Zen レポートのデータの収集
Zen レポートのデータを収集する主な方法として、Zen レポート・クラスの XData ReportDefinition ブロックを指定します。XData ReportDefinition では、Caché データベースから取得するデータを指定して、このデータを XML としてフォーマットする方法を記述します。この XML が Zen レポートのソース・データになります。
次の章 “Zen レポートのページのフォーマット” では、XML データを HTML 形式または PDF 形式で表示するための XSLT 変換の生成方法について説明します。この章では、XSLT 変換の入力として使用できるように、ソース・データを XML としてフォーマットする方法について説明します。
項目は以下のとおりです。
以下のテーブルは、Zen レポートで使用する XML データ・ソースを生成する手法を示しています。
| 手法 | XML データ・ソースの生成で手法をどのように使用するか | 詳細 |
|---|---|---|
| XData ReportDefinition | Zen レポート・クラスに XData ReportDefinition ブロックを記述します。そのレポートを実行すると XML データ・ソースが生成されます。 | この章の “XData ReportDefinition” |
| DATASOURCE |
DATASOURCE クラス・パラメータの値を指定します。DATASOURCE は、Zen レポートで使用するデータを格納した XML ファイルを参照します。 Zen レポート・クラスで DATASOURCE の値を指定する場合や、ブラウザから Zen レポートを起動するときに、URI で対応する $DATASOURCE パラメータを指定する場合は、Zen レポート・クラスで XData ReportDefinition ブロックを省略できます。両方とも指定した場合は、DATASOURCE の値が優先し、指定した XData ReportDefinition は無視されます。 |
この章の “DATASOURCE” |
| 完全な WRITE |
レポートのすべてのソース・データとなる XML 文を出力するクラス・メソッドを、任意の言語で記述します。そのメソッドを、Zen レポート・クラスの XData ReportDefinition ブロックから、最上位の <report> 要素で call 属性および callClass 属性を使用して参照します。 この場合、この XData ReportDefinition ブロックを 1 つの <report> 要素で構成し、その要素で call 属性および (必要に応じて) callClass 属性を指定します。 |
この章の “クラス・メソッドからの XML 文の記述” |
| 部分的な WRITE | レポートのソース・データにある特定の場所で使用する XML 文のブロックを出力するクラス・メソッドを、任意の言語で記述します。そのメソッドを、Zen レポート・クラスの XData ReportDefinition ブロックから、<group> 要素で call 属性および callClass 属性を使用して参照します。 | この章の “クラス・メソッドからの XML 文の記述” |
| <call> | <call> 要素ではストリームを返すメソッドを呼び出し、<call> 要素の出現場所でストリームをレポート定義に挿入します。 | この章の “<call>” セクション |
| <callelement> | <call> と似ていますが、使用されているデータ・コンテキストの認識を提供します。 | この章の “<callelement>” セクション |
| <include> | XData ブロックに存在する XML 文のブロックを、XML データ・ソースに挿入します。この XData は、同じ Zen レポート・クラスに置くことも、他のクラスに置くこともできます。 | この章の “<include>” セクション |
| <macrodef> | 同じ Zen レポート・クラスや他のクラスの XData ブロックから ReportDefinition ビルディング・ブロックを ReportDefinition に配置します。 | この章の “<macrodef>” セクション |
| <get> | 他の Zen レポート・クラスにある XData ReportDefinition ブロックで生成した XML 文のブロックを、XML データ・ソースに挿入します。 | この章の “<get>” セクション |
| クラス・クエリ | XML データ・ソースを持つ完全な Zen レポートを生成します。それには、Zen レポート・ジェネレータに対して、定義済みのクエリがある既存の ObjectScript クラスから Zen レポート・クラスを生成するように要求します。生成される Zen レポート・クラスでは、このクラス・クエリによって XData ReportDefinition ブロックが生成されます。 | この章の “クラス・クエリからの Zen レポートの生成” |
ReportDisplay ブロックのデータ収集でも、いくつかの方法が使用できます。“ReportDisplay ブロックでのデータ収集” を参照してください。
XData ReportDefinition
XData ReportDefinition ブロックには、以下の構文要素があります。
-
<report> では、SQL クエリを定義するか、レポートで使用するデータが含まれる SQL 結果セットを指定します。
-
<group> 要素では、出力 XML の構成と編成を指定します。
-
<report> または <group> には、後述の “値ノード” を任意の順序や数で指定できます。これらの要素には、<report> および <group> で指定した出力 XML の構成内に表示されるデータ値を指定します。
-
<aggregate> — 合計や平均などの集約を計算し、結果を出力します。
-
<attribute> — 出力 XML に XML 属性を書き込みます。
-
<element> — 出力 XML に XML 要素を書き込みます。
-
-
<report> または <group> には、後述の要素を任意の順序で任意の数だけ指定できます。これらの要素によって、XML を外部ソースから現在の XData ReportDefinition ブロックに渡します。
-
<call> — ストリームを返すメソッドを呼び出し、要素の出現場所でストリームをレポート定義に挿入します。この機能により、別々に開発したサブレポートからレポートを作成できます。注意 : <call> は、<report> でのみ使用できます。<group> では使用できません。
-
<callelement> — <call> と似ていますが、使用されているデータ・コンテキストの認識を提供します。
-
<get> — 他の Zen レポート・クラスにある XData ReportDefinition ブロックで生成した XML 文を参照します。
-
<include> — Zen レポート・クラスまたは他のクラスの XData ブロックで一連の XML 文を参照します。
-
これらの構文要素で使用する式で、%val 変数は現在のクエリのフィールド値を表します。
以下の図で示しているのは、XData ReportDefinition ブロックの要素とデータの結果 XML 表現との間におけるリレーションシップです。左側には、SAMPLES データベースの ZenApp.MyReport からの ReportDefinition ブロックがあります。右側には、この ReportDefinition によって生成された XML があります。図の後に詳しい説明があります。

-
XData ReportDefinition の 最上位レベル <report> 要素に、myReport を値として持つ name 属性があります。これにより、<myReport> という名前の最上位コンテナ・ノードが XML 出力に得られます。sql 属性によって、データベースのデータを取得する SQL 文を渡します。
-
<report> コンテナでは、各 <attribute> 要素によってその親の <myReport> ノードを修飾する出力 XML 属性が生成されます。name 属性により、出力 XML 属性の名前を指定します。この例では、これらの名前は runTime、runBy、author、および month です。これらの属性の値は、XData ReportDefinition の中で対応する <attribute> の expression から得られます。例のこの部分では、各 expression によってサーバで ObjectScript 式が実行され、生成される XML に表示される値が生成されます。
-
この例では、<report> コンテナの直接の子となる <aggregate> 要素を 1 つ指定しています。XML 出力で <myReport> ノードの直接の子となる XML 要素が生成されます。この要素の名前は <grandTotal> で、XML 出力の <myReport> コンテナの最後 (<myReport> にある他の属性や要素の後) に記述されます。
<grandTotal> 要素には 1 つの値が設定されます。この値は、<aggregate> の type 属性と field 属性の組み合わせによって生成されます。この例では、データを渡す <report> の SQL クエリにある列 (“Num“) を field 属性で特定します。この例では、実行する集約の種類 (総和) を type で指定します。
-
最初の <group> 要素によって、階層のレベルをさらに追加しています。name 属性によって、<group> で作成される第 2 レベル・コンテナ・ノードの “SalesRep” 名が指定されます。この <group> では、<group> で使用可能なメソッドのいずれかを使用してその独自データを指定できますが、指定していないので、その親コンテナである <report> のデータ定義が継承されます。つまり、この <group> で使用される field 属性では、<report> によって生成されるデータを参照します。breakOnField 属性により、指定フィールドの値が変更されると新規ノードを出力で作成するように、XML 生成プロセスに指示します。その結果は一連の <SalesRep> ノードになり、結果セットで名前が付いた販売担当者ごとに 1 つあります。
<group> には <attribute> 要素が格納されます。この要素によって、XML 出力の各 <SalesRep> ノードを修飾する属性が生成されます。前述のように、生成された属性の名前が name により渡され、field により値が渡されます。この場合、属性は “name” と呼ばれ、この <group> で <report> から継承した SQL クエリで “SalesRep” 列から値は取得します。
-
最初の <group> には 2 番目の <group> 要素が格納され、“record” の名前で XML 出力の第 3 レベル・コンテナ・ノードを指定しています。<attribute> 要素により、属性の id と number が各 <record> ノードに追加されます。また、要素を各 <record> ノードに追加する <element> 要素も、この <group> に格納されます。<attribute> の場合と同様に <element> の name 属性と field 属性が機能して、生成された要素の名前と値を渡します。
-
最初の <group> にある <aggregate> 要素によって、XML 出力の <SalesRep> ノードの子となる XML 要素が生成されます。これらの要素の名前として、count、subTotal、および avg を指定しています。各集約要素には値が 1 つ設定されています。この値は前述のように、対応する <aggregate> の type 属性と field 属性の組み合わせによって生成されます。
%val 変数
%val は、XData ReportDefinition ブロックでのみ使用できる特別な変数です。すべての XData ReportDefinition 要素では、値が ObjectScript 式である属性で %val を使用できます。expression、breakOnExpression、および filter がその主な例です。
%val は、以降のトピックで説明するとおり、単一値または多次元とすることができます。
ObjectScript の一般的な知識は、これらの式の構成方法を知るうえで役立ちます。"Caché ObjectScript の使用法" の、特に “演算子と式” の章の “文字列関係演算子” を参照してください。
%val の使用先
%val は、値ノードの <element>、<attribute>、または <aggregate> の expression 属性で使用できます。%val は、同じ要素にある field 属性のフィールド値を表します。次の <element> にはこの例があります。
<element name="displayURL" field="ID" expression="..GetDisplayURL(%val)"/>以下の <attribute> の例も同様です。
<attribute name="name" field="SalesRep"
expression='$E(%val)_$ZCVT($E(%val,2,$l(%val)),"L")'/>expression 属性の値は ObjectScript 式であるため、上記の例では、$EXTRACT ($E) や $ZCONVERT ($ZCVT) などの ObjectScript 関数を使用して、結果セットの SalesRep という field に含まれているデータの書式を設定することができます。
<report> および <group> では、breakOnExpression で %val を使用して、breakOnField のフィールドの値を表すことができます。
<report>、<group>、<element>、および <attribute> では、filter 式で %val を使用できます。この場合、%val は同じ要素内の field 属性のフィールド値を表します。また、単一値ではなく多次元とすることもできます。
また、%val は、カスタム集約クラスの ObjectScript コード内でも機能します。
%val の多次元値
単一値 %val を使用できる場所には、次のような多次元形式を使用することもできます。
%val("CaseSensitiveFieldName")
この多次元形式を値ノードの <element> または <attribute> で使用する場合は、fields 属性 (field ではありません) にコンマで区切ったフィールド名のリストを指定します。次に、expression または filter 属性で、それぞれのフィールド名を添え字として付けたこれらの値を参照します。これらの添え字では大文字と小文字が区別されます。
次の例では、fields 属性で 2 つのクエリ・フィールドを参照し、次に、expression 属性の値で、%val の添え字としてこれらのフィールド名を使用しています。この例では、expression の値は、ObjectScript _ (アンダースコア) 連結演算子を文字列に使用する ObjectScript 式です。
<element name="message" fields="Customer,SaleDate"
expression='%val("Customer")_" has date "_%val("SaleDate")'/><report> および <group> でも、多次元 %val を使用できます。この機能を使用するには、<report> または <group> で fields 属性を指定しなければなりません。
引用規約は注意して使用してください。上記の expression の値では、一重引用符内に二重引用符を効果的に使用しています。以下の例では、filter の値を囲むために使用されている一重引用符内で、%val の添え字および文字 G に対して正しい引用規約が適用されています。
filter = '$E(%val(""TheaterName""))=""G""'
このように式内で注意して引用符を使用する代わりに、また、Zen レポート・クラスのモジュール性や柔軟性を高めるために、expression、breakOnExpression、filter などの属性では、属性の値としてクラス・メソッドへの参照を指定することもできます。その場合、式の属性内ではなく、そのメソッド内でロジックを指定します。以下は、この実際の例です。
filter="..Filter()"
上記の構文は、式で参照しているメソッドを Zen レポート・クラスでも定義していて、そのメソッドがゼロまたはゼロ以外の値を返すように定義されている場合に機能します。以下にその例を示します。
Method Filter()
{
If $E(%val("TheaterName"))="G" Quit 1
Quit 0
}代わりに、メソッドを次のように定義したとします。
Method Filter(input As %String)
{
If $E(input)="G" Quit 1
Quit 0
}この場合、以下のようにフィルタを設定できます。%val の添え字の引用規約に注意してください。
filter='..Filter(%val(""TheaterName""))'
<report> および <group>
<report> 要素は、XData ReportDefinition ブロック内の必須の最上位コンテナです。
別の <report> 要素と <group> 要素は、XData ReportDisplay ブロック内で使用されます。詳細は、“Zen レポートのページのフォーマット” を参照してください。
<report> では、レポートのデータを編成するために、0 個以上の <group> 要素を含んでいます。
レポートが入れ子になったグループを含んでいる場合、含まれる <group> をそれぞれ、それらを含んでいる <group> の子と呼びます。含んでいる <group> を、含まれる <group> 要素の親と呼びます。<report> 要素が 1 つのみある最上位を除いて、入れ子の各レベルには複数の <group> 要素を含めることができます。同じ親 <group> 内の同一レベルの <group> 要素を兄弟と呼びます。
XData ReportDefinition ブロックでは、<report> および <group> の構文規則は以下のようになります。
-
<report> では、name 属性を指定する必要があります。
-
<report> では、レポートのデータを編成するために、0 個以上の <group> 要素を含んでいます。
-
<report> でクエリ属性を指定することにより、レポートのデータ収集ができます。また、プロパティ runonce="true" を設定することにより、レポートの内容を実行できます。
-
<report> は、他の要素内で入れ子にすることはできません。
-
<group> には、<element>、<attribute>、および <aggregate> の各要素を 0 個以上、任意の順番で記述します。ただし、<element>、<attribute>、および <aggregate> の各要素は、入れ子にすることはできません。
-
<group> には、0 個以上の <group> 要素を記述します。詳細は、“入れ子になったグループ” および “兄弟グループ” を参照してください。
-
<group> では、グループ独自のクエリを定義できます。グループ独自のクエリが定義されていない <group> では、クエリが定義されている最も近い祖先の <report> または <group> からクエリが継承されます。詳細は、“<report> または <group> でのクエリの作成” および “フィールドまたは式に基づくブレーク” を参照してください。
<report> および <group> の属性
<report> と <group> には、次のテーブルに示す汎用属性があります。
| 属性 | 説明 |
|---|---|
| クエリ属性 | これらの属性を使用して、レポートのソース・データを取得できます。詳細は、後述の “<report> または <group> でのクエリの作成” を参照してください。 |
| ブレーク属性 | breakOnExpression 属性および breakOnField 属性を使用して、レポートのソース・データを編成できます。詳細は、後述の “フィールドまたは式に基づくブレーク” を参照してください。 |
| Direct XML 属性 | call 属性および callClass 属性を使用して、ソース・データを指定できます。それには、XML 文を <report> または <group> 定義で生成する代わりに、クラス・メソッドから記述します。“クラス・メソッドからの XML 文の記述” を参照してください。 |
| call | "Direct XML 属性" を参照してください。 |
| callClass | "Direct XML 属性" を参照してください。 |
| excelSheetName |
excelSheetName 属性により、生成されたワークシートの名前を指定できます。既定では、ワークシートに Excel シート用の既定名前付け規約 (Sheet1、Sheet2 など) が使用されます。単一シートのレポートに対しては <report> で excelSheetName を指定し、複数シートのレポートに対してはワークシートを定義する各 <group> でこれを指定します。excelSheetName 属性ではローカライズがサポートされています。"Zen レポートのローカライズ" を参照してください。 excelSheetName で最初の文字が ! (感嘆符) の場合、シート名を取得するために評価される ObjectScript 実行時式として後続の内容がレポートで解釈されます。実行時式により渡されるシート名は、ローカライズされません。 シート名の生成を詳細に制御する場合は、%ZEN.Report.reportPageOpens in a new tab に定義されているメソッド %getUniqueExcelSheetName をオーバーライドします。“複数シートのレポート” を参照してください。 |
| getxmlstylesheet | XSLT スタイル・シートの内容が格納されるストリームを返すメソッドの名前。このスタイル・シートを使用して、ReportDisplay ブロックで処理する前に、ReportDefinition ブロックで渡される XML で変換を実行します。“ReportDefinition XML の再構成” を参照してください。この属性は <report> 要素にのみ使用できます。 |
| name |
