
Define and Build Indexes
Overview
An index is a structure maintained by a persistent class that InterSystems IRIS® data platform can use to optimize queries and other operations.
You can define an index on the values of a field within a table, or the corresponding property within a class. (You can also define an index on the combined values of several fields/properties.) The same index is created, regardless of whether you defined it using SQL field and table syntax, or class property syntax. InterSystems IRIS automatically defines indexes when certain types of fields (properties) are defined. You can define additional indexes on any field in which data is stored or for which data can be reliably derived. InterSystems IRIS provides several types of indexes. You can define more than one index for the same field (property), providing indexes of different types for different purposes.
InterSystems IRIS populates and maintains indexes (by default) whenever a data insert, update, or delete operation is carried out against the database, whether using SQL field and table syntax, or class property syntax. You can override this default (by using the %NOINDEX keyword) to rapidly make changes to the data, and then build or rebuild the corresponding index as a separate operation. You can define indexes before populating a table with data. You can also define indexes for a table that is already populated with data and then build the index as a separate operation.
InterSystems IRIS makes use of available indexes when preparing and executing SQL queries. By default it selects which indexes to use to optimize query performance. You can override this default to prevent the use of one or more indexes for a specific query or for all queries, as appropriate. For information about optimizing index usage, refer to Using Indexes.
Index Attributes
Every index has a unique name. This name is used for database administrative purposes (reporting, index building, dropping indexes, and so on). Like other SQL entities, an index has both an SQL index name and a corresponding index property name; these names differ in permitted characters, case-sensitivity, and maximum length. If defined using the SQL CREATE INDEX command, the system generates a corresponding index property name. If defined using a persistent class definition, the SqlName keyword allows the user to specify a different SQL index name (SQL map name). The Management Portal SQL interface Catalog Details displays the SQL index name (SQL Map Name) and the corresponding index property name (Index Name) for each index.
The index type is defined by two index class keywords, Type and Extent. The types of indexes available with InterSystems IRIS include:
-
Standard Indexes (Type = index) — A persistent array that associates the indexed value(s) with the RowID(s) of the row(s) that contains the value(s). Any index not explicitly defined as a bitmap index, bitslice index, or extent index is a standard index.
-
Bitmap Indexes (Type = bitmap) — A special kind of index that uses a series of bitstrings to represent the set of RowID values that correspond to a given indexed value; InterSystems IRIS includes a number of performance optimizations for bitmap indexes.
-
Bitslice Indexes (Type = bitslice) — A special kind of index that enables very fast evaluation of certain expressions, such as sums and range conditions. Certain SQL queries automatically use bitslice indexes.
-
Columnar Indexes (Type = columnar) — A special kind of index that enables very fast queries, especially ones involving filtering and aggregation operations, on columns whose underlying data is stored across rows.
-
Extent Indexes — An index of all of the objects in an extent. For more information, see the Extent index keyword page.
The maximum number of indexes for a table (class) is 400.
Storage Type and Indexes
The index functionality described here applies to data stored in a persistent class. InterSystems SQL supports index functionality for data stored using the InterSystems IRIS default storage structure, %Storage.Persistent (%Storage.Persistent-mapped classes), and for data stored using %Storage.SQL (%Storage.SQL-mapped classes). You can define an index for a %Storage.SQL-mapped class using a functional index type. The index is defined in the same manner as an index in a class using default storage, with the following special considerations:
-
The class must define the IdKey functional index, if it is not automatically system assigned. See Master Map, below.
-
This functional index must be defined as an INDEX.
Refer to %Library.FunctionalIndexOpens in a new tab for further details.
Index Global Names
The name of the subscripted global that stores index data is determined by the name of the global that stores the data in the table. These names are dependent on the values of the USEEXTENTSET and DEFAULTGLOBAL class parameters that define the table, either in a persistent class or by using the %CLASSPARAMETER key word in a CREATE TABLE statement. For more information about USEEXTENTSET and DEFAULTGLOBAL, see “Hashed Global Names” and “User-Defined Global Names” respectively.
Master Map
The system automatically defines a Master Map for every table. The Master Map is not an index, it is a map that directly accesses the data itself using its map subscript field(s). By default, the master map subscript field is the system-defined RowID field. By default, this direct data access using the RowID field is represented with the SQL Map Name (SQL index name) IDKEY.
By default, a user-defined primary key is not the IDKEY. This is because Master Map lookup using RowID integers is almost always more efficient than lookup by primary key values. However, if you specify that the primary key is the IDKEY, the primary key index is defined as the Master Map for the table and SQL Map Name is the primary key SQL index name.
For a single-field primary key/IDKEY, the primary key index is the Master Map, but the Master Map data access column remains the RowID. This is because there is a one-to-one match between a record’s unique primary key field value and its RowID value, and RowID is the presumed more efficient lookup. For a multi-field primary key/IDKEY, the Master Map is given the primary key index name, and the Master Map data access columns are the primary key fields.
You can view the Master Map definition through the Management Portal SQL Catalog Details tab. This displays, among other items, the global name where the Master Map data is stored. For SQL and default storage, this Master Map global defaults to ^package.classnameD and the namespace is recorded to prevent ambiguity. For custom storage, no Master Map data storage global is defined; you can use the DATALOCATIONGLOBAL class parameter to specify a data storage global name.
For SQL and default storage, the Master Map data is stored in a subscripted global named either ^package.classnameD or ^hashpackage.hashclass.1 (refer to Index Global Names for more information). Note that the global name specifies the persistent class name, not the corresponding SQL table name, and that the global name is case-sensitive. You can supply the global name to ZWRITE to display the Master Map data.
Data access using a Master Map is inefficient, especially for large tables. For this reason, it is recommended that the user define indexes that can be used to access data fields specified in WHERE conditions, JOIN operations, and other operations.
Automatically-Defined Indexes
The system automatically defines certain indexes when you define a table. The following indexes are automatically generated when you define a table and populated when you add or modify table data. If you define:
-
A primary key that is not an IDKEY, the system generates a corresponding index of type Unique. The name of the primary key index may be user-specified or derived from the name of the table. For example, if you define an unnamed primary key, the corresponding index will be named tablenamePKEY#, where # is a sequential integer for each unique and primary key constraint.
-
A UNIQUE field, InterSystems IRIS generates an index for each UNIQUE field with the name tablenameUNIQUE#, where # is a sequential integer for each unique and primary key constraint.
-
A UNIQUE constraint, the system generates an index for each UNIQUE constraint with the specified name, indexing the fields that together define a unique value.
-
A shard key, the system generates an index on the shard key field(s) named ShardKey.
You can view these indexes through the Management Portal SQL Catalog Details tab. The CREATE INDEX command can be used to add a UNIQUE field constraint; the DROP INDEX command can be used to remove a UNIQUE field constraint.
By default, the system generates the IDKEY index on the RowID field. Defining an IDENTITY field does not generate an index. However, if you define an IDENTITY field and make that field the primary key, InterSystems IRIS defines the IDKEY index on the IDENTITY field and makes it the primary key index. This is shown in the following example:
CREATE TABLE Sample.MyStudents (
FirstName VARCHAR(12),
LastName VARCHAR(12),
StudentID IDENTITY,
CONSTRAINT StudentPK PRIMARY KEY (StudentID) )Similarly, if you define an IDENTITY field and give that field a UNIQUE constraint, InterSystems IRIS explicitly defines an IdKey/Unique index on the IDENTITY field. This is shown in the following example:
CREATE TABLE Sample.MyStudents (
FirstName VARCHAR(12),
LastName VARCHAR(12),
StudentID IDENTITY,
CONSTRAINT StudentU UNIQUE (StudentID) )These IDENTITY indexing operations only occur when there is no explicitly defined IdKey index and the table contains no data.
Bitmap Extent Index
A bitmap extent index is a bitmap index for the rows of the table, not for any specified field of the table. In a bitmap extent index, each bit represents a sequential RowID integer value, and the value of each bit specifies whether or not the corresponding row exists. InterSystems SQL uses this index to improve performance of COUNT(*), which returns the number of records (rows) in the table. A table can have, at most, one bitmap extent index. Attempting to create more than one bitmap extent index results in an SQLCODE -400 error with the %msg ERROR #5445: Multiple Extent indexes defined: DDLBEIndex.
-
A table defined using CREATE TABLE automatically defines a bitmap extent index. This automatically-generated index is assigned the Index Name DDLBEIndex and the SQL MapName %%DDLBEIndex.
-
A table defined as a persistent class does not automatically define a bitmap extent index. If you add a bitmap index to a persistent class that does not have a bitmap extent index, InterSystems IRIS automatically generates a bitmap extent index. This generated bitmap extent index has an Index Name and SQL MapName of $ClassName (where ClassName is the name of the table’s persistent class).
