
Using Text Analytics in Cubes
The integration of text analytics within InterSystems IRIS Business Intelligence uses InterSystems IRIS Natural Language Processing (NLP), which InterSystems has deprecated. As a result, this feature may be removed from future versions of InterSystems products. The following documentation is provided as reference for existing users only. Existing users who would like assistance identifying an alternative solution should contact the WRCOpens in a new tab.
This page describes how to include text analytics within Business Intelligence cubes: analytics that examine text data (called unstructured data here).
Also see Generating Secondary Cubes for Use with Text Analytics.
Also see Accessing the BI Samples.
Overview of Integration with Text Analytics
The Analytics engine includes the ability to analyze text data (unstructured data), which is written as text in a human language such as English or French. For a general introduction of this ability, see Conceptual Overview (NLP).
You can use unstructured data within cubes, if the source table for a cube includes a property that contains unstructured data (for example, a string field that contains text). Then you can define pivot tables that use NLP (natural language processing) dimensions, and you can use these pivot tables on dashboards as usual.
For example, the source table for a cube might contain both structured and unstructured data. The Aviation demo, discussed later in this page, is such an example. For this demo, the source table consists of records of aviation events. For each aviation event, there is a set of short string fields that indicate the incident location, aircraft type, and so on. A longer text field contains the full report of the event.
(You can define also KPIs that expose text analytics queries via the InterSystems IRIS Business Intelligence KPI mechanism. See KPIs and Dashboards (NLP).)
Terminology
When analyzing unstructured data, the Analytics engine identifies the entities in it, identifying the words that belong together and their roles in the sentence. An entity is a minimal logical unit of text — a word or a group of words. Example entities are clear skies and clear sky (note that these are distinct entities, because the engine does not perform stemming). The language model identifies two kinds of entities:
-
A relation is a word or group of words that join two concepts by specifying a relationship between them. A relation is commonly but not always a verb.
-
A concept is a word or group of words that is associated by a relation. A concept is commonly but not always a noun or noun phrase.
The engine transforms each sentence into a logical sequence of concepts and relationships, thereby identifying the words that belong together (as entities) and their roles within the sentence. This is a much more structured form of data and serves the basis for analysis, including relevance metrics, automated summarizing and categorization, and matching against existing taxonomies or ontologies.
For its core activities of identifying concepts and relationships (as well as measuring the relevance of these entities), the engine does not require information about the topics discussed in the text. Therefore, the engine is a true bottom-up technology that works well with any domain or topic, because it is based on an understanding of the language rather than of the topic.
However, if you have some knowledge about the topics discussed in the text, you can let the engine find any matches for these known terms, called dictionary terms. Because the engine understands the role and extent of entities, it can also judge whether an entity (or sequence of entities) encountered in the text is a good or a poor match with a known term and come up with a match score. For example, for the dictionary term runway, the entity runway (occurring in the text) is a full match, but runway asphalt is only a partial match and therefore gets a lower score.
Dictionary terms are grouped in dictionary items, which represent the unique things you wish to identify. For example runway and landing strip might be two terms for a generic dictionary item that covers any mentions of runways.
For a broader discussion of dictionaries, see Smart Matching: Creating a Dictionary and Smart Matching: Using a Dictionary.
About NLP (Natural Language Processing) Measures and Dimensions
Unlike other kinds of measures, an NLP measure is not shown in the Analyzer, and you do not directly use it in pivot tables. You define an NLP measure for each property that you want the engine to process as text data. Then you can use the measure as the basis of an NLP dimension.
An NLP dimension is like other dimensions; it includes one or more levels, which contain members. Any member consists of a set of records in the source class of the cube.
There are two kinds of NLP dimensions:
-
Entity dimensions. An entity dimension contains a single level. Each member of that level corresponds to an entity that the engine found in the unstructured data.
The members of this level are sorted in decreasing order by spread (number of records that include this entity). When you expand this level in the left area of the Analyzer, it displays the 100 most common entities. When you use this level as a filter, however, you can search to access any entity.
-
Dictionary dimensions. A dictionary dimension typically contains two levels as follows:
-
The upper level, the dictionary level, contains one member for each dictionary. That member consists of all records that match any item of the given dictionary.
For example, the weather conditions member consists of all records that match any item in the dictionary weather conditions. This includes items such as winter, rain, clouds sky, and so on.
-
The optional lower level, the item level, contains one member for each dictionary item. That member consists of all records that match any term of the given dictionary item.
