
シャーディングによるデータ量に応じた水平方向の拡張
このページでは、InterSystems IRIS シャード・クラスタの導入と使用について説明します。
InterSystems IRIS のシャーディングの概要
シャーディングは、InterSystems IRIS を水平方向に拡張するための重要な機能です。InterSystems IRIS シャード・クラスタは、データの格納とキャッシュの両方を複数のサーバ間で分割して、クエリおよびデータ取り込みに応じた柔軟で安価なパフォーマンス拡張を実現しながら、きわめて効率的にリソースを使用することにより、インフラストラクチャの価値を最大化します。シャーディングは、InterSystems IRIS の優れた垂直方向の拡張性と容易に組み合わせることができ、InterSystems IRIS がソリューションを提供する作業負荷の範囲が大幅に広がります。
シャード・クラスタを導入および使用するための実践演習を含むシャーディングの簡単な紹介については、"InterSystems IRIS デモ : シャード・クラスタの導入" を参照してください。
シャーディングの要素
シャーディングによる水平方向の拡張は、さまざまなアプリケーションに有益ですが、以下のいずれかまたは両方を含むユース・ケースで最も大きな効果が得られます。
-
ディスクからの大量のデータの取得、データの複雑な処理、またはその両方 (分析作業負荷など)
-
大量で高速のデータ取り込み
シャーディングは、データ・ノードと呼ばれる複数の InterSystems IRIS インスタンス間で大規模なデータベース・テーブルおよびそれらに関連付けられたインデックスを水平方向に分割すると同時に、これらのインスタンスのいずれかを介してアプリケーションがこれらのテーブルにアクセスできるようにします。データ・ノードが集まって、シャード・クラスタを形成します。このアーキテクチャには以下の利点があります。
-
シャード・テーブルに対するクエリは、すべてのデータ・ノード上で並列で実行され、結果はマージおよび集約され、完全なクエリ結果としてアプリケーションに返されます。
-
データ分割は別個のインスタンスによってホストされるため、単一インスタンスのキャッシュがデータ・セット全体を処理するのではなく、データ・セットの独自のパーティションを処理する専用キャッシュがあります。
シャーディングにより、大きなテーブルに対するクエリのパフォーマンスが、単一システムのリソースによって制約されなくなります。複数のシステムにわたってクエリ処理とキャッシュの両方を分散することで、シャーディングは計算リソースとメモリ・リソースの両方の線形に近い拡大を実現し、作業負荷に合わせて調整されたクラスタを設計および管理できます。データ・ノードを追加することによりスケール・アウトすると、シャード・データをクラスタ全体で再分散することができます。この分散データ・レイアウトは、データの並列ロードやサードパーティ・フレームワークでの使用などで活用することもできます。
シャードは、テーブルの行のサブセットです。各行は 1 つのシャード内に格納され、テーブルのすべてのシャードにほぼ同じ数の行が格納されます。各データ・ノードは、クラスタ上のシャード・テーブルごとに 1 つのシャードで構成されるデータ・シャードをホストします。シャーディング・マネージャと呼ばれるフェデレートされたソフトウェア・コンポーネントは、どのシャード (およびどのテーブル行) がどのデータ・ノードにあるかを追跡し、それに応じてクエリを送ると共に、他のシャード操作を管理します。各テーブルは、そのフィールドの 1 つをシャード・キーとして使用することで、自動的にデータ・ノード間で水平方向に分割されます。シャード・キーは、データを均等に分散するための確実な方法を提供します。シャード・キーは一般にはテーブルの RowId (既定) ですが、ユーザ定義のフィールドまたはフィールド・セットにすることもできます。
シャード・データはデータ・ノード間で物理的に分割されますが、任意のデータ・ノードで (シャード化されていないデータ、メタデータ、およびコードとして) すべて論理的に表示可能です。各データ・ノードには、クラスタ上のすべてのデータおよびコードに透過的にアクセスできるようにする、クラスタ・ネームスペース (クラスタ全体で同一の名前) があります。アプリケーションは任意のノードのクラスタ・ネームスペースにアクセスでき、全データセットをローカルのものであるかのように利用できます。したがってアプリケーション接続はクラスタ内すべてのデータ・ノードで負荷分散され、クエリの並列処理や分割されたキャッシュを最大限に活用する必要があります。
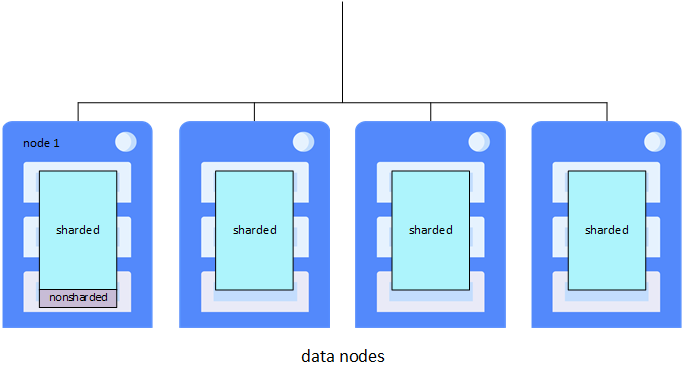
シャード化されていないデータは、最初に構成されたデータ・ノード (データ・ノード 1、または単にノード 1 と呼ぶ) にのみ格納されます。この区別は、より多くのデータがノード 1 に格納されるということ以外、ユーザに対して透過的です。ただし、この違いも一般的には小さいものです。アプリケーション SQL から見ると、シャード・テーブルとシャード化されていないテーブルの区別は透過的です。
InterSystems IRIS ミラーリングを使用すると、シャード・クラスタ内のデータ・ノードに対して高可用性を実現できます。単一インスタンスと同じように簡単に InterSystems IRIS インスタンスのミラー・フェイルオーバー・ペアをクラスタに追加できます。ミラーリングされたシャード・クラスタの導入の詳細は、"ミラー・データ・ノードによる高可用性" を参照してください。
常に大量のデータが取り込まれるような状況でも、クエリの遅延がきわめて小さいことが求められる高度な使用事例では、計算ノードを追加してクエリを処理するための透過的なキャッシュ層を提供することで、クエリとデータ取り込みの作業負荷を分離し、両方のパフォーマンスを向上させることができます。1 つのデータ・ノードに複数の計算ノードを割り当てることで、クラスタのクエリ・スループットをさらに向上させることができます。計算ノードとそれらの導入手順の詳細は、"作業負荷の分離とクエリ・スループットの向上のための計算ノードの導入" を参照してください。
シャーディングの効果の評価
InterSystems IRIS のシャーディングは、さまざまなアプリケーションに有益ですが、以下を含むユース・ケースで最も大きな効果が得られます。
-
比較的大きなデータ・セット、大量のデータを返すクエリ (またはその両方)。
シャーディングでは、データと共にキャッシュを分割することにより、複数のシステムのメモリ・リソースを利用し、データのサイズに合わせてキャッシュの処理能力を調整します。単一インスタンスのデータベース・キャッシュがすべてのデータに使用可能であるのと比べて、各データ・ノードのデータベース・キャッシュ (グローバル・バッファ・プール) はデータ・セットの一部のみに使用されます。定期的に使用されるデータが大きすぎて、シャード化されていない単一インスタンスのデータベース・キャッシュに収まらない場合、パフォーマンスの向上が最も顕著になります。
-
大量のデータ処理を行う大量の複雑なクエリ。
シャーディングでは、クエリを分解し、複数のデータ・ノード間で並列で実行することにより、複数のシステムの計算リソースを利用し、クエリ処理のスループットを調整します。クラスタに対するクエリが以下の条件に該当する場合、パフォーマンスの向上が最も顕著です。
-
永続ストレージから大量のデータを読み取り、特に、返す結果に対して取得するデータの割合が高い。
-
かなりの計算作業 (集約、グループ化、ソートなど) を必要とする。
-
-
大容量または高速のデータ取り込み (またはその組み合わせ)。
シャーディングでは、InterSystems IRIS JDBC ドライバを使用してデータ・ノードに直接接続し、並列でデータをロードすることにより、複数のインスタンス間で取り込みを分散し、データ取り込みを調整します。データが検証済みであるとして、一意性チェックを省略できる場合は、効果がさらに大きくなります。
これらの要因はそれぞれ個別でも、シャーディングから得られる潜在的恩恵に影響しますが、結合すれば恩恵も大きくなる場合があります。例えば、大量のデータの高速の取り込み、大規模データ・セット、大量のデータを取得して処理する複雑なクエリを組み合わせると、現代の分析上の作業負荷の多くがシャーディングに非常に適した候補になります。
前述のように、これまでに説明したいくつかの要因に対処するために InterSystems IRIS のシャーディングを垂直方向の拡張と組み合わせて使用すれば、さまざまな状況で最も高い効果が得られる可能性があります (詳細は、"InterSystems IRIS シャード・クラスタの計画" を参照してください)。
現在のリリースでは、シャーディングで、アトミック性を必要とする複雑なトランザクションが関与する作業負荷をサポートしておらず、そのような作業負荷に対してシャード・クラスタを使用することはできません。
ネームスペース・レベルのシャーディング・アーキテクチャ
このドキュメントの以前のバージョンでは、より大規模な別のノード・タイプのセット (シャード・マスタ・データ・サーバ、シャード・データ・サーバ、シャード・クエリ・サーバ) を含むシャーディング・アーキテクチャについて説明していました。このネームスペース・レベルのアーキテクチャは、新しいノード・レベルのアーキテクチャの透過的な基盤として残っており、ノード・レベルのアーキテクチャと完全な互換性があります。ノード・レベルのアーキテクチャにおいて、クラスタ・ネームスペース (クラスタ全体で同一の名前) は、クラスタ上のすべてのデータおよびコード (シャード化されているもの、いないもの共に) への透過的なアクセスを提供します。最初のデータ・ノードに配置されるようになったマスタ・ネームスペースは、依然としてメタデータ、シャード化されていないデータ、およびコードへのアクセスを提供し、すべてのデータ・ノードで完全に利用可能です。これにより、導入および使用が単純で便利な、より統一され、簡単なモデルが提供されます。
管理ポータルの [シャード構成] ページおよび %SYSTEM.ShardingOpens in a new tab API を使用して、ネームスペース・レベルのシャード・クラスタを導入できます。これらの手順は、"ネームスペース・レベル・アーキテクチャの導入" で説明されています。
シャード・クラスタの導入
評価やテストのために最初のクラスタを作成する簡単な方法を提供するため、このセクションでは、ミラーリングされていないデータ・ノードで構成される基本的な InterSystems IRIS シャード・クラスタを導入し、管理ポータルまたは %SYSTEM.ClusterOpens in a new tab API を使用してそのクラスタを構成する手動手順を説明します。それ以降の各セクションでは、以下のように、これらの手順を拡張して計算ノードとミラーリングを追加します。
-
計算ノードは既存のクラスタに簡単に追加できます。プロダクション環境への計算ノードの導入を検討する場合、一般的には、データ・ノードのみのクラスタの動作を評価してから、クラスタにとって計算ノードの追加が有益であるかどうかを決定することをお勧めします。計算ノードの計画と追加の詳細は、"計算ノードの計画" および "作業負荷の分離とクエリ・スループットの向上のための計算ノードの導入" を参照してください。
-
各データ・ノードにフェイルオーバー機能 (およびオプションの災害復旧機能) を追加すること、およびフェイルオーバー・メンバ間の遅延によって軽微な影響が出る可能性があることを除くと、ミラーリングされたシャード・クラスタの動作は、同じ数のデータ・ノードのミラーリングされていないクラスタとまったく同じです。ミラーリングされたシャード・クラスタの導入に関心がある場合、手順については "ミラー・データ・ノードによる高可用性" を参照してください。
InterSystems IRIS データ・プラットフォームでは、シャード・クラスタの自動導入方法もいくつか提供されています。これらの方法を使うと、オンプレミス・ハードウェア、パブリック・クラウド、プライベート・クラウド、Kubernetes などのさまざまなトポロジのクラスタを導入するプロセスが大幅に簡素化されます。
シャード・クラスタの導入にどの方法を使用するかにかかわらず、最初のステップでは、クラスタに含めるデータ・ノードの数を決定し、それらのノード上のデータベース・キャッシュとグローバル・データベースのサイズを計画します。手動で導入する場合は、クラスタを構成する前に、クラスタをホストするインフラストラクチャを特定またはプロビジョニングし、ホストに InterSystems IRIS インスタンスを導入する必要もあります。したがって、このセクションの手動手順を使用して基本のクラスタを導入するには、以下のように、最初にこのセクションのステップを実行してから、手動構成方法を選択します。
-
以下のいずれかを使用したクラスタの構成
このセクションの手順では、以下に注意してください。
-
ミラーリングされたシャード・クラスタまたは計算ノードの導入については説明されていません。ミラーリングされた導入については "ミラーによる高可用性" で説明しています。一方、"作業負荷の分離とクエリ・スループットの向上のための計算ノードの導入" では、API を使用して基本のクラスタに計算ノードを追加する方法を説明しています。
-
ノード・レベルのシャード・クラスタを導入します。ネームスペース・レベルのクラスタの導入手順は、"ネームスペース・レベル・アーキテクチャの導入" を参照してください。
これらの手順では、クラスタを構成する前にプロビジョニングまたは特定したホストに新しい InterSystems IRIS インスタンスを導入することを前提としていますが、既存のインスタンスでも使用できるように手順を変更できます。ただしその場合、クラスタ・ノードとして構成するインスタンスとそのホストが、最初の 4 つのステップで説明する要件とガイドラインに準拠していることが条件です。
複数のデータ・ノードおよび (該当する場合は) 計算ノードにわたってアプリケーション接続を分散する Web サーバ層の負荷分散に関する重要な説明は、"負荷分散、フェイルオーバー、ミラー構成" を参照してください。
メモリ管理および拡張、CPU サイジングおよび拡張、その他の考慮事項を含む、パフォーマンス計画の重要な説明は、"システム・リソースの計画と管理" を参照してください。
最も標準的なシャード・クラスタ構成では、各クラスタ・ノードは 1 つの物理または仮想システム上の 1 つの InterSystems IRIS インスタンスで構成されます。このページで説明する手順では、この構成が前提となります。
LDAP サーバを使用して、シャード・クラスタのノード全体で一元的なセキュリティを実装することをお勧めします。InterSystems IRIS での LDAP の使用についての詳細は、"LADP ガイド" を参照してください。
HealthShare Health Connect ではシャーディングはサポートされません。
クラスタの自動導入方法
このセクションで概要を説明する手動手順のほかにも、InterSystems IRIS データ・プラットフォームでは、導入後に完全に機能するシャード・クラスタの自動導入方法が 2 つ提供されています。
InterSystems Kubernetes Operator (IKO) を使用したシャード・クラスタの導入
KubernetesOpens in a new tab は、コンテナ化されたワークロードとサービスの導入、拡張、および管理を自動化するためのオープンソースのオーケストレーション・エンジンです。導入するコンテナ化されたサービスと、そのサービスを管理するポリシーを定義すると、Kubernetes は、必要なリソースを可能な限り最も効率的な方法で透過的に提供します。また、導入が指定値から外れた場合は導入を修復またはリストアするほか、拡張を自動またはオンデマンドで行います。InterSystems Kubernetes Operator (IKO) は、IrisCluster カスタム・リソースで Kubernetes API を拡張します。このリソースは、InterSystems IRIS のシャード・クラスタ、分散キャッシュ・クラスタ、またはスタンドアロン・インスタンスとして、すべて任意でミラーリングした状態で、Kubernetes プラットフォームに導入できます。
Kubernetes で InterSystems IRIS を導入するのに IKO は必須ではありませんが、プロセスが大幅に簡易化され、InterSystems IRIS 固有のクラスタ管理機能が Kubernetes に追加され、クラスタにノードを追加するなどのタスクが可能になります。このようなタスクは、IKO を使わなければインスタンスを直接操作して手動で行わなければなりません。
IKO の使用法の詳細は、"InterSystems Kubernetes Operator の使用Opens in a new tab" を参照してください。
構成マージを使用したシャード・クラスタの導入
Linux および UNIX® システムで利用可能な構成マージ機能を使用すると、宣言型構成マージ・ファイルを導入内の各インスタンスに適用することにより、同じイメージから導入した InterSystems IRIS コンテナや、同じキットからインストールしたローカル・インスタンスの構成を変更することができます。
このマージ・ファイルは、既存のインスタンスを再起動したときに適用することもでき、インスタンスの構成パラメータ・ファイル (CPF) を更新します。CPF にはインスタンスのほとんどの構成設定が含まれており、これらの設定は開始時に毎回、インスタンス導入後の最初の設定を含めて CPF から読み取られます。導入時に構成マージを適用すると、インスタンスと共に提供された既定の CPF が実質的に独自の更新バージョンに置き換えられます。