You can use the CREATE INDEX command with the BITMAPEXTENT keyword to add a bitmap extent index to a table, or to rename an automatically-generated bitmap extent index. For further details, refer to CREATE INDEX.
You can view a table’s bitmap extent index through the Management Portal SQL Catalog Details tab. Though a table can have only one bitmap extent index, a table that inherits from another table is listed with both its own bitmap extent index and the bitmap extent index of the table it extends from. For example, the Sample.Employee table extends the Sample.Person table; in the Catalog Details Maps/Indices Sample.Employee lists both a $Employee and $Person bitmap extent index.
In a table that undergoes many DELETE operations the storage for a bitmap extent index can gradually become less efficient. You can rebuild a Bitmap Extent index either by using the BUILD INDEX command or from the Management Portal by selecting the table’s Catalog Details tab, Maps/Indices option and selecting Rebuild Index.
The %SYS.Maint.BitmapOpens in a new tab utility methods compress the bitmap extent index, as well as bitmap indexes and bitslice indexes. For further details, see Maintaining Bitmap Indexes.
Invoking the %BuildIndices() method builds an existing bitmap extent index in any of the following cases: the %BuildIndices() pIndexList argument is not specified (build all defined indexes); pIndexList specifies the bitmap extent index by name; or pIndexList specifies any defined bitmap index. See Building Indexes Programmatically.
Defining Indexes
There are two ways to define indexes:
-
Defining Indexes Using a Class Definition, which includes:
Defining Indexes Using DDL
If you are using DDL statements to define tables, you can also use the following DDL commands to create and remove indexes:
The DDL index commands do the following:
-
They update the corresponding class and table definitions on which an index is being added or removed. The modified class definition is recompiled.
-
They add or remove index data in the database as needed: The CREATE INDEX command populates the index using the data currently stored within the database. Similarly, the DROP INDEX command deletes the index data (that is, the actual index) from the database.
Defining Indexes Using a Class Definition
You can add index definitions to a %Persistent class definition by editing the text of the class definition. An index is defined on one or more index property expressions optionally followed by one or more optional index keywords. It takes the form:
INDEX index_name ON index_property_expression_list [index_keyword_list];
where:
-
index_name is a valid identifier.
-
index_property_expression_list is a list of the one or more comma-separated property expressions that serve as the basis for the index.
-
index_keyword_list is an optional comma-separated list of index keywords, enclosed in square brackets. Used to specify the index Type for a bitmap or bitslice index. Also used to specify a Unique, IdKey, or PrimaryKey index. (An IdKey or PrimaryKey index is, by definition, also a Unique index.) The complete list of index keywords appears in the Class Definition Reference.
The index_property_expression_list argument consists of one or more index property expressions. An index property expression consists of:
-
The name of the property to be indexed.
-
An optional (ELEMENTS) or (KEYS) expression, which provide a means of indexing on collection subvalues. If the index property is not a collection, the user can use the BuildValueArray() method to produce an array containing keys and elements. For more information on keys and elements, see Indexing Collections.
-
An optional collation expression. This consists of a collation name followed optionally by a list of one or more comma-separated collation parameters. You cannot specify an index collation for a Unique, IdKey, or PrimaryKey index. A Unique or PrimaryKey index takes its collation from the property (field) that is being indexing. An IdKey index is always EXACT collation. For a list of valid collation names, see Collation Types.
Adding an index to a class definition does not automatically build the index at compile time, unlike using the CREATE INDEX command. For information on building an index, see Building Indexes.
For example, the following class definition defines two properties and an index based on each of them:
Class MyApp.Student Extends %Persistent [DdlAllowed]
{
Property Name As %String;
Property GPA As %Decimal;
Index NameIDX On Name;
Index GPAIDX On GPA;
}A more complex index definition might be:
Index Index1 On (Property1 As SQLUPPER(77), Property2 AS EXACT);Properties That Can Be Indexed
Properties that can be indexed are:
-
Those that are stored in the database.
-
Those that can be reliably derived from stored properties.
A property that can be reliably derived (and is not stored) must be defined with the SQLComputed keyword as true; the compute code of the property must be the only way to derive the property’s value and the property cannot be set directly.
As a general rule, only derived properties defined as Calculated and SQLComputed can be indexed. There is, however, an exception for derived collections. That is, a collection defined with the SQLComputed and Transient keywords, but not the Calculated keyword, can be indexed.
If a property has a long text limit, data may be ingested in into the property, but the contents of the property may be too long to fit in the subscript of the index. The length limit may also manifest for composite indexes where the combination of multiple fields makes the property too long for the subscript. However, indexes on long strings generally have limited usefulness, as they are rarely identical to other values. Therefore, in these cases, an error message is provided and the data is not stored in the index. If you still would like a long text field to be included in an index, you can define TRUNCATE collation with a limit of 128 characters on the relevant properties.
There must not be a sequential pair of vertical bars (||) within the values of any property used by an IdKey index, unless that property is a valid reference to an instance of a persistent class. This restriction is required by the InterSystems SQL internal mechanism. The use of || in IdKey properties can result in unpredictable behavior.
Indexes on Combinations of Properties
You can define indexes on combinations of two or more properties (fields). Within a class definition, use the On clause of the index definition to specify a list of properties, such as:
Class MyApp.Employee Extends %Persistent [DdlAllowed]
{
Property Name As %String;
Property Salary As %Integer;
Property State As %String(MAXLEN=2);
Index MainIDX On(State,Salary);
}An index on multiple properties may be useful if you need to perform queries that use a combination of field values, such as:
SELECT Name,State,Salary
FROM Employee
ORDER BY State,SalaryIndex Collation
A Unique, PrimaryKey, or IdKey index cannot specify a collation type. For other types of indexes, each property specified in an index definition can optionally have a collation type. The index collation type should match the property (field) collation type when the index is applied.
-
If an index definition includes an explicitly specified collation for a property, the index uses that collation.
-
If an index definition does not include an explicitly specified collation for a property, the index uses the collation explicitly specified in the property definition.
-
If the property definition does not include an explicitly specified collation, then the index uses the collation that is the default for the property data type.
For example, the Name property is defined as a string, and therefore has, by default, SQLUPPER collation. If you define an index on Name, it takes, by default, the property’s collation, and the index would also be defined with SQLUPPER. The property collation and the index collation match.
However, if a comparison applies a different collation, for example, WHERE %EXACT(Name)=%EXACT(:invar), the property collation type in this usage no longer matches the index collation type. A mismatch between the property comparison collation type and the index collation type may cause the index to not be used. Therefore, in this case, you might wish to define the index for the Name property with collation EXACT. If an ON clause of a JOIN statement specifies a collation type, for example, FROM Table1 LEFT JOIN Table2 ON %EXACT(Table1.Name) = %EXACT(Table2.Name), a mismatch between the property collation type specified here and the index collation type may cause InterSystems IRIS to not use the index.
The following rules govern collation matches between an index and a property:
-
Matching collation types always maximize use of an index.
-
A mismatch of collation types, where the property is specified with EXACT collation (as shown above) and the index has some other collation allow the index to be used, but its use is less effective than matching collation types.
-
A mismatch of collation types, where the property collation is not EXACT and the property collation does not match the index collation, causes the index to not be used.
To explicitly specify a collation for a property in an index definition, the syntax is:
Index IndexName On PropertyName As CollationName;
where
-
IndexName is the name of the index
-
PropertyName is the property being indexed
-
CollationName is the type of collation being used for the index
For example:
Index NameIDX On Name As Exact;Different properties can have different collation types. For example, in the following example the F1 property uses SQLUPPER collation while F2 uses EXACT collation:
Index Index1 On (F1 As SQLUPPER, F2 As EXACT);For a list of recommended collation types, see Collation Types.
An index specified as Unique, PrimaryKey, or IdKey cannot specify an index collation. The index takes its collation from the property collations.
Using the Unique, PrimaryKey, and IdKey Keywords with Indexes
As is typical with SQL, InterSystems IRIS supports the notions of a unique key and a primary key. InterSystems IRIS also has the ability to define an IdKey, which is one that is a unique record ID for the instance of a class (row of a table). These features are implemented through the Unique, PrimaryKey, and IdKey keywords:
-
Unique — Defines a UNIQUE constraint on the properties listed in the index’s list of properties. That is, only a unique data value for this property (field) can be indexed. Uniqueness is determined based on the property’s collation. For example, if the property collation is EXACT, values that differ in letter case are unique; if the property collation is SQLUPPER, values that differ in letter case are not unique. However, note that the uniqueness of indexes is not checked for properties that are undefined. In accordance with the SQL standard, an undefined property is always treated as unique.