<report> または <group> は、この name を持つ XML 要素を出力に生成します。 指定した name が XML 識別子として無効な文字列である場合、レポートは正常に機能しません。明らかに使用を避けなければならない文字は、空白文字、および XML の標準エンティティの 5 文字 (&'<>") です。 グループが <report> の場合、name 属性が必要です。<group> では、name は省略可能です。指定しない場合、<group> によって自動的に名前が生成されます。 |
| suppressExcelHeaders |
suppressExcelHeaders 属性により、Zen レポートから Excel スプレッドシートを作成するときに通常生成されるすべてのヘッダを抑制できます。すべてのヘッダを抑制するには <report> に対して suppressExcelHeaders="true" を指定し、複数シートのレポートで関連付けられたワークシートのヘッダを抑制するには <group> に対してこれを指定します。 この属性で基本となるデータ型は %ZEN.Datatype.booleanOpens in a new tab です。“Zen レポート属性のデータ型” を参照してください。 |
| xmlstylesheet | XSLT スタイル・シートの内容が格納されるストリーム。このスタイル・シートを使用して、ReportDisplay ブロックで処理する前に、ReportDefinition ブロックで渡される XML で変換を実行します。“ReportDefinition XML の再構成” を参照してください。この属性は <report> 要素にのみ使用できます。 |
| xmlstylesheetarg | getxmlstylesheet によって指定されるメソッドのオプション引数。 |
<report> または <group> でのクエリの作成
<report> または <group> では、データを生成するための結果セットが必要です。この結果セットを取得するには、<report> または <group> で、クエリを指定してそれ自体の結果セットを生成できます。また、その祖先の <report> または <group> の要素の 1 つによって生成された結果セットを継承することもできます。
-
現在の <report> または <group> でクエリを指定するには、このセクションの以下のトピックを参照してください。
-
データの収集に使用するクエリ属性 — orderby、runonce、top などの重要な修飾子について説明します。
-
-
祖先の <report> または <group> からの結果セットの継承に関する詳細は、“入れ子になったグループ” を参照してください。
データの収集に使用するクエリ属性
<report> または <group> では、クエリを指定するための以下の属性がサポートされています。
| 属性 | 説明 |
|---|---|
| fields |
fields には、結果セット・クエリから選択した 1 つ以上の field 名のコンマ区切りリストを指定します。 空白を fields の値に使用することもできます。 %val 変数などを扱う filter 構文の詳細は、このテーブルの "filter" のエントリを参照してください。 詳細は、このテーブルの後に示す説明を参照してください。 |
| filter |
現在処理中の結果セットの行を、この <report> または <group> の XML 出力に含めるかどうかを決定する ObjectScript 式。式の評価結果が 0 の場合、その結果セットの行はスキップされます。 filter 式では、この <report> または <group> の fields 属性にリストした名前 (大文字と小文字が区別されます) を添え字として付けた %val 変数を使用して、結果セット・クエリのフィールドの値を参照することができます。構文に関する詳細は、“%val 変数” を参照してください。 ObjectScript の一般的な知識は、これらの式の構成方法を知るうえで役立ちます。“%val 変数” の ObjectScript に関するヒントと共に、"Caché ObjectScript の使用法" の、特に “演算子と式” の章の “文字列関係演算子” を参照してください。 |
| OnCreateResultSet | %ResultSetOpens in a new tab オブジェクトを作成するために呼び出すサーバ側コールバック・メソッドの名前。OnCreateResultSet の値は、Zen レポート・クラスで定義されたサーバのみのクラス・メソッド名に設定する必要があります。詳細は、“OnCreateResultSet コールバック・メソッド” を参照してください。 |
| orderby |
この <report> または <group> のクエリ内に既に存在する ORDER BY 句をオーバーライドするために使用する、コンマで区切られたフィールドのリスト。orderby 文字列の最初の文字に ! (感嘆符) を使用した場合、Zen レポートでは、文字列の残りの部分がその文字列を指定する ObjectScript 式として解釈されます。詳細は、このテーブルの後の “ReportDefinition の orderby 属性” を参照してください。レポートの ReportDisplay セクションでの orderby 使用に関する詳細は、“Zen レポートのデータの表示” の章の “ReportDisplay の orderby 属性” を参照してください。 |
| queryClass |
クエリを含むクラスの名前。この属性は、queryName の値も指定する場合にのみ使用します。 "Zen コンポーネントの使用法" の “Zen のテーブル” の章にある “クラス・クエリの参照” セクションでは、Zen ページでqueryClass を使用する方法が説明されています。 |
| queryName |
%ResultSetOpens in a new tab を指定するクラス・クエリの名前。クラス・クエリは SqlProc として投影される必要があります。queryClass の値も指定しないと、レポートでは、現在のレポート・クラスで定義されているクエリと見なされます。 "Zen コンポーネントの使用法" の “Zen のテーブル” の章にある “クラス・クエリの参照” セクションでは、Zen ページで queryName を使用する方法が説明されています。 |
| removeEmpty |
XData ReportDefinition ブロックで removeEmpty 属性を指定することで、<report> または <group> 要素によって生成された XML データに空白の値が含まれるようにするかどうかを制御します。つまり、クエリによって 1 つ以上の空白行を含む結果セットが返された場合の、これらの行の処理方法を removeEmpty で決定します。removeEmpty には以下のいずれかの値を設定できます。
Excel または xlsx 出力ではサポートされていません。 removeEmpty で基本となるデータ型は %ZEN.Datatype.booleanOpens in a new tab です。“Zen レポート属性のデータ型” を参照してください。 |
| runonce |
<report> や <group> の runonce 属性を True に設定すると、その <report> や <group> では独自のクエリを定義できません。代わりに、その <report> や <group> は、独自のクエリを定義できる他のグループのコンテナとして機能します。 <report> や <group> に runonce 属性を指定すると、その <report> や <group> に指定した sql、queryClass、またはその他のクエリ属性は無視されます。そのコンテナにあるサブグループでは、クエリ属性を定義できます。 runonce で基本となるデータ型は %ZEN.Datatype.booleanOpens in a new tab です。 “Zen レポート属性のデータ型” を参照してください。 |
| runtimeMode |
このレポートの結果を取得するために実行するクエリの SQL 実行時モード。可能な値は以下のとおりです。
ほとんどの場合、runtimeMode には既定値の 2 (DISPLAY モード) を指定すればよく、通常は変更する必要はありません。 %ResultSetOpens in a new tab を返すクエリの SQL 実行時モードの設定に関する詳細は、"Caché SQL の使用法" の “データベースの問い合わせ” の章の “ユーザ定義関数を呼び出すクエリ” を参照してください。 |
| sql |
<report> リストまたは <group> リストの内容を取得するサーバ側 SQL クエリ。詳細は、このテーブルの後に示す説明を参照してください。 |
| suppressRootTag | suppressRootTag により、レポートのルート・タグ生成を抑制します。これを行わない場合、レポートの name 属性から生成されます。ルート・タグの抑制が便利な状況は、レポートでその XML が DATASOURCE 経由のみで導出される場合や、<include> 要素や <call> 要素、および挿入された XML に独自のルート・タグが含まれる場合です。 |
| sqlexpression |
sqlexpression により、<table> または <group> の SQL クエリを提供するための COS 式の使用が可能になります。Zen レポートでは、コンパイル時に結果の SQL についての解析は行いません。 スタジオでは、sql 属性で行うような、属性値作成の支援はありません。詳細は、"sqlexpression プロパティ" を参照してください。 |
| top |
正の整数値。SQL クエリに記述した "SELECT TOP top" 句 ("SELECT TOP 10" など) と同じ効果があります。<group> または <report> で得られる結果の件数は、top で指定した数に制限されます。 |
以下の例は、sql 属性で返される結果セットから 2 つのフィールドを選択する fields 属性を示します。
<report
xmlns="http://www.intersystems.com/zen/report/definition"
name="fieldsTest" sql="Select Name, SSN, DOB from
Sample.Person WHERE Name > 'm'" fields="Name, SSN"
filter='%val(""Name"")=""Vonnegut,Agnes M.""'>
</report>sql 属性は、Zen レポート内でも <tablePane> 内と同様に機能します。ただし異なる点としては、すべての Zen クエリは表示モードで実行され、Zen レポートでは実行時モードを制御するための runtimeMode 属性がサポートされています。
sql は XML ブロックの中で使用するので、その値は XML の構文規則に従う必要があります。例えば、「より小さい」を意味する文字 < を比較に使用することはできません。< の代わりに、XML エンティティである < を使用する必要があります。以下はその例です。
sql="SELECT ID,Customer,Num,SalesRep,SaleDate
FROM ZENApp_Report.Invoice
WHERE (ID < 500)
ORDER BY SalesRep,SaleDate"
/* */ は、sql 文字列で唯一サポートされるコメント構文です。
sql およびクエリ・パラメータの使用法に関する詳細と例は、"Zen コンポーネントの使用法" の “Zen のテーブル” の章の “SQL クエリの指定” および “クエリ・パラメータ” を参照してください。
クエリの処理に関する標準的な規則
<report> または <group> のクエリの結果の処理に関する標準的な規則は、以下のとおりです。
-
存在しないフィールドを参照した場合、空の文字列 (つまり "") が返され、“見つかりません“ というエラーはトリガされません。
-
<report> または <group> でクエリを使用し、<element> が含まれていると、そのクエリを満たす各行に <element> の値が出力されます。
-
<group> にパラメータを使用したクエリが含まれており、その親 <group> に兄弟グループが存在する場合、パラメータは、親グループにあるパラメータの値、つまり、その親グループの最初の兄弟グループにブレークが発生する前にその最初の兄弟グループのパラメータが指定した値を参照します。
-
グループが入れ子になったグループの場合、行がブレーク条件を満たしているかどうかにかかわらず、グループはその親グループの行ごとにデータ行を取得します。したがって、ブレーク条件が満たされているかどうかに関係なく、親グループからすべてのデータが子グループそれぞれに渡されます。
-
兄弟グループは、ブレーク条件が満たされた後でのみデータを取得し、ブレーク条件が満たされる直前の行にあったデータを使用します。
-
1 つのグループ内の兄弟に <aggregate> 要素が含まれている場合、そのグループ内の最初の兄弟、およびクエリを提供する兄弟において集約が認識されます。兄弟グループでその独自クエリを渡す場合、集約はそのグループにおいて認識され、集約値はグループのクエリにより返される値を反映します。
sqlexpression プロパティ
COS 式に sqlexpression を添えて使用すれば、<table> または <group> の SQL クエリを提供できます。以下の例では、最初に Pattern という Zen レポート・プロパティを定義しています。
Property Pattern As %String(ZENURL = "PATTERN") [ InitialExpression = "M%" ];
次に、COS 式でプロパティを使用することで、データを伴うレポート生成のための結果セットを定義する SQL クエリを構築します。
XData ReportDefinition [ XMLNamespace = "http://www.intersystems.com/zen/report/definition" ]
{
<report xmlns="http://www.intersystems.com/zen/report/definition"
sqlexpression='""SELECT ID,NAME,SSN,AGE,HOME_STATE
FROM SAMPLE.PERSON WHERE NAME LIKE '""_%report.Pattern_""'""'
orderby="ID" name="people">
<group name='Persons' breakOnField="ID">
<group name='Person' >
<attribute field='ID' name='ID'/>
<attribute field='AGE' name="AGE"/>
<attribute field='Name' name='Name'/>
<attribute field='DOB' name='DOB'/>
<attribute field='SSN' name='SSN'/>
<attribute field='HOME_STATE' name='HOME_STATE'/>
</group>
<group name="MorePersons"
sqlexpression='""SELECT ID,NAME,SSN,AGE,HOME_STATE
FROM SAMPLE.PERSON WHERE NAME LIKE '""_%report.Pattern_""'""'
orderby="ID">
<element field="Name" name="Name"/>
</group>
</group>
</report>
}
ReportDefinition の orderby 属性
orderby 属性により、この <report> または <group> のクエリが取得する結果セットの並び順を指定するフィールドのコンマ区切りリストが提供されます。この属性はクエリ内に既に存在する ORDER BY 句をオーバーライドするので、ストアド・プロシージャまたはクラスにより返される結果セットの並び順を変更する場合、および Zen レポートのクエリの書き換えができない場合に有用となります。orderby は、結果セットがテーブルから取得された後に並べ替えを適用するので、orderby 文字列で使用する名前は、SQL SELECT 文で適用するエイリアスを反映する必要があります。レポートの ReportDisplay セクションでの orderby 使用に関する詳細は、“Zen レポートのデータの表示” の章の “ReportDisplay の orderby 属性” を参照してください。
orderby 文字列にリストするフィールドはすべて、この <report> または <group> のクエリの SELECT 句で既に指定されている必要があります。また、orderby は、クエリが明示的に定義されていない <report> または <group> では使用できません。
orderby 値では、昇順と降順のどちらで並べ替えるかを指定できます。これを行うには、“\” (円記号)、および ASC または DESC のいずれかの文字列を orderby リストのフィールドの名前に追加します。既定の並べ替えは昇順となります。ASC や DESC の文字列では、大文字と小文字は区別されません。以下はその例です。
orderby="customer\desc"
以下の例では、orderby にリテラル値を指定しています。この例では、クエリは SalesRep および Customer を基準として並べ替えられます。元のクエリの SalesRep および SaleDate は基準として使用されません。
<report
xmlns="http://www.intersystems.com/zen/report/definition"
name="myReport"
sql="SELECT ID,Customer,Num,SalesRep,SaleDate
FROM ZENApp_Report.Invoice
WHERE (Month(SaleDate) = ?) OR (? IS NULL)
ORDER BY SalesRep,SaleDate"
orderby="SalesRep,Customer" >
<!-- Supply values to the ? query parameters here -->
<parameter expression='..Month'/>
<parameter expression='..Month'/>
<!-- Other report contents appear here -->
</report>orderby 文字列の最初の文字に ! (感嘆符) を使用した場合、Zen レポートでは、文字列の残りの部分がその文字列を指定する ObjectScript 式として解釈されます。以下の例では、Zen レポート・クラスのプロパティ SortOrder を参照して、orderby 属性の値を指定しています。ReportDefinition ブロックで評価される ObjectScript の現在のクラスが Zen レポートであるため、二重ドット構文を使用して、レポート・クラスのプロパティを参照することができます。ReportDisplay ブロックでは評価コンテキストが異なるので、別の構文が必要となることに注意してください。
<report
xmlns="http://www.intersystems.com/zen/report/definition"
name="myReport"
sql="SELECT ID,Customer,Num,SalesRep,SaleDate
FROM ZENApp_Report.Invoice
WHERE (Month(SaleDate) = ?) OR (? IS NULL)
ORDER BY SalesRep,SaleDate"
orderby="!..SortOrder" >
<!-- Other report elements here -->
</report>上記の例を機能させる方法の 1 つとして、レポートを起動するときに orderby の値を動的に指定する方法があります。そのためには、ZENURL データ型パラメータを、対応する Zen レポート・クラスのプロパティ SortOrder に割り当てます。以下はその例です。InitialExpression の値は役立つ場合もありますが、レポートを起動するときにこのプロパティの値を指定する限り、必須ではありません。
Property SortOrder As %String(ZENURL="$SORTME")
[ InitialExpression="SalesRep,Customer"];
上記のとおり SortOrder を定義すると、ここで示すように URI で レポートを起動することによって、orderby の値を変更することができます。正しい URI は、1 行にすべてを記述しますが、次のサンプル URI ではわかりやすくするために改行が追加されています。
http://localhost:57772/csp/mine/my.ZENReport.cls ?$SORTME=Customer,SaleDate&$EMBEDXSL=1
orderby 属性を有効にするには、Zen レポート・クラスで SQLCACHE クラス・パラメータを 1 (True) に設定する必要があります。これは SQLCACHE の既定値です。
OnCreateResultSet コールバック・メソッド
サーバ側コールバック・メソッドの指定に OnCreateResultSet 属性を使用した場合、次の例のようになります。
<report
xmlns="http://www.intersystems.com/zen/report/definition"
name="PersonReport" OnCreateResultSet="CreateRS" >
<parameter value="B"/>
<group name="Person">
<attribute name="Name" field="Name"/>
<attribute name="Age" field="Age"/>
<attribute name="FavoriteColors" field="FavoriteColors"/>
</group>
</report>OnCreateResultSet 属性で指定したメソッドは、特定のシグニチャを使用してページ・クラス内で定義する必要があります。以下に例を示します。
ClassMethod CreateRS(ByRef pSC As %Status, ByRef tParams) As %ResultSet
{
set statement=##class(%SQL.Statement).%New()
if '$$$isObject(statement) set pSC=%objlasterror Quit ""
set sql="SELECT Name,Age,FavoriteColors FROM Sample.Person WHERE Name %STARTSWITH ?"
