[ピボット分析] ウィンドウの使用
ここでは、[ピボット分析] ウィンドウの使用方法について説明します。このウィンドウには、ピボット・テーブル・ウィジェットで分析ボタン  を使用してアクセスできます。
を使用してアクセスできます。
"BI サンプルのアクセス方法" も参照してください。
[ピボット分析] ウィンドウの使用
システムには、各種の専門的な分析に使用できる分析ウィンドウが用意されています。どの場合でも、まず 1 つ以上のセルを選択すると、分析ではそれらのセルに関連付けられた最下位レベルのデータが考慮されます。このウィンドウにアクセスする手順は以下のとおりです。
-
1 つまたは複数の行のデータ・セルを選択します。
複数のセルを選択するには、Shift キーを押しながらセルを選択します。
行全体を選択するには、左側の行ラベルを選択します。列全体を選択するには、列ヘッダを選択します。
分析オプションは、合計行または合計列のセルには使用できません。
-
分析ボタン
を選択します。ウィジェットの構成方法に応じて、分析オプションの選択肢が表示されるか、選択肢なしでオプションの 1 つが表示されます。
-
(該当する場合) [分析オプション] で、以下のいずれかを選択します。
または、[iKnow プラグイン] を選択し、以下のいずれかを選択します。
[iKnow プラグイン] オプションは、キューブに NLP メジャーが含まれる場合にのみ適用可能です。
以下のセクションで詳細を説明します。
このウィンドウは、アナライザでも使用できます。
クラスタ分析
[ピボット分析] ウィンドウの背景情報は、"[ピボット分析] ウィンドウの使用" を参照してください。
クラスタ分析またはクラスタリングは、サブセット (クラスタと呼ばれる) への一連の観測値の割り当てであるため、同じクラスタ内の観測値はある意味で似ています。クラスタリングは、教師なし学習方法の 1 つであり、機械学習、データ・マイニング、パターン認識、画像解析、情報検索、生命情報科学など、多くの分野で使用される統計データ分析の一般的な手法です。
クラスタ分析では、ページの上部領域は以下のようになります。
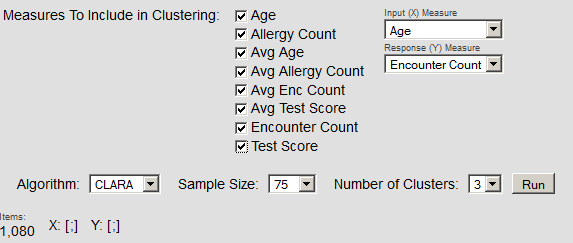
このページを使用する手順は以下のとおりです。
-
ページの上部領域で、分析の詳細を指定します。
詳細はこのドキュメントの対象範囲ではありません。読者がクラスタ分析に精通していることを前提にしています。
-
[実行] を選択します。
ページの下部領域に結果が表示されます。以下はその例です。
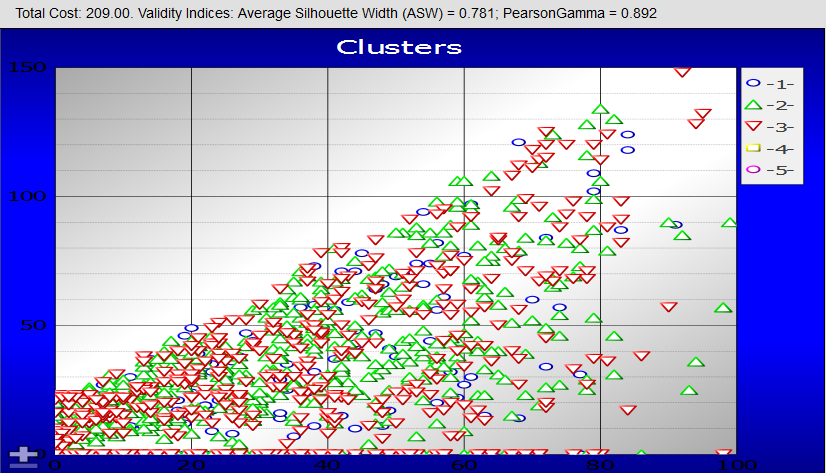
クラスタ分析の一般的な情報については、Wikipedia の当該ページ (https://en.wikipedia.org/wiki/Cluster_analysisOpens in a new tab) を参照してください。また、このトピックに関する多くの書籍も入手可能です。
分布分析
[ピボット分析] ウィンドウの背景情報は、"[ピボット分析] ウィンドウの使用" を参照してください。
分布分析では、一連のレコード全体で、特定の測定におけるさまざまな値の出現数が示されます。
分布分析の場合は、以下のように表示されます。
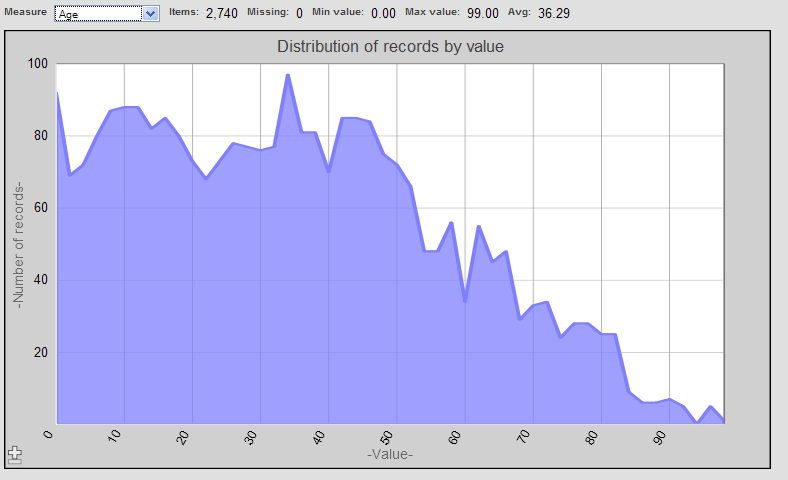