-
PrimaryKey — Defines a PRIMARY KEY constraint on the properties listed in the index’s list of properties.
-
IdKey — Defines a unique constraint and specifies which properties are used to define the unique identity of an instance (row). An IdKey always has EXACT collation, even when it is of data type string.
The syntax of such keywords appears in the following example:
Class MyApp.SampleTable Extends %Persistent [DdlAllowed]
{
Property Prop1 As %String;
Property Prop2 As %String;
Property Prop3 As %String;
Index Prop1IDX on Prop1 [ Unique ];
Index Prop2IDX on Prop2 [ PrimaryKey ];
Index Prop3IDX on Prop3 [ IdKey ];
}The IdKey, PrimaryKey, and Unique keywords are only valid with standard indexes. You cannot use them with bitmap or bitslice indexes.
It is also valid syntax to specify both the IdKey and PrimaryKey keywords together, such as:
Index IDPKIDX on Prop4 [ IdKey, PrimaryKey ];This syntax specifies that the IDPKIDX index is both the IdKey for the class (table), as well as its primary key. All other combinations of these keywords are redundant.
For any index defined with one of these keywords, there is a method that allows you to open the instance of the class where the properties associated with the index have particular values; for more information, see Opening an Instance by Index Key.
For more information on the IdKey keyword, see the IdKey page of the Class Definition Reference. For more information on the PrimaryKey keyword, see the PrimaryKey page of the Class Definition Reference. For more information on the Unique keyword, see the Unique page of the Class Definition Reference.
Storing Data with Indexes
You can specify that a copy of one or more data values be stored within an index using the index Data keyword:
Class Sample.Person Extends %Persistent [DdlAllowed]
{
Property Name As %String;
Property SSN As %String(MAXLEN=20);
Index NameIDX On Name [Data = Name];
}In this case, the index, NameIDX, is subscripted by the collated (uppercase) value of the various Name values. A copy of the actual (uncollated) value of the Name is stored within the index. These copies are maintained when changes are made to the Sample.Person table through SQL or to corresponding the Sample.Person class or its instances through objects.
Maintaining a copy of data along within an index can be helpful in cases where you frequently perform selective (selecting a few rows out of many) or ordered searches that return a few columns out of many.
For example, consider the following query against the Sample.Person table:
SELECT Name FROM Sample.Person ORDER BY NameThe SQL Engine could decide to satisfy this request entirely by reading from the NameIDX and never reading the master data for the table.
You cannot store data values with a bitmap index.
Indexing Collections
When a property is indexed, the value that is placed in the index is the entire collated property value. For collections, it is possible to define index properties that correspond to the element and key values of the collection by appending (ELEMENTS) or (KEYS) to the property name. (ELEMENTS) and (KEYS) allow you to specify that multiple values are produced from a single property value and each of these sub-values is indexed. When the property is a collection, then the ELEMENTS token references the elements of the collection by value and the KEYS token references them by position. When both ELEMENTS and KEYS are present in a single index definition. the index key value includes the key and associated element value.
For example, suppose there is an index based on FavoriteColors property of the Sample.Person class. The simplest form of an index on the items in this property’s collection would be either of:
INDEX fcIDX1 ON (FavoriteColors(ELEMENTS));or
INDEX fcIDX2 ON (FavoriteColors(KEYS));where FavoriteColors(ELEMENTS) refers to the elements of the FavoriteColors property and FavoriteColors(KEYS) refers to the keys of the FavoriteColors property. The general form is propertyName(ELEMENTS) or propertyName(KEYS), where that collection’s content is the set of elements contained in a property defined as a List Of or an Array Of some data type. For information on collections, see Working with Collections.
To index literal properties (described in Defining and Using Literal Properties), you can create an index value array as produced by a propertyNameBuildValueArray() method (described in the following section). As with collections proper, the (ELEMENTS) and (KEYS) syntax is valid with index value arrays.
If property-collection is projected as array, then the index must obey the following restrictions in order to be projected to the collection table. The index must include (KEYS). The index cannot reference any properties other than the collection itself and the object's ID value. If a projected index also defines DATA to be stored in the index, then the data properties stored must also be restricted to the collection and the ID. Otherwise the index is not projected. This restriction applies to an index on a collection property that is projected as an array; it does not apply to an index on a collection that is projected as a list. For further details, refer to Controlling the SQL Projection of Collection Properties.
Indexes that correspond to element or key values of a collection can also have all the standard index features, such as storing data with the index, index-specific collations, and so on.
InterSystems SQL can use a collection index by specifying the FOR SOME %ELEMENT predicate.
Indexing Data Type Properties with (ELEMENTS) and (KEYS)
For the purposes of indexing data type properties, you can also create index value arrays using the BuildValueArray() method. This method parses a property value into an array of keys and elements. It does this by producing a collection of element values derived from the value of the property with which it is associated. This method does not work on existing collection properties.
When you use BuildValueArray() to create an index value array, its structure is suitable for indexing.
The BuildValueArray() method has the name propertyNameBuildValueArray() and its signature is:
ClassMethod propertynameBuildValueArray(value, ByRef valueArray As %Library.String) As %Status
where
-
The name of the BuildValueArray() method derives from the property name in the typical way for composite methods.
-
The first argument is the property value.
-
The second argument is an array that is passed by reference. This is an array containing key-element pairs where the array subscripted by the key is equal to the element.
-
The method returns a %Status value.
Indexing Array Collections
To specify an index on an array collection property, you must include the keys in the index definition. For example:
Class MyApp.Branch Extends %Persistent [ DdlAllowed ]
{
Property Name As %String;
Property Employees As Array Of MyApp.Employee;
Index EmpIndex On (Employees(KEYS), Employees(ELEMENTS));
}These keys identify the RowID of the array element’s child table row. Without this key, the parent table does not project an index to the child table. Because this projection does not occur, INSERT operations into the parent table fail.
Indexing an Embedded Object (%SerialObject) Property
To index a property in an embedded object, you create an index in the persistent class referencing that embedded object. The property name must specify the name of the referencing field in the table (%Persistent class) and the property in the embedded object (%SerialObject), as shown in the following example:
Class Sample.Person Extends (%Persistent) [ DdlAllowed ]
{ Property Name As %String(MAXLEN=50);
Property Home As Sample.Address;
Index StateInx On Home.State;
} Here Home is a property in Sample.Person that references the embedded object Sample.Address, which contains the State property, as shown in the following example:
Class Sample.Address Extends (%SerialObject)
{ Property Street As %String;
Property City As %String;
Property State As %String;
Property PostalCode As %String;
}Only the data values in the instance of the embedded object associated with the persistent class property reference are indexed. You cannot index a %SerialObject property directly. The SqlCategory for %Library.SerialObject (and all sub-classes of %SerialObject that do not define the SqlCategory explicitly) is STRING.
You can also define an index on an embedded object property using the SQL CREATE INDEX statement, as shown in the following example:
CREATE INDEX StateIdx ON TABLE Sample.Person (Home_State)For more details, see Introduction to Serial Objects and Embedded Object (%SerialObject).
Summary of Index Types
InterSystems SQL provides a number of different index types that are useful in different circumstances. To optimize your schema, you should define the index that best serves your use case. The table below summarizes these index types; see the linked sections for further information about each type.
Note that adding any index increases both the amount of storage space a table takes up and the number of operations performed when updating or adding data.
| Index Type | Description | Field Types | Example Use Cases |
|---|---|---|---|
| Standard | Groups rows that share a value in a specific column | Any | Efficient for most circumstances |
| Bitmap |
For each unique value in a column, stores a bitstring that indicates which rows contain the value When a bitmap index is defined, a Bitmap Extent index is automatically created |
Numeric | Queries that use:
AND or OR for multiple conditions on a single table RANGE conditions |
| Bitmap Extent | An existence bitmap created automatically when a bitmap index is created or when a table is defined with CREATE TABLE | Numeric (see Bitmap) | Queries that use:
COUNT commands |
| Bitslice | Converts numeric values to binary and stores that binary value as a bitmap | Numeric | Queries that use: |
| Columnar | Stores a copy of the field’s data in a compressed, vectorized format | Numeric; short strings with low cardinality | Queries that use:
RANGE conditions |
Bitmap Indexes
A bitmap index is a special type of index that uses a series of bitstrings to represent the set of ID values that correspond to a given indexed data value.
Bitmap indexes have the following important features:
-
Bitmaps are highly compressed: bitmap indexes can be significantly smaller than standard indexes. This reduces disk and cache usage considerably.