set pSC=statement.%Prepare(sql)
if $$$ISERR(pSC) Quit ""
set statement.%SelectMode=2
set rs=statement.%Execute(tParams(1))
quit rs
}以下はその説明です。
-
コールバック・メソッドは、%SQL.StatementOpens in a new tab オブジェクトの新規インスタンスをインスタンス化する必要があります。
-
その後、コールバックは %SQL.Statement.%Prepare メソッドを使用して、SQL 文を準備します。
-
コールバック・メソッドは、SQL 文の準備中にエラーが発生したかどうかを示すために、ステータス・コードを参照で返します。
-
必須のインバウンド引数 pParams は、上記の例の STARTSWITH の値 "B" などの、<report> 定義または <group> 定義で指定した <parameter> の値を実行時に自動的に含める配列です。
-
コールバックは %SQL.Statement.%Execute メソッドを使用して結果セットを作成します。この結果セットが、<report> または <group> のデータ・ソースとなります。
-
pParams の配列には、1 で始まる数字を添え字として付けます。この数字は、<report> 定義または <group> 定義のこれらのパラメータの順序を示します。
Zen レポートでは、OnCreateResultSet 属性で指定したメソッドに必要なシグニチャは、<tablePane> で使用するものとは異なります。
クエリ・パラメータの使用法に関するその他の例は、"Zen コンポーネントの使用法" の “Zen のテーブル” の章の “クエリ・パラメータ” を参照してください。
フィールドまたは式に基づくブレーク
<group> では、breakOnExpression および breakOnField 属性を使用して、その <group> が含む <report> または <group> から受け取った結果セットのレコードを編成することができます。アイテムに基づいて “ブレークする” とは、“この結果セットのフィールドの値が変化したときにこのグループを終了する” ことを意味します。
ここで言う結果セットとは、その <group> 自身ではなく、<group> の親によって定義された結果セットのことです。例えば、コンテナであるグループとそれに含まれるグループを、次のように定義したとします。この例の省略記号 (...) は、省略された構文の項目を表しています。
<group name="SalesByState" sql="SELECT STATE,...">
<group name="SalesByCity"
sql="SELECT CITY ... FROM ... WHERE STATE=?"
breakOnField="STATE">
<parameter field="STATE"/>
...
</group>
...
</group> 含まれるグループは、ある州のすべての都市をリストし、州が変わるとそのグループを閉じます。 breakOnField は、そのコンテナであるグループ SalesByState を参照します。これは、<parameter> がそのコンテナであるグループ SalesByCity を参照するのと同じ理由です。含まれる項目は、コンテナ項目から提供された結果セットをフィルタ処理します。
フィールドまたは式に基づくブレークに使用する属性
<group> では、親から提供された結果セットのレコードをグループ化するための以下の属性がサポートされています。<group> でいずれの “ブレーク” 属性も指定しなかった場合、フィルタ処理は行われず、<group> では、その親のクエリから提供された結果セットのすべてのレコードが処理されます。
| 属性 | 説明 |
|---|---|
| breakOnExpression |
breakOnField で指定したフィールドの値に適用される ObjectScript 式。式内の %val は、現在処理中の結果セットのレコードの breakOnField の実際の値を表します。構文に関する詳細は、“%val 変数” を参照してください。 ObjectScript の一般的な知識は、これらの式の構成方法を知るうえで役立ちます。“%val 変数” の ObjectScript に関するヒントと共に、"Caché ObjectScript の使用法" の、特に “演算子と式” の章の “文字列関係演算子” を参照してください。 |
| breakOnField |
この <group> のコンテナである <report> または <group> から返される結果セットのフィールドの名前。つまり、入れ子にされた <group> に割り当てる breakOnField の値を選ぶ場合、1 レベル上の親を見て、入れ子にされた <group> の編成に使用可能なフィールドを見つける必要があります。 <group> に breakOnField 属性を設定する場合、入れ子にされた <group> で breakOnField として指定するフィールドを、そのコンテナである <report> または <group> のクエリで ORDER BY によって並べ替えておく必要があります。これは、フィールドに基づいてブレークすると、結果セットが順番に調べられ、指定したフィールドが変わった時点でブレークが生成されるためであり、クエリを breakOnField 順に並べておかないと、入れ子にされた <group> の出力で予期しないブレークが発生する可能性があります。 |
以下の例では、上のテーブルで示した属性をいずれも使用しています。
ここでは、月別にグループ化する処理を行う必要があり、また、日付を入力引数として取り、月を示す値を返す GetMonth というメソッドを Zen レポート・クラスで定義済みであると想定します。この場合、breakOnField を結果セットの日付が含まれるフィールドに設定して、breakOnExpression を使用してレコードのグループ化で使用する月を計算することができます。以下がその例です。
<report xmlns="http://www.intersystems.com/zen/report/definition"
name='myReport'
sql="SELECT ID,Customer,Num,SalesRep,SaleDate
FROM ZENApp_Report.Invoice
ORDER BY SalesRep,SaleDate">
<group name="month"
breakOnField="SaleDate"
breakOnExpression="..GetMonth(%val)">
<!-- contents of the group here -->
</group>
</report>フィールドまたは式に基づくブレークに使用する値の選択
このセクションでは、breakOnField を使用する <group> 要素の誤った例と正しい例を示します。
以下の例では、salesRep3ab という名前の <group> に誤りがあります。このグループの breakOnField の値には SSN が指定されていますが、SSN はそのグループ自身のクエリに含まれるフィールドです。このフィールドは、親 <group> のクエリから提供されるフィールドである必要があります。
<group name="salesRep3a" breakOnField="Name"
sql="SELECT HOME_CITY from sample.person WHERE Name=? ORDER BY HOME_CITY">
<parameter field="Name"/>
<attribute expression="$G(%node(2))" name="num"/>
<attribute field="Name" name="name"/>
<element name="City" field="HOME_CITY"/>
<group name="salesRep3ab" breakOnField="SSN"
sql="SELECT SSN from sample.person WHERE HOME_CITY=?">
<parameter field="HOME_CITY"/>
<element field="SSN" name="SSN3ab"/>
</group>
<group name="salesRep3ac"
sql="SELECT SSN from sample.person WHERE HOME_CITY=?">
<parameter field="HOME_CITY"/>
<element field="SSN" name="SSN3ac"/>
</group>
</group> 以下は、上記の誤った例に対する正しい例です。ここでは、salesRep3ab という名前の <group> は適切に設定されています。指定されている HOME_CITY は、コンテナであるグループ salesRep3a のクエリに含まれるフィールドです。
<group name="salesRep3a" breakOnField="Name"
sql="SELECT HOME_CITY from sample.person WHERE Name=? ORDER BY HOME_CITY">
<parameter field="Name"/>
<attribute expression="$G(%node(2))" name="num"/>
<attribute field="Name" name="name"/>
<element name="City" field="HOME_CITY"/>
<group name="salesRep3ab" breakOnField="HOME_CITY"
sql="SELECT SSN from sample.person WHERE HOME_CITY=?">
<parameter field="HOME_CITY"/>
<element field="SSN" name="SSN3ab"/>
</group>
<group name="salesRep3ac"
sql="SELECT SSN from sample.person WHERE HOME_CITY=?">
<parameter field="HOME_CITY"/>
<element field="SSN" name="SSN3ac"/>
</group>
</group> フィールドに基づくブレークに使用する ObjectScript 式
breakOnField 文字列の最初の文字に ! (感嘆符) を使用した場合、Zen では、文字列の残りの部分がその文字列を指定する ObjectScript 式として解釈されます。以下の例では、Zen レポート・クラスのプロパティ GroupBy を参照して、breakOnField 属性と orderby 属性の値を指定しています。
<group name="Admissions" queryClass="Report.CurrentAdmissions"
queryName="FindAllAdmsInWard" orderby="!..GroupBy" >
<parameter expression="..Hospital"/>
<parameter expression="..Unit"/>
<parameter expression="..Ward"/>
<parameter expression="..Consultant"/>
<parameter expression="..GroupOption"/>
<parameter expression="..SortOption"/>
<parameter expression="..UserName"/>
<group name="GroupBy" breakOnField="!..GroupBy">
<group name="Admission" >
<attribute field="AdmDate" name="AdmDate"/>
<attribute field="AdmTime" name="AdmTime"/>
<attribute field="PatNo" name="URN"/>
<attribute field="AdmNo" name="AdmNo"/>
<attribute field="PatName" name="Surname"/>
<attribute field="PatName2" name="GivenName"/>
<attribute field="Sex" name="Sex"/>
<attribute field="Age" name="Age"/>
<attribute field="BedCode" name="BedCode"/>
<attribute field="LocationCode" name="LocationCode"/>
<attribute field="DoctorDesc" name="DoctorDesc"/>
<attribute field="insdesc" name="insdesc"/>
<attribute field="CARETYPDesc" name="CARETYPDesc"/>
</group>
</group>
</group> 上記の例を機能させる方法の 1 つとして、レポートを起動するときに breakOnField および orderby の値を動的に指定する方法があります。そのためには、ZENURL データ型パラメータを、対応する Zen レポート・クラスのプロパティ GroupBy に割り当てます。以下はその例です。InitialExpression の値は役立つ場合もありますが、レポートを起動するときにこのプロパティの値を指定する限り、必須ではありません。
Property SortOrder As %String(ZENURL="$SORTME")
[ InitialExpression="LocationCode" ];
上記のように SortOrder を定義しておくと、ここで示すように URI を指定してレポートを起動することによって、breakOnField および orderby の値を変更できます。正しい URI は、1 行にすべてを記述しますが、次のサンプル URI ではわかりやすくするために改行が追加されています。
http://localhost:57772/csp/mine/my.ZENReport.cls ?$SORTME=Hospital&$EMBEDXSL=1
入れ子になったグループ
あるグループが <report> または他の <group> の要素内にある場合、そのグループは入れ子となります。グループのレベルとは、レポート定義の最上位からそのグループまでの入れ子の深さです。Zen では、入れ子のレベル数に制限はありません。
入れ子になったグループにクエリを設定する方法は主に 2 つあります。Zen レポートで可能な操作を以下に示します。
-
親グループのクエリを定義して、入れ子にされたグループにクエリの返す結果セット (クエリのフィールドでのブレークを含めて) を処理させる。
-
親グループでクエリを 1 つ定義し、入れ子にされたグループでも追加のクエリを定義する。この場合、各子グループのクエリは通常、親のクエリからパラメータを受け取ります。子のクエリは、親のクエリの新しいブレークの値ごとに 1 回実行されます。次のコードは、この規則の例を示しています。
<report sql="SELECT City FROM Table1 ORDER BY City"> <group name="City" breakOnField="City" sql="SELECT Employee FROM Table2 WHERE City=?"> <parameter field="City"/> ... </group> </report>
グループを処理するときに、ブレーク条件を満たさないデータは、入れ子になったグループに渡されます。
Zen レポートで入れ子グループを使用しているときには、クエリ内のフィールドへの参照は次の一連のルールに従って解決されます。
-
<group> ごとに (外側の <report> を含む)、そのグループのレベルにおけるクエリ・コンテキストを定義します。
-
子の <group> で新しいクエリが定義されない場合、<group> では、親グループのクエリがその子自体のクエリであるかのように使用されます。
-
<group>、<parameter>、または <attribute> 要素内のフィールドへの参照は、現在の要素から 1 レベル上のクエリを参照することによって解決されます。
-
<element> または <aggregate> 要素内のフィールドへの参照は、現在の要素と同じレベルのクエリを参照することによって解決されます。
以下は、クエリ内のフィールドへの参照の解決例です。
-
Name は Table1 から取得されます。
<report sql="SELECT Name FROM Table1"> <element name="A" field="Name"/> ... -
Name は解決されず、エラーとなります。
<report sql="SELECT Name FROM Table1"> <attribute name="A" field="Name"/> ... -
Name は Table2 から取得されます。
<report sql="SELECT Name FROM Table1"> <group name="Name" sql="SELECT Name FROM Table2 WHERE..."> <element name="A" field="Name"/> ... -
Name は Table1 から取得されます。
<report sql="SELECT Name FROM Table1"> <group name="Name" sql="SELECT Name FROM Table2 WHERE..."> <attribute name="A" field="Name"/> ...
