メジャーの定義
ここでは、Business Intelligence キューブでメジャーを定義する方法を説明します。
システムは、既定の名前が Count のメジャーを自動的に作成します。この既定の名前をオーバーライドするには、キューブの [カウント・メジャーのキャプション] オプションを指定します。"キューブ・オプションの指定" を参照してください。
"サンプルのアクセス方法" も参照してください。
メジャーの追加
メジャーを追加するには、クラス・ビューワからクラス・プロパティをドラッグして、これをモデル・ビューワの [メジャー] ラベルにドロップします。次に、必要に応じて詳細領域で変更を加えます。
また、次のようにすることもできます。
-
[要素を追加] をクリックします。
ダイアログ・ボックスが表示されます。
-
[新規項目名の入力] に、メジャー名を入力します。
"モデル要素の名前" を参照してください。
-
[メジャー] をクリックします。
-
[OK] をクリックします。
-
モデル・ビューワで、メジャーを選択します。
-
少なくとも、以下のオプションは指定してください。
-
[タイプ] — "メジャーのデータ型の指定" の説明に従って、メジャーのデータ型を指定します。
-
[プロパティ] または [式] — ソース値を指定します。"ディメンジョンまたはレベルのソース値の定義" および "ソース式の詳細" を参照してください。
-
[集計] — "メジャー集約方法の指定" の説明に従って、メジャー値の集約方法を指定します。
-
メジャーのデータ型の指定
[タイプ] オプションは、以下のように、メジャーがソース・データで予期するデータの種類および生成されるファクト・テーブルで使用されるタイプを指定します。
| メジャーのデータ型 | ソース・データで予期されるデータ型 | メジャーで使用されるデータ型 | メジャーの詳細 |
|---|---|---|---|
| number (既定) | 数値データ | %DoubleOpens in a new tab | 数値。既定の集約は SUM です。 |
| integer | 数値データ (小数値は切捨て) | %IntegerOpens in a new tab | 整数値。既定の集約は SUM です。 |
| age | $Horolog 形式の日付/時間データ | %IntegerOpens in a new tab | 日数単位の経過時間。共に使用できるのは、AVG (既定)、MIN、および MAX の各集約のみです。夜間にキューブの完全再構築または年齢メジャーの選択的構築を実行する場合を除き、年齢メジャーは一般に推奨されません。 |
| date | $Horolog 形式の日付/時間データ | %DeepSee.Datatype.dateTimeOpens in a new tab | 日付値 ($Horolog 形式、ただし秒は省略)。共に使用できるのは、AVG、MIN、および MAX (既定) の各集約のみです。 |
| boolean | 0 または 1 | %BooleanOpens in a new tab | 集約可能なブーリアン値。既定の集約は COUNT です。 |
| string | 任意 | %StringOpens in a new tab | ファクト・テーブルに格納される文字列値。インデックスは作成されません。共に使用できるのは COUNT のみです。このメジャーをアナライザにドラッグしてドロップすることはできません。 |
| iKnow* | テキスト値 | 選択されているソースに応じて %GlobalCharacterStreamOpens in a new tab または %StringOpens in a new tab | NLP スマート・インデックス作成 API を使用して処理してインデックス作成されるテキスト値。このメジャーをアナライザにドラッグしてドロップすることはできません。 |
*iKnow タイプの詳細は、"InterSystems Business Intelligence の上級モデリング" を参照してください。
メジャー集約方法の指定
[集計] オプションは、複数のレコードを結合する際、常に、このメジャーの値の集約方法を指定します。このオプションを指定する場合は、以下の値のいずれかを使用します。
-
SUM (既定) — セット内の値を加算します。
-
COUNT — ソース・データが 非 NULL (および非ゼロ) 値のレコード数をカウントします。
-
MAX — セット内の最大値を使用します。
-
MIN — セット内の最小値を使用します。
-
AVG — セットの平均値を計算します。
ブーリアンまたは文字列のメジャーでは COUNT を選択します。
検索可能なメジャーの指定
メジャーを検索可能 として指定できます。その場合はピボット・テーブルで使用されるレコードをそのメジャーの値でフィルタ処理できます。
メジャーを検索可能として指定するには、詳細領域で [検索可能] チェック・ボックスにチェックを付けます。
検索可能なメジャーの名前には、角括弧やコンマ ([],) を含めることはできません。