-
Bitmaps operations are optimized for transaction processing: you can use bitmap indexes within tables with no performance penalty as compared with using standard indexes.
-
Logical operations on bitmaps (counting, AND, and OR) are optimized for high performance.
-
The SQL Engine includes a number of special optimizations that can take advantage of bitmap indexes.
The creation of bitmap indexes depends upon the nature of the table’s unique identity field(s):
-
If the table’s ID field is defined as a single field with positive integer values, you can define a bitmap index for a field using this ID field. This type of table either uses a system-assigned unique positive integer ID, or uses an IdKey to define custom ID values where the IdKey is based on a single property with type %Integer and MINVAL > 0, or type %Numeric with SCALE = 0 and MINVAL > 0.
-
If the table’s ID field is not defined as single field with positive integer values (for example, a child table), you can define a %BID (bitmap ID) field that takes positive integers which acts as a surrogate ID field; this allows you to create bitmap indexes for fields in this table.
Subject to the restrictions listed below, bitmap indexes operate in the same manner as standard indexes. Indexed values are collated and you can index on combinations of multiple fields.
This page addresses the following topics related to bitmap indexes:
Bitmap Index Operation
Bitmap indexes work in the following way. Suppose you have a Person table containing a number of columns:
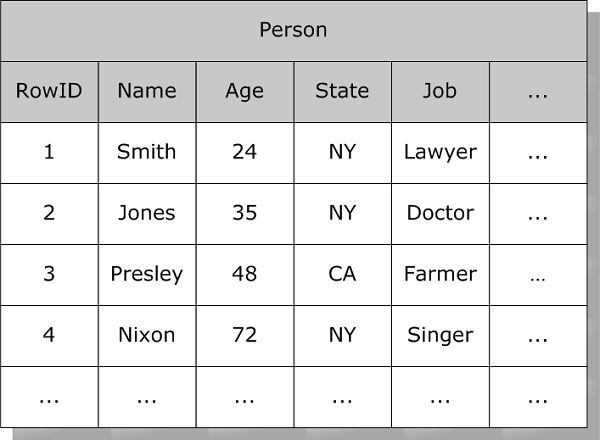
Each row in this table has a system-assigned RowID number (a set of increasing integer values). A bitmap index uses a set of bitstrings (a string containing 1 and 0 values). Within a bitstring, the ordinal position of a bit corresponds to the RowID of the indexed table. For a given value, say where State is “NY”, there is a string of bits with a 1 for every position that corresponds to a row containing “NY” and a 0 in every other position.
For example, a bitmap index on State might look like this:
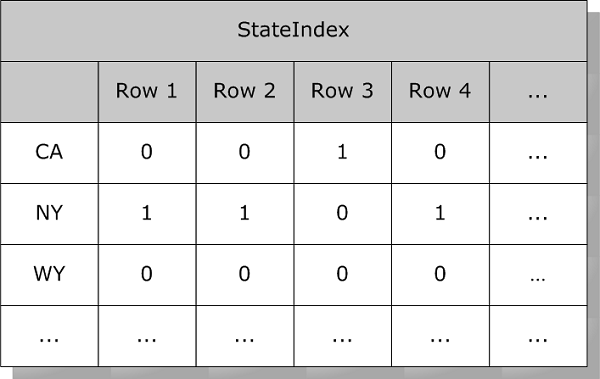
While an index on Age might look like this:
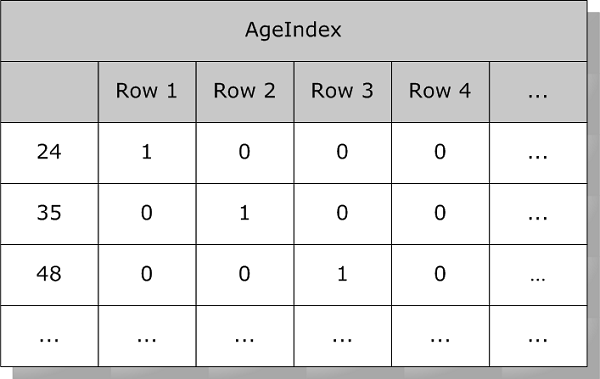
The Age field shown here can be an ordinary data field or a field whose value can be reliably derived (Calculated and SQLComputed).
In addition to using bitmap indexes for standard operations, the SQL engine can use bitmap indexes to efficiently perform special set-based operations using combinations of multiple indexes. For example, to find all instances of Person that are 24 years old and live in New York, the SQL Engine can simply perform the logical AND of the Age and State indexes:
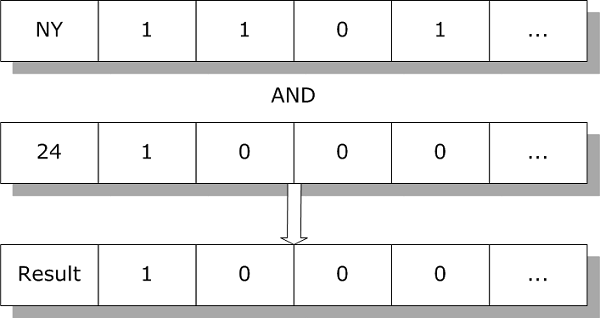
The resulting bitmap contains the set of all rows that match the search criteria. The SQL Engine uses this to return data from these rows.
The SQL Engine can use bitmap indexes for the following operations:
-
ANDing of multiple conditions on a given table.
-
ORing of multiple conditions on a given table.
-
RANGE conditions on a given table.
-
COUNT operations on a given table.
Defining Bitmap Indexes Using DDL
If you are using DDL statements to define tables, you can also use the following DDL commands to create and remove bitmap indexes for a table with a positive integer ID:
This is identical to creating standard indexes, except that you must add the BITMAP keyword to the CREATE INDEX statement:
CREATE BITMAP INDEX RegionIDX ON TABLE MyApp.SalesPerson (Region)Defining an IdKey Bitmap Index Using a Class Definition
If the table’s ID is a field with values restricted to unique positive integers, you can add bitmap index definitions to a class definition using either the New Index Wizard or by editing the text of the class definition in the same way that you would create a standard index. The only difference is that you need to specify the index Type as being “bitmap”:
Class MyApp.SalesPerson Extends %Persistent [DdlAllowed]
{
Property Name As %String;
Property Region As %Integer;
Index RegionIDX On Region [Type = bitmap];
}Defining a %BID Bitmap Index Using a Class Definition
If the table’s ID is not restricted to positive integers, you can create a %BID field to use to create bitmap index definitions. You can use this option for a table with an ID field of any datatype, as well as an IDKEY consisting of multiple fields (which includes child tables). A %BID bitmap can be created for either data storage type: a default structure table or a %Storage.SQL table. This feature is referred to as “Bitmaps for Any Table,” or BAT.
To enable use of bitmap indexes on such a table, you must do the following:
-
Define the %BID field, or identify an existing field as the %BID field. The data type of this field must restrict values to unique positive integers. For example, in this table, the IDKey is a composite of two fields that are not restricted to positive integers. This makes the MyBID field, which has a positive integer data type (%Counter) a candidate for the %BID field.
Class MyTable Extends %Persistent [ DdlAllowed ] { Property IdField1 As %Integer; Property IdField2 As %Integer; Property MyBID As %Counter; /* %BID Field */ Index IDIdx On (IdField1, IdField2) [ IdKey, Unique ]; } -
Define the BIDField class parameter to identify the %BID field for the SQL compiler. Set its value to the SQLFieldName of the %BID field. For example:
Class MyTable Extends %Persistent [ DdlAllowed ] { Parameter BIDField = "MyBID"; /* BIDField Class Parameter */ Property IdField1 As %Integer; Property IdField2 As %Integer; Property MyBID As %Counter; Index IDIdx On (IdField1, IdField2) [ IdKey, Unique ]; } -
Define the BATKey index. This index acts as the master map and data map for the SQL query processor. Typically, the %BID field is the first subscript of the BATKey index. The map data can then include the IDKEY fields and any additional properties that you want to have the fastest access to. You must set the index on the %BID field. For example:
Class MyTable Extends %Persistent [ DdlAllowed ] { Parameter BIDField = "MyBID"; Property IdField1 As %Integer; Property IdField2 As %Integer; Property MyBID As %Counter; Index MyBATKey On MyBID [ Type = key, Unique ]; /* BATKey Index */ Index IDIdx On (IdField1, IdField2) [ IdKey, Unique ]; } -
Define the BATKey class parameter identify the BATKey index for the SQL compiler. Set its value to the SQLFieldName of the BATKey index. For example:
Class MyTable Extends %Persistent [ DdlAllowed ] { Parameter BIDField = "MyBID"; Parameter BATKey = "MyBATKey"; /* BATKey Class Parameter */ Property IdField1 As %Integer; Property IdField2 As %Integer; Property MyBID As %Counter; Index MyBATKey On MyBID [ Type = key, Unique ]; Index IDIdx On (IdField1, IdField2) [ IdKey, Unique ]; } -
Define the %BID locator index, or identify an existing index as the %BID locator index. This index ties the %BID index to the IDKey fields of the table. For example:
Class MyTable Extends %Persistent [ DdlAllowed ] { Parameter BIDField = "MyBID"; Parameter BATKey = "MyBATKey"; Property IdField1 As %Integer; Property IdField2 As %Integer; Property MyBID As %Counter; Index MyBATKey On MyBID [ Type = key, Unique ]; Index IDIdx On (IdField1, IdField2) [ IdKey, Unique ]; Index BIDLocIdx On (IdField1, IdField2, MyBID) [ Unique ]; /* %BID Locator Index */ }
This table now supports bitmap indexes. You can define bitmap indexes as needed using standard syntax. For example: Index RegionIDX On Region [Type = bitmap];
Tables created in this way also support bitslice indexes, which can also be defined using standard syntax.