For example, the winter member consists of each record that matches any of its terms, including snow, icy, and ice-covered.
-
Note that because the source text typically includes multiple entities, any given source record is likely to belong to multiple members of a level.
Generated Text Analytics Domains
When you use the features described in this page, the system creates one or more text analytics domains. Each cube level and each measure is available as a pseudo metadata field, which you can use in text analytics queries. For a level, the equal and not equal operator are supported. For a measure, all operators are supported. For information on text analytics queries, see Using InterSystems IRIS Natural Language Processing (NLP).
Also see Text Analytics Domain Management, later in this page.
Setting Up the Aviation Events Demo
This page uses the Samples-Aviation sample (https://github.com/intersystems/Samples-AviationOpens in a new tab). InterSystems recommends that you create a dedicated namespace named SAMPLES and then load samples into that namespace. For the general process, see Downloading Samples for Use with InterSystems IRIS® data platform.
The Aviation demo, which includes several cube definitions, example term lists, and a dashboard.
For this demo, the primary cube (Aviation Events) is based on the table Aviation.Event, which consists of records of aviation events. For each aviation event, there is a set of short string fields that indicate the incident location, aircraft type, and so on. A longer text field contains the full report of the event.
Sample Dashboard
To see the sample dashboard:
-
In the Management Portal, access the namespace into which you loaded this sample.
-
Select Analytics > User Portal.
The system then displays the User Portal, which lists any existing public dashboards and pivot tables in this namespace. At the top of the User Portal you can select a View: display option.
-
Select the Aviation event reports dashboard.
The Aviation event reports dashboard includes this pivot table:
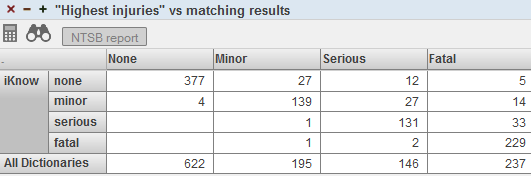
This pivot table is defined as follows:
-
The measure is Count (count of events).
-
Except for the last row, each row represents an entity that was found by the Analytics engine and matched to an item in a Text Analytics dictionary.
-
The last row represents all records matched to items in dictionaries.
-
The columns display members of the Highest Injury level, which is a level in a standard data dimension that is based on a direct classification provided for the reports.
This means that the rows display groupings as determined by the unstructured data (found by the Analytics engine in the textual report), and the columns display groupings as determined by the structured data (the direct classifications). You can use a pivot table like this to find any discrepancies between the unstructured data and structured data.
Consider, for example, the None column, which provides information on reports that are officially classified with None as the highest injury level. Of this set, the cells in this column provide the following information:
-
The iKnow —> none cell indicates that in 377 reports, the Analytics engine found an entity that matches the none item of the Injuries dictionary. This is reasonable.
-
The iKnow —> minor cell indicates that in four reports, the Analytics engine found an entity that matches the minor item of the Injuries dictionary. That is, in four reports, the unstructured data suggests that there were minor injuries (despite the fact that these reports are classified with None as the highest injury level).
The value in this cell represents a discrepancy between the unstructured data and structured data. For this cell, it would be useful to investigate further and read the complete reports.
-
The iKnow —> serious and iKnow —> fatal cells are empty. These cells indicate that there are no records where the Analytics engine found injury entities named serious or fatal. This is reasonable.
If we display a detail listing for the cell iKnow —> minor in the column None and then view the reports (via the  icon) for these incidents, we find that these reports were misclassified and there were minor injuries in all of them. For example, the first report includes the sentence The private pilot reported minor injuries.
icon) for these incidents, we find that these reports were misclassified and there were minor injuries in all of them. For example, the first report includes the sentence The private pilot reported minor injuries.
Similarly, in the Minor column, the cells iKnow —> serious and iKnow —> fatal indicate other discrepancies. For the Serious column, the cell iKnow —> fatal indicates other discrepancies.
A Closer Look at the Aviation Cubes
For a closer look at these demo cubes, use the Architect and the Analyzer. The Aviation Events cube contains the following elements:
-
The Count measure, which is a count of event reports.
-
The InjuriesTotal measure, which is a sum of injuries.
-
The Report measure, which is an NLP measure that uses the unstructured data. This measure is not listed in the Analyzer, because it is meant for use only by NLP dimensions.
-
The Event Date, Location, Sky Condition, Mid-Air, and Injuries dimensions, which are standard dimensions that use the structured data.