構成マージを使用すると、ノード・タイプごとに別個のマージ・ファイルを呼び出してシャード・クラスタを導入できます。その際、データ ノード 1、次に残りのデータ・ノード、そして計算ノード (オプション) というように順番に導入できます (他のデータ・ノードを構成するには、データ・ノード 1 として構成されているインスタンスが実行されている必要があるため、他のインスタンスを導入する前に、このインスタンスを導入して正常に開始する必要があります)。導入ホストの名前が指定した正規表現で終わっていれば、1 つのマージ・ファイルを使用して、データ・ノードのクラスタを自動的に導入 (およびオプションでミラーリング) することもできます。データ・ノードの導入後、オプションで別のマージ・ファイルを使用して計算ノードを導入できます。
前述のように、IKO には構成マージ機能が組み込まれています。
一般的な構成マージの使用法および具体的なシャード・クラスタの導入方法の詳細は、"構成マージを使用した InterSystems IRIS の自動構成" を参照してください。
データ・ノードの計画
クラスタに格納するシャード・データについて予測される作業セットと、そのデータに対して実行するクエリの性質に応じて、クラスタに適したデータ・ノードの数がわずか 4 台の場合もあります。いつでもデータ・ノードを既存のクラスタに追加し、シャード・データ を再分散できるため ("データ・ノードの追加とデータの再分散" を参照)、控えめになるのはもっともです。
(リソースの制限を条件として) プロダクション構成に必要なデータ・ノードの最適な数を最初に見積もるのに適した基本的な方法は、クラスタに必要なデータベース・キャッシュの総量を計算した後、状況およびリソースの可用性に応じて、サーバの数とサーバごとのメモリ量をどのように組み合わせるのが構成に適しているかを判断することです。これは、複数のシステム間で必要なリソースを分割する必要がある場合を除き、通常のサイジング・プロセスと同様です(メモリ管理および拡張、CPU サイジングおよび拡張、その他の考慮事項を含む、パフォーマンス計画の重要な説明は、"システム・リソースの計画と管理" を参照してください)。
必要なデータベース・キャッシュのサイズを決定するには、クラスタ上に格納することが予想されるシャード・データの総量、および頻繁にシャード・データと結合されるクラスタ上のシャード化されていないデータの量を見積もることから開始します。次にこれらの合計を使用して、シャード・データと頻繁に結合されるシャード化されていないデータの両方の作業セットを見積もり、これらを合わせたものが、クラスタ内のすべてのデータ・ノードで必要なデータベースのキャッシュ処理能力の合計を表します。この計算の詳細は、"InterSystems IRIS シャード・クラスタの計画" を参照してください。
ノード数とノードごとのメモリの両方に関するすべてのオプションを検討したら、各データ・ノード上のデータベース・キャッシュ (グローバル・バッファ・プール) がその処理能力の割り当て分に等しくなる、またはほぼ等しくなるように、十分なデータ・ノードを構成できます。さまざまなシナリオで、開始時のデータ・ノード数は、必要なキャッシュ・サイズの合計を、クラスタ・ノードとして導入するために使用できるシステムのメモリ容量で割ることで、大まかに決定することができます。
シャード・クラスタ内のすべてのデータ・ノードの仕様とリソースが同じであるか、少なくともほぼ同等である必要があります。クエリの並列処理の速度は、最も低速なデータ・ノードと同じ速度にしかなりません。さらに、クラスタ内のすべての InterSystems IRIS インスタンスの構成が一貫している必要があります。確実に正しい SQL クエリ結果が返されるようにするには、インスタンス・レベルで構成される照合などのデータベース設定やそれらの SQL 設定 (既定の日付形式など) がすべてのノードで同じでなければなりません。標準化された手順や、シャード・クラスタで利用可能な自動導入方法を使用すると、この一貫性を簡単に確保できます。
アプリケーションは任意のデータ・ノードのクラスタ・ネームスペースに接続して、全データセットをローカルのものであるかのように利用できるので、一般的なベスト・プラクティスとして、クラスタ内のすべてのデータ・ノード間でアプリケーション接続を負荷分散することをお勧めします。 IKO は、一般的なシナリオの場合、必要に応じてデータ・ノードのロード・バランサを自動的にプロビジョニングし、構成します。他の手段でシャード・クラスタを導入する場合は負荷分散メカニズムが必要となります。複数のデータ・ノードにわたってアプリケーション接続を分散する Web サーバ層の負荷分散に関する重要な説明は、"負荷分散、フェイルオーバー、ミラー構成" を参照してください。
データベース・キャッシュとデータベースのサイズの見積もり
シャード・クラスタを導入する前に、各データ・ノードに割り当てるデータベース・キャッシュのサイズを決定します。これは、予想される増大に十分対応できる空き容量を確保できるよう、各データ・ノードの既定のグローバル・データベースに必要なデータ量の予想サイズを把握するのにも有効です。
自動導入方法を使用してシャード・クラスタを導入する場合、これらの設定を導入の一部として指定できます。シャーディング API または管理ポータルを使用して手動で導入する場合は、シャード・クラスタを構成する前に各インスタンスのデータベース・キャッシュ・サイズを指定し、呼び出しでデータベース設定を指定することができます。両方の手動導入方法で既定の設定を提供しています。
以下に示すサイズはガイドラインであり、要件ではないこと、また、実践ではこれらの数値の見積もりが調整される可能性があることに留意してください。
データベース・キャッシュ・サイズ
"InterSystems IRIS シャード・クラスタの計画" で説明しているように、理想的にデータ・ノード上のデータベース・キャッシュに割り当てる必要があるメモリ量は、予想されるシャード・データの作業セットすべてのノードへの割り当て分に、頻繁にシャード・データに結合されるシャード化されていないデータの予想される作業セットすべてを加えたものになります。
グローバル・データベース・サイズ
"InterSystems IRIS シャード・クラスタの計画" で説明しているように、既定のグローバル・データベースのターゲット・サイズは以下のとおりです。
-
クラスタ・ネームスペース — シャード・データの合計サイズのうちの各サーバへの割り当て分 (上述のセクションで説明している計算による) に、予想を超える増大を見越したマージンを加えたもの。
-
ノード 1 のマスタ・ネームスペース — シャード化されていないデータの合計サイズに、予想を超える増大を見越したマージンを加えたもの。
すべての導入方法でこれらのデータベースのサイズが既定で構成されているため、ユーザがこの構成を行う必要はありません。ただし、これらのデータベースが配置されるストレージが、ターゲット・サイズに対応できる大きさであることを確認する必要があります。
インフラストラクチャのプロビジョニングまたは特定
必要なネットワーク・ホスト・システム (物理、仮想、またはクラウド) の数をプロビジョニングまたは特定します (各データ・ノードにつき 1 つのホスト)。
シャード・クラスタ内のすべてのデータ・ノードの仕様とリソースが同じであるか、少なくともほぼ同等である必要があります。クエリの並列処理の速度は、最も低速なデータ・ノードと同じ速度にしかなりません(計算ノードでも同じことが言えます。ただし、その場合、ストレージは考慮されません)。
ベスト・プラクティスとして、クラスタ内のすべてのデータ・ノード間でアプリケーション接続を負荷分散することをお勧めします。
クラスタのパフォーマンスを最大限に発揮させるためのベスト・プラクティスは、すべてのデータ・ノード間に低遅延のネットワーク接続を構成してネットワーク・スループットを最大化することです。例えば、すべてのデータ・ノードを同じデータ・センターまたはアベイラビリティ・ゾーン内の同じサブネットに配置します。この手順では、データ・ノードが TCP/IP 経由で相互にアクセス可能であることが前提となっており、推奨ネットワーク帯域幅はすべてのノード間で最小 1 GB、利用可能であれば 10 GB 以上が推奨されています。
データ・ノード・ホストへの InterSystems IRIS の導入
この手順では、各システムで単一の InterSystems IRIS インスタンスをホストするか、またはホストする予定であることが前提となっています。各インスタンスとそのホストがこのステップで説明する要件を満たす限り、最後のステップで新しく導入したインスタンスの代わりに既存のインスタンスを構成できます。
シャード・クラスタ内のすべての InterSystems IRIS インスタンスは、同じバージョンである必要があり、シャーディング・ライセンスを有する必要があります。
可能であれば、すべてのインスタンスについて、データベース・ディレクトリとジャーナル・ディレクトリを別個のストレージ・デバイスに配置してください。これは、大量のデータ取り込みがクエリの実行と同時に行われる場合に特に重要です。ジャーナル・ストレージなど、ファイル・システムおよびストレージの構成のガイドラインについては、"ストレージの計画"、"ファイル・システムの分離"、および "ジャーナリングの最善の使用方法" を参照してください。
クラスタ内のすべての InterSystems IRIS インスタンスの構成が一貫している必要があります。確実に正しい SQL クエリ結果が返されるようにするには、インスタンス・レベルで構成される照合などのデータベース設定やそれらの SQL 設定 (既定の日付形式など) がすべてのノードで同じでなければなりません。
各ホスト・システムで、以下を実行します。
-
インターシステムズが提供するイメージからコンテナを作成する ("コンテナ内でのインターシステムズ製品の実行" を参照) か、キットから InterSystems IRIS をインストールする ("インストール・ガイド" を参照) ことにより、InterSystems IRIS のインスタンスを導入します。
-
"データベース・キャッシュとデータベースのサイズの見積もり" の説明に従って、インスタンスのデータベースをホストするストレージ・デバイスがグローバル・データベースのターゲット・サイズに十分対応できる大きさであることを確認します。
-
"データベース・キャッシュとデータベースのサイズの見積もり" で決定したサイズに従って、インスタンスのデータベース・キャッシュ (グローバル・バッファ・プール) を割り当てます。管理ポータルでデータベース・キャッシュを割り当てる手順は、"メモリと開始設定" を参照してください。また、インスタンスの構成パラメータ・ファイル (CPF) を編集するか、UNIX® および Linux プラットフォームでは構成マージ・ファイルを使用して目的の値でインスタンスを導入することにより、globals パラメータを使用してキャッシュを割り当てることもできます。
クラスタ・メンバの共有メモリ・ヒープのサイズを大きくすることがお勧めの手段となることもあります。共有メモリ・ヒープは、gmheap パラメータの説明のように管理ポータルを使用して編集するか、上記の globals の説明のように gmheap を使用してインスタンスの CPF ファイルで編集できます。
Note:InterSystems IRIS インスタンスのルーチン・キャッシュとデータベース・キャッシュおよび共有メモリ・ヒープに必要なメモリを見積もる際の一般的なガイドラインは、"共有メモリの割り当て" を参照してください。
最後に、管理ポータル (次のセクション) または %SYSTEM.Cluster API (次の次のセクション) を使用して、導入したインスタンスをシャード・クラスタとして構成します。
管理ポータルを使用したクラスタの構成
最初の 4 つのステップ (データ・ノードの計画、データベース・キャッシュとデータベース・サイズの見積もり、インフラストラクチャのプロビジョニングまたは特定、およびデータ・ノード・ホストへの InterSystems IRIS の導入) を完了したら、この手順を使用して、前のステップで導入したインスタンス (または準備しておいた既存のインスタンス) を、管理ポータルを使用してデータ・ノードの基本の InterSystems IRIS シャード・クラスタとして構成します。
以下のステップを使用して、クラスタ内の各ノードを構成します。
ブラウザで管理ポータルを開く方法の詳細は、コンテナに導入されたインスタンスの手順、またはキットからインストールしたインスタンスの手順を参照してください。
この手順の後に、他の管理ポータルのシャード・クラスタ・オプションについて簡単に説明します。
データ・ノード 1 の構成
シャード・クラスタは最初のデータ・ノードを構成するときに初期化されます。最初のデータ・ノードをデータ・ノード 1、または単にノード 1 と呼びます。このデータ・ノードは、クラスタのシャード化されていないデータ、メタデータ、およびコードを格納し、すべてのデータ・ノードがそのデータにアクセスできるようにするマスタ・ネームスペースをホストするという点で、他のノードとは異なります。この区別は、より多くのデータがこの最初のノードに格納されるということ以外、ユーザに対して完全に透過的です。ただし、この違いも一般的には小さいものです。
最初の 4 つのステップ (データ・ノードの計画、データベース・キャッシュとデータベース・サイズの見積もり、インフラストラクチャのプロビジョニングまたは特定、およびデータ・ノード・ホストへの InterSystems IRIS の導入) を完了したら、この手順を使用して、前のステップで導入したインスタンス (または準備しておいた既存のインスタンス) を、管理ポータルを使用してデータ・ノードの基本の InterSystems IRIS シャード・クラスタとして構成します。
ノード 1 を構成するには、以下の手順を実行します。
-
インスタンスの管理ポータルを開き、[システム管理]→[構成]→[システム構成]→ [シャーディング]→[シャード有効] の順に選択し、表示されるダイアログで [OK] をクリックします (既定値はほぼすべてのクラスタに適しているため、[ECP 接続の最大数] 設定の値を変更する必要はありません)。
-
インスタンスを再起動します (管理ポータルが表示されているブラウザのウィンドウやタブを閉じる必要はありません。インスタンスが完全に再起動した後に再読み込みするだけでかまいません)。
-
[ノードレベルの構成] ページ ([システム管理]→[構成]→[システム構成]→[シャーディング]→[ノードレベルの構成]) に移動して、[構成] ボタンをクリックします。
-
[ノードレベルクラスタの構成] ダイアログで [このインスタンスで新しいシャードクラスタを初期化] を選択し、表示されるプロンプトに次のように応答します。
-
[クラスタネームスペース] および [マスターネームスペース] のドロップダウンからそれぞれクラスタ・ネームスペースとマスタ・ネームスペースを選択します。どちらのドロップダウンにも以下が含まれます。
-
作成する新しいネームスペースの既定の名前 (IRISCLUSTER および IRISDM) と、その既定のグローバル・データベース。
-
対象となるすべての既存のネームスペース。
シャード・クラスタを初期化すると、既定で、クラスタとマスタ・ネームスペース (それぞれ IRISCLUSTER および IRISDM という名前) と共に、その既定のグローバル・データベースと必要なマッピングが作成されます。ただし、クラスタ・ネームスペースとマスタ・ネームスペースの名前、およびそのグローバル・データベースの特性を制御するため、クラスタを構成する前に一方または両方のネームスペースと既定のデータベースを作成しておき、この手順でそれらを指定できます。例えば、"グローバル・データベース・サイズ" で説明されている考慮事項を踏まえ、クラスタ・ネームスペースの既定のグローバル・データベースの特性や、クラスタ内のすべてのデータ・ノードに複製されるシャード・データベースを制御するために、この方法を実行できます。
Note:クラスタ・ネームスペースとして指定した既存ネームスペースの既定グローバル・データベースになんらかのグローバルまたはルーチンがあると、初期化がエラーで失敗します。
-
-
場合によっては、InterSystems IRIS に認識されているホスト名が適切なアドレスに解決されないことや、ホスト名が利用できないことがあります。このような理由または他の理由で、代わりに IP アドレスを使用して他のクラスタ・ノードをこのノードと通信させたい場合は、ホスト名のオーバーライドのプロンプトで IP アドレスを入力します。
-
[ミラーリング有効] は選択しないでください。ミラーリングされたシャード・クラスタの導入手順は、"ミラーによる高可用性" で説明されています。
-
-
[OK] をクリックして [ノードレベルの構成] ページに戻ります。2 つのタブ [シャード] と [シャードテーブル] が表示されています。ノード 1 がクラスタ・アドレス (次の手順で必要になります) を含めて [シャード] に表示されるので、参照用にノード 1 の管理ポータルで [ノードレベルの構成] ページを開いたままにしておくことができます。[シャードを検証] をクリックして、ノード 1 が正しく構成されていることを検証します。
残りのデータ・ノードの構成
ノードを構成したら、以下の手順を使用して追加の各データ・ノードを構成します。
-
インスタンスの管理ポータルを開き、[システム管理]→[構成]→[システム構成]→ [シャーディング]→[シャード有効] の順に選択し、表示されるダイアログで [OK] をクリックします (既定値はほぼすべてのクラスタに適しているため、[ECP 接続の最大数] 設定の値を変更する必要はありません)。
-
インスタンスを再起動します (管理ポータルが表示されているブラウザのウィンドウやタブを閉じる必要はありません。インスタンスが完全に再起動した後に再読み込みするだけでかまいません)。
-
[ノードレベルの構成] ページ ([システム管理]→[構成]→[システム構成]→[シャーディング]→[ノードレベルの構成]) に移動して、[構成] ボタンをクリックします。
-
[ノードレベルクラスタの構成] ダイアログで [このインスタンスを既存のシャードクラスタに追加] を選択し、表示されるプロンプトに次のように応答します。
-