Generating a Bitmap Extent Index
A bitmap index requires a bitmap extent index. Defining a persistent class only generates a bitmap extent index if one or more bitmap indexes are defined. Therefore, when compiling a persistent class that contains a bitmap index, the class compiler generates a bitmap extent index if no bitmap extent index is defined for that class. Tables defined with the CREATE TABLE DDL statement automatically generate a bitmap extent index.
If you delete all bitmap indexes from the persistent class definition, the bitmap extent index is automatically deleted. However, if you rename the bitmap extent index (for example, using the CREATE BITMAPEXTENT INDEX command) deleting the bitmap index does not delete the bitmap extent index.
When building indexes for a class, the bitmap extent index is built either if you explicitly build the bitmap extent index, or if you build a bitmap index and the bitmap extent index is empty.
A class inherits its bitmap extent index from the primary superclass if it exists, either defined or generated. A bitmap extent index inherited from a primary superclass is considered to be a bitmap index and will trigger a bitmap extent index to be generated in the subclass, if no bitmap extent index is explicitly defined in that subclass.A bitmap extent index is defined as follows:
Class Test.Index Extends %Registered Object
{
Property Data As %Integer [ InitialExpression = {$RANDOM(100000)}];
Index DataIndex On Data [ Type = bitmap ];
Index ExtentIndex [ Extent, Type = bitmap ];
}
InterSystems IRIS does not generate a bitmap extent index in a superclass based on future possibility. This means that InterSystems IRIS does not ever generate a bitmap extent index in a persistent class unless an index whose type = bitmap is present. A presumption that some future subclass might introduce an index with type = bitmap is not sufficient.
Special care is required during the process of adding a bitmap index to a class on a production system (where users are actively using a particular class, compiling said class, and subsequently building the bitmap index structure for it). On such a system, the bitmap extent index may be populated in the interim between the compile completing and the index build proceeding. This can cause the index build procedure to not implicitly build the bitmap extent index, which leads to a partially complete bitmap extent index.
Choosing an Index Type
The following is a general guideline for choosing between bitmap and standard indexes. In general, use standard indexes for indexing on all types of keys and references:
-
Primary key
-
Foreign key
-
Unique keys
-
Relationships
-
Simple object references
Otherwise, bitmap indexes are generally preferable (assuming that the table uses system-assigned numeric ID numbers).
Other factors:
-
Separate bitmap indexes on each property usually have better performance than a bitmap index on multiple properties. This is because the SQL engine can efficiently combine separate bitmap indexes using AND and OR operations.
-
If a property (or a set of properties that you really need to index together) has more than 10,000-20,000 distinct values (or value combinations), consider standard indexes. If, however, these values are very unevenly distributed so that a small number of values accounts for a substantial fraction of rows, then a bitmap index could be much better. In general, the goal is to reduce the overall size required by the index.
Restrictions on Bitmap Indexes
All bitmap indexes have the following restrictions:
-
You cannot define a bitmap index on a UNIQUE column.
-
You cannot store data values within a bitmap index.
-
You cannot define a bitmap index on a field unless the SqlCategory of the ID field is INTEGER, DATE, POSIXTIME, or NUMERIC (with scale=0).
-
For a table containing more than 1 million records, a bitmap index is less efficient than a standard index when the number of unique values exceeds 10,000. Therefore, for a large table it is recommended that you avoid using a bitmap index for any field that contains (or is likely to contain) more than 10,000 unique values; for a table of any size, avoid using a bitmap index for any field that is likely to contain more than 20,000 unique values. These are general approximations, not exact numbers.
You must create a %BID property to support bitmap indexes on a table that:
-
Uses a non-integer field as the unique ID key.
-
Uses a multi-field ID key.
-
Is a child table within a parent-child relationship.
You can use the $SYSTEM.SQL.Util.SetOption()Opens in a new tab method SET status=$SYSTEM.SQL.Util.SetOption("BitmapFriendlyCheck",1,.oldval) to set a system-wide configuration parameter to check at compile time for this restriction, determining whether a defined bitmap index is allowed in a %Storage.SQL class. This check only applies to classes that use %Storage.SQL. The default is 0. You can use $SYSTEM.SQL.Util.GetOption("BitmapFriendlyCheck")Opens in a new tab to determine the current configuration of this option.
Application Logic Restrictions
A bitmap structure can be represented by an array of bit strings, where each element of the array represents a "chunk" with a fixed number of bits. Because undefined is equivalent to a chunk with all 0 bits, the array can be sparse. An array element that represents a chunk of all 0 bits need not exist at all. For this reason, application logic should avoid depending on the $BITCOUNT(str,0) count of 0-valued bits.
Because a bit string contains internal formatting, application logic should never depend upon the physical length of a bit string or upon equating two bit strings that have the same bit values. Following a rollback operation, a bit string is restored to its bit values prior to the transaction. However, because of internal formatting, the rolled back bit string may not equate to or have the same physical length as the bit string prior to the transaction.
Maintaining Bitmap Indexes
In a volatile table (one that undergoes many INSERT and DELETE operations) the storage for a bitmap index can gradually become less efficient. To maintain bitmap indexes, you can run the %SYS.Maint.BitmapOpens in a new tab utility methods to compress the bitmap indexes, restoring them to optimal efficiency. You can use the OneClass()Opens in a new tab method to compress the bitmap indexes for a single class or the Namespace()Opens in a new tab method to compress the bitmap indexes for an entire namespace. These maintenance methods can be run on a live system.
The results of running the %SYS.Maint.BitmapOpens in a new tab utility methods are written to the process that invoked the method. These results are also written to the class %SYS.Maint.BitmapResultsOpens in a new tab.
SQL Manipulation of Bitmap Chunks
InterSystems SQL provides the following extensions to directly manipulate bitmap indexes:
-
%CHUNK function
-
%BITPOS function
-
%BITMAP aggregate function
-
%BITMAPCHUNK aggregate function
-
%SETINCHUNK predicate condition
All of these extensions follow the InterSystems SQL conventions for bitmap representation, representing a set of positive integers as a sequence of bitmap chunks, of up to 64,000 integers each.
These extensions enable easier and more efficient manipulation of certain conditions and filters, both within a query and in embedded SQL. In embedded SQL they enable simple input and output of bitmaps, especially at the single chunk level. They support the processing of complete bitmaps, which are handled by %BITMAP() and the %SQL.Bitmap class. They also enable bitmap processing for non-RowID values, such as foreign key values, parent-reference of a child table, either column of an association, etc.
For example, to output the bitmap for a specified chunk:
SELECT %BITMAPCHUNK(Home_Zip) FROM Sample.Person
WHERE %CHUNK(Home_Zip)=2To output all the chunks for the whole table:
SELECT %CHUNK(Home_Zip),%BITMAPCHUNK(Home_Zip) FROM Sample.Person
GROUP BY %CHUNK(Home_Zip) ORDER BY 1%CHUNK function
%CHUNK(f) returns the chunk assignment for a bitmap indexed field f value. This is calculated as f\64000+1. %CHUNK(f) for any field or value f that is not a bitmap indexed field always returns 1.
%BITPOS function
%BITPOS(f) returns the bit position assigned to a bitmap indexed field f value within its chunk. This is calculated as f#64000+1 . %BITPOS(f) for any field or value f that is not a bitmap indexed field returns 1 more than its integer value. A string has an integer value of 0.