このページを使用するには、メジャーを選択します (この例では、Age)。
横軸には、選択されているセルにおけるこのメジャーの値がすべて表示されます。縦軸には、メジャー値ごとに、値のあるソース・レコード (選択されているセル) の数が表示されます。
このページの上部には、以下の値が表示されます。
-
[アイテム] — ピボット・テーブルの選択されているセルのソース・レコードの数。
-
[存在しません] — このメジャーで値がないソース・レコード (選択されているセル) の数。
-
[最小値] — これらのソース・レコードにおけるこのメジャーの最小値。
-
[最大値] — これらのソース・レコードにおけるこのメジャーの最大値。
-
[平均] — これらの値の平均。
回帰分析
[ピボット分析] ウィンドウの背景情報は、"[ピボット分析] ウィンドウの使用" を参照してください。
回帰分析では、独立変数と従属変数間のリレーションシップの決定を試みます (InterSystems IRIS Business Intelligence 回帰分析は 1 つの独立変数のみを考慮します)。
回帰分析の場合は、以下のように表示されます。
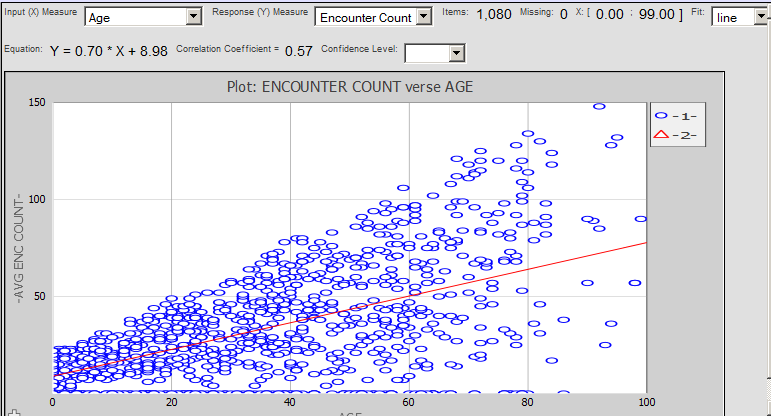
このページを使用するには、以下の詳細を指定します。
-
[入力 (X) メジャー] — 独立変数として扱うメジャーを選択します (この例では、Age など)。これらの値は、横軸で表示されます。
-
[応答 (Y) メジャー] — 最初のメジャーに依存すると思われるメジャーを選択します (この例では Encounter Count など)。これらの値は、縦軸で表示されます。
この操作によって、選択されているセルに関連付けられた最下位レベルのレコードごとのデータ・ポイントがこのページに表示されます。
-
[フィット] — 実行するフィッティングのタイプを選択します。
-
[線形] — 線形回帰を実行します。
-
[指数] — 指数回帰を実行します。
-
[対数] — 対数回帰を実行します。
-
[べき乗] — べき乗回帰を実行します。
-
-
[信頼水準] — 必要に応じて、決定される値のエラー・バーの計算時に使用する信頼水準を選択します。
いずれの場合も、システムによって、Y を X の関数として予測する方程式の詳細が決定され、予測された X-Y 曲線がこのページ上にプロットされます。グラフの上の領域には、フィットの詳細が表示されます。例えば、線形回帰の場合は以下のように表示されます。

また、別の例として、指数回帰の場合は以下のような詳細がこのページに表示されます。

回帰分析の一般的な情報については、Wikipedia の当該ページ (https://en.wikipedia.org/wiki/Regression_analysisOpens in a new tab) を参照してください。また、このトピックに関する多くの書籍も入手可能です。
Text Analytics コンテンツ分析
[ピボット分析] ウィンドウの背景情報は、"[ピボット分析] ウィンドウの使用" を参照してください。
iKnow コンテンツ分析オプションでは、最も一般的な、および最も一般的でない、構造化されていないテキスト値に関する情報を表示します。この分析オプションは、キューブに NLP メジャーが含まれる場合にのみ適用可能です。