クラスタ URL を入力します。これは、[ノードレベルの構成] ページの [シャード] タブにノード 1 に対して表示されているアドレスです (前の手順の説明を参照してください)。クラスタ URL は、ノード 1 ホストの ID (ホスト名、または前の手順で IP アドレスを指定した場合は IP アドレス) に、InterSystems IRIS インスタンスのスーパーサーバ・ポートとクラスタ・ネームスペースの名前を加えたものになります。例えば、clusternode011.acmeinternal.com:1972:IRISCLUSTER のようになります (クラスタ・ネームスペースの名前は、既定の IRISCLUSTER である場合は省略できます)。
Note:もう 1 つのノード (この手順で必要なノード) から見ると、コンテナ化された InterSystems IRIS インスタンスのスーパーサーバ・ポートは、そのコンテナが作成されたときにスーパーサーバ・ポートが公開されたホスト・ポートによって異なります。この詳細および例は、"永続的な %SYS を使用した InterSystems IRIS コンテナの実行" と "InterSystems IRIS コンテナの実行 : Docker Compose の例"、および Docker ドキュメントの "Container networkingOpens in a new tab" を参照してください。
キットでインストールした、そのホスト上にしかない InterSystems IRIS インスタンスの既定のスーパーサーバ・ポート番号は 1972 です。複数のインスタンスがインストールされている場合、スーパーサーバ・ポート番号は 51776 以上の範囲になります。インスタンスのスーパーサーバ・ポート番号を表示または変更するには、管理ポータルで [システム管理]→[構成]→[システム構成]→[メモリと開始設定] を選択します。
-
[ロール] プロンプトで [データ] を選択して、インスタンスをデータ・ノードとして構成します。
-
場合によっては、InterSystems IRIS に認識されているホスト名が適切なアドレスに解決されないことや、ホスト名が利用できないことがあります。このような理由または他の理由で、代わりに IP アドレスを使用して他のクラスタ・ノードをこのノードと通信させたい場合は、ホスト名のオーバーライドのプロンプトで IP アドレスを入力します。
-
[ミラー化クラスタ] は選択しないでください。ミラーリングされたシャード・クラスタの導入手順は、"ミラーによる高可用性" で説明されています。
-
-
[OK] をクリックして [ノードレベルの構成] ページに戻ります。2 つのタブ [シャード] と [シャードテーブル] が表示されています。これまでに構成したデータ・ノードが [シャード] にノード 1 から表示されます。[シャードを検証] をクリックして、データ・ノードが正しく構成されていて、他のノードと通信できることを検証します。
Note:構成するデータ・ノードが多数ある場合は、[詳細設定] ボタンをクリックし、[詳細設定] ダイアログで [割り当て時に自動的にシャードを検証] を選択することにより、検証操作を自動化できます。シャード・クラスタを導入する際は、このダイアログのその他の設定は既定値のままにします。
管理ポータルのシャーディング・オプション
[再分散] ボタンを使用すると、[REBALANCE] ダイアログが表示されます。このダイアログで、既存のクラスタに最近追加されたデータ・ノードを含むすべてのデータ・ノードに均等にシャード・データを再分散できます (再分散の実行中にシャード・テーブルをクエリすることはできません)。データの再分散の詳細は、"データ・ノードの追加とデータの再分散" を参照してください。
[詳細設定] ダイアログは、[ノードレベルの構成] ページの [詳細設定] ボタンを押すと表示できます。このダイアログには以下のオプションがあります。
-
[割り当て時に自動的にシャードを検証] を選択すると、新しいクラスタ・ノードの構成後の検証を自動化できます。
-
クラスタのシャード・クエリ実行モードOpens in a new tabを既定の非同期から同期に変更します。この効果の説明については、"ミラーリングされたクラスタに計算ノードを含めることによる、フェイルオーバー前後での透過的なクエリ実行" を参照してください。
-
シャードの接続タイムアウトOpens in a new tabを既定値の 60 秒から変更します。
-
ホスト名ではなく、データ・ノード 1 ホストの IP アドレスOpens in a new tabを使用してクラスタ通信中に特定します。
-
クラスタがミラー・シャードへの接続を再試行するOpens in a new tab回数を既定値の 1 から変更します。
-
ローカル・ノードの ECP 接続の最大数を変更します。クラスタ内のノードの合計数がこの設定を超えることはできません。このセクションの 2 つのステップそれぞれの開始時に説明したように、この設定は、管理ポータルの [シャード有効] オプションを使用した場合、64 に設定されます。
-
クラスタを、DROP TABLE 操作中にエラーを無視Opens in a new tabするように設定します。
[ノードレベルの構成] ページの [シャードテーブル] タブに、クラスタ上のすべてのシャード・テーブルに関する情報が表示されます。
%SYSTEM.Cluster API を使用したクラスタの構成
以下の手順を使用して、前のステップで %SYSTEM.Cluster API を使用してデータ・ノードの基本の InterSystems IRIS シャード・クラスタとして導入したインスタンス (または準備しておいた既存のインスタンス) を構成します。"インターシステムズ・クラス・リファレンス" の "%SYSTEM.ClusterOpens in a new tab" クラス・ドキュメントを参照してください (%SYSTEM パッケージのすべてのクラスと同様に、%SYSTEM.ClusterOpens in a new tab メソッドは、$SYSTEM.Cluster を介しても使用できます)。
以下のステップを使用して、クラスタ内の各ノードを構成します。
ノード 1 の構成
シャード・クラスタは最初のデータ・ノードを構成するときに初期化されます。最初のデータ・ノードをデータ・ノード 1、または単にノード 1 と呼びます。このデータ・ノードは、クラスタのシャード化されていないデータ、メタデータ、およびコードを格納し、すべてのデータ・ノードがそのデータにアクセスできるようにするマスタ・ネームスペースをホストするという点で、他のノードとは異なります。この区別は、より多くのデータがこの最初のノードに格納されるということ以外、ユーザに対して完全に透過的です。ただし、この違いも一般的には小さいものです。
ノード 1 を構成するには、インスタンスの InterSystems ターミナルを開き、$SYSTEM.Cluster.Initialize()Opens in a new tab メソッドを呼び出します。以下に例を示します。
set status = $SYSTEM.Cluster.Initialize()
これらの手順で詳述されている各 API 呼び出しの戻り値 (成功の場合は 1 など) を確認するには、以下を入力します。
zw status
状況によっては通知なしで呼び出しが失敗することがあるため、各呼び出しの後に [ステータス] を確認することをお勧めします。呼び出しが成功しなかった ([ステータス] が [1] 以外) 場合、以下を入力することにより、わかりやすいエラー・メッセージが表示されます。
do $SYSTEM.Status.DisplayError(status)
Initialize() 呼び出しにより、マスタ・ネームスペースとクラスタ・ネームスペース (それぞれ IRISDM と IRISCLUSTER)、およびその既定のグローバル・データベースを作成し、必要なマッピングを追加します。ノード 1 はクラスタの他の部分に対してテンプレートとして機能します。クラスタ・ネームスペースの名前、既定のグローバル・データベース (シャード・データベースとも呼ばれる) の特性、およびマッピングは、2 番目に構成したデータ・ノードに直接複製され、さらにその他すべてのデータ・ノードに直接、または間接的に複製されます。インスタンスの SQL 構成設定も複製されます。
クラスタとマスタ・ネームスペースの名前、およびそれらのグローバル・データベースの特性を制御するには、クラスタのネームスペース、マスタ・ネームスペース、またはその両方として既存のネームスペースを指定 (いずれかまたは両方の名前を引数として含めることによって指定) します。以下に例を示します。
set status = $SYSTEM.Cluster.Initialize("CLUSTER","MASTER",,)
この際、指定した各ネームスペースの既存の既定グローバル・データベースは残ります。これにより、シャード・データベースの特性を制御でき、これらはクラスタ内の他のデータ・ノードに複製されます。
クラスタ・ネームスペースとして指定した既存ネームスペースの既定グローバル・データベースになんらかのグローバルまたはルーチンがあると、初期化がエラーで失敗します。
既定では、どのホストもクラスタ・ノードになることができます。Initialize() の 3 番目の引数で、IP アドレスまたはホスト名のコンマ区切りのリストを指定することで、クラスタに参加できるホストを指定できます。リストにないノードはクラスタに参加できません。
場合によっては、InterSystems IRIS に認識されているホスト名が適切なアドレスに解決されないことや、ホスト名が利用できないことがあります。このような理由または他の理由で、代わりに IP アドレスを使用して他のクラスタ・ノードをこのノードと通信させたい場合は、4 番目の引数として IP アドレスを含めます(この引数にホスト名を指定することはできません。IP アドレスのみです)。いずれの場合も、2 番目のデータ・ノードを構成する際、ホスト識別子 (ホスト名または IP アドレス) を使用してノード 1 を識別します。インスタンスのスーパーサーバ (TCP) ポートも必要です。
もう 1 つのノード (この手順で必要なノード) から見ると、コンテナ化された InterSystems IRIS インスタンスのスーパーサーバ・ポートは、そのコンテナが作成されたときにスーパーサーバ・ポートが公開されたホスト・ポートによって異なります。この詳細および例は、"永続的な %SYS を使用した InterSystems IRIS コンテナの実行" と "InterSystems IRIS コンテナの実行 : Docker Compose の例"、および Docker ドキュメントの "Container networkingOpens in a new tab" を参照してください。
キットでインストールした、そのホスト上にしかない InterSystems IRIS インスタンスの既定のスーパーサーバ・ポート番号は 1972 です。インスタンスのスーパーサーバ・ポート番号を表示または設定するには、そのインスタンスの管理ポータルで [システム管理]→[構成]→[システム構成]→[メモリと開始設定] を選択します (ブラウザで管理ポータルを開く方法の詳細は、コンテナに導入されたインスタンスの手順、またはキットからインストールしたインスタンスの手順を参照してください)。
Initialize() メソッドは、InterSystems IRIS インスタンスが既にシャード・クラスタのノードであるか、ミラー・メンバである場合、エラーを返します。
残りのデータ・ノードの構成
各追加データ・ノードを構成するには、InterSystems IRIS インスタンスのターミナルを開き、既存のクラスタ・ノード (2 番目のノードを構成している場合はノード 1) のホスト名とその InterSystems IRIS インスタンスのスーパーサーバ・ポートを指定して $SYSTEM.Cluster.AttachAsDataNode()Opens in a new tab メソッドを呼び出します。以下に例を示します。
set status = $SYSTEM.Cluster.AttachAsDataNode("IRIS://datanode1:1972")
ノード 1 の初期化の際、Initialize() の 4 番目の引数として IP アドレスを指定した場合は、最初の引数でノード 1 を識別するためにホスト名の代わりに IP アドレスを使用します。以下に例を示します。
set status = $SYSTEM.Cluster.AttachAsDataNode("IRIS://100.00.0.01:1972")
AttachAsDataNode() 呼び出しは、以下を実行します。
-
クラスタ・ネームスペースとシャード・データベースを作成し、それらを "ノード 1 の構成" で説明したとおり、テンプレート・ノードの設定 (最初の引数で指定) に合わせて構成し、必要なマッピングを作成して、これらをノード 1 のマスタ・ネームスペースのグローバル・データベースとルーチン・データベースに含めます (ユーザ定義のマッピングを含む)。
-
すべての SQL 構成オプションを、テンプレート・ノードに合わせて設定します。
-
このノードは AttachAsDataNode() のテンプレート・ノードとして後で使用される可能性があるため、クラスタに参加できるホストのリストを、ノード 1 の Initialize() 呼び出しで指定したリスト (ある場合) に設定します。
テンプレート・ノードのクラスタ・ネームスペースと同じ名前のネームスペースが新しいデータ・ノードに存在する場合は、そのネームスペースとそのグローバル・データベースがクラスタ・ネームスペースとシャード・データベースとして使用され、マッピングのみが複製されます。続いてこの新しいノードがテンプレート・ノードとして使用される場合は、これらの既存の要素の特性が複製されます。
AttachAsDataNode() 呼び出しは、InterSystems IRIS インスタンスが既にシャード・クラスタのノードまたはミラー・メンバであるか、最初の引数で指定されたテンプレート・ノードがミラー・メンバである場合、エラーを返します。
前のステップで説明したように、InterSystems IRIS に認識されているホスト名が適切なアドレスに解決されないことや、ホスト名が利用できないことがあります。代わりに IP アドレスを使用して他のクラスタ・ノードをこのノードと通信させるには、IP アドレスを 2 番目の引数として含めます(この引数にホスト名を指定することはできません。IP アドレスのみです)。
すべてのデータ・ノードを構成したら、$SYSTEM.Cluster.ListNodes()Opens in a new tab メソッドを呼び出してこれらをリストできます。以下に例を示します。
set status = $system.Cluster.ListNodes()
NodeId NodeType Host Port
1 Data datanode1 1972
2 Data datanode2 1972
3 Data datanode3 1972
この例のように、データ・ノードには、クラスタにアタッチされる順序を表す数値 ID が割り当てられます。
ベスト・プラクティスとして、クラスタ内のすべてのデータ・ノード間でアプリケーション接続を負荷分散することをお勧めします。
クラスタへの計算ノードの追加の詳細は、"作業負荷の分離とクエリ・スループットの向上のための計算ノードの導入" を参照してください。
シャード・テーブルの作成とデータのロード
クラスタが完全に構成されたら、シャード・テーブルを計画および作成し、それらにデータをロードします。必要な手順は以下のとおりです。
シャーディングに関する既存のテーブルの評価
クラスタ上のシャード化されていないデータに対するシャード・データの割合は一般には高いですが、既存のスキーマのシャード・クラスタへの移行を計画する際は、すべてのテーブルがシャーディングに適した候補であるとは限らないことに留意してください。アプリケーションのテーブルのうち、どれをシャード・テーブルとして定義するのか、どれをシャード化されていないテーブルとして定義するのかを決定する際には、主に、以下の要因に基づいて、クエリ・パフォーマンスやデータ取り込みの速度の向上を検討する必要があります (これらの要因については、"シャーディングの効果の評価" でも説明しています)。計画の際、シャード・テーブルとシャード化されていないテーブルの区別は、アプリケーション SQL に対して完全に透過的であることに留意してください。インデックスの選択と同様に、シャーディングの決定はパフォーマンスにのみ影響します。
-
全体のサイズ — 他の条件がすべて同じであれば、テーブルが大きいほど、効果が大きくなる可能性があります。
-
データ取り込み — 頻繁または大規模な (あるいはその両方の) INSERT 文をテーブルが受け取るかどうか。データの並列ロードは、シャーディングによってそのパフォーマンスを向上させることができることを意味します。
-
クエリの量 — 継続的に最も頻繁にクエリが実行されているテーブルはどれか。この場合も、他の条件がすべて同じであれば、クエリの量が多いほど、パフォーマンスが大きく向上する可能性があります。
-
クエリ・タイプ — クエリの量が多い、大きいテーブルの中でも、多くのデータを読み取る (特に、返す結果に対して読み取るデータの割合が高い) クエリを頻繁に受け取るものや多くの計算作業を行うものは、シャーディングに適した候補となります。例えば、幅広い SELECT 文によって頻繁にスキャンされるテーブルや、集約関数を含む多数のクエリを受け取るテーブルなどです。
シャーディングに適した候補をいくつか特定したら、以下の考慮事項について確認します。
-
頻繁な結合 — "シャード・キーの選択" で説明するように、頻繁に結合されるテーブルは、同じシャード・キーでシャード化してコシャード結合を有効にすることができます。これにより、個々のシャード上でローカルに結合を実行できるため、パフォーマンスが向上します。等値条件の 2 つの大きいテーブルを結合する、頻繁に使用される各クエリを調べて、コシャード結合の機会を示しているかどうかを評価します。テーブルのコシャーディングによって効果が得られるクエリが全体的なクエリ作業負荷のかなりの部分を占めている場合、これらの結合されるテーブルはシャーディングに適した候補となります。