入れ子になったグループによって返されるデータ結果を適切に処理するために、“<report> または <group> でのクエリの作成” のセクションのルールを参照してください。次のセクションの “兄弟グループ” も参照してください。
兄弟グループ
複数のグループが、同一レベルの同じ <report> または親 <group> 内に含まれている場合、それらは兄弟となります。
兄弟グループは、Zen レポート・クラスで SQLCACHE クラス・パラメータを 1 (True) に設定した場合にのみ機能します。これが既定の設定です。SQLCACHE を 0 (False) に設定すると、Zen レポートは以前と同様に機能しますが、レポートで兄弟グループまたは兄弟要素を使用した場合にエラーが返されます。
兄弟グループにクエリを設定する方法は主に 2 つあります。
-
兄弟のそれぞれで独自のクエリを定義する。この場合、兄弟それぞれの WHERE 節により親のクエリのブレーク・フィールドを参照します。
-
最初の兄弟はブレーク条件をテストしてそのレコードを出力し、次に後続の兄弟が同じブレーク・フィールドの処理を行う。
ブレーク条件は、最初の兄弟にのみ適用されます。breakOnField 属性と breakOnExpression 属性は、兄弟内の順序で最初に来ない <group> では無視されます。この動作の理由は、後続の兄弟が、最初の兄弟のブレーク条件で定義されたセットからの最終レコードしか受け取らないことにあります。後続の兄弟は 1 つのレコードしか処理しないので、ブレーク条件は無関係となります。
以下の例は、最初の方法を示しています。company という親グループには、2 つの兄弟グループ cname および crev が含まれています。親グループでは、breakOnField=“Company” と定義しています。2 つの兄弟グループは “Company“ の値を使用して、レポートが提供する結果セットの各従業員の会社に関する情報を検索します。
<report xmlns="http://www.intersystems.com/zen/report/definition"
name="SiblingGroupReport"
sql="SELECT TOP 10 Name,Company FROM Sample.Employee ORDER BY Company" >
<group name="company" breakOnField="Company" >
<attribute name="companyID" field="Company" />
<!-- Both sibling groups process all employee records. -->
<!-- First sibling group looks up company name for each employee. -->
<group name="cname"
sql="SELECT Name FROM Sample.Company WHERE ID = ?">
<parameter field="Company"/>
<attribute name="employee" field="Name" />
<element name="company_name" field="Name" />
</group>
<!-- Second sibling group looks up company revenue for each employee. -->
<group name="crev"
sql="SELECT Revenue FROM Sample.Company WHERE ID = ?">
<parameter field="Company"/>
<attribute name="employee" field="Name" />
<element name="company_revenue" field="Revenue" />
</group>
</group>
</report>次の図は、このレポートの XML 出力を示しています。親グループは、結果セットの各会社に対して company という XML 要素を作成します。スペース節約のため、この画像では 1 番目の会社の XML は閉じられていますが、companyID="2" の個所でも結果を確認できます。このレポートでは、各従業員に会社名と会社の収益を提示する要素を作成しています。

以下の例は、2 番目の方法を示しています。SiblingGroupReport というレポートには、2 つの兄弟グループ EmployeeByCompany および CompanyName が含まれています。最初のグループでは、“Company“ フィールドを breakOnField と定義しています。これにより従業員のレコードがすべて処理されます。breakOnField フィールドの値が変わると、Zen レポートではグループを閉じて、グループの最終レコードを後続の兄弟グループに渡します。この例では、2 番目のグループはそのレコードの “Company“ の値を使用して、会社名を検索します。
<report xmlns="http://www.intersystems.com/zen/report/definition"
name="SiblingGroupReport"
sql="SELECT TOP 10 Name,Age,Company AS CompanyID,Home_City,Home_State,Home_Zip
FROM Sample.Employee ORDER BY Company" >
<!-- First sibling group processes all employee records,
breaking on Company. -->
<group name="EmployeeByCompany" breakOnField="CompanyID" >
<attribute name="CompanyID" field="CompanyID" />
<element name="name" field="Name"/>
<element name="city" field="Home_City"/>
<element name="state" field="Home_State"/>
<element name="zip" field="Home_Zip"/>
</group>
<!-- Second sibling group gets only last employee record.
Uses it to look up company name. -->
<group name="CompanyName"
sql="SELECT Name FROM Sample.Company WHERE ID = ?" >
<parameter field="CompanyID" />
<attribute name="CompanyID" field="CompanyID" />
<element name="name" field="Name"/>
</group>
</report>次の図は、このレポートの出力を示しています。companyID="1" の XML はここでも閉じられています。companyID="2" でもこれを確認できます。レポートでは、要素 EmployeeByCompany の会社の全従業員に対して、出力を配置しています。要素 CompanyName には、会社名が記載されます。
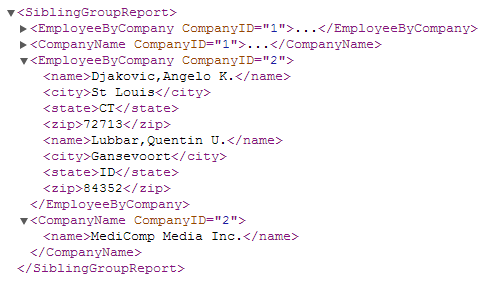
便宜上、特殊な変数 %node(level) が、指定されたレベルの現在の兄弟の続き番号に等しくなるように、最初の兄弟を 1 として順に定義されます。XData ReportDefinition ブロックの ObjectScript 式内でこの変数を使用できます。以下に例を示します。
<attribute expression="$G(%node(2))" name="num"/> 兄弟グループによって返されるデータ結果を適切に処理するために、“<report> または <group> でのクエリの作成” のセクションのルールを参照してください。また、前述のセクション “入れ子になったグループ”、および "<element>" のトピックの兄弟要素に関する説明も参照してください。
条件に応じて生成されたグループ
XData ReportDefinition ブロックの <group> 要素では、ifexpression 属性をサポートしています。この属性により、ユーザは実行時に出力される ZEN レポート・グループを選択できます。属性の値が 1 (既定値) の場合、グループは実行時に生成されます。属性を 0 に設定すると、そのグループとそのサブグループすべての生成は抑制されます。ZENURL プロパティを使用すると、属性の値を制御して、実行時のグループ生成をオフにできます。
以下の例では、ZENURL プロパティの IncludeRecord (定義は以下を参照) を使用します。
Property IncludeRecord As %Boolean(ZENURL="$INCLUDERECORD")
[ InitialExpression = 0 ];
これにより、record という名前のグループをレポートで生成するかどうかを管理します。
<group name="record" ifexpression="..IncludeRecord">
<attribute name='id' field='ID' />
<attribute name='number' field='Num' />
<element name='date' field='SaleDate' />
<element name='customer' field='Customer' />
</group>値ノード
ここでは、レポートのデータ内容を表示する要素について説明します。これらの要素はすべて、XData ReportDefinition ブロック内の <report> または <group> の子とすることができます。この要素は以下のとおりです。
-
<element> — 出力 XML に XML 要素を書き込みます。
-
<attribute> — 出力 XML に XML 属性を書き込みます。
-
<aggregate> — 合計や平均などの集約を計算し、結果を出力します。
空白の処理
Zen レポートの既定では、レポートに使用する目的で XML ソース・データを処理するときに、キャリッジ・リターン文字 (ASCII 13) が削除されます。属性 escape によってキャリッジ・リターン文字の削除が制御されます。これは、<element>、<attribute>、および <aggregate> 要素で使用できます。escape に指定できる値は次のとおりです。
-
"xml" — (既定) Zen レポートで、レポートに使用するために XML ソース・データを処理するときに、キャリッジ・リターン文字 (ASCII 13) が削除されます。
-
"none" — キャリッジ・リターン文字 (ASCII 13) は削除されません。元のテキストにスペースや改行文字が含まれているかどうかにかかわらず、すべての文字が保持されます。XML のエスケープは行われず、すべての文字は CDATA 構文で囲まれます。
-
"noneifspace" — Zen レポートで、レポートに使用するために XML ソース・データを処理するときに、キャリッジ・リターン文字 (ASCII 13) が削除されます。改行文字やスペース文字を含むテキストは、CDATA 構文で囲まれます。
-
"passthru" — キャリッジ・リターン文字 (ASCII 13) は削除されません。XML のエスケープは行われません。XML ドキュメントの有効状態を保持するには、要素内の XML データが有効でなければなりません。例えば、<foo> と </foo> のように、要素の開始タグと終了タグを必ず対で使用する必要があります。
特別な改行処理は <element> 要素にのみ適用され、<attribute> 要素は対象となりません。XML では、属性値に改行文字を記述できません。
値ノードの属性
値ノードの <element>、<attribute>、および <aggregate> には、どれも次の属性があります。
| 属性 | 説明 |
|---|---|
| accumIf |
(オプション) Zen レポートの集約を条件付きで累積すると便利な場合があります。そのため、値ノードには、0 (False) または 0 以外 (True) に評価される ObjectScript 式を値に持つ accumIf 属性があります。値ノードの accumIf 式が False に評価されると、その値ノードはスキップされます。その結果、その値ノードではレポートのデータ・ソースに何も書き込まれません。このテーブルの後の "accumIf" のセクションを参照してください。 |
| expression |
(オプション) field の値を出力する前に処理する ObjectScript 式。expression 内で、%val 変数を使用して field の実際の値を表すことができます。構文に関する詳細は、“%val 変数” を参照してください。 以下の例は、1 つの入力引数を持つ GetDisplayURL() メソッドが定義されている Zen レポート・クラスで機能します。 <element name="displayURL" field="ID" expression="..GetDisplayURL(%val)"/> 以下の例のように、レポートの実行時間などの静的なデータを返すために %val を使用せずに expression 属性を使用できます。この例では、ObjectScript 関数 $ZDATETIME ($ZDT) と特殊な値 $HOROLOG ($H) を使用して、タイムスタンプ値を返します。 <element name="runTime" expression="$ZDT($H,3)"/> ObjectScript の一般的な知識は、これらの式の構成方法を知るうえで役立ちます。“%val 変数” の ObjectScript に関するヒントと共に、"Caché ObjectScript の使用法" の、特に “演算子と式” の章の “文字列関係演算子” を参照してください。 |
| field |
(必須) field には、XML 出力のデータを取得する結果セットのフィールドを指定します。参照先の field は、このノードの結果セットに実際に存在する必要があります。この結果セットは、XData ReportDefinition ブロック内のこのノードに最も近い祖先ノードのクエリから提供された結果セットです。次のいずれかの場合があります。
値ノードの expression または filter 内で、%val 変数を使用して field の実際の値を表すことができます。 field 文字列の最初の文字に ! (感嘆符) を使用した場合、Zen では、文字列の残りの部分がその文字列を指定する ObjectScript 式として解釈されます。このテーブルの後の "Field" のセクションを参照してください。 |
| fields |
fields は field に似ていますが、結果セットから選択した 1 つ以上のフィールドのコンマ区切りリストを指定します。値ノードの expression または filter 内で、fields にリストした名前 (大文字と小文字が区別されます) を添え字として付けた %val 変数を使用して、これらのフィールドを参照できます。 %val 構文に関する詳細は、“%val 変数” を参照してください。 |
| filter | すべての値ノードで filter 属性がサポートされているわけではありません。<element> および <attribute> では filter がサポートされていますが、<aggregate> ではサポートされていません。filter に関する詳細は、それぞれの値ノードの説明を参照してください。 |
| name |
この名前を持つ XML 要素を出力に生成します。<element> を含む <report> または <group> の結果セットに month というフィールドがあり、month の有効な値の 1 つが文字列 July であると想定します。以下のようなエントリがあるとします。<element name="myMonth" field="month" /> レポートのデータを定義する XML に、以下のような要素が生成されます。<myMonth>July</myMonth> 指定した name が、XML 識別子として無効な文字列である場合、Zen レポート・クラスのコンパイルを試みるとエラーが発生します。明らかに使用を避けなければならない文字は、空白文字、および XML の標準エンティティの 5 文字 (&'<>") です。 name を指定しなかった場合、Zen では名前 item が使用されます。 |
accumIf
accumIf 式の構文では ObjectScript を使用することになっていますが、XData ReportDefinition 構文には XML のエスケープの問題があるので、accumIf 値では引用符の規約に注意する必要があります。値を一対の一重引用符で囲んだうえで、ObjectScript 構文では 1 つの二重引用符とする箇所に二重引用符を 2 つ記述します。以下の例では、<aggregate> の accumIf の値で Region と Northeast を囲む二重引用符にこの規約を適用しています。
<report xmlns="http://www.intersystems.com/zen/report/definition"
name="InsurancePolicies"
sql="SELECT Region,Flood,InsuredValue
FROM InsurancePolicies ORDER BY Flood">
<group name="Flood" breakOnField="Flood" >
<attribute name="Flood" field="Flood"/>
<group name="Policy">
<attribute name="Region" field="Region"/>
<attribute name="InsuredValue" field="InsuredValue"/>
</group>
<aggregate name="NortheastTotal" field="InsuredValue"
fields="Region" type="SUM"
accumIf='%val(""Region"")=""Northeast""' />
</group>
</report>この例では、Flood の値として <Y> と <N> の 2 つが考えられます。これらの値は、プロパティが米国政府機関が指定する洪水地域内にあるかどうかを示します。これらの値それぞれに対して、<aggregate> では米国北東部における保険価額を計算します。
field
field 文字列の最初の文字に ! (感嘆符) を使用した場合、Zen では、文字列の残りの部分がその文字列を指定する ObjectScript 式として解釈されます。以下の例では、Zen レポート・クラスのプロパティ GroupBy を参照して、<attribute> の field 属性の値と、別の要素の breakOnField 属性および orderby 属性の値を指定しています。
<group name="ReportTime">
<attribute name="timestamp" expression="$ZDATETIME($H, 2, 2)"/>
</group>
<group name="Admissions" queryClass="Report.CurrentAdmissions"
queryName="FindAllAdmsInWard" orderby="!..GroupBy" >
<parameter expression="..Hospital"/>
<parameter expression="..Unit"/>
<parameter expression="..Ward"/>
<parameter expression="..Consultant"/>
<parameter expression="..GroupOption"/>
<parameter expression="..SortOption"/>
<parameter expression="..UserName"/>