コンテンツ分析の場合は、以下のように表示されます。
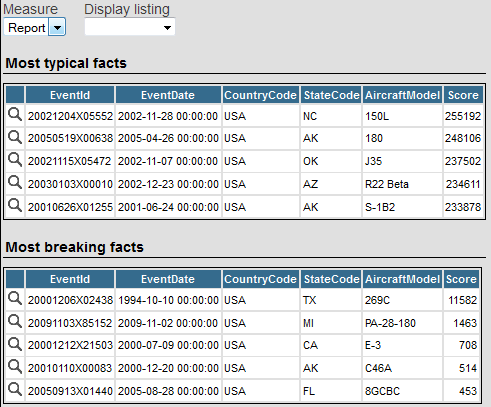
[最も一般的なファクト] セクションには、Analytics エンジンの判断に基づいて、最も一般的なコンテンツを持つレコードがリストされます。[最も例外的なファクト] セクションには、最も例外的なコンテンツを持つレコードがリストされます。例外的なコンテンツとは、そのソースの最も優位性の高いエンティティがソース・グループの最も優位性の高い要素に最も類似していないコンテンツです。詳細は、"InterSystems IRIS 自然言語処理 (NLP) の使用法" の "優位性と近似" を参照してください。
各テーブルにはレコードがリストされ、選択した詳細リストにリストされているフィールドが表示されます。
このページでは、次の操作を実行できます。
-
指定されたレコードの構造化されていないテキスト全体を表示します。そのためには、そのレコードに表示される虫眼鏡のアイコンを選択します。
-
別の NLP メジャーを選択して分析します。そのためには、[メジャー] の項目を選択します。
NLP メジャーは、他の種類のメジャーと異なっており、他のメジャーと同じ方法で使用することはできません。自由形式のテキスト・レポートなど、構造化されていないテキストが含まれるソース値に基づいています。ここでの分析対象として NLP メジャーを選択した場合、それらのソース値に対する Analytics エンジンの実行結果を検証することになります。
-
別の詳細リストを選択して使用します。そのためには、[リストを表示] の項目を選択します。
ShortListing という名前のリスト (定義されている場合) またはサブジェクト領域の既定のリストが最初に表示されます。
この例では、Aviation Events のサンプルを使用しています。
Text Analytics エンティティ分析
[ピボット分析] ウィンドウの背景情報は、"[ピボット分析] ウィンドウの使用" を参照してください。
iKnow エンティティ分析オプションでは、構造化されていないテキスト値のエンティティに関する情報を表示します。この分析オプションは、キューブに NLP メジャーが含まれる場合にのみ適用可能です。
エンティティ分析の場合は、以下のように表示されます。
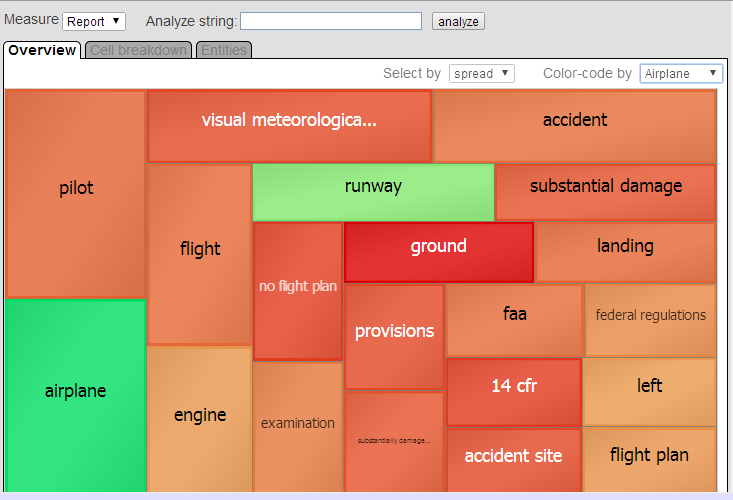
このページには 3 つのタブがあり、分析ボタン を選択する前に選択したピボット・テーブルのセルに関連付けられているレコードの情報が表示されます。これらのタブは以下のように連携して機能します。
-
[概要] タブには、それらのレコードの中から最も一般的なエンティティ 20 件の情報が表示されます。[選択基準] オプションを使用すると、これらのエンティティをシステムが選択する方法を制御できます。詳細は、最初のサブセクションを参照してください。
グラフの中の長方形を選択するとさらに詳細が表示されます。次の箇条書き項目を参照してください。
-
[セル詳細] タブには、[概要] タブで選択した長方形に対して、そのエンティティが、元のピボット・テーブルのセルの中でどのように分布しているかが表示されます。2 番目のサブセクションを参照してください。