ただし、大きいテーブルがはるかに小さいものに頻繁に結合されるときに、大きいテーブルをシャード化し、小さいテーブルをシャード化されないようにすると、最も効果的な場合があります。シャード化するテーブルを選択する際には、特定の結合の頻度やクエリ・コンテキストを入念に分析すると非常に役立ちます。
-
一意制約 — シャード・キーが一意キーのサブセットでない限り、シャード・テーブルの一意制約によって、挿入/更新のパフォーマンスに重大な悪影響が生じることがあります。詳細は、"シャード・キーの選択" を参照してください。
他の要因に関係なく、アトミック性を必要とする複雑なトランザクションに含まれるテーブルはシャード化しないでください。
シャード・テーブルの作成
シャード・テーブル (およびシャード化されていないテーブル) は、任意のノードのクラスタ・ネームスペースで、シャーディング仕様を含む SQL CREATE TABLE 文を使用して作成できます。このシャーディング仕様は、テーブルがシャーディングされること、および使用されるシャード・キー (シャード・テーブルのどの行をどのシャードに格納するかを特定するフィールド) を示します。シャード間でテーブルの行を均等に分散するための確実な方法を提供する適切なシャード・キーでテーブルが作成されると、INSERT や専用ツールを使用してここにデータをロードできます。また、CONVERT オプションを指定して ALTER TABLE コマンドを使用することで、シャード化されていないテーブルをシャード・テーブルに変換することもできます。このような変換では、シャード・キーを選択する必要があります。
シャード・キーの選択
既定では、シャード・テーブルを作成してシャード・キーを指定していない場合、システムにより割り当てられた RowID をシャード・キーとして使用して、データがここにロードされます。例えば、2 つのシャードがある場合、RowID=1 の行は一方のシャードに、RowID=2 の行はもう一方のシャードにロードされます。これはシステムが割り当てたシャード・キー (SASK) と呼ばれ、データの均等分散を最適に保証し、最も効率的な並列データ・ロードを可能にするため、多くの場合、最も簡単で効果的なアプローチになります。
既定では、RowID フィールドは ID と名付けられ、列 1 に割り当てられます。ID というユーザ定義フィールドが追加されると、テーブルのコンパイル時に RowID フィールドは ID1 という名前に変更され、キーを指定せずにシャーディングを行う際、既定で使用されるのは、このユーザ定義の ID フィールドになります。
シャード・テーブルの作成時に、シャード・キーとして 1 つ以上のフィールドを指定するオプションもあります。これはユーザ定義のシャード・キー (UDSK) と呼ばれます。スキーマに RowID に対応しない意味的に重要な一意の識別子が含まれている場合、例えば、スキーマ内のいくつかのテーブルに accountnumber フィールドがある場合は、UDSK を使用する良い機会かもしれません。
その他の考慮事項として、大きなテーブルを結合するクエリがあります。各シャード・クエリはシャードローカル・クエリに分解されます。それぞれのクエリは個々に、各シャード上でローカルに実行され、そのシャードに存在するデータを参照すればよいだけです。ただし、シャード・クエリに 1 つ以上の結合が含まれる場合、シャードローカル・クエリは一般に他のシャードのデータを参照する必要があるため、処理時間が長くなると共に、データベース・キャッシュに割り当てられたメモリをより多く使用します。この余分なオーバーヘッドは、コシャード結合を有効にすることで回避できます。コシャード結合では、結合される 2 つのテーブルの行が同じシャード上に配置されます。結合がコシャードされている場合、その結合が関与するクエリは、同じシャード上の行のみを結合するシャードローカル・クエリに分解され、他のシャード・クエリと同様に個別にローカルに実行されます。
コシャード結合は、以下の 2 つのアプローチのいずれかを使用して有効にできます。
-
2 つのテーブルに対して同等な UDSK を指定する。
-
1 つのテーブルに SASK を使用し、もう 1 つのテーブルで coshard with キーワードと適切な UDSK を使用する。
同等な UDSK を使用するには、2 つのテーブルにシャード・キーとして頻繁に結合されるフィールドを指定するだけです。例えば CITATION テーブルと VEHICLE テーブルを結合し、各車両に関連付けられた交通違反通知を返す場合、以下のようにします。
SELECT * FROM citation, vehicle where citation.vehiclenumber = vehicle.vin
この結合をコシャード結合にするには、同等なそれぞれのフィールドをシャード・キーとして使用して、両方のテーブルを作成します。
CREATE TABLE VEHICLE (make VARCHAR(30) not null, model VARCHAR(20) not null,
year INT not null, vin VARCHAR(17) not null, shard key (vin))
CREATE TABLE CITATION(citationid VARCHAR(8) not null, date DATE not null,
licensenumber VARCHAR(12) not null, plate VARCHAR(10) not null,
vehiclenumber VARCHAR(17) not null, shard key (vehiclenumber))
シャーディング・アルゴリズムは決定的であるため、特定の VIN の VEHICLE 行と CITATION 行 (ある場合) (それぞれ vin および vehiclenumber フィールドの値) は、同じシャード上に配置されます (ただし、フィールド値そのものが、行の各セットがどのシャードに配置されるかを特定することはありません)。したがって、上記のクエリが実行されると、各シャードローカル・クエリは、ローカルに (つまり、完全にそのシャード上で) 結合を実行できます。シャード・キーとして使用される 2 つのフィールド間の等値条件が含まれていなければ、結合をこのようにコシャードすることはできません。同様に、それぞれのテーブルのシャード・キーに、フィールド値の等値性を比較できるタイプの同じフィールド番号が同じ順序で存在する限り、複数フィールドの UDSK を使用して、コシャード結合を有効にできます。
多くのケースで有効なその他のアプローチでは、SASK を使用して 1 つのテーブルを作成し、最初のテーブルと共にコシャードされることを示す coshard with キーワード、および最初のテーブルのシステムが割り当てた RowID 値に等しい値を持つシャード・キーを指定することにより、もう 1 つのテーブルを作成します。例えば、以下のように、クエリで ORDER テーブルおよび CUSTOMER テーブルを頻繁に結合しているとします。
SELECT * FROM orders, customers where orders.customer = customers.%ID
この場合、結合の片方のフィールドは RowId を表すため、テーブル CUSTOMER を SASK を使用して次のように作成することから開始します。
CREATE TABLE CUSTOMER (firstname VARCHAR(50) not null, lastname VARCHAR(75) not null,
address VARCHAR(50) not null, city VARCHAR(25) not null, zip INT, shard)
コシャード結合を有効にするには、CUSTOMER テーブルへの参照として customer フィールドが定義されている ORDER テーブルを、そのフィールドで CUSTOMER テーブルとのコシャードを指定することで、シャーディングします。
CREATE TABLE ORDER (date DATE not null, amount DECIMAL(10,2) not null,
customer CUSTOMER not null, shard key (customer) coshard with CUSTOMER)
前に説明した UDSK の例と同様、これにより、ORDER の各行は、RowID 値がその customerid 値と一致する CUSTOMER の行と同じシャード上に配置されます (例えば、customerid=427 であるすべての ORDER 行は、ID=427 の CUSTOMER 行と同じシャード上に配置されます)。このようにして有効になったコシャード結合は、SASK でシャーディングされたテーブルの ID と、そのテーブルと共にコシャードされるテーブルに対して指定されるシャード・キーとの間の等値条件を含む必要があります。
一般には、スキーマで指定した以下のいずれかを使用することで、最も有用なコシャード結合を有効にできます。
-
例に示したとおり、テーブルと coshard with キーワードとの構造的な関係を表す SASK。この例では、ORDER テーブル内の customerid が CUSTOMER テーブル内の RowId への参照となっています。
-
RowID に対応しないため、VEHICLE テーブルおよび CITATION テーブルの等値の vin フィールドと vehiclenumber フィールドの使用で説明したとおりに coshard with を使用してコシャードできない、意味的に重要なフィールドを含む UDSK(多くの結合で使用されますが、表面的またはアドホックな関係を表すフィールドを含む UDSK は、通常あまり役立ちません)。
結合がないクエリやシャード・データとシャード化されていないデータを結合するクエリと同様に、コシャード結合は、シャード数の増加に伴う拡張性に優れているだけでなく、結合されるテーブルの数の増加に伴う拡張性にも優れています。コシャードされていない結合は、シャードや結合されるテーブルの数が適度であれば、優れたパフォーマンスを発揮しますが、それらの数の増加に伴う拡張性にはそれほど優れていません。こうした理由から、例えば、クエリが頻繁に実行されるフィールドのセットのパフォーマンスを向上させるためにインデックスを考慮するのと同様に、この段階でコシャード結合を慎重に検討する必要があります。
シャード・キーを選択する際は、これらの一般的な考慮事項に留意してください。
-
シャード・テーブルのシャード・キーは変更できず、その値を更新することもできません。
-
他の条件がすべて同じであれば、シャード間でのテーブルの行のバランスの取れた分散はパフォーマンスを向上させ、行の分散に使用されるアルゴリズムは、シャード・キーにさまざまな値が大量に含まれるが、主だった異常値はない場合に、最適なバランスを提供します (頻度に関して)。これは既定の RowID が一般にうまく機能するためです。類似した特性を持つ適切な UDSK は効率的であることも多いですが、不適切な UDSK はパフォーマンスの大きな向上が見られない不均衡なデータ分散につながる可能性があります。
-
大きいテーブルがはるかに小さいものに頻繁に結合されるときに、大きいテーブルをシャード化し、小さいテーブルをシャード化されないようにすると、コシャード結合を有効にするより効果的な場合があります。
一意制約の評価
シャード・テーブルに一意制約がある場合 ("フィールド制約" および "複数フィールドでの一意制約" を参照)、すべてのシャード間で一意性が保証されます。これは通常、挿入または更新される各行について、すべてのシャード全体で一意性を強制する必要があるため、挿入/更新のパフォーマンスが大幅に低下することを意味します。ただし、シャード・キーが一意キーのフィールドのサブセットである場合は、行が挿入または更新されるシャードでローカルに一意性を強制することにより、すべてのシャード全体で一意性を保証できるため、このようなパフォーマンスへの影響が回避されます。
例えば、指定したキャンパスの OFFICES テーブルに buildingnumber フィールドと officenumber フィールドが含まれているとします。建物番号はキャンパス内で一意であり、オフィス番号は各建物内で一意です。この 2 つを組み合わせて、各従業員のオフィス・アドレスをキャンパス内で一意にする必要があります。したがって、テーブルに対する一意制約を以下のように配置します。
CREATE TABLE OFFICES (countrycode CHAR(3), buildingnumber INT not null, officenumber INT not null,
employee INT not null, CONSTRAINT address UNIQUE (buildingname,officenumber))
ただし、テーブルをシャーディングする予定で、挿入/更新のパフォーマンスへの影響を回避するには、buildingnumber、officenumber、またはその両方をシャード・キーとして使用する必要があります。例えば、buildingnumber に対してシャーディングを行う (shard key (buildingnumber) を上記の文に追加することによる) 場合、各建物のすべての行が同じシャードに配置され、アドレスが “building 10, office 27” である従業員の行を挿入する際に、buildingnumber=10 であるすべての行を含むシャードに、アドレスの一意性をローカルに適用できます。officenumber に対してシャーディングを行う場合、officenumber=27 であるすべての行が同じシャードに配置され、“building 10, office 27” の一意性を、そのシャードにローカルに適用できます。一方、SASK、または UDSK として employee を使用する場合は、buildingnumber と officenumber の任意の組み合わせが任意のシャードに現れる可能性があるため、“building 10, office 27” の一意性をすべてのシャードで適用しなければならず、パフォーマンスに影響が生じます。
このような理由により、次のいずれかが当てはまらない限り、シャード・テーブルでの一意制約の定義は避けることをお勧めします。
-
すべての一意制約がサブセットとしてシャード・キーと共に定義されている (これは一般に、SASK や他の UDSK ほど効果的ではない)。
-
挿入および更新のパフォーマンスが、該当するテーブルのクエリ・パフォーマンスと比べてはるかに重要性が低いと思われる。
アプリケーション・コードで一意性を強制することにより (あるカウンタに基づくなど)、テーブル内の一意制約の必要性を排除でき、シャード・キーの選択が簡素化されます。
テーブルの作成
クラスタ内の任意のデータ・ノードのクラスタ・ネームスペースで標準の CREATE TABLE 文 ("CREATE TABLE" を参照) を使用して空のシャード・テーブルを作成します。"シャード・キーの選択" の例で示したように、テーブルを作成する際、2 種類のシャーディング仕様があります。
-
システムが割り当てたシャード・キー (SASK) でシャーディングを行うには、CREATE TABLE 文に shard キーワードを含めます。
-
ユーザ定義のシャード・キー (UDSK) でシャーディングを行うには、shard の後に key とシャーディングするフィールドを指定します (shard key (customerid, purchaseid) など)。
"主キーの定義" で説明しているように、テーブルを作成する際に PK_IS_IDKEY オプションを設定すると、テーブルの RowID が主キーになります。このような場合、既定のシャード・キーを使用することは、主キーがシャード・キーとなることを意味します。ただし、主キーをシャード・キーとして使用する場合は、テーブルを作成する前にこの設定の状態を確認しなくても済むように、シャード・キーを明示的に指定することをお勧めします。
ノード 1 または別のデータ・ノードの管理ポータルの [シャード構成] ページ ([システム管理]→[構成]→[システム構成]→[シャード構成]) に移動して、クラスタ・ネームスペースを選択し、[シャードテーブル] タブを選択することによって、名前、所有者、シャード・キーを含む、クラスタ上のすべてのシャード・テーブルのリストを表示できます。データをロードしたテーブルに対し、[詳細] リンクをクリックすると、クラスタ内の各データ・ノードに格納されているテーブルの行数を確認できます。
以下の制約が、シャード・テーブルの作成に適用されます。
-
ALTER TABLE を使用して既存のシャード化されていないテーブルをシャード・テーブルに入れることはできません (ただし、ALTER TABLE を使用してシャード・テーブルを変更することはできます)。
-
SHARD KEY フィールドのデータ型は、数値または文字列でなければなりません。シャード・キー・フィールドについて現在サポートされている照合は、完全一致、SQLString、および SQLUpper のみで、切り捨ては行われません。
-
ROWVERSION フィールドおよび SERIAL (%Counter) フィールド以外のすべてのデータ型がサポートされます。
-
シャード・テーブルに %CLASSPARAMETER VERSIONPROPERTYOpens in a new tab を含めることはできません。
このセクションのトピックの詳細および例は、"CREATE TABLE" を参照してください。
DDL を使用したシャード・テーブルの定義に加え、シャード・クラス・キーワードを使用してクラスをシャード・クラスとして定義することができます。詳細は、"永続クラスの作成によるシャード・テーブルの定義" を参照してください。クラス・コンパイラが拡張され、コンパイル時にシャーディングと互換性のないクラス定義機能 (カスタマイズされたストレージ定義など) の使用に対して警告を発行するようになりました。さらに成熟した作業負荷メカニズムや一部の互換性のない機能のサポートは、InterSystems IRIS の今後のバージョンで導入される予定です。
クラスタへのデータのロード