<group name="GroupBy" breakOnField="!..GroupBy">
<group name="Admission" >
<attribute field="!..GroupBy" name="groupby"/>
<attribute field="AdmDate" name="AdmDate"/>
</group>
</group>
</group>
上記の例を機能させる方法の 1 つとして、レポートを起動するときに field、breakOnField および orderby の値を動的に指定する方法があります。そのためには、ZENURL データ型パラメータを、対応する Zen レポート・クラスのプロパティ GroupBy に割り当てます。以下はその例です。InitialExpression の値は役立つ場合もありますが、レポートを起動するときにこのプロパティの値を指定する限り、必須ではありません。
Property GroupBy As %String(ZENURL="$SORTME")
[ InitialExpression="LocationCode" ];
上記のように GroupBy を定義しておくと、ここで示すように URI を指定してレポートを起動することによって、field、breakOnField、および orderby の値を変更できます。正しい URI は、1 行にすべてを記述しますが、次のサンプル URI ではわかりやすくするために改行が追加されています。
http://localhost:57772/csp/mine/my.ZENReport.cls ?$SORTME=Hospital&$EMBEDXSL=1
<element>
<element> 要素は、XData ReportDefinition ブロックの <report> または <group> 内で有効です。各 <element> によって、レポートの XML データ定義に XML 要素が追加されます。
<element> 属性
<element> には以下の属性があります。
| 属性 | 説明 |
|---|---|
| 値ノードの属性 | 詳細は、“値ノードの属性” を参照してください。 |
| escape |
ブラウザでは通常、表示されるページから余分だと見なされた空白が削除されます。そのため、出力で空白文字を保持する場合は、escape 属性を使用する必要があります。escape には以下の値を指定できます。
|
| fieldType |
要素によって取得されるデータの型を示す文字列。fieldType 属性の値は、"literal" (既定値) または "stream" です。fieldType が "stream" の場合、要素フィールドではストリームを取得する必要があります。取得しないとランタイム・エラーが発生します。 fieldType が "stream" の場合、expression 属性や %val は使用できません。 %val を使用して OID を処理する場合、fieldType を "literal" (既定値) にします。<element> の escape 属性を使用して、ストリームの変換方法 (< を「より小さい」を意味するエンティティに変換するかどうかなど) を指定できます。 |
| filter |
0 (False) と評価される場合と評価されない場合のある ObjectScript 式。filter 式の評価結果が 0 の場合、この <element> の処理はスキップされます。その結果、この <element> からの出力はレポートの XML データ内に表示されません。 filter 式では、%val 変数を使用して結果セット・クエリのフィールドの値を参照できます。以下が使用できます。
詳細は、“%val 変数” を参照してください。 ObjectScript の一般的な知識は、これらの式の構成方法を知るうえで役立ちます。“%val 変数” の ObjectScript に関するヒントと共に、"Caché ObjectScript の使用法" の、特に “演算子と式” の章の “文字列関係演算子” を参照してください。 |
| excelName |
Zen レポートから Excel スプレッドシートを生成している場合、excelName 属性を使用して、この <element> から生成された列のヘッダとして使用する文字列を指定できます。excelName が NULL の場合、列ヘッダは name 属性から取得されます。excelName 属性ではローカライズがサポートされています。"Zen レポートのローカライズ" を参照してください。 |
| excelNumberFormat |
Zen レポートから Excel スプレッドシートを生成している場合、excelNumberFormat 属性を使用して、数値の書式を設定する方法を Excel に指示する文字列を指定できます。この属性は、Excel スプレッドシートを xlsx モードで生成する場合と、EXCELMODE を “element” に設定する場合にのみ使用されます。"数値、日付および集約" を参照してください。 |
| isExcelDate |
既定では、<element> によって指定された値は、生成された Excel スプレッドシートのテキストとして解釈されます。属性 isExcelDate="true" を設定すると、この値は、Excel の日付として解釈されます。日付は、Excel の日付形式である必要があります。これは、%DATE または %TIMESTAMP が存在し、runtimeMode="1" (ODBC モード) の場合に、SQL を使用してフェッチするための日付表示形式です。Excel がこの値を日付として解釈できない場合、生成されたスプレッドシートを Excel で開こうとすると、エラーが発生します。"数値、日付および集約" を参照してください。 この属性で基本となるデータ型は %ZEN.Datatype.booleanOpens in a new tab です。“Zen レポート属性のデータ型” を参照してください。 |
| isExcelNumber |
既定では、<element> によって指定された値は、生成された Excel スプレッドシートのテキストとして解釈されます。属性 isExcelNumber="true" を設定すると、この値は、Excel の数値として解釈されます。Excel がこの値を数値として解釈できない場合、生成されたスプレッドシートを Excel で開こうとすると、エラーが表示されます。"数値、日付および集約" を参照してください。 この属性で基本となるデータ型は %ZEN.Datatype.booleanOpens in a new tab です。“Zen レポート属性のデータ型” を参照してください。 |
| isExcelTime |
既定では、<element> によって指定された値は、生成された Excel スプレッドシートのテキストとして解釈されます。属性 isExcelTime="true" を設定すると、この値は、Excel の時間として解釈されます。時間は、Excel の時間形式である必要があります。これは、%DATE または %TIMESTAMP が存在し、runtimeMode="1" (ODBC モード) の場合に、SQL を使用してフェッチするための時間表示形式です。Excel がこの値を時間として解釈できない場合、生成されたスプレッドシートを Excel で開こうとすると、エラーが表示されます。"数値、日付および集約" を参照してください。 この属性で基本となるデータ型は %ZEN.Datatype.booleanOpens in a new tab です。“Zen レポート属性のデータ型” を参照してください。 |
グループの兄弟としての要素
<group> は、別の <group> の兄弟として指定できます。兄弟グループの詳細は、<group> 要素に関するセクションの “兄弟グループ” を参照してください。<element> は、XData ReportDefinition ブロックの同じレベルにある 1 つ以上の <group> 要素の兄弟として指定できます。その場合、その同じレベルの順番で見て最初の兄弟グループである <group> は、そのレベルの各 <element> および各 <group> にとって特に重要な意味を持ちます。この <group> は、そのレベルの同僚グループと呼ばれます。
要素は、Zen レポート・クラスで SQLCACHE クラス・パラメータを 1 (True) に設定した場合にのみ、グループの兄弟として機能します。これが既定の設定です。SQLCACHE を 0 (False) に設定すると、Zen レポートは以前と同様に機能しますが、レポートで兄弟グループまたは兄弟要素を使用した場合にエラーが返されます。
ある <element> と <group> が兄弟であると想定します。この同じレベルの <group> は、独自のクエリからデータを取得するか、最も近い祖先の <report> または <group> によって定義されているクエリからデータを取得します。これに関する詳細は、この章の <group> の説明の “<report> または <group> でのクエリの作成” および “フィールドまたは式に基づくブレーク” を参照してください。
一方、兄弟レベルにある <element> は、結果セットのフィールドを含む行が同僚グループのブレーク条件を満たしているフィールドからデータを取得します。<element> に同僚グループが存在しない場合、XML 出力内の要素のコンテンツには、(値が互いに異なっていない場合でも) 結果セットの行ごとの指定されたフィールドの値が含まれます。
<attribute>
<attribute> 要素は、XData ReportDefinition ブロックの <report> または <group> 内で有効です。各 <attribute> によって、レポートの XML データ定義に属性が追加されます。この属性は、<attribute> のコンテナである <report> または <group> によって出力される要素を変更します。
属性および要素に関する構文の制約は、最初は理解しにくいかもしれません。そこで、初心者ユーザによってよく試行される Zen レポートの XData ReportDefinition ブロックの例を以下に紹介します。
<group name="surprise">
<element name="this" field="contains_the_value_x" />
<element name="that" field="contains_the_value_w" />
<attribute name="other" field="contains_the_value_y" />
<attribute name="thing" field="contains_the_value_z" />
</group>以下が期待される XML 出力です。
<surprise>
<this>x</this>
<that other="y" thing="z">w</that>
</surprise>それに対して、実際の XML 出力は以下のとおりです。
<surprise other="y" thing="z">
<this>x</this>
<that>w</that>
</surprise>Zen レポートの XData ReportDefinition ブロックでは、<element> 内に <attribute> を入れ子にすることはできません。そのため、以下のようには記述できません。
<element name="that" field="contains_the_value_w" >
<attribute name="other" field="contains_the_value_y" />
<attribute name="thing" field="contains_the_value_z" />
</element>以下の出力 XML の作成を試みます。
<that other="y" thing="z">w</that>
上記の例の <that> ノードでは、有効な XML 構文を使用していますが、このノードは、Zen レポートの XData ReportDefinition ブロック内で <element>、<attribute>、および <group> の各要素を組み合わせて生成することはできません。Zen レポートによって生成される XML には、以下の制約があります。
-
要素には、テキスト・コンテンツを含めることができますが、属性を含めることはできません。
-
グループには、属性と要素を含めることができますが、テキスト・コンテンツを含めることはできません。
以下にならって、XML 出力内に入れ子になった要素と属性を作成したいとします。
<surprise>
<this>x</this>
<that other="y" thing="z">w</that>
</surprise>上記の例を生成できる Zen レポートの XData ReportDefinition ブロックに最も近い例は、以下のとおりです。
<group name="surprise">
<element name="this" field="contains_the_value_x" />
<group name="that">
<element name="there" field="contains_the_value_w" />
<attribute name="other" field="contains_the_value_y" />
<attribute name="thing" field="contains_the_value_z" />
</group> </group>
この結果、以下の出力 XML が生成されます。
<surprise>
<this>x</this>
<that other="y" thing="z">
<there>w</there>
</that>
</surprise><attribute> には以下の属性があります。
| 属性 | 説明 |
|---|---|
| 値ノードの属性 | 詳細は、“値ノードの属性” を参照してください。 |
| escape |
ブラウザでは通常、表示されるページから余分だと見なされた空白が削除されます。そのため、出力で空白文字を保持する場合は、escape 属性を使用する必要があります。escape には以下の値を指定できます。
|
| filter |
0 (False) と評価される場合とされない場合のある ObjectScript 式。filter 式の評価結果が 0 の場合、この <attribute> の処理はスキップされます。その結果、この <attribute> からの出力はレポートの XML データ内に表示されません。 filter 式では、%val 変数を使用して結果セット・クエリのフィールドの値を参照できます。以下が使用できます。
詳細は、“%val 変数” を参照してください。 ObjectScript の一般的な知識は、これらの式の構成方法を知るうえで役立ちます。“%val 変数” の ObjectScript に関するヒントと共に、"Caché ObjectScript の使用法" の、特に “演算子と式” の章の “文字列関係演算子” を参照してください。 |
<aggregate>
<aggregate> 要素 は、<report> または <group> に関連付けられたクエリから返された結果セットの各レコードを対象に計算を実行します。その結果は、レポートの XML データ内のノードのコンテンツになります。
<aggregate> には以下の属性があります。
| 属性 | 説明 |
|---|---|
| 値ノードの属性 | 詳細は、“値ノードの属性” を参照してください。 |
| class |
type が CUSTOM の場合、%ZEN.Report.CustomAggregateOpens in a new tab を拡張したクラスのパッケージとクラス名を、class 属性で指定する必要があります。 参照可能な組み込みの集約クラスがいくつかあります。詳細は、後述の “組み込みの集約クラス” のリストを参照してください。 ユーザ定義機能を作成するには、ユーザ独自の %ZEN.Report.CustomAggregateOpens in a new tab サブクラスを作成します。“新規集約クラスの生成” を参照してください。 |
| escape |
ブラウザでは通常、表示されるページから余分だと見なされた空白が削除されます。そのため、出力で空白文字を保持する場合は、escape 属性を使用する必要があります。escape には以下の値を指定できます。
|
| excelFormula |
この集約が生成されたスプレッドシートの Excel 式であることを示します。この値は、集約の type と同等の Excel 式の名前にする必要があります。"数値、日付および集約" を参照してください。 |
| excelName |
Zen レポートを使用して Excel スプレッドシートを生成するとき、集約は、多くの場合 ReportDefinition の要素によって生成される列の下部に配置されます。この場合、集約は、この要素によって生成される列ヘッダを使用します。集約はあるが要素がないレポートから Excel スプレッドシートを生成できます。この場合、列ヘッダの既定値は、name 属性から取得されます。excelName 属性を使用して、この <aggregate> の列ヘッダとして使用する文字列を指定することも可能です。"数値、日付および集約" を参照してください。 excelName 属性ではローカライズがサポートされています。"Zen レポートのローカライズ" を参照してください。 |
| excelNumberFormat |
Zen レポートから Excel スプレッドシートを生成している場合、excelNumberFormat 属性を使用して、数値の書式を設定する方法を Excel に指示する文字列を指定できます。この属性は、Excel スプレッドシートを xlsx モードで生成する場合と、EXCELMODE を “element” に設定する場合にのみ使用されます。"数値、日付および集約" を参照してください。 |
| filter |
集約の条件付き挿入をサポートしています。filter の評価が 1 の場合、レポートには出力の集約が含まれます。 filter の評価が 0 の場合、レポートには集約が含まれません。filter 式では、集約の値を格納する特殊変数 %val を使用できます。 |
| format |
この集約からの出力をフォーマットする ObjectScript 式。format 式では、集約の値を格納する特殊変数 %val を使用できます。 |
| ignoreNLS |
実行時モードが DISPLAY (2) のときにのみ使用します。1 に設定した場合は、この集約に対する各国言語の設定処理を実行しません。0 に設定した場合は、NSL 処理を実行します。NULL ("") の場合は、ignoreNLS の値をパラメータ AGGREGATESIGNORENLS の値から取得します。既定値は、"" です。"集約の各国言語の設定" を参照してください。 |
| postprocessResult |
実行時モードが DISPLAY (2) のときにのみ使用します。1 に設定した場合、各国言語の設定の集約結果の後処理を実行します。False の場合、後処理は実行されません。NULL ("") の場合、レポートの生成中に、この属性の値が 1 に設定されます。既定値は、"" です。"集約の各国言語の設定" を参照してください。 |
| preprocessValue |
実行時モードが DISPLAY (2) のときにのみ使用します。1 に設定した場合、各国言語の設定の集約値の前処理を実行します。False の場合、前処理は実行されません。NULL ("") の場合、レポートの生成中に、この属性の値が 1 に設定されます。既定値は、"" です。"集約の各国言語の設定" を参照してください。 |
| type |
実行する集約の種類を指定します。有効な値は以下のとおりです。大文字と小文字は区別されます。
|
集約のフォーマット
format 属性により、集約の出力に対するフォーマットが適用されます。以下の例は、SAMPLES データベースの ZENApp.MyReportOpens in a new tab クラスからのものです。この例では、ObjectScript 関数 $NUMBER を使用して、avg という集約をフォーマットしています。