書式文字列の指定
[書式文字列] オプションを使用すると、データの表示形式を指定できます。この形式設定は、アナライザで (または、手動で MDX クエリを作成することで) オーバーライドできます。アーキテクトでメジャーの形式設定を指定するには、そのメジャーが表示されているときに以下を実行します。
-
検索ボタン
 をクリックします。
をクリックします。以下のフィールドが含まれるダイアログ・ボックスが表示されます。
![4 つの Piece と呼ばれる値の [書式文字列] と [色] を入力する方法を示している、アーキテクト内の [書式文字列] 画面。](images/d2model_format_string_ui.png)
以下はその説明です。
-
[正の部分] は、正の値に使用する形式を指定します。
-
[負の部分] は、負の値に使用する形式を指定します。
-
[ゼロの部分] は、ゼロに使用する形式を指定します。
-
[欠落部分] は、欠落している値に使用する形式を指定します。これは現在使用されていません。
これらのそれぞれにおいて、[書式文字列] によって数値形式が、[色] によって色が指定されます。
詳細は、日付タイプのメジャーでは異なります。次のセクションを参照してください。
-
-
必要に応じて値を指定します (この手順の後の詳細を参照してください)。
-
[OK] をクリックします。
[書式文字列] フィールド
[書式文字列] フィールドは、以下のベース・ユニットのいずれかを含む文字列です。
| ベース・ユニット | 意味 | 例 |
|---|---|---|
| # | 1000 単位の区切り文字なしで値を表示します。小数点以下の桁は含まれません。 | 12345 |
| #,# | 1000 単位の区切り文字を使用して値を表示します。小数点以下の桁は含まれません。これは正の数値に対する既定の表示形式です。 | 12,345 |
| #.## | 1000 単位の区切り文字なしで値を表示します。小数点以下 2 桁 (またはピリオド後のシャープ記号の数に応じた小数点以下桁数) まで含まれます。ピリオド以降のシャープ記号は必要なだけ指定できます。 | 12345.67 |
| #,#.## | 1000 単位の区切り文字を使用して値を表示します。小数点以下 2 桁 (またはピリオド後のシャープ記号の数に応じた小数点以下桁数) まで含まれます。ピリオド以降のシャープ記号は必要なだけ指定できます。 | 12,345.67 |
| %time% | 値を hh:mm:ss の形式で表示します。この値は秒数を示しているものと見なされます。これは、継続時間を表示するメジャーで役立ちます。 | 0:05:32 |
InterSystems IRIS は、サーバ・ロケールによって決まる 1000 単位の区切り文字と小数点記号を表示します ("ロケールを使用した時間メンバ名の制御" を参照してください)。ただし、ロケールは、前述のテーブルの最初の列に示した構文には影響しません。
ベース・ユニットの前後に追加の文字を組み込むことができます。
-
パーセント記号 (%) を組み込むと、値がパーセントとして表示されます。つまり、値に 100 が乗じられ、指定した位置にパーセント記号 (%) が表示されます。
-
その他の文字も、指定の位置に指定どおり表示されます。
以下のテーブルに例を示します。
| formatString の例 | 論理値 | 表示値 |
|---|---|---|
| formatString="#,#;(#,#);"
これは、既定の数値表示方法に対応します。 |
6608.9431 | 6,609 |
| -1,234 | (1,234) | |
| formatString="#,#.###;" | 6608.9431 | 6,608.943 |
| formatString="#%;" | 6 | 600% |
| formatString="$#,#;($#,#);" | 2195765 | $2,195,765 |
| -3407228 | ($3,407,228) |
色の部分
Color フィールドでは、以下のいずれかを指定します。
-
MediumBlue、SeaGreen などの CSS カラー名。これらについては、https://www.w3.org/TR/css3-color/Opens in a new tab およびインターネットの他の場所を参照してください。
-
#FF0000 (赤) などの 16 進カラー・コードOpens in a new tab。
-
rgb(255,0,0) (赤) などの RGB 値。
日付メジャーの書式文字列の指定
日付メジャーの書式文字列を指定するには、アーキテクトの [詳細] ペインで [書式文字列] フィールドに以下のいずれかを入力します。
| 書式文字列 | メジャーの文字列に与える影響 | 形式の例 |
|---|---|---|
| %date% | 日付は、現行プロセスの既定の日付形式を使用します。 | |