データは、SQL をサポートする InterSystems IRIS インタフェースを介してシャード・テーブルにロードできます。InterSystems IRIS JDBC ドライバに組み込まれている透過的な並列ロード機能では、シャード・テーブルへのデータの高速一括ロードがサポートされています。これらのオプションを、以下で説明します。
-
JDBC クライアント・ツールや SQL シェルなど、SQL をサポートする任意の InterSystems IRIS インタフェースを介してクラスタ上の空のシャード・テーブルにデータをロードできます。十分に検証されたデータで迅速にテーブルを生成することを目的とした LOAD DATA コマンドは、テーブルまたはファイルからデータをロードします。INSERT SELECT FROM などの INSERT 文を使用してデータをロードすることもできます。
-
InterSystems IRIS JDBC ドライバは、シャード・テーブルのロードに対する特定の最適化を実装します。シャード・テーブルへの INSERT 文を準備する際、JDBC クライアントは自動的に各データ・ノードへの直接接続を開き、これらに挿入された行を分配することで、特定の構成や API 呼び出しを行うことなく、大幅にパフォーマンスを向上させます。JDBC を使用するどのアプリケーションのシャード・テーブルのロードも、透過的にこの機能を利用します。
Note:ほとんどのデータ・ロード操作では、JDBC ドライバは、クラスタによって仲介されるデータ・ノードへの直接接続を使用します。これは、クラスタに割り当てる際に使用された IP アドレスまたはホスト名でデータ・ノードにアクセスすることをドライバ・クライアントに要求し、これが不可能な場合、このようなクエリを実行できないことを意味します。
シャード化されていないテーブルの作成とロード
シャード・テーブルと同様に、一般的な方法を使用して任意のデータ・ノードにシャード化されていないテーブルを作成し、それらのテーブルにデータを読み込むことができます。これらのテーブルは、シャード化されていないクエリとそれらをシャード・テーブルに結合するシャード・クエリの両方について、クラスタですぐに使用できます(これは、シャード化されていないテーブルを、それらを必要とする可能性がある各ノードに明示的に複製する必要があるアーキテクチャとは対照的です)。シャード化されていないものとしてロードするテーブルを選択する際のガイダンスについては、"シャーディングに関する既存のテーブルの評価" を参照してください。
シャード・クラスタにおけるクエリ
マスタ・ネームスペースとそこに格納されているシャード・テーブルは完全に透過的であり、マスタ・ネームスペース内のシャード・テーブルとシャード化されていないテーブルの任意の組み合わせを含む SQL クエリは、InterSystems IRIS ネームスペース内のテーブルに対する SQL クエリとまったく同じです。シャード・テーブルやシャード・キーを特定するための特殊なクエリ構文は必要ありません。クエリでは、複数のシャード・テーブルを結合することも、シャード・テーブルとシャード化されていないテーブルを結合することもできます。以下に示した InterSystems IRIS シャード・クラスタの初期バージョンにおける制限および制約以外のすべてがサポートされています。これらの制限および制約をすべて取り除くことを目標としています。
-
2 つのテーブルがコシャードされる場合、シャード・テーブルに強制される参照整合性制約は外部キーのみです。また、サポートされる唯一の参照アクションは NO ACTION です。
-
シャード・キー・フィールドのデータ型は、数値または文字列でなければなりません。シャード・キー・フィールドについて現在サポートされている照合は、完全一致、SQLString、および SQLUpper のみで、切り捨ては行われません。
-
シャード・テーブルの行レベルのセキュリティは、現在サポートされていません。
-
SQL ゲートウェイ接続経由でコンテンツを取得しているリンク・テーブルをシャード化することはできません。
-
以下の InterSystems IRIS SQL 拡張の使用は、現在サポートされていません。
-
%FOREACH および %AFTERHAVING を含む集約関数拡張
-
入れ子になった集約関数
-
SELECT 節または HAVING 節に集約関数と集約していないフィールドの両方を使用したクエリ (この集約していないフィールドを、GROUP BY 節で GROUP 項目としても使用している場合を除く)
-
FOR SOME %ELEMENT 述語条件
-
%INORDER キーワード
-
データ・ノードでクエリ・キャッシュを明示的に削除する場合、すべてのクエリ・キャッシュをマスタ・ネームスペースから削除することも、特定のテーブルについてクエリ・キャッシュを削除することもできます。これらのどちらのアクションでも、データ・ノードに削除が伝播されます。個々のクエリ・キャッシュの削除がデータ・ノードに伝播されることはありません。
クエリからタイムアウト・エラーが返された場合や messages.log に ECP 接続の問題が報告された場合、その一般的な原因はネットワークの問題です。このような場合は、%SYSTEM.Sharding API の $SYSTEM.Sharding.VerifyShards()Opens in a new tab メソッドを呼び出すことをお勧めします。このメソッドによってテストが実行され、接続の回復が試行されて、その過程での診断情報が報告されます。
クエリで報告される特権エラーの原因は、さまざまなシャードにユーザが割り当てた特権の不一致にあることが考えられます。例えば、特定のテーブルやビューに SELECT 特権を割り当てている場合です。サーバごとに特権を検証し、その同期を図ることをお勧めします。IRIS の今後のバージョンでは、このプロセスを自動化する予定です。
その他のシャード・クラスタ・オプション
シャーディングには、ニーズに適したさまざまな構成およびオプションが用意されています。このセクションでは、関連するその他のオプションについて簡単に説明します。内容は以下のとおりです。
クラスタにおけるこれらのオプションの効果を評価する際には、インターシステムズのサポート窓口Opens in a new tabまでお問い合わせください。
データ・ノードの追加とデータの再分散
InterSystems IRIS のシャーディングは、スケーラビリティと弾力性を実現するために設計されています。"InterSystems IRIS シャード・クラスタの計画" で説明しているように、最初の導入時にクラスタに含めるデータ・ノードの数は、シャード・テーブルで予測される作業セット、利用可能な計算リソースを含む (ただし、これらに限定されない) いくつかの要素の影響を受けます。ただし、時間の経過に伴って、クラスタ上のシャード・データの量が大幅に増加したり、リソース制約が削除されるといったさまざまな理由により、データ・ノードを追加する場合があります。"シャード・クラスタの導入" で説明されている自動または手動の導入方法を使用して、データ・ノードを追加できます。
"InterSystems IRIS のシャーディングの概要" で説明しているように、シャーディングでは、すべてのデータ・ノードでクエリの分解とそれらの実行を並列で実行することにより、クエリ処理のスループットを調整し、結果はマージおよび集約され、完全なクエリ結果としてアプリケーションに返されます。一般に、データ・ノードに格納されるシャード・データの量が多いほど、結果を返すのに時間がかかり、全体的なクエリのパフォーマンスは、最も遅いデータ・ノードによって制限されます。したがって、最適なパフォーマンスを得るには、シャード・データの格納が、クラスタのデータ・ノード間でほぼ均等になるようにする必要があります。
データ・ノードの追加後は該当しませんが、すべてのデータ・ノードでクラスタのシャード・データを再分散することで、このほぼ均等な分散がリストアされます。クラスタはその動作を中断せずに再分散できます。
データ・ノードの追加およびデータの再分散のプロセスを、次の例で説明します。
-
データ・ノードをクラスタに追加した後、既存のシャード・テーブルの行は、再分散するまで元のノードでそれらが配置されていた場所に維持されます。
データ・ノードが追加される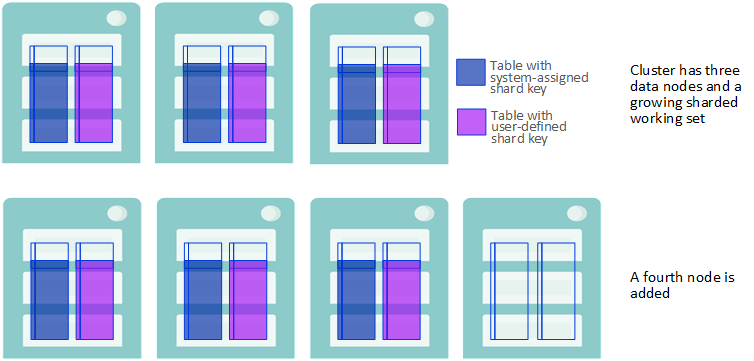
-
既存のテーブルに追加した行、または新しく作成してデータを読み込んだテーブルの形式でスケーリングされたクラスタにシャード・データを追加した場合、そのストレージは、各テーブルのシャード・キーによって異なります。
-
テーブルにシステム割り当てシャード・キー (SASK) がある場合、新しい行は、新しいノードを含むすべてのデータ・ノードに均等に格納されます。
-
テーブルにユーザ定義のシャード・キー (UDSK) がある場合、新しい行は元のデータ・ノード・セットにのみ均等に格納され、新しく追加したノードには格納されません。(ただし、新しいノードが追加される前に、既存の UDSK テーブルが存在しなかった場合は、新しい UDSK テーブル内の行がすべてのデータ・ノードに分散されます。)
新しいデータがシャード・キーに基づいて格納される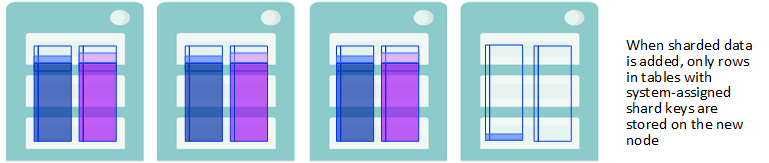
-
-
データ・ノードの追加後、クラスタ上でのクエリの並列処理を最大限に活用するには、クラスタに格納されたシャード・データを再分散し、今後クラスタに追加されるデータの分散された格納を可能にします。
再分散によりシャード・データが均等に格納される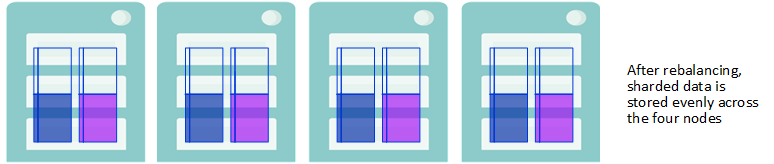
-
再分散後、両方の行が既存のテーブルに追加され、新しく作成されたテーブルの行も、シャード・キーに関係なくすべてのデータ・ノードに分散されます。したがって、再分散後、すべてのシャード・データ (既存のテーブル、既存のテーブルに追加された行、新しいテーブル内) は、すべてのデータ・ノードに均等に分散されます。
新しいシャード・データが均等に格納される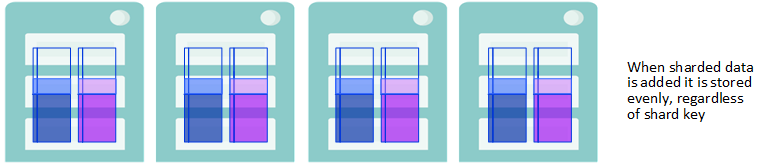
再分散操作は以下の 2 つの方法のいずれかで開始できます。
-
管理ポータルの [ノードレベルの構成] ページ ([システム管理]→[構成]→[システム構成]→[シャーディング]→[ノードレベルの構成]) で [再分散] をクリックすることにより表示される [再分散] ダイアログを使用する。
-
$SYSTEM.Sharding.Rebalance()Opens in a new tab API 呼び出しを使用する。
$SYSTEM.Sharding.Rebalance()Opens in a new tab のクラス・リファレンス・ドキュメントでは、いずれかのインタフェースを使用して指定できるパラメータについて説明しているほか、データ・ノード間でのシャード・データの再分散の詳細な手法についても説明しています。
再分散操作では、シャード・テーブル上でのほぼすべての操作が許可されていますが、シャード・テーブルへの JDBC バッチ挿入 (または仲介される JDBC バッチ挿入を使用するすべてのバルク・ロード・ユーティリティ) は例外で、これが試みられるとエラーが返されます。再分散操作の実行中には、クエリ・パフォーマンスに小さな悪影響を及ぼす場合があり、さらに小さな規模では、更新、挿入、削除などを含むその他の操作、テーブルの作成、変更、および削除、新しいシャードの割り当てにも悪影響を及ぼす場合があります。
パフォーマンスがかなりの懸念事項となる場合は、その操作に時間制限を設け、トラフィックが少ない時間やメンテナンスの時間にスケジュールすることもできます。時間制限に達すると、再分散操作は (まだ完了していない場合) データの移動を停止します (ただし、一部のクリーンアップ・タスクは短時間継続する場合があります)。再分散するデータが残っている場合は、選択した時間に、前の再分散が中断された場所を取得して別の再分散操作を開始できます。このアプローチを使用して、ニーズに合った長さでスケジュールされた一連の操作により、クラスタを完全に再分散できます。
この API 呼び出しを使用する場合、呼び出しにより移動されるデータの最小量を指定することもできます。指定された制限時間内にそれだけの量のデータを移動できない場合、再配分は発生しません。データ・ノードを追加したら、そのデータを再分散することによりパフォーマンスを最大限に高めることに留意してください。
ミラー・データ・ノードによる高可用性
InterSystems IRIS ミラーとは、物理的に独立した複数の InterSystems IRIS インスタンスの論理グループで、プロダクション・データベースの同一コピーを同時に保持します。これによって、データベースへのアクセスを提供しているインスタンスが使用不可になった場合でも、別のインスタンスが自動的にすばやく引き継ぐことができます。この自動フェイルオーバー機能により、ミラー内の InterSystems IRIS データベースに高可用性が提供されます。InterSystems IRIS のミラーリングの詳細は、"高可用性ガイド" を参照してください。
シャード・クラスタ内のデータ・ノードをミラーリングすると、データ・ノードにフェイルオーバー機能を提供し、高可用性を実現できます。シャード・クラスタ内のミラーリングされた各データ・ノードには、少なくともインスタンスのフェイルオーバー・ペアが含まれます。ペアの一方は常にプライマリとして動作するのに対し、他方はバックアップとして動作し、フェイルオーバー・パートナーが利用できなくなった場合にプライマリとして引き継ぐことができます。シャード・クラスタ内のデータ・ノード・ミラーに DR (災害復旧) 非同期メンバを 1 つ以上含めることもできます。このメンバをフェイルオーバー・メンバに昇格させることで、無効になったフェイルオーバー・パートナーを置き換えたり、フェイルオーバー・パートナーが両方とも利用できなくなった場合に災害復旧を提供したりできます。一般的な構成では、DR 非同期をフェイルオーバー・ペアとは別のデータ・センターまたはクラウドのアベイラビリティ・ゾーンに配置して、すべてのメンバが同じ障害や停止の影響を受ける可能性を最小限に抑えることを強くお勧めします。
シャード・クラスタは、すべてミラーリングするか、まったくミラーリングしないかのどちらかにする必要があります。同じクラスタ内にミラーリングされたデータ・ノードとミラーリングされていないデータ・ノードを混在させることはできません。
(管理ポータルまたは %SYSTEM.Cluster API のいずれかを使用した) ミラーリングされたデータ・ノードの手動での構成手順では、既存のミラー構成が認識されます。つまり、既存の環境と要件に応じて、ミラーリングされていないインスタンスか、ミラーリングされたインスタンスのいずれかから、以下のようにミラーリングされたデータ・ノードのシャード・クラスタを構成できます。
-
ミラーリングされたシャード・クラスタとしてミラーリングされていないインスタンスを構成する場合、追加する対象の各プライマリが、クラスタにアタッチされる前に自動的にミラー・プライマリとして構成されます。その後、別のミラーリングされていないインスタンスを、そのバックアップとして追加できます。追加したインスタンスは、自動的に適切に構成されてからクラスタにアタッチされます。
-
既存のミラーをシャード・クラスタとして構成する場合は、追加する各プライマリは、既存のミラー構成に変更を加えることなく、データ・ノード・プライマリとしてクラスタにアタッチされます。その後、フェイルオーバー・パートナーをそのプライマリのバックアップとして指定して、クラスタに追加できます。(データ・ノード・プライマリとして追加したミラーリングされたインスタンスにフェイルオーバー・パートナーがない場合は、ミラーリングされていないインスタンスをバックアップとして指定できます。これは自動的に適切に構成されてからクラスタにアタッチされます。)
-
同様に、ミラーリングされていないインスタンスを、データ・ノード・ミラーの DR 非同期メンバとして追加し、自動的に適切に構成してからクラスタにアタッチするか、フェイルオーバー・メンバが既にクラスタにアタッチされている既存のミラーのDR 非同期メンバを、適切に指定することで追加することができます。
-
どの場合も、クラスタ・ネームスペースとマスタ・ネームスペース (既定では IRISCLUSTER と IRISDM) のグローバル・データベースは、ミラー (前者はすべてのデータ・ノード、後者はノード 1 のミラー) に追加されます。既存のミラー・メンバを構成する場合は、ミラーリングされたデータベースは、シャード・クラスタの構成に従ってミラーリングされたまま残ります。
一般には、ミラーリングされていないすべてのインスタンスで開始してシャード・クラスタ導入の一環としてミラーを構成するか、既存のミラーからすべてのデータ・ノードを構成するのがベスト・プラクティスです。
"シャード・クラスタの導入" で説明されているいずれかの方法を使用して、ミラーリングされたシャード・クラスタを導入できます。そこで説明されている自動導入方法にはすべて、ミラーリングがオプションとして含まれます。このセクションでは、ミラーリングされたクラスタに関する手順を説明し、"シャード・クラスタの導入" のセクションに含まれる手動手順の最後のステップを置き換えます。まず、"シャード・クラスタの導入" のセクションで説明されているステップを実行してから、以下のように、ここで説明する手順の 1 つを使用して導入を完了します。
-
Note:
最初のステップで計画したミラーリングされたデータ・ノードにホストをそれぞれ 2 つ指定する必要があることに注意してください。例えば、8 個のデータ・ノードが必要な計画の場合、クラスタには 16 個のホストが必要です。シャード・クラスタ内のすべてのデータ・ノードに対して推奨されているように、ミラーを構成する 2 つのホストの仕様とリソースは、同じであるか、少なくともほぼ同等である必要があります。
-
以下のいずれかを使用した、ミラーリングされたクラスタ・ノードの構成
ただし、クラスタを導入する際のベスト・プラクティスとして、以下を推奨します。
-
クラスタ内のミラーリングされたすべてのデータ・ノード間でアプリケーション接続を負荷分散します。