-
The Entities dimension, which is an entity dimension.
-
The Dictionaries dimension, which is an dictionary dimension.
-
The Aircraft dimension, which is a relationship to the Aircraft cube.
The Aircraft cube provides dimensions that you can use to group records by attributes of the aircraft, such as its type and model. The Aircraft cube also includes a relationship to the Crew cube, which provides levels associated with the personnel on the aircraft.
Defining an NLP measure
To add an NLP measure:
-
Select Add Element.
The system displays a dialog box.
-
For Enter New Item Name, type a measure name.
-
Select Measure.
-
Select OK.
-
Select the measure in the middle area of the Architect.
-
Specify the following options:
-
Property or Expression — Specifies a source value that contains unstructured data.
Or specify a value that contains the full path of a plain text file, where the file contains the text to be processed.
-
Type — Select iKnow.
-
iKnow Source — Specify the type of the source value. Select string, stream, or file. For example, if the selected source property is of type %Stream.GlobalCharacterOpens in a new tab, select stream. Or if the value is the path to a file, select file.
This option indicates, to the Analytics engine, how to process the values specified in Property or Expression.
The value domain is for advanced use; see Alternative Technique: Using an Existing Text Analytics Domain.
As an example, the Aviation cube is based on the Aviation.Event class. The NLP measure Report is based on the NarrativeFull property of that class. For this measure, iKnow Source is string.
Note that the Aggregate option has no effect on NLP measures.
-
-
Save the cube definition in the Architect.
-
If you plan to define one or more dictionary levels that use this measure, also specify the Dictionaries option as follows:
-
Select the button below Dictionaries.
The system displays a dialog box.
-
Select the appropriate dictionary in the Available Dictionaries list and then select > to move that dictionary to the Selected Dictionaries list.
If Available Dictionaries does not list the dictionaries that you need, see Loading and Updating a Dictionary, later in this page.
-
Repeat as needed.
-
Select OK.
Each dictionary is actually a term list. If you follow the steps described here, the Analytics Engine automatically finds the given term lists, loads them as dictionaries, and performs matching. (If you do not add this attribute, you can instead invoke a method to perform these tasks.)
-
Note that NLP measures are not stored in the fact table for the cube and are not displayed in the Analyzer. The primary purpose of an NLP measure is to define an Text Analytics domain and to serve as the basis of an NLP dimension. See the next sections.
Also note that you can override the default parameters for the measure. See Specifying Text Analytics Domain Parameters for a Measure, later in this page; this option is for advanced use.
Alternative Technique: Using an Existing Text Analytics Domain
If you have an existing Text Analytics domain, you can reuse that. Use the preceding instructions with the following changes:
-
Specify iKnow Source as domain.
-
When you specify the source expression or source property, make sure that it evaluates to the external ID of the source that corresponds to that record in the fact table.
-
In an IDE, add the iKnowDomain attribute to the measure definition. Its value should be the name of an existing Text Analytics domain.
-
Skip step 8. That is, do not specify the Dictionaries option.
In this case, the Text Analytics domain is managed separately from the process of compiling, building, and synchronizing cubes. At build time, the Analytics Engine does not drop or load any text analytics records. Your custom code must ensure that all data represented and identified by the External ID property/expression at the fact level is properly loaded. At runtime (and only at runtime), the Analytics Engine uses the Text Analytics logic. Also note that the Analytics Engine does not load automatically data during the process of compiling, building, and synchronizing cubes. To load data, specify parameters, or otherwise manage this domain, use the domain APIs directly as described in Using InterSystems IRIS Natural Language Processing (NLP).
Alternative Technique: Retrieving Unstructured Text from Elsewhere
In some scenarios, you may need to retrieve the unstructured text from a web page. For example, you might have a table of structured information, with a field that contains the URL where additional information (such as a news article) can be found. In such a case, the easiest way to use that text as an NLP measure is as follows:
-
Write a utility method to retrieve the text from the URL.
-
Refer to that utility method in a source expression for the NLP measure.
For an example, suppose that we are basing a cube on a class that has summary information about news articles. Each record in the class contains the name of the news agency, the date, the headline, and a property named Link, which contains the URL of the full news story. We want to create an NLP measure that uses the news stories at those URLs.