%BITMAP aggregate function
The aggregate function %BITMAP(f) combines many f values into a %SQL.Bitmap object, in which the bit corresponding to f in the proper chunk is set to 1 for each value f in the result set. f in all of the above would normally be a positive integer field (or expression), usually (but not necessarily) the RowID.
%BITMAPCHUNK aggregate function
The aggregate function %BITMAPCHUNK(f) combines many values of the field f into an InterSystems SQL standard bitmap string of 64,000 bits, in which bit f#64000+1=%BITPOS(f) is set to 1 for each value f in the set. Note that the bit is set in the result regardless of the value of %CHUNK(f) . %BITMAPCHUNK() yields NULL for the empty set, and like any other aggregate it ignores NULL values in the input.
%SETINCHUNK predicate condition
The condition (f %SETINCHUNK bm) is true if and only if ($BIT(bm,%BITPOS(f))=1) . bm could be any bitmap expression string, e.g. an input host variable :bm, or the result of a %BITMAPCHUNK() aggregate function, etc. Note that the <bm> bit is checked regardless of the value of %CHUNK(f) . If <bm> is not a bitmap or is NULL, the condition returns FALSE. (f %SETINCHUNK NULL) yields FALSE (not UNKNOWN).
Bitslice Indexes
A bitslice index is used for a numeric data field when that field is used for certain numeric operations. A bitslice index represents each numeric data value as a binary bit string. Rather than indexing a numeric data value using a boolean flag (as in a bitmap index), a bitslice index represents each value in binary and creates a bitmap for each digit in the binary value to record which rows have a 1 for that binary digit. This is a highly specialized type of index that can substantially improve performance of the following operations:
-
SUM, COUNT, or AVG aggregate calculations. (A bitslice index is not used for COUNT(*) calculations.) Bitslice indexes are not used for other aggregate functions.
-
A field specified in a TOP n ... ORDER BY field operation.
-
A field specified in a range condition operation, such as WHERE field > n or WHERE field BETWEEN lownum AND highnum.
The SQL optimizer determines whether a defined bitslice index should be used. Commonly, the optimizer only uses a bitslice index when a substantial number of rows (thousands) are being processed.
You can create a bitslice index for a string data field, but the bitslice index will represent these data values as canonical numbers. In other words, any non-numeric string, such as “abc” will be indexed as 0. This type of bitslice index could be used to rapidly COUNT records that have a value for a string field and not count those that are NULL.
In the following example, Salary would be a candidate for a bitslice index:
SELECT AVG(Salary) FROM SalesPersonA bitslice index can be used for an aggregate calculation in a query that uses a WHERE clause. This is most effective if the WHERE clause is inclusive of a large number of records. In the following example, the SQL optimizer would probably use a bitslice index on Salary, if defined; if so, it would also use a bitmap index on Region, either using a defined bitmap or generating a bitmap tempfile for Region:
SELECT AVG(Salary) FROM SalesPerson WHERE Region=2However, a bitslice index is not used when the WHERE condition cannot be satisfied by an index, but must be performed by reading the table that contains the field being aggregated. The following example would not use the bitslice index on Salary:
SELECT AVG(Salary) FROM SalesPerson WHERE Name LIKE '%Mc%'A bitslice index can be defined for any field containing numeric values. InterSystems SQL uses a scale parameter to convert fractional numbers into bitstrings, as described in the ObjectScript $FACTOR function. A bitslice index can be defined for a field of data type string; in this case, non-numeric string data values are treated as 0 for the purposes of the bitslice index.
A bitslice index can be defined for fields in a table that has system-assigned row Ids with positive integer values, or a table defined with a %BID property to support bitmap (and bitslice) indexes.
A bitslice index can only be defined for a single field name, not a concatenation of multiple fields. You cannot specify a WITH DATA clause.
The following example compares a bitslice index to a bitmap index. If you create a bitmap index for values 1, 5, and 22 for rows 1, 2, and 3, it creates an index for the values:
^gloI("bitmap",1,1)= "100"
^gloI("bitmap",5,1)= "010"
^gloI("bitmap",22,1)="001"
If you create a bitslice index for values 1, 5, and 22 for rows 1, 2, and 3, it first converts the values to bit values:
1 = 00001 5 = 00101 22 = 10110
It then creates an index for the bits:
^gloI("bitslice",1,1)="110"
^gloI("bitslice",2,1)="001"
^gloI("bitslice",3,1)="011"
^gloI("bitslice",4,1)="000"
^gloI("bitslice",5,1)="001"
In this example, the value 22 in a bitmap index required setting 1 global node; the value 22 in a bitslice index required setting 3 global nodes.
Note that an INSERT or UPDATE requires setting a bit in all n bitslices, rather than setting a single bitstring. These additional global set operations can affect performance of INSERT and UPDATE operations that involve populating bitslice indexes. Populating and maintaining a bitslice index using INSERT, UPDATE, or DELETE operations is slower than populating a bitmap index or a regular index. Maintaining multiple bitslice indexes, and/or maintaining a bitslice index on a field that is frequently updated may have a significant performance cost.
In a volatile table (one that undergoes many INSERT, UPDATE, and DELETE operations) the storage for a bitslice index can gradually become less efficient. The %SYS.Maint.BitmapOpens in a new tab utility methods compress both bitmap indexes and bitslice indexes, restoring efficiency. For further details, see Maintaining Bitmap Indexes.
Columnar Indexes
A columnar index is used for a field that is frequently queried but whose table has an underlying row storage structure. By default, each row of a table is stored as a $LIST in a separate global subscript. A columnar index stores data for a specific field in a compressed, vectorized format.
To define a columnar index using InterSystems SQL DDL, use the CREATE COLUMNAR INDEX syntax of CREATE INDEX:
CREATE COLUMNAR INDEX indexName ON table(column)
To define a columnar index in a persistent class, specify the type = columnar keyword on the index you define:
Index indexName ON propertyName [ type = columnar ]
This sample DDL shows how to define a columnar index on a specific column in a table:
CREATE TABLE Sample.BankTransaction (
AccountNumber INTEGER,
TransactionDate DATE,
Description VARCHAR(100),
Amount NUMERIC(10,2),
Type VARCHAR(10))
CREATE COLUMNAR INDEX AmountIndex
ON Sample.BankTransaction(Amount)
Suppose you are performing an AVG aggregate calculation on the Amount column of this table and filtering the result to include only deposit amounts.
SELECT AVG(Amount) FROM Sample.BankTransaction WHERE Type = 'Deposit'This calculation requires loading each $LIST global into memory when you need only a subset of rows (WHERE Type = 'Deposit') for a single column (Amount). Performing an AVG calculation on a field with a columnar index, the query plan accesses this information from the index rather than directly from the $LIST globals.
A columnar index may not be defined on a serial property or subclass. However, you may define an index on a non-serial property of a subclass, such as an %Integer.
A columnar index is similar to a bitmap index but is slightly less efficient for equality conditions. The bitmap index already has the bitstrings for each value, whereas a columnar index takes a vectorized operation to get them from the columnar index. A columnar index is often more efficient for range conditions. With a bitmap index, multiple bitstrings need to be combined, whereas in a columnar index, the same computation can be carried it in a single vectorized operation.
For more details on columnar indexes and defining table storage layouts, see Choose an SQL Table Storage Layout.
Building Indexes
You can build/re-build indexes as follows:
-
Using the BUILD INDEX SQL command to build specified indexes, or build all indexes defined for a table, a schema, or the current namespace. For live systems, InterSystems recommends using this option.
-
Using the Management Portal to rebuild all of the indexes for a specified class (table).
-
Using the %BuildIndices() (or %BuildIndicesAsync()) method.
The preferred way of building indexes systems is to use the BUILD INDEX SQL command. Building an index does the following:
-
Removes the current contents of the index.
-
Scans (reads every row) of the main table and adds index entries for each row in the table. As appropriate, low-level optimizations with respect to parallel execution and efficient batch sorting are applied using $SortBegin and $SortEnd.
If you use BUILD INDEX on a live system, the index is temporarily labeled as not selectable, meaning that queries cannot use the index while it is being built. Note that this will impact the performance of queries that use the index.
Building Indexes with BUILD INDEX
After creating an index at the class or DDL level, you should build it using the BUILD INDEX command. This statement can be used to build all of the indexes in a namespace, all the indexes in a schema, or only the indexes specified in the command. By default, it acquires an extent lock on each table prior to building its indexes and releases it when it has finished, making it safe to use on an active system. Queries will not be able to use an index while it is being built. Any data that is inserted or updated in the table using the INSERT or UPDATE commands while the BUILD INDEX command is running will be included in the building process.
