
Generating Secondary Cubes for Use with Text Analytics
The integration of text analytics within InterSystems IRIS Business Intelligence uses InterSystems IRIS Natural Language Processing (NLP), which InterSystems has deprecated. As a result, this feature may be removed from future versions of InterSystems products. The following documentation is provided as reference for existing users only. Existing users who would like assistance identifying an alternative solution should contact the WRCOpens in a new tab.
This page assumes that you have added an NLP measure to a Business Intelligence cube (and have created NLP dimensions that use that measure), as described in Using Text Analytics in Cubes. This page describes how to generate secondary cubes that analyze entity occurrences and dictionary matching results. Always build the main cube before building these cubes.
The approach in this page is an alternative to using plug-ins as described in Adding Measures to Quantify Entity Occurrences and Adding Measures to Quantify Matching Results, in Using Text Analytics in Cubes. Plug-ins are a better approach, because the secondary cubes must be rebuilt manually whenever the main cube is rebuilt or synchronized.
Also see Accessing the BI Samples.
Entity Occurrence Cube
To generate a cube that represents entity occurrences, use the following command in the Terminal:
d ##class(%iKnow.DeepSee.CubeUtils).CreateEOCube(cubename,measurename)Where cubename is the name of the cube that contains an NLP measure, and measurename is the name of the NLP measure.
This method generates a read-only class that provides access to the entity occurrence data, for benefit of the cube class. The entity occurrence class is named BaseCubeClass.measurename.EntityOccurrence, where BaseCubeClass is the class name of the base cube class and measurename is the name of the NLP measure.
The method also generates the cube class: BaseCubeClass.measurename.EOCube. The new cube definition is as follows:
-
The logical name of the cube is BaseCubemeasurenameEO where BaseCube is the logical name of the base cube and measurename is the name of the NLP measure.
-
This cube represents entity occurrences. That is, the fact table for this cube contains one row for each unique entity occurrence.
-
The cube defines the Count measure, which counts entity occurrences.
-
The cube defines the Entity Value dimension, which groups entity occurrences by entity value.
This is a custom computed dimension; for general information on computed dimensions, see Using Advanced Features of Cubes and Subject Areas.
For this cube, a fact represents an entity occurrence. Note that in this cube, there is a one-to-one relationship between facts and entity values. In contrast, in the main cube, there is a one-to-many relationship between facts and entity values.
-
The cube defines the Roles dimension, which has the members concept and relation. These members group the entity occurrences into concepts and relations. For information on these terms, see Logical Text Units Identified by NLP.
-
The cube includes a relationship to the base cube. This relationship is called Main cube.
The following shows an example pivot table that uses the entity occurrence cube for the Aviation demo:
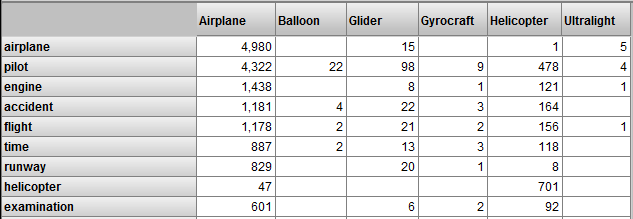
This pivot table is defined as follows:
-
The measure is Count (count of entity occurrences.)
-
The rows display members of the Entity Value dimension. Each member of this dimension represents an entity occurrence. For example, the pilot member represents each occurrence of the entity pilot in the sources.
-
The columns display members of the Category level of the Aircraft dimension in the main cube. Each member of this dimension represents the source documents associated with a given aircraft category.
This pivot table indicates, for example, that the entity airplane occurred 4980 times in the reports for events in the Airplane category.
Matching Results Cube
To generate a cube that represents matching results, use the following command in the Terminal:
d ##class(%iKnow.DeepSee.CubeUtils).CreateMRCube(cubename,measurename)Where cubename is the name of the cube that contains an NLP measure, and measurename is the name of the NLP measure.
This method generates a read-only class that provides access to the matching results data, for benefit of the cube class. The matching results class is named BaseCubeClass.measurename.MatchingResults, where BaseCubeClass is the class name of the base cube class and measurename is the name of the NLP measure.
This method also generates the cube class: BaseCubeClass.measurename.MRCube. The new cube definition is as follows:
-
The logical name of the cube is BaseCubemeasurenameMR where BaseCube is the logical name of the base cube and measurename is the name of the NLP measure.
-
This cube represents dictionary matches. That is, the fact table for this cube contains one row for each unique dictionary match.
-
The cube defines the Count measure, which counts dictionary matches.
-
The cube defines the Score measure, which shows the score of the dictionary matches.
-
The cube defines the Dictionary dimension. The Dictionary level groups matches by dictionary, and the Dictionary Item level groups matches by dictionary item.
For this cube, a fact represents a matching result. Note that in this cube, there is a one-to-one relationship between facts and dictionary items. In contrast, in the main cube, there is a one-to-many relationship between facts and dictionary items.
-
The cube defines the Type dimension, which has the members entity, CRC, path, and sentence. These members group the matches into entities, CRCs, paths, and sentences. For information on these terms, see Logical Text Units Identified by NLP.
For this demo, the Type dimension only has the members entity and CRC.
-
The cube includes a relationship to the base cube. This relationship is called Main cube.
The following shows an example pivot table that uses the matching results cube for the Aviation demo:

This pivot table is defined as follows:
-
The measures are Count (count of matching results) and Score (cumulative score of the dictionary matches).
-
The rows display members of the Injuries dictionary. Each member of this dimension represents an entity that matches a specific item in this dictionary. For example, the minor member represents each entity in the sources that matches the dictionary item minor.
-
The columns display members of the Type dimension in the main cube. Each member of this dimension represents the source documents associated with a given report type, either Accident or Incident.
This pivot table indicates, for example, that the sources of type Incident contain zero matches for the dictionary item fatal. In contrast, the sources of type Accident contain 106 matches for this dictionary item.