-
クラスタにデータを保存する前に、ミラーリングされたシャード・クラスタを導入して完全に構成し、ミラーリングされたデータ・ノードのすべてのメンバ (フェイルオーバー・ペアとすべての DR 非同期) をクラスタにアタッチします。ただし、データが存在するかどうかに関係なく、既存のミラーリングされていないクラスタをミラーリングされたクラスタに変換することもできます。
-
データ・ノード・ミラーのフェイルオーバー後にクエリを透過的に実行できるようにするため、ミラーリングされたクラスタに計算ノードを含めます。
管理ポータルのミラーリングのページおよび %SYSTEM.MIRROR API では、ここで説明されている %SYSTEM.ClusterOpens in a new tab API および管理ポータルのシャーディングのページより多くのミラー設定を指定できます。"ミラーリングの構成" を参照してください。ミラーリングされていないインスタンスからクラスタを作成し、管理ポータルまたは API で自動的にミラーを構成する予定であっても、作業の前に "ミラーの作成" で手順と設定を確認することをお勧めします。
このセクションの手順を使用して、ミラーリングされたネームスペース・レベルのクラスタを導入することはできません。ただし、ミラーリングされていないネームスペース・レベルのクラスタを導入してから ("ネームスペース・レベル・アーキテクチャの導入" を参照)、そのクラスタをミラーリングされたクラスタに変換できます ("ミラーリングされていないクラスタからミラーリングされたクラスタへの変換" を参照)。
ミラーリングされたクラスタの考慮事項
ミラーリングされたシャード・クラスタの導入時には、以下のセクションで説明する重要なポイントに留意してください。
ミラーリングされたクラスタに計算ノードを含めることによる、フェイルオーバー前後での透過的なクエリ実行
計算ノードには永続データが保存されないため、計算ノードそのものはミラーリングしませんが、ミラーリングされたクラスタに計算ノードを含めると便利な場合があります。これは、関係のあるワークロードが、"作業負荷の分離とクエリ・スループットの向上のための計算ノードの導入" (計算ノードとそれらの導入手順の詳細情報を提供) で説明されている高度なユース・ケースに一致しない場合でも同様です。
ミラーリングされたシャード・クラスタが非同期クエリ・モード (既定) である場合に、シャード・クエリの実行中にデータ・ノード・ミラーがフェイルオーバーすると、エラーが返され、アプリケーションはクエリを再試行しなければなりません。この問題に対処する方法は 2 つあります。つまり、以下のように、フェイルオーバー前後でシャード・クエリを透過的に実行できるようにすることです。
-
クラスタを同期クエリ・モードに設定する。ただし、これには欠点があります。同期モードの場合、シャード・クエリをキャンセルできず、IRISTEMP データベースの使用量が増えます。このため、シャード・クエリが増加すると、利用可能なストレージ領域がすべて消費されて、クラスタの動作が中断するリスクが高くなります。
-
計算ノードをクラスタに含める。計算ノードには、計算ノードが割り当てられているミラーリングされたデータ・ノードとのミラー接続があるため、フェイルオーバーの前後で非同期モードでクエリを透過的に実行できます。
上記のオプションを考慮すると、ワークロードにとってフェイルオーバー前後でクエリを透過的に実行できることが重要である場合は、ミラーリングされたシャード・クラスタに計算ノードを含めることをお勧めします (少なくとも、ミラーリングされたデータ・ノードと同じ数の計算ノードが必要です)。計算ノードを含めることができない状況の場合は、$SYSTEM.Sharding.SetOption()Opens in a new tab API 呼び出しの RunQueriesAsync オプション (%SYSTEM.Sharding API を参照) を使用して、クラスタを非同期モードに変更できます。ただし、変更するのは、シャード・クエリをキャンセルできること、および IRISTEMP のサイズを管理できることよりも、フェイルオーバー前後でクエリを透過的に実行できることの方が重要な場合だけにしてください。
導入前のクラスタおよびマスタ・ネームスペースの作成
シャード・クラスタは最初のデータ・ノードを構成するときに初期化されます。最初のデータ・ノードをデータ・ノード 1、または単にノード 1 と呼びます。ここには既定で、クラスタとマスタ・ネームスペース (それぞれ IRISCLUSTER および IRISDM という名前) と共に、その既定のグローバル・データベースと必要なマッピングの作成が含まれます。ただし、クラスタ・ネームスペースとマスタ・ネームスペースの名前、またはそのグローバル・データベースの特性 (あるいはその両方) を制御するため、クラスタを構成する前に一方または両方のネームスペースと既定のデータベースを作成しておき、この手順でそれらを指定できます。ミラーリングされたシャード・クラスタの導入時にこれを行うことを計画している場合、ミラーリングされていないインスタンスで開始することはできませんが、代わりに次の手順を示された順序で実行する必要があります。
-
それぞれ 2 つのフェイルオーバー・メンバを含め、想定される各データ・ノードにミラーを構成します。
-
各ミラー・プライマリ上で対象のクラスタ・ネームスペースを作成し (既定の名前 IRISCLUSTER またはオプションで別の名前を使用)、データ・ノード 1 としてアタッチするミラーのプライマリ上で対象のマスタ・ネームスペース (既定の名前 IRISDM) を作成します。各ネームスペースの作成時に、[グローバルのための既存のデータベースを選択] のプロンプトで [新規データベース作成] を選択し、データベース・ウィザードの 2 ページ目の下部にある [ミラー・データベース?] に [はい] と設定して、ミラーリングされたデータベースとしてネームスペースの既定のグローバル・データベースを作成します。
-
このセクションで説明したとおり、データ・ノードとしてミラーを構成し、作成したネームスペースをクラスタおよびマスタ・ネームスペースとして指定します。
すべてのミラー・メンバでの IP アドレスのオーバーライドの有効化
場合によっては、対象のクラスタ・ノード上の InterSystems IRIS インスタンスに認識されているホスト名が適切なアドレスに解決されないことや、ホスト名が利用できないことがあります。このため、または他の何らかの理由により、他のクラスタ・ノードが代わりにその IP アドレスを使用してノードと通信する場合、管理ポータルの [ホスト名をIPアドレスで上書き] プロンプトで、または $SYSTEM.Cluster.InitializeMirrored()Opens in a new tab および $SYSTEM.Cluster.AttachAsMirroredNode()Opens in a new tab 呼び出しの引数として、そのノードの IP アドレスを指定することでこれを有効にできます。ミラーの 1 つのメンバに対してこれを実行したら、以下のようにすべてのミラー・メンバに対してこれを実行する必要があります。
-
ミラーリングされていないインスタンスをミラーリングされたデータ・ノードとして構成する場合は、上記のプロンプトまたは呼び出しを使用して、すべてのミラー・メンバに対して IP アドレスのオーバーライドを必ず有効にしてください。
-
ただし、既存のミラーをデータ・ノードとして構成する場合は、クラスタに追加する前に、ミラーのすべてのメンバに対して IP アドレスのオーバーライドを有効にする必要があります。管理ポータルと API のどちらの手順を使用しているかに関係なく、これは、各ノードで、InterSystems ターミナル・ウィンドウを開き、(任意のネームスペースで) $SYSTEM.Sharding.SetNodeIPAddress()Opens in a new tab ("%SYSTEM.Sharding API" を参照) を呼び出すことによって行ってください。以下に例を示します。
set status = $SYSTEM.Sharding.SetNodeIPAddress("00.53.183.209")ノードでこの呼び出しを使用したら、他の API 呼び出しでそのノードを参照するのに、ホスト名ではなく、指定した IP アドレスを使用する必要があります ($SYSTEM.Cluster.AttachAsMirroredNode()Opens in a new tab 呼び出し (ここでアタッチされるプライマリを指定する必要があります) を使用してミラー・バックアップをクラスタにアタッチする場合など)。
ミラーリングされたクラスタのメタデータの更新
%SYSTEM.ClusterOpens in a new tab API および管理ポータルのシャーディングのページ以外で、例えば管理ポータルのミラーリングのページや SYS.MirrorOpens in a new tab API を使用して、クラスタのミラーリングされたデータ・ノードを変更する場合は、変更後にミラーリングされたクラスタのメタデータを更新する必要があります。詳細は、"変更をミラーリングするためのクラスタ・メタデータの更新" を参照してください。
管理ポータルを使用したミラーリングされたクラスタの構成
ブラウザで管理ポータルを開く方法の詳細は、コンテナに導入されたインスタンスの手順、またはキットからインストールしたインスタンスの手順を参照してください。
ミラーリングされたクラスタを管理ポータルを使用して構成するには、以下の手順を実行します。
-
対象のノード 1 プライマリと対象のノード 1 バックアップの両方でインスタンスの管理ポータルを開き、[システム管理]→[構成]→[システム構成]→[シャーディング]→[シャード有効] の順に選択し、表示されるダイアログで [OK] をクリックします (ここで [ECP 接続の最大数] 設定を変更する必要はありません)。続いて、指示に従ってインスタンスを再起動します。管理ポータルが表示されているブラウザのウィンドウやタブを閉じる必要はありません。インスタンスが完全に再起動したら再読み込みするだけでかまいません。
-
対象のプライマリで、[ノードレベルの構成] ページ ([システム管理]→[構成]→[システム構成]→[シャーディング]→[ノードレベルの構成]) に移動して、[構成] ボタンをクリックします。
-
[ノードレベルクラスタの構成] ダイアログで [このインスタンスで新しいシャードクラスタを初期化] を選択し、表示されるプロンプトに次のように応答します。
-
[クラスタネームスペース] および [マスターネームスペース] のドロップダウンからそれぞれクラスタ・ネームスペースとマスタ・ネームスペースを選択します。どちらのドロップダウンにも以下が含まれます。
-
作成する新しいネームスペースの既定の名前 (IRISCLUSTER および IRISDM) と、その既定のグローバル・データベース。
-
対象となるすべての既存のネームスペース。
シャード・クラスタを初期化すると、既定で、クラスタとマスタ・ネームスペース (それぞれ IRISCLUSTER および IRISDM という名前) と共に、その既定のグローバル・データベースと必要なマッピングが作成されます。ただし、クラスタ・ネームスペースとマスタ・ネームスペースの名前、およびそのグローバル・データベースの特性を制御するため、クラスタを構成する前に一方または両方のネームスペースと既定のデータベースを作成しておき、この手順でそれらを指定できます。例えば、"グローバル・データベース・サイズ" で説明されている考慮事項を踏まえ、クラスタ・ネームスペースの既定のグローバル・データベースの特性や、クラスタ内のすべてのデータ・ノードに複製されるシャード・データベースを制御するために、この方法を実行できます。
Note:シャード・クラスタとして既存のミラーを構成する際に既存のネームスペースを使用する場合は、"導入前のクラスタおよびマスタ・ネームスペースの作成" の手順に従います。
クラスタ・ネームスペースとして指定した既存ネームスペースの既定グローバル・データベースになんらかのグローバルまたはルーチンがあると、初期化がエラーで失敗します。
-
-
場合によっては、InterSystems IRIS に認識されているホスト名が適切なアドレスに解決されないことや、ホスト名が利用できないことがあります。このような理由または他の理由で、代わりに IP アドレスを使用して他のクラスタ・ノードをこのノードと通信させたい場合は、ホスト名のオーバーライドのプロンプトで IP アドレスを入力します。
-
[ミラーリング有効] を選択し、アービターを構成する場合はその場所とポートを追加します (これは強く推奨されるベスト・プラクティスです)。
-
-
[OK] をクリックして [ノードレベルの構成] ページに戻ります。2 つのタブ [シャード] と [シャードテーブル] が表示されています。ノード 1 がクラスタ・アドレス (次の手順で必要になります) を含めて [シャード] に表示されるので、参照用にノード 1 の管理ポータルで [ノードレベルの構成] ページを開いたままにしておくことができます。まだバックアップを追加していないため、ミラー名はまだ表示されません。
-
対象のノード 1 バックアップで、プライマリの [ノードレベルの構成] ページに移動し、[構成] ボタンをクリックします。
-
[ノードレベルクラスタの構成] ダイアログで [このインスタンスを既存のシャードクラスタに追加] を選択し、表示されるプロンプトに次のように応答します。
-
[ノードレベルの構成] ページの [シャード] タブに、[クラスタ URL] として、ノード 1 プライマリに対して表示されているアドレスを入力します (前のステップを参照)。
-
[ロール] プロンプトで [データ] を選択して、インスタンスをデータ・ノードとして構成します。
-
場合によっては、InterSystems IRIS に認識されているホスト名が適切なアドレスに解決されないことや、ホスト名が利用できないことがあります。このような理由または他の理由で、代わりに IP アドレスを使用して他のクラスタ・ノードをこのノードと通信させたい場合は、ホスト名のオーバーライドのプロンプトで IP アドレスを入力します。
-
[ミラー化クラスタ] を選択して以下を実行します。
-
[ミラーの役割] ドロップダウンから [バックアップ・フェイルオーバー] を選択します。
-
前のステップでノード 1 を初期化する際にアービターを構成した場合は、その際に追加したものと同じアービターの場所とポートを追加します。
-
-
-
[OK] をクリックして [ノードレベルの構成] ページに戻ります。2 つのタブ [シャード] と [シャードテーブル] が表示されています。これまでに構成したノード 1 プライマリとバックアップは [シャード] のノード 1 の位置に、割り当てられているミラー名が含まれた状態で一覧表示されます。
-
残りのミラーリングされたデータ・ノードに対し、[シャード有効] オプションの設定と両方のインスタンスの再起動から始めて、前のステップを繰り返します。プライマリをクラスタに追加する場合は、前述のように、ノード 1 プライマリのアドレスを [クラスタ URL] として入力します。ただし、バックアップを追加する場合には、先ほど追加したプライマリのアドレスを [クラスタ URL] として入力します (ノード 1 プライマリのアドレスではありません)。
-
ミラーリングされたデータ・ノードをそれぞれ追加したら、クラスタ内のプライマリの 1 つで [ノードレベルの構成] ページに移動して [シャードを検証] をクリックし、新しいミラーリングされたノードが正しく構成されていて、他のノードと通信できることを検証します。この作業は、ミラーリングされたデータ・ノードをすべて追加するまで待つこともできます。また、構成するデータ・ノードが多数ある場合は、[詳細設定] ボタンをクリックし、[詳細設定] ダイアログで [割り当て時に自動的にシャードを検証] を選択することにより、検証操作を自動化できます(シャード・クラスタを導入する際は、このダイアログのその他の設定は既定値のままにします)。
%SYSTEM.Cluster API を使用したミラーリングされたクラスタ・ノードの構成
この API を使用して、ミラーリングされたクラスタを構成するには、以下の手順を実行します。
-
対象のノード 1 プライマリで、インスタンスの InterSystems ターミナルを開き、$SYSTEM.Cluster.InitializeMirrored()Opens in a new tab メソッドを呼び出します。以下に例を示します。
set status = $SYSTEM.Cluster.InitializeMirrored()Note:これらの手順で詳述されている各 API 呼び出しの戻り値 (成功の場合は 1 など) を確認するには、以下を入力します。
zw status呼び出しが成功しなかった場合、以下を入力することにより、わかりやすいエラー・メッセージが表示されます。
do $SYSTEM.Status.DisplayError(status)"ノード 1 の構成" で説明したように、この呼び出しは、$SYSTEM.Cluster.Initialize()Opens in a new tab と同じようにノード上のクラスタを初期化します。InitializeMirrored() の最初の 4 つの引数 (必須のものはありません) の説明については、このセクションを確認してください。これらの引数は Initialize() の引数と同じです。インスタンスがまだミラー・プライマリでない場合、次の 5 つの引数を使用してこれを構成します。既にプライマリである場合、これらは無視されます。ミラー引数は以下のとおりです。
-
アービターのホスト
-
アービターのポート
-
認証機関の証明書、ローカルな証明書、必要に応じて TLS でミラーを保護するために必要な秘密鍵ファイルを含むディレクトリ。呼び出しでは、これらのファイルがそれぞれ CAFile.pem、CertificateFile.pem、および PrivateKeyFile.pem という名前であると想定しています。
-
ミラーの名前。
-
このミラー・メンバの名前。