BUILD INDEX uses the journaling setting for the current process to log any errors. You can turn off locking and journaling behavior by supplying the %NOLOCK and %NOJOURN options, respectively.
The following examples build indexes for the MyApp.Salesperson class:
BUILD INDEX FOR TABLE MyApp.SalesPerson
BUILD INDEX FOR TABLE MyApp.SalesPerson INDEX NameIdx, SSNKey
The first statement builds all of the indexes for the specified table (or class) name. The second statement builds only the NameIdx and SSNKey indexes.
Building Indexes with the Management Portal
You can build existing indexes (rebuild indexes) for a table by doing the following:
-
From the Management Portal select System Explorer, then SQL. Select a namespace by clicking the name of the current namespace at the top of the page; this displays the list of available namespaces. After selecting a namespace, select the Schema drop-down list on the left side of the screen. This displays a list of the schemas in the current namespace with boolean flags indicating whether there are any tables or any views associated with each schema.
-
Select a schema from this list; it appears in the Schema box. Just above it is a drop-down list that allows you to select Tables, System Tables, Views, Procedures, or All of these that belong to the schema. Select either Tables or All, then open the Tables folder to list the tables in this schema. If there are no tables, opening the folder displays a blank page. (If you have not selected Tables or All, opening the Tables folder lists the tables for the entire namespace.)
-
Select one of the listed Tables. This displays the Catalog Details for the table.
-
To rebuild all indexes: click the Actions drop-down list and select Rebuild Table’s Indices.
-
To rebuild a single index: click the Indices button to display the existing indexes. Each listed index has the option to Rebuild Index.
-
Building Indexes Programmatically
You can also use the %BuildIndices() and %BuildIndicesAsync() methods provided by the %PersistentOpens in a new tab class for the table to build indexes. Note that these methods are only provided for classes that use InterSystems IRIS default storage structure. Calling these methods requires that at least one index definition has been added to a specified class and compiled. Read about the methods more fully in the class reference pages linked below.
-
%Library.Persistent.%BuildIndices()Opens in a new tab: %BuildIndices() executes as a background process but the caller has to wait for %BuildIndices() to complete before receiving control back.
-
%Library.Persistent.%BuildIndicesAsync()Opens in a new tab: %BuildIndicesAsync() initiates %BuildIndices() as a background process and the caller immediately receives control back. The first argument to %BuildIndicesAsync() is the queueToken output argument. The remaining arguments are the same as %BuildIndices().
Index Validation
You can validate indexes using the either of the following methods:
-
$SYSTEM.OBJ.ValidateIndices()Opens in a new tab validates the indexes for a table, and also validates any indexes in collection child tables for that table.
-
%Library.Storage.%ValidateIndices()Opens in a new tab validates the indexes for a table. Collection child table indexes must be validated with separate %ValidateIndices() calls.
Both methods check the data integrity of one or more indexes for a specified table, and optionally correct any index integrity issues found. They perform index validation in two steps:
-
Confirm that an index entity is properly defined for every row (object) in the table (class).
-
Traverse each index and for every entry indexed, make sure there is a value and matching entry in the table (class).
If either method finds discrepancies, it can optionally correct the index structure and/or contents. It can validate, and optionally correct, standard indexes, bitmap indexes, bitmap extent indexes, and bitslice indexes. By default, both methods validate indexes, but do not correct indexes.
%ValidateIndices() can only be used to correct an index on a READ and WRITE active system if SetMapSelectability()Opens in a new tab is used and the %ValidateIndices() arguments include both autoCorrect=1 and lockOption>0. Because %ValidateIndices() is significantly slower, %BuildIndices() is the preferred method for building indexes on an active system.
%ValidateIndices() is commonly run from the Terminal. It displays output to the current device. This method can be applied to a specified %List of index names, or to all indexes defined for the specified table (class). It operates only on those indexes that originated in specified class; if an index originated in a superclass, that index can be validated by calling %ValidateIndices() on the superclass. It is not supported for READONLY classes.
Validating Indexes on Sharded Classes
%ValidateIndices() is supported for sharded classes and for shard-master class tables (Sharded=1). You can invoke %ValidateIndices, either directly as a class method, or from $SYSTEM.OBJ.ValidateIndices on the shard master class. Index validation is then performed on the shard local class on each shard, and the results are returned to the caller on the shard master. When using %ValidateIndices() on a sharded class, the verbose flag is forced to 0. There is no output to the current device. Any issues found/corrected are returned in the byreference errors() array.
Using Indexes in Query Processing
Indexing provides a mechanism for optimizing queries by maintaining a sorted subset of commonly requested data. Determining which fields should be indexed requires some thought: too few or the wrong indexes and key queries will run too slowly; too many indexes can slow down INSERT and UPDATE performance (as the index values must be set or updated).
What to Index
To determine if adding an index improves query performance, run the query from the Management Portal SQL interface and note in Performance the number of global references. Add the index and then rerun the query, noting the number of global references. A useful index should reduce the number of global references. You can prevent use of an index by using the %NOINDEX keyword as preface to a WHERE clause or ON clause condition.
You should index fields (properties) that are specified in a JOIN. A LEFT OUTER JOIN starts with the left table, and then looks into the right table; therefore, you should index the field from the right table. In the following example, you should index T2.f2:
FROM Table1 AS T1 LEFT OUTER JOIN Table2 AS T2 ON T1.f1 = T2.f2
An INNER JOIN should have indexes on both ON clause fields.
Run Show Plan and follow to the first map. If the first bullet item in the Query Plan is “Read master map”, or the Query Plan calls a module whose first bullet item is “Read master map”, the query first map is the master map rather than an index map. Because the master map reads the data itself, rather than an index to the data, this almost always indicates an inefficient Query Plan. Unless the table is relatively small, you should create an index so that when you rerun this query the Query Plan first map says “Read index map.”
You should index fields that are specified in a WHERE clause equal condition.
You may wish to index fields that are specified in a WHERE clause range condition, and fields specified in GROUP BY and ORDER BY clauses.
Under certain circumstances, an index based on a range condition could make a query slower. This can occur if the vast majority of the rows meet the specified range condition. For example, if the query clause WHERE Date < CURRENT_DATE is used with a database in which most of the records are from prior dates, indexing on Date may actually slow down the query. This is because the Query Optimizer assumes range conditions will return a relatively small number of rows, and optimizes for this situation. You can determine if this is occurring by prefacing the range condition with %NOINDEX and then run the query again.
If you are performing a comparison using an indexed field, the field as specified in the comparison should have the same collation type as it has in the corresponding index. For example, the Name field in the WHERE clause of a SELECT or in the ON clause of a JOIN should have the same collation as the index defined for the Name field. If there is a mismatch between the field collation and the index collation, the index may be less effective or may not be used at all. For further details, refer to Index Collation.
For details on how to create an index and the available index types and options, refer to the CREATE INDEX command, and Defining and Building Indexes.
Index Configuration Options
The following system-wide configuration methods can be used to optimize use of indexes in queries:
-
To use the PRIMARY KEY as the IDKey index, set the $SYSTEM.SQL.Util.SetOption()Opens in a new tab method, as follows: SET status=$SYSTEM.SQL.Util.SetOption("DDLPKeyNotIDKey",0,.oldval). The default is 1.
-
To use indexes for SELECT DISTINCT queries set the $SYSTEM.SQL.Util.SetOption()Opens in a new tab method, as follows: SET status=$SYSTEM.SQL.Util.SetOption("FastDistinct",1,.oldval). The default is 1.
For further details, refer to SQL and Object Settings Pages listed in System Administration Guide.
Using %ALLINDEX, %IGNOREINDEX, and %NOINDEX
The FROM clause supports the %ALLINDEX and %IGNOREINDEX optimize-option keywords as hints. These optimize-option keywords govern all index use in the query.
You can use the %NOINDEX condition-level hint to specify exceptions to the use of an index for a specific condition. The %NOINDEX hint is placed in front of each condition for which no index should be used. For example, WHERE %NOINDEX hiredate < ?. This is most commonly used when the overwhelming majority of the data is selected (or not selected) by the condition. With a less-than (<) or greater-than (>) condition, use of the %NOINDEX condition-level hint is often beneficial. With an equality condition, use of the %NOINDEX condition-level hint provides no benefit. With a join condition, %NOINDEX is supported for ON clause joins.
The %NOINDEX keyword can be used to override indexing optimization established in the FROM clause. In the following example, the %ALLINDEX optimization keyword applies to all condition tests except the E.Age condition:
SELECT P.Name,P.Age,E.Name,E.Age
FROM %ALLINDEX Sample.Person AS P LEFT OUTER JOIN Sample.Employee AS E
ON P.Name=E.Name
WHERE P.Age > 21 AND %NOINDEX E.Age < 65Analyzing Index Usage
There are two tools you can use to analyze the usage of indexes you have defined by SQL cached queries.
