The Caché Database Engine
At the heart of Caché lies the Caché Database Engine. The database engine is highly optimized for performance, concurrency, scalability, and reliability. There is a high degree of platform-specific optimization to attain maximum performance on each supported platform.
Caché is a full-featured database system; it includes all the features needed for running mission-critical applications (including journaling, backup and recovery, and system administration tools). To help reduce operating costs, Caché is designed to require significantly less database administration than other database products. The majority of deployed Caché systems have no database administrators.
The major features of the database engine are described in the following sections.
Transactional Multidimensional Storage
All data within Caché is stored within sparse, multidimensional arrays. Unlike the multidimensional arrays used by typical OLAP (online analytic processing) products, Caché supports transaction processing operations (inserts, updates, locking, transactions) within its multidimensional structures. Also, unlike most OLAP engines, these multidimensional structures are not limited in size to available memory. Instead, Caché includes a sophisticated, efficient data cache.
Because Caché data is of inherently variable length and is stored in sparse arrays, Caché often requires less than half of the space needed by a relational database. In addition to reducing disk requirements, compact data storage enhances performance because more data can be read or written with a single I/O operation, and data can be cached more efficiently.
Multidimensional arrays give applications a great degree of flexibility in how they store their data. For example, a set of closely related objects, say an Invoice object and its corresponding LineItem objects, can easily be configured so that the LineItem objects are physically clustered with a Invoice object for highly efficient access.
The flexibility of transactional multidimensional storage gives Caché a significant advantage over the two–dimensional structure used by traditional relational databases: it is this flexibility that allows Caché to be a high-performance SQL, object, and XML database without compromise. It also means that Caché applications are better prepared for future changes in technology.
Mapping
Using a unique feature known as mapping, you can specify how the data within one or more arrays (or parts of arrays) is mapped to a physical database file. Such mapping is a database administration task and requires no change to class/table definitions or application logic. Moreover, mapping can be done within a specific sparse array; you can map one range of values to one physical location while mapping another to another file, disk drive, or even to another database server. This makes it possible to reconfigure Caché applications (such as for scaling) with little effort.
Process Management
A process is an instance of a Caché virtual machine running on a Caché server. A typical Caché server can run thousands of simultaneous processes depending on hardware and operating system. Each process has direct, efficient access to the multidimensional storage system.
The Caché virtual machine executes instructions (called P-code) that are highly optimized for the database, I/O, and logic operations typically required by transaction processing and data warehousing applications.
Lock Management
To support concurrent database access, Caché includes a powerful Lock Management System.
In systems with thousands of users, reducing conflicts between competing processes is critical to providing high performance. One of the biggest conflicts is between transactions wishing to access the same data. Caché offers the following features to alleviate such conflicts:
-
Atomic Operations — To eliminate typical performance hot spots, Caché supports a number of atomic operations, that is with no need for application level locks. An example is the ability to atomically allocate unique values for object/row identity (a common bottleneck in relational applications).
-
Logical Locks — Caché does not lock entire pages of data while performing updates. Because most transactions require frequent access or changes to small quantities of data, Caché supports granular logical locks that can be taken out on a per-object (row) basis.
-
Distributed Locks — In distributed database configurations (see the next topic), the system automatically supports distributed locks.
Distributed Data Management
One of the most powerful features of Caché is its ability to link servers together to form a distributed data network. In such a network, machines that primarily serve data are known as Data Servers while those that mainly host processes, but little to no data, are known as Application Servers.
Servers can share data (as well as locks) using the Caché Enterprise Cache Protocol (ECP). ECP is effective because data is transported in packages. When information is requested across the network, the reply data package includes the desired data as well as additional related data. The natural data relationships inherent to objects and the Caché multidimensional data model make it possible to identify and include information that is related to the originally requested data. This “associated” information is cached locally either at the client or on the application server. Usually, subsequent requests for data can be satisfied from a local cache, thus avoiding additional trips across the network. If the client changes any data, only the updates are propagated back to the database server.
ECP makes it possible for applications to support a wide variety of runtime configurations including multi-tier and peer-to-peer.
Journal Management
To provide database integrity and reliability, Caché includes a number of journaling subsystems that keep track of physical and logical database updates. The journal management technology is also used to provide transaction support (a journal is used to perform transaction rollback operations) as well as database shadowing (a journal is used to synchronize a shadow server with a primary data server). As with the rest of the system, Caché lets you configure its journaling system to meet your needs.
Database Portability
Caché runs on, and is optimized for, a wide variety of hardware platforms and operating systems, as documented in the online InterSystems Supported PlatformsOpens in a new tab document for this release.
You can easily port applications developed with Caché as well as data from one platform to another. This can be as easy as installing Caché on the new platform and moving the database files to new system. When moving between some systems, you may need to run an in-place data conversion utility (to convert one endian representation to another).
Deployment Options
Caché supports a variety of different runtime configurations giving you maximum flexibility when you deploy your applications. You can switch between different deployment options by changing Caché system settings; typically there is no need to change your application logic.
Some basic deployment options are listed below.
Basic Client/Server Configuration
In the simplest client/server configuration, a single Caché data server services a number of clients (from one to many thousands, depending on the application and platform).
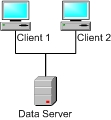
The client systems can be any of the following:
-
Stand-alone desktop systems running a client application that connects via a client/server protocol (such as ODBC, ActiveX, JDBC, Java).
-
Web server processes talking to Caché via Zen, CSP (Caché Server Pages), SOAP, or some other connectivity option (such as ODBC, JDBC). Each web server process may then service a number of browser-based or machine-to-machine sessions.
-
Middleware processes (such as an Enterprise Java Bean application server) that connect to Caché via ODBC, JDBC, etc.
-
Devices, such as terminals or lab equipment, that connect to Caché using one of many supported protocols (including TELNET and TCP/IP).
-
Some combination of the above.
Shadow Server Configuration
The shadow server configuration builds upon the basic client/server setup by adding one or more shadow servers. Each shadow server synchronizes itself with the data within the main data server by connecting to and monitoring its journal.
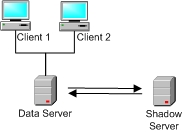
Shadow servers are typically used to service ad hoc queries, large reports, and batch processes to limit their impact on the main transaction system. They can also be used to provide failover systems.
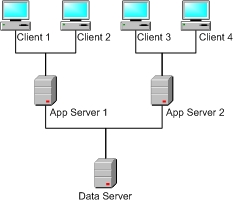
Multi-Tier Configuration
The multi-tier configuration uses the Caché distributed database technology — the Enterprise Cache Protocol (ECP) — to make it possible for a greater number of clients to connect to the system.
In the simplest multi-tier setup, one or more Caché systems, acting as application servers, are placed between the central data server and the various client systems. In this case the application servers do not store any data, instead they host processes that perform work for the benefit of the client, off-loading the CPU of the data server. This type of configuration scales best for applications that exhibit good “locality of reference,” that is most transactions involve reasonably related data so that locking across application servers is limited. Such applications, as well as those with a fair amount of read access (like most typical web applications), work extremely well in this model.
More complex configurations, with multiple data servers as well as data stored on application server machines, are also possible.
Typically applications use the multi-tier configuration for scaling as well as for providing high-availability (with applications servers serving as hot standby systems).