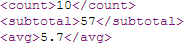
<group name='SalesRep' breakOnField='SalesRep'>
<attribute name='name' field='SalesRep' />
<aggregate name='count' type="COUNT" field='Num' />
<aggregate name='subtotal' type="SUM" field='Num' />
<aggregate name='avg' type="AVG" field='Num' format="$number(%val,2)" />
<group name="record">
<attribute name='id' field='ID' />
<attribute name='number' field='Num' />
<element name='date' field='SaleDate' />
<element name='customer' field='Customer' />
</group>
</group>以下の XML フラグメントは 3 つの集約を示しています。このように、avg をフォーマットしたものとなります。
ObjectScript の一般的な知識は、これらの式の構成方法を知るうえで役立ちます。“%val 変数” の ObjectScript に関するヒントと共に、"Caché ObjectScript の使用法" の、特に “演算子と式” の章の “文字列関係演算子” を参照してください。
集約の各国言語の設定
Zen レポートでは、集約の計算時の各国言語の設定 (NLS) をサポートします。NLS サポートは、パラメータ AGGREGATESIGNORENLS と、プロパティ ignoreNLS、preprocessValue、および postprocessResult で制御されます。AGGREGATESIGNORENLS の既定値は true (1) です。また、すべてのプロパティの既定値は NULL ("") です。既定の場合、各集約の ignoreNLS プロパティは、AGGREGATESIGNORENLS からその値を取得します。1 に設定し、レポートでは各国言語の設定を無視します。レポートで NLS を集約に適用するには、AGGREGATESIGNORENLS を false (0) に設定します。NLS 処理は、集約ごとに制御することもできます。これは ignoreNLS の値を設定することで行います。これによって、AGGREGATESIGNORENLS の値をオーバーライドします。
数値 XSLT 関数 は US ロケールのみ対応します。この理由により、各国言語の設定で 10 進数値を区切るためにコンマを使用している場合、数値浮動小数点引数を XSLT 関数で使用すると、集約は適切に表示されません。
実行時モードに DISPLAY (2) を設定してレポートを作成するときに、Caché で NLS を使用している場合、集約の計算に使用する入力値の NLS 形式は、計算を実行する COS コードで使用できる形式に変換する必要があります。集約の計算が完了したら、COS が生成した形式から、使用中の各国言語の設定と一致する形式に変換する必要があります。
NLS のサポートは、集約のベース・クラス %ZEN.Report.aggregateOpens in a new tab のメソッドにより実装されています。AGGREGATESIGNORENLS が false (0) の場合、それらのメソッドが値を前処理するか、使用中の各国言語の設定に従って結果を後処理します。このベース・クラスを拡張すると、必要になる前処理メソッドと後処理メソッドを定義できます。
レポートで NLS を使用し、preprocessValue の値または postprocessResult の値が NULL ("") の場合、これはレポート生成時に 1 に変更されます。この動作は、preprocessValue または postprocessResult のどちらかの値を 1 または 0 に明示的に設定することでオーバーライドできます。レポートが NLS を無視する場合は、これらのプロパティの値が無視され、レポートは NLS 処理を実行するメソッドを呼び出さなくなります。
AGGREGATESIGNORENLS が false (0) の場合、Zen レポートが提供するすべての標準集約と付属のカスタム集約は、NLS と透過的に連動します。カスタム集約を定義する必要があり、そのカスタム集約が各国言語の設定と連動する必要がある場合は、Zen レポートで定義されている集約をテンプレートとして使用してください。
組み込みの集約クラス
以下は、組み込みカスタム集約クラスのリストです。これらのクラスは、<aggregate> の type を CUSTOM に指定した場合に、<aggregate> の class 属性を使用して指定できます。これらの組み込みクラスを使用する代わりに、独自のクラスを作成することもできます。詳細は、“新規集約クラスの生成” を参照してください。
2 組の値どうしの相関係数を返します。分母が 0 になる場合は、空の文字列を返します。
この集約は、2 組の値の %List を引数として受け取ります。この引数を指定するには、<aggregate> の expression 属性で $LISTBUILD 関数と %val 変数を使用します。以下はその例です。
<report xmlns="http://www.intersystems.com/zen/report/definition"
name="SampleCorrelation"
sql="SELECT AmountOfChocolateConsumed,AgeAtDeath
FROM Correlation.TestData">
<aggregate type="CUSTOM" class="%ZEN.Report.Aggregate.Correlation"
name='DeathByChocolate'
expression='$LB(%val("AmountOfChocolateConsumed"),%val("AgeAtDeath"))'
fields='AmountOfChocolateConsumed,AgeAtDeath' />
</report>単純な COUNT とは対照的に、データ・セットにある個々の値の個数を返します。
処理した値の統計的共分散を返します。これは、2 つの変数が共に変化する程度を示す尺度となります。
この集約は、2 組の値の %List を引数として受け取ります。この引数を指定するには、<aggregate> の expression 属性で $LISTBUILD 関数と %val 変数を使用します。以下はその例です。
<report xmlns="http://www.intersystems.com/zen/report/definition"
name="relationship" sql="SELECT x,y FROM Test.XYData">
<aggregate type="CUSTOM" class="%ZEN.Report.Aggregate.Covariance"
name='covariance' expression='$LB(%val("x"),%val("y"))' fields='x,y' />
</report>このカスタム集約クラスは、Zen レポートに値を表示することを目的としたものではなく、他の線形回帰集約でその集約値を計算するために内部的に使用するものです。返り値は、2 つの要素を持つ %List です。これらの要素は、2 組の入力値 x と y の関係のグラフを最も良好に語義的な近似する次の線形方程式の係数 a と b を指定します。
y = (a * x) + b
入力引数は、線形方程式の x と y を指定する 2 組の値の %List です。この引数を指定するには、<aggregate> の expression 属性で $LISTBUILD 関数と %val 変数を使用します。以下はその例です。
<report xmlns="http://www.intersystems.com/zen/report/definition"
name="xydata" sql="SELECT x,y FROM Test.XYData">
<aggregate type="CUSTOM" class="%ZEN.Report.Aggregate.LinearRegression"
name='linreg' expression='$LB(%val("x"),%val("y"))' fields='x,y' />
</report>"%ZEN.Report.Aggregate.LinearRegression" の説明を参照してください。
この集約は、2 組の値 x と y の %List を受け取り、値 x と y の関係のグラフを最も良好に語義的な近似する次の線形方程式の係数 b (y 切片値) を返します。
y = (a * x) + b
決定係数を返します。この係数は、統計的モデルによって将来の結果をどの程度正確に予測できるかを示す尺度です。
"%ZEN.Report.Aggregate.LinearRegression" の説明を参照してください。
この集約は、2 組の値 x と y の %List を受け取り、値 x と y の関係のグラフを最も良好に語義的な近似する次の線形方程式の係数 a (勾配値) を返します。
y = (a * x) + b
線形回帰で処理した値の統計的分散を返します。
単純な AVG (平均) とは対照的に、数値データ・セットの中央値を返します。データ・セットの半分は中央値よりも大きな値、残り半分は中央値よりも小さな値です。
データ・セットにあるデータが奇数個の場合、中央値はそのデータ・セットのメンバとして存在します。データ・セットにあるデータが偶数個の場合、中央値はデータ・セットに属する 2 つのメンバの間の値になります。
データ・セットの統計モード値 (最も頻繁に検出されたデータ) を返します。
処理した値の標準偏差を返します。これは、分母に n ではなく n - 1 のベッセルの補正を使用した偏りのない標準偏差です。
指定された値全体の偏りのある標準偏差を返します。
処理した値の統計的分散を返します。これは、偏りのない標準偏差の 2 乗です。
指定された値全体の偏りのある統計的分散を返します。
新規集約クラスの生成
新しいタイプの集約が必要な場合、以下の手順でカスタム集約クラスを作成し、使用できます。
-
%ZEN.Report.CustomAggregateOpens in a new tab のサブクラスを作成します。
-
集約の名前を次の形式で指定します。
Parameter XMLNAME = "myaggregatename"
名前 myaggregatename は、XML ネームスペース内で一意である必要があります。
-
集約にパラメータを指定する必要がある場合、クラスのプロパティとしてこれらを定義します。
-
以下のメソッドを無効にします。
-
GetResult は、すべてのレコードを処理して集約の最終値が返されると呼び出されます。
-
ProcessValue は、レポートまたはグループ・クエリで返された個々のレコードに対して順番に呼び出されます。
これらのメソッド内では、単一値または多次元の特殊変数 %val を使用することができます。
-
-
このクラスを myPackage.myClassName として保存し、コンパイルします。
-
myaggregatename を要素名として使用して、この集約をレポートで参照できます。パラメータを属性として集約に渡すことができます。type 属性や class 属性を指定する必要はありません。
以下の例ではカスタム集約クラスを 2 つ (me.MultiDimAggregate と me.ParameterizedAggregate) 作成し、レポートで使用しています。
Class me.MultiDimAggregate Extends %ZEN.Report.CustomAggregate
{
Parameter XMLNAME = "multidim";
Property Count As %Integer [ InitialExpression = 0 ];
/// Processes each new value
Method ProcessValue(ByRef pValue As %String) As %Status
{
if $e(pValue("Name"))="A" Set ..Count=..Count+1
if $e(pValue("Home_State"))="A" Set ..Count=..Count+1
}
/// Return the count of names and states that begin with "A"
Method GetResult() As %String
{
quit ..Count
}
}
me.ParameterizedAggregate クラスでは、FieldToCount プロパティに %ZEN.Report.Datatype.string データ型を使用しています。このデータ型のプロパティの値は結果セットのフィールド名となる必要があります。このデータ型は、特別な処理をトリガする REPORTFIELD パラメータをサポートしており、FieldToCount の値を %val 特殊変数の添え字に入力します。FieldToCount で指定するフィールドの値は、%val にその添え字のデータとして渡されます。
他のプロパティに対しては、%ZEN.Datatype パッケージのデータ型、または任意のデータ型を使用します。
Class me.ParameterizedAggregate Extends %ZEN.Report.CustomAggregate
{
Parameter XMLNAME = "mycountdistinct";
Property exclude As %ZEN.Datatype.string;
/// Array of values processed
Property Values As array Of %String;
/// Running count of distinct values processed
Property Count As %Integer [ InitialExpression = 0 ];
/// The field you're counting
Property FieldToCount As %ZEN.Report.Datatype.string;
/// Processes each new value
Method ProcessValue(ByRef pValue As %String) As %Status
{
if pValue(..FieldToCount)="" quit $$$OK
if $e(pValue(..FieldToCount))=..exclude quit $$$OK
If ..Values.GetAt(pValue(..FieldToCount)) {
#; seen it already
} Else {
Do ..Values.SetAt(1,pValue(..FieldToCount))
Set ..Count=..Count+1
}
Quit $$$OK
}
/// Return the count of distinct values processsed
Method GetResult() As %String
{
Quit ..Count
}
}
<report xmlns="http://www.intersystems.com/zen/report/definition"
name="MyReport" sql="select top 20 Name,Home_Street,
Home_City,Home_State From Sample.Person order by Home_State">
<group name="State" breakOnField="Home_State">
<group name="Person">
<attribute name="Name" field="Name"/>
<attribute name="Street" field="Home_Street"/>
<attribute name="City" field="Home_City"/>
<attribute name="State" field="Home_State"/>
</group>
<aggregate name="countSomething" field="!..Field" type="CUSTOM"
class="%ZEN.Report.Aggregate.CountDistinct" />
<mycountdistinct name="mycount" exclude='#($zcvt("a","u"))#' FieldToCount="Name"/>
<multidim name="mymultidim" fields="Name,Home_State" expression="%val"/>
</group>
</report>このレポート例では集約を 3 つ使用しています。最初は組み込みカスタム集約クラスです。"組み込みの集約クラス" を参照してください。
<aggregate name="countSomething" field="!..Field" type="CUSTOM"
class="%ZEN.Report.Aggregate.CountDistinct" />2 番目は me.ParameterizedAggregate で定義されたカスタム型の集約です。exclude 属性で渡される値は Zen の式である点に注意してください。
<mycountdistinct name="mycount" exclude='#($zcvt("a","u"))#' FieldToCount="Name"/>
3 番目は me.MultiDimAggregate で定義されたカスタム型の集約です。expression 属性の値は %val である点に注意してください。この場合、%val は、参照によって ProcessValue に渡されます。 つまり、集約によって .%val を渡します。 これによって、ProcessValue メソッドは %val という多次元配列にアクセスできます。
<multidim name="mymultidim" fields="Name,Home_State" expression="%val"/>
DATASOURCE
Zen レポートで使用するデータを格納する XML ドキュメントを指定します。DATASOURCE の値は、以下のいずれかです。
-
有効な XML ドキュメントの URI。相対 URI は、現在の URI を基準にして処理されます。
-
有効な XML ドキュメントを含むファイル。このファイルは、Zen レポートの Web アプリケーション定義の [CSPファイル物理パス] で指定したディレクトリに存在している必要があります。例えば、Zen レポート・クラスの URI が以下の場合、
http://localhost:57772/csp/myNamespace/mine.MyReport.cls
DATASOURCE パラメータの構文は以下のようになり、
Parameter DATASOURCE="data.xml";
また、data.xml ファイルは、[CSPファイル物理パス] として指定したディレクトリ内に存在している必要があります。このディレクトリの既定の値は、Caché インストール・ディレクトリの下にある /csp/myNamespace です。
-
空の文字列。この場合、クラスの XData ReportDefinition ブロックの仕様を使用して、クラス独自の XML ドキュメントが生成されます。Zen レポート・クラスにある DATASOURCE 文字列および XData ReportDefinition ブロックがいずれも有効で、空ではない場合は、XData ブロックよりも DATASOURCE パラメータが優先します。
-
同じネームスペースにある別の Zen レポート・クラスで作成した XML ドキュメント。そのクラスからの XML 出力を使用する必要があることを示すには、以下のように $MODE=xml クエリ・パラメータを使用します。
Parameter DATASOURCE="MyApp.Report.cls?$MODE=xml";