-
The Management Portal Index Analyzer SQL performance tool.
-
The %SYS.PTools.UtilSQLAnalysisOpens in a new tab methods indexUsage()Opens in a new tab, tableScans()Opens in a new tab, tempIndices()Opens in a new tab, joinIndices()Opens in a new tab, and outlierIndices()Opens in a new tab.
Index Analyzer
You can analyze index usage for SQL queries from the Management Portal using either of the following:
-
Select System Explorer, select Tools, select SQL Performance Tools, then select Index Analyzer.
-
Select System Explorer, select SQL, then from the Tools drop-down menu select Index Analyzer.
The Index Analyzer provides an SQL Statement Count display for the current namespace, and five index analysis report options.
SQL Statement Count
At the top of the SQL Index Analyzer there is an option to count all SQL statements in the namespace. Press the Gather SQL Statements button. The SQL Index Analyzer displays “Gathering SQL statements ....” while the count is in progress, then “Done!” when the count is complete. SQL statements are counted in three categories: a Cached Query count, a Class Method count, and a Class Query count. These counts are for the entire current namespace, and are not affected by the Schema Selection option. The corresponding method is getSQLStmts()Opens in a new tab in the %SYS.PTools.UtilSQLAnalysisOpens in a new tab class.
You can use the Purge Statements button to delete all gathered statements in the current namespace. This button invokes the clearSQLStatements()Opens in a new tab method.
Report Options
You can either examine reports for the cached queries for a selected schema in the current namespace, or (by not selecting a schema) examine reports for all cached queries in the current namespace. You can skip or include system class queries, INSERT statements, and/or IDKEY indexes in this analysis. The schema selection and skip option check boxes are user customized.
The index analysis report options are:
-
Index Usage: This option takes all of the cached queries in the current namespace, generates a Show Plan for each and keeps a count of how many times each index is used by each query and the total usage for each index by all queries in the namespace. This can be used to reveal indexes that are not being used so they can either be removed or modified to make them more useful. The result set is ordered from least used index to most used index.
-
Queries with Table Scans: This option identifies all queries in the current namespace that do table scans. Table scans should be avoided if possible. A table scan can’t always be avoided, but if a table has a large number of table scans, the indexes defined for that table should be reviewed. Often the list of table scans and the list of temp indexes will overlap; fixing one will remove the other. The result set lists the tables from largest Block Count to smallest Block Count. A Show Plan link is provided to display the Statement Text and Query Plan.
-
Queries with Temp Indices: This option identifies all queries in the current namespace that build temporary indexes to resolve the SQL. Sometimes the use of a temp index is helpful and improves performance, for example building a small index based on a range condition that InterSystems IRIS can then use to read the in order. Sometimes a temp index is simply a subset of a different index and might be very efficient. Other times a temporary index degrades performance, for example scanning the master map to build a temporary index on a property that has a condition. This situation indicates that a needed index is missing; you should add an index to the class that matches the temporary index. The result set lists the tables from largest Block Count to smallest Block Count. A Show Plan link is provided to display the Statement Text and Query Plan.
-
Queries with Missing JOIN Indices: This option examines all queries in the current namespace that have joins, and determines if there is an index defined to support that join. It ranks the indexes available to support the joins from 0 (no index present) to 4 (index fully supports the join). Outer joins require an index in one direction. Inner joins require an index in both directions. By default, the result set only contains rows that have a JoinIndexFlag < 4. JoinIndexFlag=4 means there is an index that fully supports the join.
-
Queries with Outlier Indices: This option identifies all queries in the current namespace that have outliers, and determines if there is an index defined to support that outlier. It ranks the indexes available to support the outlier from 0 (no index present) to 4 (index fully supports the outlier). By default, the result set only contains rows that have a OutlierIndexFlag < 4. OutlierIndexFlag=4 means there is an index that fully supports the outlier.
When you select one of these options, the system automatically performs the operation and displays the results. The first time you select an option or invoke the corresponding method, the system generates the results data; if you select that option or invoke that method again, InterSystems IRIS redisplays the same results. To generate new results data you must use the Gather SQL Statements button to reinitialize the Index Analyzer results tables. Changing the Skip all system classes and routines or Skip INSERT statements check box option also reinitializes the Index Analyzer results tables. To generate new results data for the %SYS.PTools.UtilSQLAnalysisOpens in a new tab methods, you must invoke getSQLStmts()Opens in a new tab to reinitialize the Index Analyzer results tables.
Listing Indexes
The INFORMATION.SCHEMA.INDEXESOpens in a new tab persistent class displays information about all column indexes in the current namespace. It returns one record for each indexed column. It provides a number of index properties, including the name of the index, table name, and column name that the index maps to. Each column record also provides the ordinal position of that column in the index map; this value is 1 unless the index maps to multiple columns. It also provides the boolean properties PRIMARYKEY and NONUNIQUE (0=index value must be unique).
The following example returns one row for each column that participates in an index for all non-system indexes in the current namespace:
SELECT Index_Name,Table_Schema,Table_Name,Column_Name,Ordinal_Position,
Primary_Key,Non_Unique
FROM INFORMATION_SCHEMA.INDEXES WHERE NOT Table_Schema %STARTSWITH '%'You can list indexes for a selected table using the Management Portal SQL interface Catalog Details Maps/Indices option. This displays one line for each index, and displays index information not provided by INFORMATION.SCHEMA.INDEXESOpens in a new tab.
Open, Exists, and Delete Methods
The InterSystems IRIS indexing facility supports the following operations:
-
Opening an Instance by Index Key
-
Checking If an Instance Exists
-
Deleting an Instance
Opening an Instance by Index Key
For ID key, primary key, or unique indexes, the indexnameOpen() method (where indexname is the name of the index) allows you to open the object whose index property value or values match supplied value or values. Because this method has one argument corresponding to each property in the index, the method has three or more arguments:
-
The first argument(s) each correspond to the properties in the index. This collation of this argument must match the collation of data stored in the index; if the collation does not match, the system fails to open the object. Data is by default stored with SQLUPPER collation. Use $ZCONVERT to set the proper collation.
-
The penultimate argument specifies the concurrency value with which the object is to be opened (with the available concurrency settings listed in Object Concurrency).
-
The final argument can accept a %Status code, in case the method fails to open an instance.
The method returns an OREF if it locates a matching instance.
For example, suppose that a class includes the following index definition:
Index SSNKey On SSN [ Unique ];then, if the referenced object has been stored to disk and has a unique ID value, you can invoke the method as follows:
SET person = ##class(Sample.Person).SSNKeyOpen("111-22-3333",2,.sc)Upon successful completion, the method has set the value of person to the OREF of the instance of Sample.Person whose SSN property has a value of 111–22–3333.
The second argument to the method specifies the concurrency value, which here is 2 (shared). The third argument holds an optional %Status code; if the method does not find an object that matches the supplied value, then an error message is written to the status parameter sc.
This method is implemented as the %Compiler.Type.Index.Open() method; this method is analogous to the %Persistent.Open()Opens in a new tab and %Persistent.OpenId()Opens in a new tab methods, except that it uses the properties in the index definition instead of the OID or ID argument.
Checking If an Instance Exists
The indexnameExists() method (where indexname is the name of the index) checks if an instance exists with the index property value or values specified by the method’s arguments; these values must have the same collation as the data stored in the index. The method has one argument corresponding to each property in the index; its final, optional argument can receive the object’s ID, if one matches the supplied value(s). The method returns a boolean, indicating success (1) or failure (0). This method is implemented as the %Compiler.Type.Index.Exists() method.
For example, suppose that a class includes the following index definition:
Index SSNKey On SSN [ Unique ];then, if the referenced object has been stored to disk and has a unique ID value, you can invoke the method as follows:
SET success = ##class(Sample.Person).SSNKeyExists("111-22-3333",.id)Upon successful completion, success equals 1 and id contains the ID matching the object that was found.
This method returns values for all indexes except:
-
bitmap indexes, or a bitmap extent index.
-
when the index includes an (ELEMENTS) or (KEYS) expression. For more information on such indexes, see Indexing Collections.
Deleting an Instance
The indexnameDelete() method (where indexname is the name of the index) is meant for use with a Unique, PrimaryKey, and or IdKey index; it deletes the instance whose key value matches the supplied key property/column values. There is one optional argument, which you can use to specify a concurrency setting for the operation. The method returns a %Status code. It is implemented as the %Compiler.Type.Index.Delete() method.