グラフの中の棒を選択するとさらに詳細が表示されます。次の箇条書き項目を参照してください。
-
[エンティティ] タブには、[セル詳細] タブで選択した棒に対して関連するエンティティが表示されます。3 番目のサブセクションを参照してください。
この例では、BI サンプルの Aviation Events キューブ・デモを使用しています。
[概要] タブ
[概要] タブには、分析ボタン を選択する前に選択したピボット・テーブルのセルに関連付けられているレコードの中から、上位エンティティに関する情報が表示されます。このタブのグラフには、選択したメトリックに応じて、上位 20 件のエンティティごとに 1 つの四角形が表示されます。
上位エンティティの選択
システムでの上位エンティティの選択方法を決定するには、[選択基準] ドロップダウン・リストからメトリックを選択します。このオプションは以下のとおりです。
-
既定の [分散] は、その分散 (エンティティが出現するファクトの合計数) を基準に上位エンティティをリストします。
-
[BM25] は、頻度の計算アルゴリズムを使用して、計算された BM25 スコアを基準に上位エンティティを降順でリストします。Okapi BM25 の基準をベースとしたアルゴリズムを使用してこのスコアは計算され、文書の長さを考慮しながらエンティティの TF (Term Frequency : 単語の出現頻度) とその IDF (Inverse Document Frequency : 逆文書頻度) を組み合わせます。
-
[TFIDF] は、頻度の計算アルゴリズムを使用して、計算された TFIDF スコアを基準に上位エンティティを降順でリストします。エンティティの用語頻度 (TF :Term Frequency) を逆文書頻度 (IDF :Inverse Document Frequency) と組み合わせることで、このスコアを計算します。用語頻度では、単一ソース内でのエンティティの出現頻度をカウントします。IDF はソースのコレクションに出現するエンティティの回数をカウントし、この全体的な頻度によって TF を小さくします。したがって、少ないパーセンテージのソースにおいて複数回出現するエンティティは、TFIDF スコアが高くなります。大きいパーセンテージのソースにおいて複数回出現するエンティティは、TFIDF スコアが低くなります。
[BM25] および [TFIDF] オプションでは計算が集中するため、完了に時間がかかることがあります。
色分け
このグラフ内の色は、対象エンティティの Naive Bayes の確率に基づき、指定されたピボット・テーブルのセルに対して、それぞれのエンティティが指標としてどの程度活用されているかを示します。これは、以下のように行われます。
-
ピボット・テーブルで最初に選択したセルが 1 つだけの場合、グラフの色は、そのピボット・テーブルのセルの指標として、それぞれのエンティティが他のすべてのレコードと比較してどの程度活用されているかを示します。
-
ピボット・テーブルで最初に選択したセルが複数ある場合は、グラフに [色分け基準] ドロップダウン・リストが表示され、[すべて] オプションを含めて、ピボット・テーブルのセルの名前がリストされます。