To do this, we could define a method, GetArticleText(), in the cube class as follows:
ClassMethod GetArticleText(pLink As %String) As %String
{
set tSC = $$$OK, tStringValue = ""
try {
set tRawText = ..GetRawTextFromLink(pLink, .tSC)
quit:$$$ISERR(tSC)
set tStringValue = ..StripHTML(tRawText, .tSC)
quit:$$$ISERR(tSC)
} catch (ex) {
set tSC = ex.AsStatus()
}
if $$$ISERR(tSC) {
set tLogFile = "UpdateNEWSARCHIVE"
set tMsg = $system.Status.GetOneErrorText(tSC)
do ##class(%DeepSee.Utils).%WriteToLog("UPDATE", tMsg, tLogFile)
}
quit tStringValue
}The GetRawTextFromLink() method would retrieve the raw text, as follows:
ClassMethod GetRawTextFromLink(pLink As %String, Output pSC As %Status) As %String
{
set pSC = $$$OK, tRawText = ""
try {
// derive server and path from pLink
set pLink = $zstrip(pLink,"<>W")
set pLink = $e(pLink,$find(pLink,"://"),*)
set tFirstSlash = $find(pLink,"/")
set tServer = $e(pLink,1,tFirstSlash-2)
set tPath = $e(pLink,tFirstSlash-1,*)
// send the HTTP request for the article
set tRequest = ##class(%Net.HttpRequest).%New()
set tRequest.Server = tServer
set tSC = tRequest.Get(tPath)
quit:$$$ISERR(tSC)
set len = 32000
while len>0 {
set tString = tRequest.HttpResponse.Data.Read(.len, .pSC)
quit:$$$ISERR(pSC)
set tRawText = tRawText _ tString
}
} catch (ex) {
set pSC = ex.AsStatus()
}
quit tRawText
}The StripHTML() method would remove the HTML formatting, as follows:
ClassMethod StripHTML(pRawText As %String, Output pSC As %Status) As %String
{
set pSC = $$$OK, tCleanText = ""
try {
for tTag = "b","i","span","u","a","font","em","strong","img","label","small","sup","sub" {
set tReplaceTag(tTag) = " "
}
set tLowerText = $$$LOWER(pRawText)
set tStartPos = $find(tLowerText,"<body")-5, tEndTag = ""
set pRawText = $e(pRawText,tStartPos,*), tLowerText = $e(tLowerText,tStartPos,*)
for {
set tPos = $find(tLowerText,"<")
quit:'tPos // no tag start found
set tNextSpace = $f(tLowerText," ",tPos), tNextEnd = $f(tLowerText,">",tPos)
set tTag = $e(tLowerText,tPos,$s(tNextSpace&&(tNextSpace<tNextEnd):tNextSpace, 1:tNextEnd)-2)
if (tTag="script") || (tTag="style") {
set tPosEnd = $find(tLowerText,">",$find(tLowerText,"</"_tTag,tPos))
} else {
set tPosEnd = tNextEnd
}
if 'tPosEnd { //
set tEndTag = $e(pRawText,tPos-1,*)
set pRawText = $e(pRawText,1,tPos-2)
quit
}
set tReplace = $s(tTag="":"", 1:$g(tReplaceTag(tTag),$c(13,10,13,10)))
set pRawText = $e(pRawText,1,tPos-2) _ tReplace _ $e(pRawText,tPosEnd,*)
set tLowerText = $e(tLowerText,1,tPos-2) _ tReplace _ $e(tLowerText,tPosEnd,*)
}
set tCleanText = $zstrip($zconvert(pRawText, "I", "HTML"),"<>=W")
} catch (ex) {
set pSC = ex.AsStatus()
}
quit tCleanText
}Finally, we would create an NLP measure and base it on the following source expression: %cube.GetArticleText(%source.Link).
Loading and Updating Dictionaries
This section describes how to load and update dictionaries for use with NLP measures and dimensions.
Loading Dictionaries
To load an dictionary into InterSystems IRIS:
-
Access the Term List Manager, as described in the Accessing the Term List Manager.
-
Define a new term list to contain the dictionary items and terms. For this term list:
-
Use a convenient name for the term list. The dictionary name is based on the term list name, with an added prefix.
-
Optionally add the custom fields URI and language; see the following step for details on how these fields would be used.
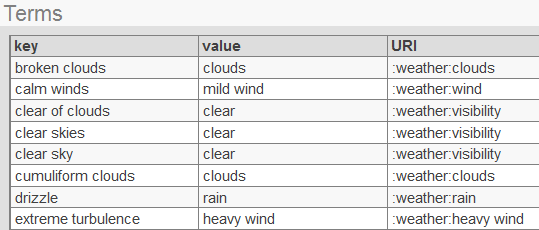
Every term list has the fields key and value, so your term list will have these fields as well.
