ECP and High Availability
One of the most powerful and unique features of Caché is the ability to scale efficiently by distributing data and application logic among a number of server systems. The underlying technology behind this feature is the Enterprise Cache Protocol (ECP), a distributed data caching architecture that manages the distribution of data and locks across a heterogeneous network of server systems. ECP application servers are designed to preserve the state of the running application across a failover of the data server. Depending on the nature of the application activity, some users may experience a pause until failover completes, but can then continue operating without interrupting their workflow.
This chapter describes how the ECP architecture works to maintain high availability in the following topics:
For more detailed information about ECP, see the Caché Distributed Data Management Guide.
ECP Architecture for High Availability
The typical ECP architecture for high availability includes a set of application servers connected to a data server.The application load is distributed across the application server tier by external load balancing, while the data server maintains the database state and may host some application load locally (such as batch activity). ECP provides efficient scaling by allowing additional application servers to be added to meet growing demand. To adequately meet demand even if an application server fails, the application server tier should have at least one server more than the number strictly required. The data server is made highly available by utilizing any one of the system failover strategies discussed in System Failover Strategies, as shown in the following illustration.
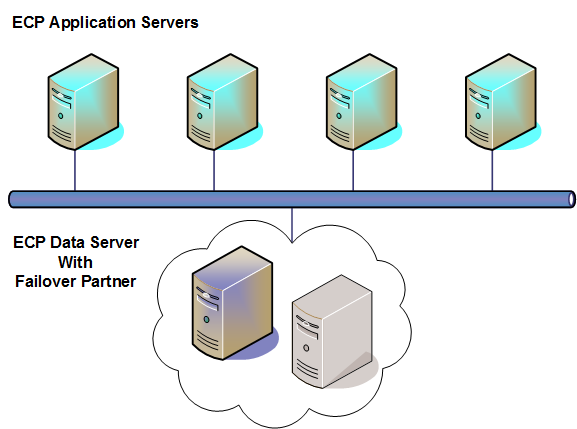
Regardless of the failover strategy employed for the data server, the application servers reconnect and recover their states following a failover, allowing application processing to continue where it left off prior to the failure. While this application recovery capability is beneficial for environments using ECP, it is not typically a reason on its own to introduce ECP when not otherwise needed. An application server itself may fail, requiring its users to reconnect, and the introduction of application servers adds complexity to the environment.
ECP Recovery and Failover
On failure of an ECP application server, data server, or the network connecting them, ECP goes through a recovery protocol that differs depending on the nature of the failure. The result is that the connection is either recovered, allowing the application processes to continue as though nothing had happened, or the connection is reset, forcing transactions to rollback and the application processes to get rebuilt. The main principles are as follows:
-
A data server waits only a short time (the Time interval for Troubled state setting, one minute by default) for an unresponsive application server, after which the data server resets its connection. This allows the data server to roll back transactions and release locks from the unresponsive application server so as not to block functioning application servers.
-
To allow enough time to recover the connection after a failover or restart of the data server, an application server waits a long time (the Time to wait for recovery setting, twenty minutes by default) for an unresponsive data server to become available again. If the time is exceeded then the application server resets its connection
-
When an application server’s connection is reset, any processes on the application server that are waiting for the data server receive <NETWORK> errors, and their transactions enter a rollback-only condition (see ECP-related Errors in the “Developing Distributed Applications” chapter of the Caché Distributed Data Management Guide.
The simplest case of ECP recovery is a temporary network interruption that is long enough to be noticed, but short enough that the underlying TCP connection stays active during the outage. During the outage, the application server notices that the connection is nonresponsive and blocks new network requests for that connection. Once the connection resumes, processes that were blocked are able to send their pending requests.
If the underlying TCP connection is reset, the data server waits for a reconnection for the Time interval for Troubled state setting (one minute by default). If the application server does not succeed in reconnecting during that interval, the data server resets its connection, rolls back its open transactions, and releases its locks. Any subsequent connection from that application server is converted into a request for a brand new connection and the application server is notified that its connection is reset.
The application server keeps a queue of locks to remove and transactions to roll back once the connection is reestablished. By keeping this queue, processes on the application server can always halt, whether or not the data server on which it has pending transactions and locks is currently available. ECP recovery completes any pending Set and Kill operations that had been queued for the data server before the network outage was detected, before it completes the release of locks.
Any time a data server learns that an application server has reset its own connection (due to application server restart, for example), even if it is still within the Time interval for Troubled state, the data server resets the connection immediately, rolling back transactions and releasing locks on behalf of that application server. Since the application server’s state was reset, there is no longer any state to be maintained by the data server on its behalf.
The final case is when the data server shut down, either gracefully or as a result of a crash. The application server maintains the application state and tries to reconnect to the database server for the Time to wait for recovery setting (20 minutes by default). The data server remembers the application server connections that were active at the time of the crash or shutdown; after restarting, it waits up to thirty seconds for those application servers to reconnect and recover their connections. Recovery involves several steps on the data server, some of which involve the data server journal file in very significant ways. The result of the several different steps is that:
-
The data server’s view of the current active transactions from each application server has been restored from the data server’s journal file.
-
The data server’s view of the current active Lock operations from each application server has been restored, by having the application server upload those locks to the data server.
-
The application server and the data server agree on exactly which requests from the application server can be ignored (because it is certain they completed before the crash) and which ones should be replayed. Therefore, the last recovery step is to simply let the pending network requests complete, but only those network requests that are safe to replay.
-
Finally, the application server delivers to the data server any pending unlock or rollback indications that it saved from jobs that halted while the data server was restarting. All guarantees are maintained, even in the face of sudden and unanticipated data server crashes, as long as the integrity of the storage devices (for database, WIJ, and journal files) are maintained.
During the recovery of an ECP-configured system, Caché guarantees a number of recoverable semantics which are described in detail in the ECP Recovery Guarantees section of the “ECP Recovery Guarantees and Limitations” appendix of the Caché Distributed Data Management Guide. Limitations to these guarantees are described in detail in the ECP Recovery Limitations section of the aforementioned appendix.