Note:InitializeMirrored() 呼び出しは、以下の場合、エラーを返します。
-
現在の InterSystems IRIS インスタンスが既にシャード・クラスタのノードである場合。
-
現在のインスタンスが既にミラー・メンバであるが、プライマリではない場合。
-
(最初の 2 つの引数で) 既に存在するクラスタ・ネームスペースまたはマスタ・ネームスペースを指定し、そのグローバル・データベースがミラーリングされていない場合。
-
-
対象のノード 1 バックアップで InterSystems IRIS インスタンスのターミナルを開き、最初の引数のクラスタ URL としてノード 1 プライマリのホストとスーパーサーバ・ポート、2 番目の引数にミラー・ロール backup を指定して、$SYSTEM.Cluster.AttachAsMirroredNode()Opens in a new tab を呼び出します。以下に例を示します。
set status = $SYSTEM.Cluster.AttachAsMirroredNode("IRIS://node1prim:1972","backup")ノード 1 プライマリの初期化の際、InitializeMirrored() の 4 番目の引数として IP アドレスを指定した場合は、最初の引数でノード 1 を識別するためにホスト名の代わりに IP アドレスを使用します。以下に例を示します。
set status = $SYSTEM.Cluster.AttachAsMirroredNode("IRIS://100.00.0.01:1972","backup")Note:そのホスト上にしかないコンテナ化されていない InterSystems IRIS インスタンスの既定のスーパーサーバ・ポート番号は 1972 です。インスタンスのスーパーサーバ・ポート番号を表示または設定するには、そのインスタンスの管理ポータルで [システム管理]→[構成]→[システム構成]→[メモリと開始設定] を選択します (インスタンスの管理ポータルを開いてスーパーサーバ・ポートを確認する方法の詳細は、コンテナに導入されたインスタンスの手順、またはキットからインストールしたインスタンスの手順を参照してください)。
"残りのデータ・ノードの構成" で説明しているように、この呼び出しにより、$SYSTEM.Cluster.AttachAsDataNode()Opens in a new tab と同様、ノードがデータ・ノードとしてアタッチされ、これがノード 1 ミラーのバックアップ・メンバとなることが保証されます。この呼び出しを発行する前に、ノードがノード 1 プライマリのバックアップとなっている場合 (つまり、既存のミラーをノード 1 として初期化している場合)、ミラー構成は変わりません。これがミラー・メンバではない場合は、ノード 1 プライマリのミラーにバックアップとして追加されます。どちらの場合も、ノード 1 プライマリのネームスペース、データベース、およびマッピング構成は、このノードに複製されます。(AttachAsMirroredNode の 3 番目の引数は、AttachAsDataNode と同じです。つまり、他のクラスタ・メンバがこのノードとの通信にホストの IP アドレスを使用する場合、このアドレスを含めます。)
ノード 1 ミラーの対象の DR 非同期メンバがある場合は、AttachAsMirroredNode() を使用してメンバをアタッチします。その際、以下の例のように、2 番目の引数として backup の代わりに drasync を使用します。
set status = $SYSTEM.Cluster.AttachAsMirroredNode("IRIS://node1prim:1972","drasync")バックアップをアタッチするときと同じように、ミラーの既存のメンバをアタッチする場合、そのミラー構成が変更されるのではなく、必要なミラー構成が追加されます。どちらの場合も、ノード 1 プライマリのネームスペース、データベース、およびマッピング構成は、新しいノードに複製されます。
Note:ノード 1 プライマリのミラーとは異なるミラーのメンバであるインスタンスをアタッチしようとすると、エラーが発生します。
-
ノード 1 以外のミラーリングされたデータ・ノードを構成するには、以下のように、$SYSTEM.Cluster.AttachAsMirroredNode()Opens in a new tab を使用してフェイルオーバー・ペアと DR 非同期の両方をクラスタにアタッチします。
-
プライマリを追加する際には、既存のプライマリをクラスタ URL に指定し、2 番目の引数として primary を指定します。インスタンスがまだミラーのプライマリではない場合、4 番目の引数と続く 4 つの引数を使用してこれを新しいミラーの最初のメンバとして構成します。引数は、前述の InitializeMirrored() 呼び出しでリストされているとおりです。インスタンスが既にミラー・プライマリの場合、ミラー引数を指定しても無視されます。
-
バックアップを追加する際には、対象のプライマリをクラスタ URL に指定し、2 番目の引数として backup を指定します。指定したノードがプライマリであるミラーに、バックアップとして既にインスタンスが構成されている場合、そのミラー構成は変わりません。インスタンスがまだミラー・メンバではない場合、これは 2 番目のフェイルオーバー・メンバとして構成されます。
-
DR 非同期を追加する際には、対象のプライマリをクラスタ URL に指定し、2 番目の引数として drasync を指定します。指定したノードがプライマリであるミラーに、DR 非同期として既にインスタンスが構成されている場合、そのミラー構成は変わりません。インスタンスがまだミラー・メンバではない場合、これは DR 非同期として構成されます。
Note:AttachAsMirroredNode() 呼び出しは、以下の場合、エラーを返します。
-
現在の InterSystems IRIS インスタンスが既にシャード・クラスタのノードである場合。
-
primary のロールが指定され、クラスタ URL (最初の引数) で指定されたクラスタ・ノードがミラー・プライマリではないか、現在のインスタンスがプライマリ以外のロールのミラーに属している場合。
-
backup のロールが指定され、最初の引数で指定されたクラスタ・ノードがミラー・プライマリではないか、バックアップ・フェイルオーバー・メンバを既に持つミラーのプライマリである場合。
-
drasync のロールが指定され、最初の引数で指定されたクラスタ・ノードがミラー・プライマリではない場合。
-
backup または drasync のロールが指定され、追加するインスタンスが既に、指定したプライマリを持つミラー以外のミラーに属している場合。
-
クラスタ・ネームスペース (または、ノード 1 バックアップを追加している場合はマスタ・ネームスペース) が現在のインスタンスに既に存在し、そのグローバル・データベースがミラーリングされていない場合。
-
-
すべてのデータ・ノードを構成したら、$SYSTEM.Cluster.ListNodes()Opens in a new tab メソッドを呼び出してこれらをリストできます。クラスタがミラーリングされている場合、このリストはミラーリングされているデータ・ノードの各メンバのミラー名とロールを示します。以下に例を示します。
set status = $system.Cluster.ListNodes() NodeId NodeType Host Port Mirror Role 1 Data node1prim 1972 MIRROR1 Primary 1 Data node1back 1972 MIRROR1 Backup 1 Data node1dr 1972 MIRROR2 DRasync 2 Data node2prim 1972 MIRROR2 Primary 2 Data node2back 1972 MIRROR2 Backup 2 Data node2dr 1972 MIRROR2 DRasync
ミラーリングされていないクラスタからミラーリングされたクラスタへの変換
ここでは、既存のミラーリングされていないシャード・クラスタをミラーリングされたクラスタに変換する手順を説明します。以下に、関連するタスクの概要を示します。
-
少なくとも十分な数の新しいノードをプロビジョニングして準備し、クラスタ内の既存のデータ・ノードそれぞれにバックアップを提供します。
-
既存のデータ・ノードそれぞれにミラーを作成してから、ノード 1 で $SYSTEM.Sharding.AddDatabasesToMirrors()Opens in a new tab を呼び出して、クラスタをミラーリングされた構成に自動的に変換します。
-
既存のデータ・ノード上に、ミラーリングされていないマスタ・データベースとシャード・データベースの調整されたバックアップを作成します (各ミラーの最初のフェイルオーバー・メンバ)。"シャード・クラスタの調整されたバックアップとリストア" を参照してください。
-
対象の 2 番目のフェイルオーバー・メンバ (新しいノード) それぞれに対して、参加させる最初のフェイルオーバー・メンバ (既存のデータ・ノード) を選択してから、最初のフェイルオーバー・メンバ上のミラーリングされたデータベースに対応するデータベースを新しいノード上に作成します。続いて、そのミラーに新しいノードを 2 番目のフェイルオーバー・メンバとして追加し、最初のフェイルオーバー・メンバ上に作成したバックアップからデータベースをリストアして、そのデータベースを自動的にミラーに追加します。
-
データ・ノード・ミラー内に作成したフェイルオーバー・ペアに DR 非同期を追加するには、最初のフェイルオーバー・メンバ上のミラーリングされたデータベースに対応する新しいノード上にデータベースを作成します。続いて、そのミラーに新しいノードを DR 非同期として追加し、最初のフェイルオーバー・メンバ上に作成したバックアップからデータベースをリストアして、そのデータベースを自動的にミラーに追加します。
-
任意のミラー・プライマリ (元のデータ・ノード) で $SYSTEM.Sharding.VerifyShards()Opens in a new tab を呼び出して、バックアップに関する情報を検証し、その情報をシャーディング・メタデータに追加します。
手順全体を 1 つのメンテナンス時間枠 (つまり、アプリケーションがオフラインで、クラスタ上にユーザのアクティビティがない予定期間) で実行することも、ここで説明するように手順を 2 つのメンテナンス時間枠に分割することもできます。
詳細なステップを以下に示します。まだ十分に理解していない場合は、続行する前に "%SYSTEM.Cluster API を使用したクラスタの構成" を確認してください。"ミラーリングの構成" で説明されているミラーの構成手順に関する知識も役に立ちますが、必須ではありません。この手順の各ステップには、必要に応じてリンクが記載されています。
ノード・レベルのミラーリングしていないクラスタを、この手順でミラー化したクラスタに変換するとネームスペース・レベルのクラスタになります。このクラスタの管理と変更は、%SYSTEM.Sharding API および管理ポータルのネームスペース・レベルのページでのみ可能です。
-
この手順を使用するには、クラスタのクラスタ・ネームスペースおよびマスタ・ネームスペースの名前がわかっている必要があります。これらの名前は、クラスタの導入時に指定されています。例えば、"データ・ノード 1 の構成" の手順 4 では、クラスタ・ネームスペースとマスタ・ネームスペースの選択について説明しています。同様に、"ノード 1 の構成" の初期 API 呼び出しの説明には、クラスタ・ネームスペースとマスタ・ネームスペースの指定が含まれています。
-
"インフラストラクチャのプロビジョニングまたは特定" および "データ・ノード・ホストへの InterSystems IRIS の導入" の指示に従って、クラスタにバックアップ・フェイルオーバー・メンバとして追加するノードを準備します。想定されるバックアップのホストの特性と InterSystems IRIS の構成は、すべての点で既存のデータ・ノードと同じである必要があります ("ミラー構成のガイドライン" を参照)。
Note:各フェイルオーバー・ペアに含まれる対象の最初のフェイルオーバー・メンバ (既存のデータ・ノード) および 2 番目のフェイルオーバー・メンバ (新しく追加したノード) をホスト名または IP アドレスで記録しておくと役に立ちます。
-
シャード・クラスタのメンテナンス時間枠を開始します。
-
現在のデータ・ノードそれぞれで ISCAgent を開始し、ミラーを作成して最初のフェイルオーバー・メンバを構成します。
-
このクラスタをミラーリングされた構成に変換する、つまり、前のステップで作成したミラーをクラスタの構成およびメタデータに組み込むには、ノード 1 のインスタンスの InterSystems ターミナルを開き、以下のようにマスタ・ネームスペースで $SYSTEM.Sharding.AddDatabasesToMirrors() メソッドを呼び出します ("%SYSTEM.Sharding API" を参照)。
set status = $SYSTEM.Sharding.AddDatabasesToMirrors()Note:これらの手順で詳述されている各 API 呼び出しの戻り値 (成功の場合は 1 など) を確認するには、以下を入力します。
zw status状況によっては通知なしで呼び出しが失敗することがあるため、各呼び出しの後に [ステータス] を確認することをお勧めします。呼び出しが成功しなかった ([ステータス] が [1] 以外) 場合、以下を入力することにより、わかりやすいエラー・メッセージが表示されます。
do $SYSTEM.Status.DisplayError(status)AddDatabasesToMirrors() 呼び出しは、以下を実行します。
-
ノード 1 でマスタ・データベースとシャード・データベースを追加し ("ノード 1 の構成" を参照)、他のデータ・ノードでシャード・データベースをそのそれぞれのミラーに追加します。
-
ノード間のすべての ECP 接続をミラー接続として再構成します。計算ノード (該当する場合) とその関連データ・ノード間の ECP 接続も対象です。
-
すべてのデータ・ノード上でリモート・データベースを再構成し、それに応じて関連するすべてのマッピングを調整します。
-
シャーディング・メタデータを更新し、再構成した接続、データベース、およびマッピングを反映させます。
呼び出しが正常に完了すると、シャード・クラスタは完全に使用可能な状態になります (ただし、バックアップ・フェイルオーバー・メンバをまだ追加していないため、フェイルオーバーはまだ実行できません)。
-
-
データ・ノードの調整されたバックアップを実行します (つまり、すべてのノードが論理的な同じ時点でバックアップされているバックアップ)。具体的には、最初のフェイルオーバー・メンバ (既存のデータ・ノード) のそれぞれでシャード・データベースをバックアップし、ノード 1 でマスタ・データベースもバックアップします。バックアップの前に、以下のようにインスタンスの構成パラメータ・ファイル (CPF) を確認して、適切なデータベースを特定しておきます。
-
CPF の [Map.clusternamespace] セクションを探して (例えば、クラスタ・ネームスペースが CLUSTERNAMESPACE の場合、このセクションは [Map.CLUSTERNAMESPACE])、IRIS.SM.Shard と IS.* グローバル接頭語のマッピング (このターゲットがシャード・データベース) を見つけることで、シャード・データベースを特定します。以下に示すように、他のグローバル接頭語もこのシャード・データベースにマッピングできます。シャード・データベースは SHARDDB として識別されます。
[Map.CLUSTERNAMESPACE] Global_IRIS.SM.Shard=SHARDB Global_IRIS.Shard.*=SHARDDB Global_IS.*=SHARDDB Package_IRIS.Federated=SHARDDB -
ノード 1 で、[Namespaces] セクションも見つけます。ここには、マスタ・ネームスペースの後に、その既定のグローバル・データベースとしてマスタ・データベースが表示されます。例えば、以下では、マスタ・データベース MASTERDB が、MASTERNAMESPACE の既定のグローバル・データベースとして表示されています。
[Namespaces] %SYS=IRISSYS CLUSTERNAMESPACE=SHARDDB MASTERNAMESPACE=MASTERDB USER=USER
-
-
オプションで、想定される 2 番目のフェイルオーバー・メンバと DR 非同期ミラー・メンバ (該当する場合) を以降のステップで準備する間、現在のメンテナンス時間枠を終了してアプリケーションのアクティビティを許可します。
-
2 番目のフェイルオーバー・メンバまたは DR 非同期としてクラスタに追加する各ノードで、以下を実行します。
-
目的の最初のフェイルオーバー・メンバ (前述の例では、CLUSTERNAMESPACE) 上のクラスタ・ネームスペースと同じ名前でネームスペースを作成し、その既定のグローバル・データベースとして、最初のフェイルオーバー・メンバ (例では、SHARDDB) 上のシャード・データベースと同じ名前でローカル・データベースを構成します。
-
ノード 1 に追加する目的の 2 番目のフェイルオーバー・メンバまたは DR 非同期でも、目的の最初のフェイルオーバー・メンバ上のマスタ・ネームスペースと同じ名前でネームスペースを作成し、その既定のグローバル・データベースとして、マスタ・データベースと同じ名前でローカル・データベースを構成します。前述の例を使用すると、既定のグローバル・データベースとして MASTERDB という名前のデータベースを持つ MASTERNAMESPACE ネームスペースを作成することになります。
-
メンテナンス時間枠内ではない場合は、新しいメンテナンス時間枠を開始します。
-