この場合、グラフの色は、[色分け基準] ドロップダウン・リストに現在表示されているピボット・テーブルのセルの指標として、それぞれのエンティティが最初に選択した他のすべてのセルのレコードと比較してどの程度活用されているかを示します。
比較基準に別のピボット・テーブルのセルを使用するには、[色分け基準] ドロップダウン・リストからオプションを選択します。以下はその例です。

[すべて] オプションは、最初に選択したすべてのセルを 1 つのグループとして処理します。
緑色は一般に有効な指標を示し、赤色は無効な指標を示します。濃い緑色はその用語が非常に有効な指標であることを示し、薄い緑色は有効な指標であることを示します。一方、薄い赤色は無効な指標であることを示し、濃い赤色は非常に無効な指標であることを示します。すべてのソースに共通しているために無効な指標となるエンティティもあり、そのためソースのカテゴリを区別できない場合があることに注意してください。
例えば、飛行機の種類を行に表示するピボット・テーブルを使用するとします。分析の最初の手順として、ピボット・テーブルのセル [飛行機] と [ヘリコプター] を選択します。[飛行機] で色分けすると、グラフは次のようになります。

エンティティ [飛行機] および [滑走路] がピボット・テーブルのセル [飛行機] の有効な指標であることに注目してください。他のエンティティ (特に [地面]) は無効な指標です。
一方、[ヘリコプター] で色分けするとグラフは次のようになります。
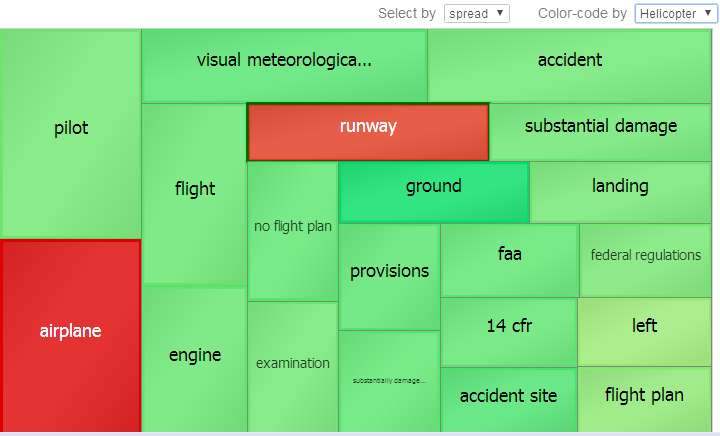
ここでは、エンティティ [飛行機] および [滑走路] がピボット・テーブルのセル [ヘリコプター] の無効な指標であることが示されています。他のエンティティ (特に [地面]) は有効な指標です。
その他のオプション
[概要] タブでは、次の操作も実行できます。
-
別の NLP メジャーを選択して分析します。そのためには、[メジャー] の項目を選択します。
NLP メジャーは、他の種類のメジャーと異なっており、他のメジャーと同じ方法で使用することはできません。自由形式のテキスト・レポートなど、構造化されていないテキストが含まれるソース値に基づいています。ここでの分析対象として NLP メジャーを選択した場合、それらのソース値に対する Analytics エンジンの実行結果を検証することになります。
-
分析する他の文字列を指定します。そのためには、[文字列の分析] に文字列を入力し、[分析] をクリックします。その文字列の追加情報が追加されます。
-
グラフ内の長方形を選択して、対応するエンティティの詳細を表示します。次のセクションを参照してください。
[セル詳細] タブ
[セル詳細] タブは、元のピボット・テーブルで複数のセルを選択している場合のみ有用です。
このタブには、元のピボット・テーブルのセルの中でエンティティがどのように分布しているかが表示されます。[概要] タブで長方形を選択すると、[セル詳細] タブが表示され、該当するエンティティの情報が表示されます。
[セル詳細] タブは以下のようになります。
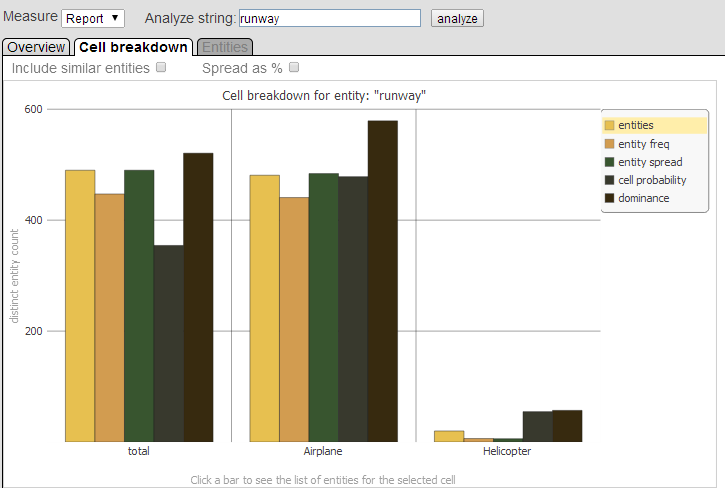
このタブには、分析ボタンを選択する前に選択したピボット・テーブルのセルの中で指定されたエンティティがどのように分布しているかが表示されます。セルごとに、以下のデータ系列について示す 5 つの色分けされた棒がグラフに表示されます。