DATASOURCE を識別すると、Zen レポートは EMBEDXSL または $EMBEDXSL を無視します。埋め込み XSLT をデータ・ソースと共に使用することはできません。データ・ソースに独自のルート・タグが含まれていると、レポート・プロパティの suppressRootTag が DATASOURCE で便利な場合があります。
レポート・クラスに対して現在設定されている DATASOURCE をオーバーライドするには、ブラウザから Zen レポートを起動するときに、URI で $DATASOURCE パラメータを指定します。
GenerateReport メソッドを使用して、コマンドラインからレポートを起動すると、Zen レポートは、レポートがブラウザで実行されたときと同じ場所でデータ・ソース・ファイルを探します。
コマンドライン・シーケンス中に、クラスに定義された DATASOURCE 値をオーバーライドする場合は、レポートの Datasource プロパティを目的の値に設定します。以下にコマンド・ラインの例を示します。
zn "SAMPLES"
set %request=##class(%CSP.Request).%New()
set %request.URL = "/csp/samples/datacurrent.xml"
set %request.CgiEnvs("SERVER_NAME")="127.0.0.1"
set %request.CgiEnvs("SERVER_PORT")=57777
set rpt=##class(jsl.TimeLine).%New()
set rpt.Datasource = "/csp/samples/datanew.xml"
set tSC=rpt.GenerateReport("C:\TEMP\timeline.pdf",2)
if 'tSC do $system.Status.DecomposeStatus(tSC,.Err) write !,Err(Err) ;'
write !,tSC
XML データ・ソースの挿入
このセクションでは、Zen レポートの XML データ・ソースを直接生成する XML 文を指定する手法について説明します。このセクションは、以下のトピックで構成されています。
-
クラス・メソッドからの XML 文の記述 — 任意のコーディング言語を使用します。
-
<call> — 呼び出されたメソッドによって生成され、文字列として返された XML を挿入します。注意 : <call> は、<report> でのみ使用できます。<group> では使用できません。
-
<callelement> — <call> と似ていますが、使用されているデータ・コンテキストの認識を提供します。
-
<include> — XData ブロックからリテラル XML 文を挿入します。
-
<get> — 他の Zen レポートにある XData ReportDefinition ブロックで生成した XML 文を挿入します。
クラス・メソッドからの XML 文の記述
XML 文をクラス・メソッドから任意の言語で記述し、最上位の <report> 要素で call 属性と callClass 属性を使用して、そのメソッドを Zen レポート・クラスの XData ReportDefinition ブロックから参照できます。この場合は、XML データ・ソースを生成する文を XData ReportDefinition ブロックで定義する必要はありません。代わりに、XData ReportDefinition ブロックを 1 つの <report> 要素で構成し、その要素で call 属性および (必要に応じて) callClass 属性を指定します。
XML データ・ソースを記述するクラス・メソッドは、XData ReportDefinition と同じ Zen レポート・クラス内に置くことも、他のクラスに置くこともできます。以下の例では ObjectScript を使用したメソッドを示していますが、このメソッドの言語として MultiValue または Basic を使用することもできます。
ClassMethod CreateXML() {
WRITE !,"<MyExample>"
WRITE !,"some text for a text node"
WRITE !,"</MyExample>"
}このメソッドを使用するには、XData ReportDefinition ブロックは以下の例のようになります。call 属性で特定されるメソッドが同じクラスにあると、<report> 要素では call 属性のみを指定する必要があります。以下のように、この名前のメソッドが同じクラス内で検索されます。
XData ReportDefinition
[XMLNamespace="http://www.intersystems.com/zen/report/definition"]
{
<report xmlns="http://www.intersystems.com/zen/report/definition"
name="myReport" call="CreateXML">
</report>
}
同じ Caché ネームスペースにある別のクラスに目的のメソッドが存在する場合、Zen でそのメソッドを探し出せるようにするには、call 属性のほかに callClass 属性を指定します。callClass 属性の値には、call メソッドが属するクラスの完全なパッケージとクラスの名前を指定する必要があります。指定しない場合、既定は <report> または <group> が属するクラスです。callArgument 属性は call 属性で指定されるメソッドに引数を与えます。
<report> と <group> の両方で、call 属性、callClass 属性、および callArgument 属性がサポートされています。call 属性を <report> 要素で指定すると、クラス・メソッドで記述した XML 文は、レポートのすべてのソース・データとなります。call 属性を <group> 要素で指定すると、クラス・メソッドはレポート用ソース・データの部分になり、<group> 要素が <report> に配置される場所に位置します。
<call>
<call> 要素ではストリームを返すメソッドを呼び出し、<call> 要素の出現場所でストリームをレポート定義に挿入します。ストリームは適格な XML にする必要があります。この機能によって、別のレポートの XData ReportDefinition ブロックで作成された XML をレポート定義で組み込むことができます。別々に開発したサブレポートからレポートを作成する場合や、レポートが大きすぎてコンパイルできない場合に便利です。<call> 要素は <report> の直接の子にする必要があります。呼び出されたサブレポートには <call> 要素を含めることはできません。
XData ReportDefinition ブロック内で使用される場合、<call> 要素には以下の属性があります。
| 属性 | 説明 |
|---|---|
| hasStatus |
True の場合、このメソッドは、ステータス値をメソッドへの最後のパラメータで参照によって返します。 |
| method |
ストリームを返すクラス・メソッドまたはインスタンス・メソッド。このメソッドは、Zen レポートで定義する必要があります。call 要素の出現場所でストリームがレポート定義に挿入されます。 このメソッドでは、サブレポートの XData ReportDefinition ブロックの出力を返したり、これ以外の機能を実行できます。サブレポートで使用する場合、このメソッドはサブレポートの新規インスタンスを作成し、GenerateStream を使用してストリームを返す必要があります。XData ReportDefinition ブロックから呼び出されたメソッドの場合、GenerateStream への mode 引数は必ず 0 (XML) になります (既定値)。 |
<call> 要素に関する問題を解決するには、"<call> 要素のトラブルシューティング" を参照してください。
<call> 要素を使用する例
SAMPLES ネームスペースでは、ZENApp パッケージにコード例が用意されています。Zen レポート・クラス ZENApp.MyReportMainDef.cls では、<call> 要素を XData ReportDefinition ブロック内で使用するレポートを定義します。
<report xmlns="http://www.intersystems.com/zen/report/definition"
name='myReport' runonce="true">
<call method="GetSub"/>
</report>
GetSub メソッドでは MyReport.cls の新規インスタンスを作成し、XData ReportDefinition ブロックの出力が含まれるストリームを生成します。このストリームは、MyReportMainDef.cls により生成された XML の <call> 要素が配置されている場所に配置されます。このメソッドを ReportDefinition から呼び出す際、GenerateStream への 2 番目の引数により mode が指定されます。この値は必ず XML を示す 0 となります。
Method GetSub() As %GlobalCharacterStream
{
set stream=""
set rpt=##class(ZENApp.MyReport).%New()
i $isobject(rpt)
{
set tSC=rpt.GenerateStream(.stream,0)
}
quit stream
}
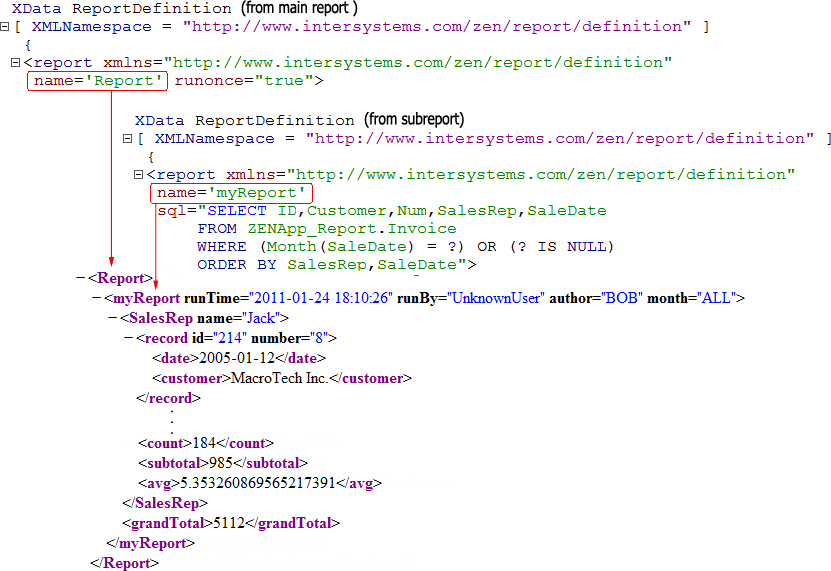
“Zen レポートのデータの収集“ の章にある “XData ReportDefinition” で、XData ReportDefinition ブロックで生成した XML の構造が説明されています。この図で示すように、生成された XML の最上位レベルの要素は report 要素の name 属性からのものです。ReportDefinition ブロックで <call> を使用して XML をサブレポートから追加すると、サブレポートの最上位レベルの要素は、レポートの最上位レベルの要素の直接の子になります。
メイン・レポートとサブレポートの名前が生成された XML にどのように表示されるかを次の図に示します。
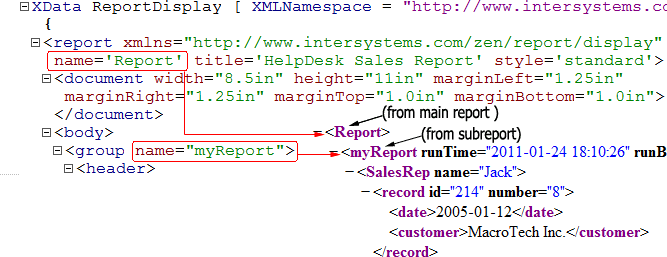
MyReportMainDef.cls の XData ReportDisplay ブロックでレポートのフォーマット処理が行われます。MyReport.cls により生成される詳細レポートではなく、概要が生成されます。<report> 要素の name 属性は、ReportDisplay ブロックで使用される名前と一致している必要があります。また、<group> 要素を ReportDisplay ブロックに <body> 要素の直接の子として追加する必要もあります。この <group> 要素の name 属性は、サブレポートの <report> 要素の name 属性と一致している必要があります。
<report> 要素の name 属性がメイン・レポートの XML 要素を参照する様子と、<group> の name 属性がサブレポートの XML 要素を参照する様子を次の図に示します。“group、field、および XPath 式” のセクションで説明されているとおり、ReportDisplay ブロックでは、Report/myReport 構造のコンテキストにおいて後続の XPath 参照を解決します。
パラメータを含む <call> 要素の使用法
<call> 要素を使用するときには、ストリームを返すメソッドにパラメータを渡すこともできます。このメカニズムは、<report> または <group> の sql プロパティにパラメータを使用する場合とよく似ています。パラメータは、配列の参照で渡されます。この配列は、正の整数 1、2、3 ... n でインデックスが作成されています。n はパラメータの数です。例えば、次に示すレポートは、メソッド MyMethod にパラメータを渡しています。パラメータの値は、レポートの結果セットのフィールド SalesRep により指定されます。
<report xmlns="http://www.intersystems.com/zen/report/definition"
name='Report' sql="SELECT SalesRep FROM ZENApp_Report.Invoice ">
<call method="MyMethod">
<parameter field="SalesRep"/>
</call>
</report>パラメータ・フィールドまたは式を使用するときに、フィールドの設定を必要としているものであると、使用されるフィールドは、call が入れ子にされた場所に応じて、周囲のグループまたはレポートの最後の行になります。これは、見逃されやすい部分であり、予期しない結果の原因になることがあります。
メソッド MyMethod は、そのメソッドが生成する XML にパラメータの値 (この場合は SalesRep の名前) を追加します。
Method MyMethod(ByRef pParms) As %GlobalCharacterStream
{
s stream=##class(%GlobalCharacterStream).%New()
do stream.Write("<A12>")
do stream.Write(pParms(1))
do stream.Write("</A12>")
quit stream
}プロパティ hasStatus が True の場合、このメソッドでステータスも返送できます。ステータスは、最後に戻されます。
<report xmlns="http://www.intersystems.com/zen/report/definition"
name='Report' sql="SELECT SalesRep FROM ZENApp_Report.Invoice ">
<call method="MyMethod" hasStatus="true">
<parameter field="SalesRep"/>
</call>
</report>Method MyMethod(ByRef pParms, Output pStatus) As %GlobalCharacterStream
{
s stream=##class(%GlobalCharacterStream).%New()
do stream.Write("<A12>")
do stream.Write(pParms(1))
do stream.Write("</A12>")
Set pStatus=$$$ERROR(9999,"Deliberate Error")
quit stream
}<callelement>
<element> と同様に、<callelement> では、filter、expression、field、および fields の属性を取ることができます。使用されているデータ・コンテキストを認識して、呼び出す SQL でレコードごとに繰り返します。<element> と異なり、メソッドを呼び出して、呼び出されたメソッドに expression の値や field の値 (式がない場合) を渡します。<call> 要素と同様に、<callelement> では、メソッドの出力を生成された XML のその要素の出現場所に配置します。
<callelement> を使用する場合、出力されストリームに正しいエスケープ値が含まれていることを確認する必要があります。データ値が <callelement> のメソッドに渡される前に、escape 属性によって選択されたエスケープがデータ値に適用されるようにする必要があります。したがって、COS 式または COS 値を入力している場合、escape="passthru" の設定が必要となることがあります。ケースバイケースで XML エスケープが必要かどうかを決定する必要があります。
<callelement> には以下の属性があります。
<callelement> を使用し、データに依存するように異なる Zen レポートからデータを使用してレポートを作成できます。 例えば、データ・フィールドの内容を調べてから、その月によって異なるサブレポートにレコードを送信できます。これによって、メイン・レポートで月ごとに異なる XML が生成されます。
| 属性 | 説明 |
|---|---|
| escape |
ブラウザでは通常、表示されるページから余分だと見なされた空白が削除されます。そのため、出力で空白文字を保持する場合は、escape 属性を使用する必要があります。エスケープ・スタイルは、<callelement> に指定された method にデータ値が渡される前に、データ値に適用されることに注意してください。 escape には以下の値を指定できます。
|
| expression |
%val としてこの項目の値に適用したり、この項目の任意の値を渡すことができる ObjectScript 式 (オプション)。存在する場合、この値は呼び出されたメソッドに渡されます。 “値ノードの属性” も参照してください。 |
| field | この項目の値を提供するこのレポートのベース・クエリにおけるフィールド (列) の名前。この先頭が ! (感嘆符) の場合、これはフィールド名として評価される式になります。expression が存在しない場合、この値は呼び出されたメソッドに渡されます。
“値ノードの属性” も参照してください。 |
| fields | この項目の値を提供するこのレポートのベース・クエリにおけるフィールド (列) の名前。
“値ノードの属性” も参照してください。 |
| filter |
0 (False) と評価される場合とされない場合のある ObjectScript 式。filter 式の評価結果が 0 の場合、この <callelement> の処理はスキップされます。その結果、この <callelement> からの出力はレポートの XML データ内に表示されません。 filter 式では、%val 変数を使用して結果セット・クエリのフィールドの値を参照できます。以下が使用できます。
詳細は、“%val 変数” を参照してください。 ObjectScript の一般的な知識は、これらの式の構成方法を知るうえで役立ちます。“%val 変数” の ObjectScript に関するヒントと共に、"Caché ObjectScript の使用法" の、特に “演算子と式” の章の “文字列関係演算子” を参照してください。 |
| method | XML ストリームを返すメソッドの名前。<callelement> 要素の出現場所でストリームが生成 XML に挿入されます。 |
メソッドの出力は適格な XML にする必要があります。メソッドではフィールドや式からの情報で Zen レポートを呼び出すことできますが、その必要はありません。渡されたデータを変更して、適格な XML を生成できます。
次の例では、Cinema データベースを SAMPLES ネームスペースで使用して、<callelement> を示しています。ReportDefinition ブロックでは <callelement> を使用して、メソッドを映画館ごとに 1 回呼び出しています。
XData ReportDefinition
[ XMLNamespace = "http://www.intersystems.com/zen/report/definition" ]
{
<report
xmlns="http://www.intersystems.com/zen/report/definition"
name="FromTheater"
sql="Select ID, TheaterName from Cinema.Theater">
<parameter expression='..ID'/>
<group name="Theater">
<element name="ID" field="ID" />
<element name="TheaterName" field="TheaterName"/>
<callelement method="MyMethod" field="ID"/>
</group>
</report>
}
MyMethod メソッドでは、ZENrCall.ShowByTime サブレポートを使用しています。
