第 3 のシステムは、フェイルオーバー・メンバとの継続的な通信を維持し、メンバ間で直接通信できない場合にフェイルオーバーの決定を安全に下すために必要なコンテキストを提供します。各フェイルオーバー・システムのホストで動作しているエージェント・プロセス (ISCAgents) も自動フェイルオーバー・ロジックを支援します。プライマリが実際に停止しているか、使用不可になっていることが確認できない限り、バックアップは引き継ぐことができず、プライマリとして動作しません。アービターと ISCAgents 間では、ほぼすべての障害シナリオでこの確認を行うことができます。
別の方法として、ハイブリッド仮想化とミラーリング HA の手法 (このセクションの後半で説明) を使用している場合は、障害が発生したホスト・システムを仮想化プラットフォームから再起動できます。これにより、ミラーリング機能でプライマリ・インスタンスの以前のステータスを判断でき、その判断に応じて処理を続行できます。
仮想 IP アドレス (VIP) を使用するようにミラーを構成している場合は、アプリケーションの接続が新しいプライマリに透過的にリダイレクトされます。ECP による接続の場合は、自動的に新しいプライマリに再設定されます。アプリケーションの接続をリダイレクトする機能は、これらのほかにも用意されています。
プライマリ・インスタンスの動作が復帰した場合、このインスタンスは自動的にバックアップとなります。また、メンテナンスやアップグレードのための計画的な中断状態で、オペレータによるフェイルオーバーを使用して可用性を維持することもできます。
仮想化環境でミラーリング使用すると、その両方の利点を兼ね備えたハイブリッド高可用性ソリューションが作成されます。ミラーは計画的または計画外の停止に自動フェイルオーバーで即座に対応し、仮想 HA ソフトウェアは計画外のマシンの停止や OS の停止後にミラー・メンバをホストする仮想マシンを自動的に再起動します。これにより、障害が発生したメンバは、すぐにミラーに再参加できるようになり、バックアップとして動作します (必要であればプライマリを引き継ぎます)。
Caché ミラーリングの詳細は、このガイドの “ミラーリング” の章を参照してください。
フェイルオーバーを伴う ECP の使用
HA に向けてどの手法を採用する場合でも、エンタープライズ・キャッシュ・プロトコル (ECP) を使用することで、ユーザとデータベース・サーバとを分離するレイヤを実現できます。データベース・サーバに障害が発生しても、ユーザ側では ECP アプリケーション・サーバとの接続が維持されます。この中断の間にデータベースに頻繁にアクセスするユーザ・セッションは、フェイルオーバーの完了または障害が発生したシステムの再起動によってデータベース・サーバが再び利用可能になるまで一時停止状態になります。
なお、HA の計画に ECP を追加することでシステムが複雑になり、新たな障害点が発生することには注意を要します。
ECP の機能と実装の詳細は、このガイドの “ECP および高可用性” の章と "Caché 分散データ管理ガイド" を参照してください。