-
[エンティティ] — 指定されたピボット・テーブルのセルに関連付けられているレコードの中で、類似するエンティティの個別の数を示します。これには、指定されたエンティティに類似するすべてのエンティティの数が含まれます。
-
[エンティティの頻度] — エンティティの頻度、つまり指定されたピボット・テーブルのセルに関連付けられているレコードの中で、指定されたエンティティが出現する回数を示します。
[類似するエンティティを含む] を選択すると、類似するエンティティもこの計算に含まれます。
-
[エンティティの分散] — エンティティの分散、つまり指定されたピボット・テーブルのセルについて、指定されたエンティティが出現するレコードの総数を示します。
[類似するエンティティを含む] を選択すると、類似するエンティティもこの計算に含まれます。
-
[セルの確率] — 対象エンティティの Naive Bayes の確率に基づき、選択されたピボット・テーブルのセルに対して、指定されたエンティティが指標としてどの程度活用されているかを示します。
-
[優位性] — これらのレコードの中で、指定されたエンティティがどの程度優位であるかを示します。詳細は、"InterSystems IRIS 自然言語処理 (NLP) の使用法" の "意味的優位性" を参照してください。
これらのデータ系列は個別に拡大縮小され、すべてがグラフに表示されます。グラフに表示される目盛りは [エンティティ] 系列にのみ適用されます。任意の棒の実際の数値を表示するには、棒の上にカーソルを置きます。以下はその例です。

このタブでは、次の操作を実行できます。
-
別の NLP メジャーを選択して分析します。そのためには、[メジャー] の項目を選択します。
-
類似するエンティティを [エンティティの頻度] および [エンティティの分散] の計算に含めます。そのためには、[類似するエンティティを含む] を選択します。
-
[エンティティの分散] の代わりに [エンティティの分散率] (レコード総数に対するエンティティの分散の割合) を表示します。そのためには、[割合としての分散] を選択します。
-
分析する他の文字列を指定します。そのためには、[文字列の分析] に文字列を入力し、[分析] をクリックします。
-
このグラフの棒を選択すると、関連するエンティティが表示されます。次のセクションを参照してください。
[エンティティ] タブ
[エンティティ] タブには、指定されたピボット・テーブルのセルの中で関連するエンティティが表示されます。[セル詳細] タブで棒を選択すると、[エンティティ] タブが表示され、関連する詳細が表示されます。
[エンティティ] タブは以下のようになります。
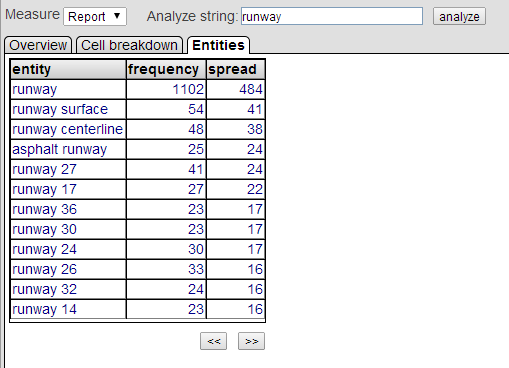
このタブでは、次の操作を実行できます。
-
別の NLP メジャーを選択して分析します。そのためには、[メジャー] の項目を選択します。
-
分析する他の文字列を指定します。そのためには、[文字列の分析] に文字列を入力し、[分析] をクリックします。その文字列の情報が表示されます。
-
結果をページ送りします。そのためには、[<<] ボタンと [>>] ボタンを使用します。