Method MyMethod(Theater) As %GlobalCharacterStream
{
s stream=##class(%GlobalCharacterStream).%New()
s rpt=##class(ZENrCall.ShowByTime).%New()
s rpt.Theater=Theater
s tSC=rpt.GenerateStream(.stream,0)
i $$$ISERR(tSC) set stream=""
quit stream
}メソッドではサブレポートの Theater プロパティを現在の映画館に設定しています。サブレポートではその映画館で上映される映画とその上映時間を検索します。
XData ReportDefinition
[ XMLNamespace = "http://www.intersystems.com/zen/report/definition" ]
{
<report
xmlns="http://www.intersystems.com/zen/report/definition"
name="FromShow"
sql="Select Theater, StartTime, Film from Cinema.Show
where (Theater = ?) order by StartTime"
>
<parameter expression='..Theater'/>
<group name="Show">
<element name="StartTime" field="StartTime" />
<element name="Film" field="Film" />
</group>
</report>
}
ReportDisplay ブロックでは生成 XML をレポートにフォーマット処理します。レポートでは映画館ごとに上映映画を上映時間別に並べ替えてリストします。
<report xmlns="http://www.intersystems.com/zen/report/display"
name="FromTheater">
<body>
<group name="Theater" pagebreak="true">
<item field="TheaterName" width="2in"></item>
<group name="FromShow">
<table orient="col" group="Show" class='table2'>
<item field="StartTime">
<caption value="StartTime" width="1in" />
</item>
<item field="Film">
<caption value="Film" width="3.5in" />
</item>
</table>
</group>
</group>
</body>
</report>
<include>
目的の Zen レポート・クラスまたは他のクラスの XData ブロックに一連の XML 文を記述し、その XData ブロックを XData ReportDefinition から <include> 要素を使用して参照できます。それにより、レポートで使用するために生成した XML データ・ソースに、この XData ブロックの内容が挿入されます。含まれているデータに独自のルート・タグがあると、レポート・プロパティの suppressRootTag が <include> で便利な場合があります。
<include> には以下の属性があります。
| 属性 | 説明 |
|---|---|
| class | 挿入する XData ブロックが存在するクラスのパッケージとクラスの名前。指定しない場合、既定は <include> 要素が属するクラスです。 |
| xdata | XData ブロックの名前。この名前では大文字と小文字が区別されます。 |
以下の XData ブロックを My.Class.cls というクラスに追加するとします。
XData FloodInfo {
<Flood Type="Total">
<Central>38</Central>
<East>609</East>
<Midwest>210</Midwest>
<Northeast>70</Northeast>
<Total>927</Total>
</Flood>
}
この場合、以下のように Your.Class.cls というクラスの XData ReportDefinition ブロックに <include> 文を配置できます。
XData ReportDefinition
[ XMLNamespace = "http://www.intersystems.com/zen/report/definition" ]
{
<report xmlns="http://www.intersystems.com/zen/report/definition"
name="root" sql="SELECT TOP 1 ID FROM InsurancePolicies">
<group name="InsurancePolicies"
sql="SELECT Location,InsuredValue
FROM InsurancePolicies
ORDER BY Location">
<group name="Location" breakOnField="Location" >
<attribute name="Location1" field="Location"/>
<aggregate name="TotalLocation" field="InsuredValue" type="SUM" />
</group>
<aggregate name="Total" field="insuredvalue"
type="SUM" format="$fnumber(%val,",")"/>
<include class="My.Class" xdata="FloodInfo"/>
</group>
</report>
}
<macrodef>
Zen レポート・クラスまたは他のクラスの XData ブロックに一連の ReportDefinition ビルディング・ブロックを配置し、<macrodef> 要素を使用してその XData ブロックを XData ReportDefinition から参照できます。また、Parameter SUPPORTMACROS=1; も設定する必要があります。それにより、レポートの ReportDefinition に XData ブロックの内容が挿入されます。<macrodef> により挿入された XML は、ReportDefinition で直接入力されているものと解釈されます。
<macrodef> には以下の属性があります。
| 属性 | 説明 |
|---|---|
| class | 挿入する XData ブロックが存在するクラスのパッケージとクラスの名前。この属性は必須です。 |
| xdata | XData ブロックの名前。この名前では大文字と小文字が区別されます。 |
以下の方法で SAMPLES データベースの ZENApp.MyReportOpens in a new tab レポートを変更します。Record と呼ばれる XData ブロックを作成します。
XData Record {
<group name="record"
<attribute name='id' field='ID' />
<attribute name='number' field='Num' />
<element name='date' field='SaleDate' />
<element name='customer' field='Customer' />
</group
}
そして以下のように、ZENApp.MyReportOpens in a new tab の XData ReportDefinition ブロックに <macrodef> 文を配置します。
XData ReportDefinition
[ XMLNamespace = "http://www.intersystems.com/zen/report/definition" ]
{
<report
xmlns="http://www.intersystems.com/zen/report/definition"
name='myReport'
sql="SELECT ID,Customer,Num,SalesRep,SaleDate
FROM ZENApp_Report.Invoice
WHERE (Month(SaleDate) = ?) OR (? IS NULL)
ORDER BY SalesRep,SaleDate"
<parameter expression='..Month'/>
<parameter expression='..Month'/>
<attribute name='runTime' expression='$ZDT($H,3)' />
<attribute name='runBy' expression='$UserName' />
<attribute name='author' expression='..ReportAuthor' />
<aggregate name='grandTotal' type="SUM" field='Num' />
<attribute name='month' expression='..GetMonth()' />
<group name='SalesRep' breakOnField='SalesRep'
<attribute name='name' field='SalesRep' />
<aggregate name='count' type="COUNT" field='Num' />
<aggregate name='subtotal' type="SUM" field='Num' />
<aggregate name='avg' type="AVG" field='Num' />
<macrodef class="ZENApp.MyReportMACRO" xdata="Record" />
</group>
</report>
}
変更したレポートによる XML 出力は、元のレポートによる XML 出力を正確に複製します。
<get>
あるレポートから生成した XML を、別のレポートで生成したグループに挿入できると便利です。それにより、さまざまな Zen レポートの結果を組み合わせて、1 つのマスタ・レポートを作成できます。その結果、各レポートで担当する内容を絞り込んで、それを確実に実行することで、柔軟性や簡潔性が得られます。他の Zen レポート・クラスの XData ReportDefinition ブロックで生成された XML 文を参照するには、<get> 要素を使用します。
<get> には以下の属性があります。
| 属性 | 説明 |
|---|---|
| host | ホスト名。通常は Caché インストールまたは localhost のホスト名です。 |
| port | ポート番号。通常は、Caché インストールの Web サーバのポート番号です。 |
| url | host、port、および url の各属性を組み合わせて使用することで、レポートの XML データ・ソースに挿入する XML 文のブロックを取得する場所を特定します。url 文字列には、host と port の値で始まる URI 文字列の残りの部分を指定します。 |
host、port、および url の組み合わせによって、URI に解決できる任意の文字列を生成できます。この組み合わせの目的は、有効な XML テキストのソースを特定することです。これはファイルの場合もありますが、普通は url で Zen レポート・クラスのアプリケーション・パス名、パッケージ名、およびクラス名を指定してその URI を構成します。これは、Zen でこのクラスを XML 出力モードで処理することにより、XML 文を生成できるようにするという考え方です。この場合、url の値では以下のクエリ・パラメータも指定する必要があります。
-
url の値で Zen レポート・クラスを特定する場合は、$MODE=xml を指定する必要があります。$MODE=xml は、目的の出力形式が XML であることを示します。
-
$STRIPPI は “処理命令の削除“ を示し、値 1 は True を示します。$STRIPPI=1 の指定は、url の値で特定した XML ソースが通常の <?xml version="1.0"?> 処理命令で始まる場合に適しています。$MODE=xml を指定して Zen レポート・クラスから XML 出力を生成すると、このような処理命令が記述されています。
<get> を使用して XML ブロックを他の XML ブロックに挿入する場合は、<?xml version="1.0"?> 命令を削除することが合理的です。このようにしないと、<get> 要素で指定したテキスト代入を実行した結果、挿入先ブロックの中に処理命令が挿入されることになります。
以下の <get> 文の例では、ある Zen レポート・クラスを特定しています。Your.Class.cls の XData ReportDefinition ブロックにこの <get> 文があるとします。この <get> 文では、My.Class.cls で生成した XML 文の全体を次のように取得し、Your.Class.cls の XML データ・ソースに挿入します。
<get host="localhost"
port="57777"
url="/csp/ours/My.Class.cls?$MODE=xml&$STRIPPI=1"/>
クラス・クエリからの Zen レポートの生成
XML データ・ソースを定義した XData ReportDefinition ブロックを含む、完全な Zen レポート・クラスを生成できます。そのためには、Zen レポート・ジェネレータに対して、定義済みのクエリを持つ通常の ObjectScript クラスから Zen レポート・クラスを生成するように要求します。得られる Zen レポートには既定のレイアウトとスタイルが適用されていますが、生成後の Zen レポート・クラスを編集してそれらを調整できます。
例えば、SAMPLES ネームスペースにある Sample.PersonOpens in a new tab クラスを取り上げます。Sample.PersonOpens in a new tab では、次のような ByName というクエリを定義します。
Query ByName(name As %String = "") As
%SQLQuery(CONTAINID = 1, SELECTMODE = "RUNTIME")
[ SqlName = SP_Sample_By_Name, SqlProc ]
{
SELECT ID, Name, DOB, SSN
FROM Sample.Person
WHERE (Name %STARTSWITH :name)
ORDER BY Name
}以下の一連のコマンドを発行することによって、Zen レポート・ジェネレータを呼び出し、Sample.PersonOpens in a new tab から Zen レポート・クラスを生成できます。以下の例の SET 文は通常すべて 1 行で表現されます。ここでは、スペースの関係で 4 行で表現しています。
ZN "SAMPLES"
Set Status=
##class(%ZEN.Report.reportGenerator).Generate("myOwn.GeneratedReport",
"Persons","Sample.Person","ByName",1,
"GroupOption","SortOption","SortBy","SSN")
If 'Status Do $system.Status.DecomposeStatus(Status,.Err) Write !,Err(Err) ;'
Write !,"Status="_Status
Killまた、GenerateForSQL() メソッドを使用して、クエリを含むクラスの名前の代わりにクエリを指定することにより、クエリから Zen レポートを生成できます。
Generate() メソッドおよび GenerateForSQL() メソッドには、以下の引数があります。
| 引数 | 目的 | 例で示されている値 |
|---|---|---|
| className | 生成する Zen レポート・クラスのパッケージとクラスの名前。 | myOwn.GeneratedReport |
| reportName | Zen レポートの名前。これは、レポートに生成する XML データのルート要素の名前になります。 | Persons |
| queryClass | Zen レポート・クラスの生成元とする通常の ObjectScript クラスの名前。Generate でのみ使用します。 | Sample.Person |
| sql | レポート生成で使用される SQL クエリを指定する文字列。GenerateForSQL でのみ使用します。 | Sample.Person |
| queryName | queryClass で定義しているクエリの名前。 | ByName |
| sortandgroup | 1 (True) の場合、並べ替えとグループ化のコードが生成され、次に続く 4 つの引数が使用されます。0 (False) の場合、そのコードは生成されないので、次の 4 つの引数を省略できます。並べ替えとグループ化を行わない方が、生成した Zen レポートははるかにシンプルになります。 | 1 |
| GroupOption | グループ化を指定するオプションの名前。 | GroupOption |
| SortOption | 詳細レコードの並べ替えを指定するオプションの名前。 | SortOption |
| SortBy | SortOption に関連する内部オプションの名前。クエリに SortBy という名前の列がない限り、値を SortBy にすることをお勧めします。 | SortBy |
| UniqueId | クエリにある列の名前。Zen レポート・ジェネレータでは、“COUNT DISTINCT” で一意の値の数をカウントするために、この列の値を使用して 2 つの行が異なるかどうかを判定します。この列で 2 つのレコードの値が同じ場合、それらは同じであると見なされて個別にはカウントされません。 | SSN — 個人の社会保障番号 |
ReportDefinition XML の再構成
状況によっては、ReportDefinition によって渡される XML を取得し、XSLT 経由で変換するほうが簡単な場合があります。結果として得られる XML は、ReportDisplay ブロックの入力 XML になり、レポートが生成されます。PDF、HTML、tiff、excel、xlsx、および displayxlsx の出力モードはすべて、この種の XML 変換をサポートしています。XSLT スタイル・シートは、isc:evaluate を呼び出すことができます。以下の方法で、XML 変換を実行する XSLT スタイル・シートを定義できます。
-
xmlstylesheet を設定します。これは、%ZEN.Report.reportPageOpens in a new tab のプロパティです。 このプロパティにより、スタイル・シートの内容が格納されるストリームを指定します。
-
xmlstylesheet が null の場合、Zen レポートでは、getxmlstylesheet プロパティで指定されるメソッドを検索します。このメソッドではスタイル・シートの内容をストリームとして返します。ZENURL が $XMLSTYLESHEETARG である xmlstylesheetarg を定義でき、この引数が getxmlstylesheet メソッドに渡されます。
-
getxmlstylesheet が null の場合、Zen レポートでは XMLSTYLESHEET パラメータを検索します。その内容が XML スタイル・シートである場所を指す絶対 URI または相対 URI をこのパラメータで指定します。相対 URI を指定する場合、Caché インストール先ディレクトリの csp/namespace にファイルを配置する必要があります。ファイルは、.xsl ファイルまたは .csp ファイルにできます。
ReportDisplay ブロックでのデータ収集
Zen レポートのグラフおよび Zen レポートのテーブルは、ReportDisplay ブロックでのデータ収集の代替手段となります。以下のセクションでは、これらの代替手段について説明します。