新しいノードそれぞれで、データが含まれるミラーリングされたデータベースを含む既存のミラーの 2 番目のフェイルオーバー・メンバまたは DR 非同期メンバとして、ミラーリングされていないインスタンスを追加するために必要なタスクを実行します。
-
対象のミラーの 2 番目のフェイルオーバー・メンバとしてノードを構成するか、または (2 番目のフェイルオーバー・メンバの構成後に) ノードを DR 非同期メンバとして構成します。
-
新しく構成したメンバ上で、最初のフェイルオーバー・メンバ上に作成したバックアップからシャード・データベースをリストアします。ノード 1 ミラー (2 番目のフェイルオーバーまたは DR 非同期) の新しく構成したメンバ上で、ノード 1 の最初のフェイルオーバー・メンバ上に作成したバックアップからマスタ・データベースもリストアします。
-
マスタ・データベースとクラスタ・データベースを有効化してキャッチアップします (オンライン・バックアップを使用してバックアップを作成した場合は必要ありません)。
Note:シャーディングによって自動的に、クラスタ・ネームスペース定義が更新され、必要なすべてのマッピング、ECP サーバ定義、およびリモート・データベース定義が作成され、マスタ・ネームスペース内のユーザ定義マッピングがシャードに伝播されます。したがって、このプロセスで手動で作成する必要があるマッピングは、マスタ・ネームスペース内のユーザ定義マッピングだけです。このマッピングは、ノード 1 の 2 番目のフェイルオーバー・メンバ上のマスタ・ネームスペース内にのみ作成する必要があります。ECP サーバ定義とリモート・データベース定義は手動でコピーする必要はありません。
-
-
いずれかのプライマリ (元のデータ・ノード) のインスタンスに対して InterSystems ターミナルを開き、以下のように、クラスタ・ネームスペース (またはノード 1 のマスタ・ネームスペース) で $SYSTEM.Sharding.VerifyShards()Opens in a new tab メソッドを呼び出します ("%SYSTEM.Sharding API" を参照)。
set status = $SYSTEM.Sharding.VerifyShards()この呼び出しにより、ミラーの 2 番目のフェイルオーバー・メンバについての必要な情報がシャーディング・メタデータに自動的に追加されます。
Note:この呼び出しを実行する場合、元のすべてのクラスタ・ノードがそのミラーの現在のプライマリである必要があります。したがって、2 番目のフェイルオーバー・メンバの追加後にミラーがフェイルオーバーした場合は、このステップを実行する前に、元のフェイルオーバー・メンバへの計画的フェイルバックを準備する必要があります (計画的フェイルオーバーの手順は、"プライマリ・フェイルオーバー・メンバのメンテナンス" を参照してください。iris stop コマンドを使用して、その手順で参照されている適切なシャットダウンを行う方法は、"InterSystems IRIS インスタンスの制御" を参照してください)。
上記の最後のステップが完了したら、メンテナンス時間枠を終了できます。ただし、クラスタをプロダクション環境に移行する前に、計画的フェイルオーバー (前の項目を参照) を実行して、各ミラーをテストすることを強くお勧めします。
変更をミラーリングするためのクラスタ・メタデータの更新
ここで説明されている API または管理ポータルによる手順以外の方法 (つまり、管理ポータルのミラーリングのページ、^MIRROR ルーチン、または SYS.MIRROR API) を使用して、ミラーリングされたクラスタ内の 1 つ以上のデータ・ノードのミラー構成を変更する場合は、クラスタのメタデータを更新する必要があります。そのためには、クラスタ・ネームスペース内で $SYSTEM.Sharding.VerifyShards()Opens in a new tab を呼び出すか ("%SYSTEM.Sharding API" を参照)、またはクラスタ内の現在のプライマリ・フェイルオーバー・メンバ上で管理ポータルの [ノードレベルの構成] ページの [シャードを検証] ボタンを使用します ("管理ポータルを使用したミラーリングされたクラスタの構成" を参照)。例えば、計画的フェイルオーバーを実行する場合は、DR 非同期を追加するか、バックアップ・メンバを DR 非同期に降格させるか、または DR 非同期をフェイルオーバー・メンバに昇格させて、シャードによってメタデータが更新されて変更が反映されることを検証します。データ・ノード・ミラーに DR 非同期を含めることによって設定した災害復旧機能を維持・活用するうえで、クラスタ・メタデータを更新することは重要な要素です。詳細は、"ミラーリングされたシャード・クラスタの災害復旧" を参照してください。
クラスタのシャードは、ミラーリング構成操作のたびに検証することも、一連の操作の完了後に一度だけ検証することもできますが、クラスタのオンライン中に操作を実行した場合は、フェイルオーバー・メンバを追加または削除する操作の実行後すぐにシャードを検証することをお勧めします。
作業負荷の分離とクエリ・スループットの向上のための計算ノードの導入
常に大量のデータが取り込まれるような状況でも、クエリの遅延がきわめて小さいことが求められる高度な使用事例では、計算ノードを追加して、クエリを処理するための透過的なキャッシュ層を提供できます。各計算ノードは、それが関連付けられているデータ・ノード上のシャード・データと、必要に応じてシャード化されていないデータをキャッシュします。クラスタに計算ノードが含まれている場合は、データ・ノード上ではなく、その計算ノード上で読み取り専用クエリが自動的に並行して実行されます。データ・ノードではすべての書き込み操作 (挿入、更新、削除、および DDL 操作) が引き続き実行されます。この作業分担により、クエリとデータ取り込みの作業負荷が分離される一方で、並列処理や分散キャッシュの利点を維持し、これら両方のパフォーマンスを向上させます。1 つのデータ・ノードに複数の計算ノードを割り当てることで、クラスタのクエリ・スループットとパフォーマンスをさらに向上させることができます。
計算ノードがクラスタに追加されると、これらはデータ・ノード間でできる限り均等に自動分散されます。計算ノードを追加することによってパフォーマンスが大幅に向上するのは、計算ノードがデータ・ノードごとに少なくとも 1 つある場合のみです。クラスタの速度は最も低速なデータ・ノードと同じ速度にしかならないので、リソースの最も効率的な使用方法は、一般的に、各データ・ノードに同じ数の計算ノードを割り当てることです。計算ノードではクエリの実行のみがサポートされ、データは格納されないので、メモリと CPU を重視し、ストレージを最小限に抑えるなど、ニーズに合わせてハードウェア・プロファイルを調整できます。
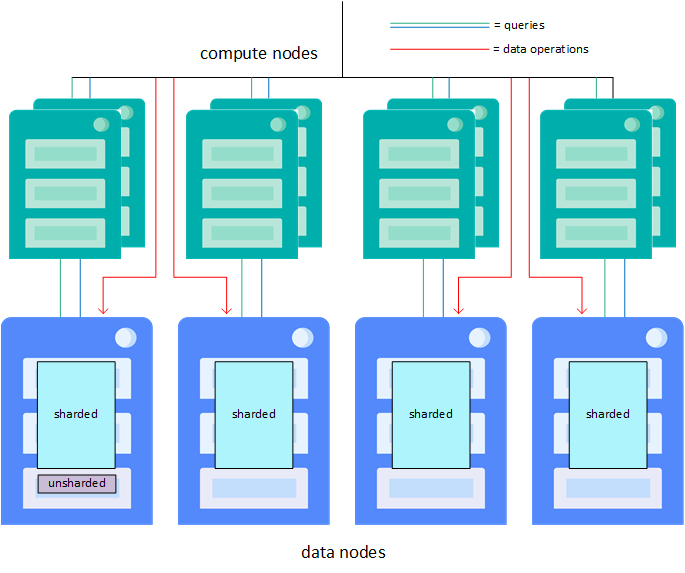
計算ノード、および計算ノードを使用したアプリケーションのクラスタへの接続の負荷分散の詳細は、"計算ノードの計画" を参照してください。
"シャード・クラスタの導入" で説明されているいずれかの導入方法を使用して、シャード・クラスタに計算ノードを追加できます。そこで説明されている自動導入方法にはすべて、計算ノードがオプションとして含まれます。このセクションでは、計算ノードを手動で導入する追加手順を説明します。まず、上記のセクションで説明されているステップを使用して、シャード・クラスタを手動で導入および構成します。その後、ここで説明するステップを使用して導入を完了します。
-
Note:
計画した計算ノードのホストを、計画したデータ・ノードのホストと共に含めます。例えば、8 個のデータ・ノードと 8 個の計算ノードが必要な計画の場合、クラスタには 16 個のホストが必要です。シャード・クラスタ内のすべてのノードの仕様とリソースが同じであるか、少なくともほぼ同等である必要があります。ただし、計算ノードのストレージは例外です。計算ノードはシャード・クラスタ・ロールではストレージを使用しません。
-
管理ポータルまたは %SYSTEM.Cluster API を使用したデータ・ノードの構成
-
管理ポータルまたは %SYSTEM.Cluster API を使用した計算ノードの追加 (以下の各セクションを参照)
管理ポータルを使用した計算ノードの構成または導入
クラスタに計算ノードを追加すると、データ・ノード間で計算ノードを自動的に分散するため、計算ノードは、前に関連付けられていた計算ノード数が最小だったデータ・ノードに割り当てられます。この手順は、クラスタをミラーリングするかどうかに関係なく同じです。
ブラウザで管理ポータルを開く方法の詳細は、コンテナに導入されたインスタンスの手順、またはキットからインストールしたインスタンスの手順を参照してください。
ネットワーク・システム上のインスタンスを計算ノードとしてクラスタに追加するには、以下の手順を使用します。
-
インスタンスの管理ポータルを開き、[システム管理]→[構成]→[システム構成]→ [シャーディング]→[シャード有効] の順に選択し、表示されるダイアログで [OK] をクリックします (既定値はほぼすべてのクラスタに適しているため、[ECP 接続の最大数] 設定の値を変更する必要はありません)。
-
インスタンスを再起動します (管理ポータルが表示されているブラウザのウィンドウやタブを閉じる必要はありません。インスタンスが完全に再起動した後に再読み込みするだけでかまいません)。
-
[ノードレベルの構成] ページ ([システム管理]→[構成]→[システム構成]→[シャーディング]→[ノードレベルの構成]) に移動して、[構成] ボタンをクリックします。
-
[ノードレベルクラスタの構成] ダイアログで [このインスタンスを既存のシャードクラスタに追加] を選択し、表示されるプロンプトに次のように応答します。
-
クラスタ URL を入力します。この URL は、既にクラスタに属しているインスタンスの [ノードレベルの構成] ページの [シャード] タブに、すべてのノードに対して表示されるアドレスです。"残りのデータ・ノードの構成" を参照してください。
Note:クラスタがミラーリングされている場合は、プライマリ・データ・ノードまたは計算ノードのアドレスを入力します。バックアップ・データ・ノードのアドレスではありません。
-
[ロール] プロンプトで [計算] を選択して、インスタンスをデータ・ノードとして構成します。
-
場合によっては、InterSystems IRIS に認識されているホスト名が適切なアドレスに解決されないことや、ホスト名が利用できないことがあります。このような理由または他の理由で、代わりに IP アドレスを使用して他のクラスタ・ノードをこのノードと通信させたい場合は、ホスト名のオーバーライドのプロンプトで IP アドレスを入力します。
-
[ミラー化クラスタ] チェック・ボックスは利用できません。計算ノードの構成はミラーリングに関係なく同じであるためです (ただし、前述のようにクラスタ URL が指定されている場合を除きます)。
-
-
[OK] をクリックして [ノードレベルの構成] ページに戻ります。2 つのタブ [シャード] と [シャードテーブル] が表示されています。これまでに構成したデータ・ノードと計算ノードが [シャード] にノード 1 から表示され、各計算ノードがどのデータ・ノードに割り当てられているかを示します。
[シャードを検証] をクリックして、計算ノードが正しく構成されていて、他のノードと通信できることを検証します。
Note:構成する計算ノードが多数ある場合は、[詳細設定] ボタンをクリックし、[詳細設定] ダイアログで [割り当て時に自動的にシャードを検証] を選択することにより、検証操作を自動化できます(シャード・クラスタを導入する際は、このダイアログのその他の設定は既定値のままにします)。
%SYSTEM.Cluster API を使用した計算ノードの導入
ネットワーク・システム上のインスタンスをクラスタに計算ノードとして追加するには、そのインスタンスの InterSystems ターミナルを開き、既存のクラスタ・ノードのホスト名とその InterSystems IRIS インスタンスのスーパーサーバ・ポートを指定して $SYSTEM.Cluster.AttachAsComputeNode()Opens in a new tab メソッドを呼び出します。以下に例を示します。
set status = $SYSTEM.Cluster.AttachAsComputeNode("IRIS://datanode2:1972")
これらの手順で詳述されている各 API 呼び出しの戻り値 (成功の場合は 1 など) を確認するには、以下を入力します。
zw status
呼び出しが成功しなかった場合、以下を入力することにより、わかりやすいエラー・メッセージが表示されます。
do $SYSTEM.Status.DisplayError(status)
テンプレート・ノードの構成時にこの IP アドレスを指定した場合 ("ノード 1 の構成" を参照) は、ホスト名ではなく、その IP アドレスを使用します。
set status = $SYSTEM.Cluster.AttachAsComputeNode("IRIS://100.00.0.01:1972")
他のノードに、IP アドレスを使用してこのノードと通信させる場合は、2 番目の引数として IP アドレスを指定します。
もう 1 つのノード (この手順で必要なノード) から見ると、コンテナ化された InterSystems IRIS インスタンスのスーパーサーバ・ポートは、そのコンテナが作成されたときにスーパーサーバ・ポートが公開されたホスト・ポートによって異なります。この詳細および例は、"永続的な %SYS を使用した InterSystems IRIS コンテナの実行" と "InterSystems IRIS コンテナの実行 : Docker Compose の例"、および Docker ドキュメントの "Container networkingOpens in a new tab" を参照してください。
そのホスト上にしかないコンテナ化されていない InterSystems IRIS インスタンスの既定のスーパーサーバ・ポート番号は 1972 です。インスタンスのスーパーサーバ・ポート番号を表示または設定するには、そのインスタンスの管理ポータルで [システム管理]→[構成]→[システム構成]→[メモリと開始設定] を選択します (インスタンスの管理ポータルを開いてスーパーサーバ・ポートを確認する方法の詳細は、コンテナに導入されたインスタンスの手順、またはキットからインストールしたインスタンスの手順を参照してください)。
最初の引数で指定したクラスタ・ノードがデータ・ノードの場合、これがテンプレートとして使用されます。計算ノードの場合は、これが割り当てられているデータ・ノードがテンプレートとして使用されます。AttachAsComputeNode() 呼び出しは、以下を実行します。
-
ECP およびシャーディング・サービスを有効にします。
-
データ・ノード間で計算ノードを自動的に分散するため、新しい計算ノードを、前に関連付けられた計算ノード数が最小だったデータ・ノードに関連付けます。
-
クラスタ・ネームスペースを作成し、"ノード 1 の構成" で説明したとおり、それをテンプレート・ノード (最初の引数で指定) の設定に合わせて構成し、必要なすべてのマッピングを作成します。
-
すべての SQL 構成オプションを、テンプレート・ノードに合わせて設定します。
クラスタ・ネームスペースと同じ名前のネームスペースが新しい計算ノードに既に存在する場合は、そのネームスペースがクラスタ・ネームスペースとして使用され、マッピングのみが複製されます。
他のクラスタ・ノードに、ホスト名ではなく IP アドレスを使用してこのノードと通信させる場合は、2 番目の引数として IP アドレスを指定します。
AttachAsComputeNode() 呼び出しは、InterSystems IRIS インスタンスが既にシャード・クラスタのノードである場合、エラーを返します。
すべての計算ノードを構成したら、$SYSTEM.Cluster.ListNodes()Opens in a new tab メソッドを呼び出してこれらをリストできます。以下に例を示します。
set status = $system.Cluster.ListNodes()
NodeId NodeType DataNodeId Host Port
1 Data datanode1 1972
2 Data datanode2 1972
3 Data datanode3 1972
1001 Compute 1 computenode1 1972
1002 Compute 2 computenode2 1972
1003 Compute 3 computenode3 1972
計算ノードが導入されると、このリストに各計算ノードが割り当てられるデータ・ノードのノード ID が示されます。$SYSTEM.Cluster.GetMetadata()Opens in a new tab を使用して、クラスタおよびマスタ・ネームスペースの名前、それらの既定のグローバル・データベース、および呼び出しを発行するノードの設定を含む、クラスタのメタデータを取得することもできます。
1 つのホストへの複数のデータ・ノードのインストール
指定数のシステムでデータ・ノードをホストしている場合、%SYSTEM.Shardng API を使用してホストごとに複数のデータ・ノード・インスタンスを構成すると、データ取り込みのスループットが大幅に向上します (%SYSTEM.Cluster API や管理ポータルでは、このような構成は不可能です)。したがって、最小限のコストで最大のデータ取り込みのスループットを達成することが重要である場合、ホストあたり 2 つまたは 3 つのデータ・ノード・インスタンスを構成することにより、これを実現できます。この方法で得られる効果は、サーバ・タイプ、サーバ・リソース、および全体の作業負荷によって異なります。システムの総数を増やすことで (ホスト・システムのメモリを複数のデータベース・キャッシュ間で分割することなく) 同様の、またはそれ以上のスループットの向上を実現できますが、インスタンスの追加は、システムの追加と比べてコストがかかりません。