| %date%^color ここで、color は、前のセクションの "色の部分" で説明された色です。 | 日付は、現行プロセスの既定の日付形式を使用し、指定された色で表示されます。 | |
| ^color | 日付は指定された色で表示されます。 |
キューブ内のメジャーの順序の変更
キューブ内のメジャーの順序を変更する手順は以下のとおりです。
-
[順序変更] をクリックします。
ダイアログ・ボックスが表示されます。
-
[メジャー] をクリックします。
-
必要に応じて、[アルファベット順] をクリックし、アルファベット順に配列します。
これは、即座にリストに作用します。必要に応じて、リストをさらに再編成できます。また、メジャーを追加する際に、アルファベット順の自動配列は行われません。
-
メジャーの名前をクリックし、必要に応じて上矢印または下矢印をクリックします。
-
必要に応じて、他のメジャーでもこの操作を繰り返します。
-
[OK] をクリックします。
キューブ内のメジャーの順序は、アナライザでの表示方法に影響を与えます。その他の影響はありません。メジャーをアルファベット順に配列したほうが便利なユーザもいれば、使用頻度の高いメジャーをリストの上部に配置するユーザもいます。
ファクト・テーブル内のフィールド名の指定
キューブ・クラスのコンパイル時に、システムは 1 つのファクト・テーブル・クラスと、いくつかの関連クラスを生成します。キューブの構築時に、これらのテーブルに値が入力されます。詳細は、"ファクト・テーブルおよびディメンジョン・テーブルの詳細" を参照してください。
既定では、システムによってファクト・テーブルの列名が生成されますが、その代わりに使用する列名を指定することもできます。これを実行するには、各メジャーの [ファクト・テーブルのフィールド名] オプションに値を指定します。このオプションは、NLP メジャーには使用できません。一意の名前を使用するように注意してください。
リストの追加フィルタの指定
既定では、ユーザが詳細リストを表示する際、システムは、現在のコンテキスト (リストが要求されたコンテキスト) で使用されているソース・レコードごとに行を 1 つ表示します。指定されたメジャーについて、詳細リストを表示する際にシステムが使用する追加フィルタを指定できます。例えば、Patients サンプルの Avg Test Score メジャーを考えてみます。このメジャーは TestScore プロパティに基づいています。これは一部の患者については NULL になっています。ユーザが Avg Test Score メジャーを開始してリストを表示する際、このメジャーを再定義してそれらの患者をフィルタで除外できます。
このようなフィルタが必要な場合、メジャーの定義の一部に含めます。大半の場合、フィルタは以下の形式になります。
measure_value operator comparison_value
このフィルタは詳細リスト・クエリに追加され、フィルタ条件を満たさないレコードをすべて除外します。
リスト・フィルタの他の形式に MAX/MIN があります。このようなリスト・フィルタを使用した場合、詳細リストには、メジャーの最大 (または最小) 値を持つレコードのみが表示されます。メジャーは、リスト・フィルタと同じ種類の集約を使用する必要があります (リスト・フィルタが含まれている場合)。
特定のメジャーについて、リストの追加フィルタを指定するには、以下の手順を実行します。
-
モデル・ビューワで、メジャーを選択します。
リスト・フィルタで [最大] を使用する場合、[最大] として [集約] で定義されているメジャーを選択します。
同様に、[最小] を使用する場合、[最小] として [集約] で定義されているメジャーを選択します。
-
([詳細] 領域の) [メジャー固有のリスト・フィルタ] セクションで、以下の値を指定します。
-
[演算子] — [<]、[<=]、[>]、[>=]、[<>]、[=]、[最大]、[最小] のいずれかを選択します。
-
[値] — 比較値を指定します。[演算子] が [最大] または [最小] の場合はこのオプションを省略します。
-
このオプションを使用した場合、このメジャーは検索可能となる必要があるため、アーキテクトで [検索可能] チェック・ボックスが自動的に有効になります。
例
Patients キューブの Avg Test Score メジャーを修正し、[演算子] に [<>]、[値] に "" を指定するとします。つまり、NULL のテスト・スコアを持つ患者をフィルタで除外します。次に、以下のピボット・テーブルを考えてみます。
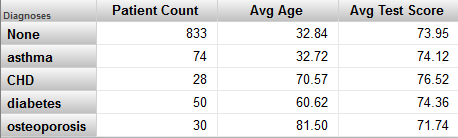
CHD 行の Patient Count セル (または Avg Age セル) をクリックして詳細リストを表示すると、以下のように表示されます。
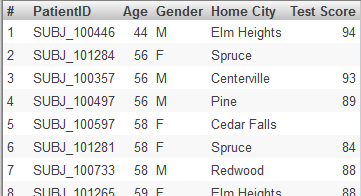
ただし、ピボット・テーブルの Avg Test Score セルをクリックして詳細リストを表示すると、以下のように表示レコードは少なくなります。