For general information on creating term lists, see Defining Term Lists.
-
-
Add terms to the term list. For each term list item, specify values as follows:
-
key (required) is a unique term that could be found in the text.
-
value (required) is the corresponding dictionary item.
-
URI (optional) is a unique identifier for the dictionary item (the value column of the term list), which you can then use as a member key in MDX queries, if you need to refer to a specific dictionary item. This identifier must be unique for each combination of dictionary name and dictionary item.
If you omit this field, the system generates a URI of the following form:
:dictionary_name:dictionary_itemWhere dictionary_name is the name of the dictionary to define or update, and dictionary_item is the value in the value field.
-
language (optional) is a all-lowercase language tag (such as en or es).
The following shows an example (omitting the language field):
-
-
Save the term list.
-
Specify the Dictionaries option for each NLP measure that should use this term list as a dictionary. See Defining an NLP measure.
The Dictionaries option specifies the term lists to load as dictionaries for this NLP measure. The system automatically loads these term lists at cube build time.
Updating Dictionaries
If you create or change a term list that is used as a dictionary, you must update the dictionary. To do so, use the UpdateDictionary() method of %iKnow.DeepSee.CubeUtilsOpens in a new tab:
classmethod UpdateDictionary(pTermList As %String,
pCube As %String = "",
pMeasure As %String = "",
pClearFirst As %Boolean = 0) as %Status
Where:
-
pTermList is the name of term list.
-
pCube is the name of the cube. If you omit this argument, this method is invoked for all cubes in this namespace.
-
pMeasure is the name of NLP measure. If you omit this argument, this method is invoked for all NLP measures in the given cube (or all cubes, depending on pCube).
-
pClearFirst controls whether to drop the existing dictionary before reloading it from the term list. Leave pClearFirst as 0 if you only appended to the term list, or use 1 if you changed or removed any existing terms.
If pClearFirst is 0, this method can run significantly faster.
Note that when you build a cube, the system refreshes all dictionaries used by this cube by appending any new term lists. Deleted and renamed items are not affected. See When Text Analytics Updates Occur, later in this page.
Defining an Entity Dimension
To add a entity dimension:
-
Create an NLP measure for this dimension to use, as described earlier in this page.
You can also do this after defining the dimension; if so, edit the dimension later so that it refers to this measure.
-
Select Add Element.
The system displays a dialog box.
-
For Enter New Item Name, type a dimension name.
-
Select iKnow Dimension and select OK.
-
Select the dimension in the middle area of the Architect.
-
Make the following changes to the dimension, if needed:
-
iKnow type — Select entity.
-
NLP measure — Select the NLP measure for this dimension to use.
-
-
Select the level in the middle area of the Architect and optionally modify Name and Display Name.
-
Optionally, to specify the members of this level manually, use an IDE and define <member> elements within the level.
By default, the level consists of all entities, in decreasing order by spread. If you use <member> to specify the members manually, that specifies the members of this level and their order. Note that for an entity dimension, the number of members displayed in the Analyzer is fixed at 100.
See Manually Specifying the Members for a Level, in Using Advanced Features of Cubes and Subject Areas.
Note that it is not necessary to specify anything for Source Values, either for the dimension or for the level. For an NLP dimension, the associated NLP measure specifies the source values.
Defining a Dictionary Dimension
To add a dictionary dimension:
-
Load a dictionary into InterSystems IRIS. See Loading Dictionaries, earlier in this page.
You can also do this after defining the dimension.
-
Create an NLP measure for this dimension to use.
You can also do this after defining the dimension; if so, edit the dimension later so that it refers to this measure.
-
Select Add Element.
The system displays a dialog box.
-
For Enter New Item Name, type a dimension name.
-
Select iKnow Dimension and select OK.
-
Select the dimension in the middle area of the Architect.
-
Make the following changes if needed:
-
iKnow type — Select dictionary.
-
NLP measure — Select the NLP measure for this dimension to use.
-
-
Optionally add another level to the same hierarchy in this dimension.
If the dimension has only one level, that level provides access to dictionary items. If the dimension has two levels, the lower level provides access to entities that match dictionary items.
-
Select each level in the middle area of the Architect and optionally modify Name and Display Name.
-
Save the cube definition in the Architect.
-
Open the cube class in an IDE and find the definition of this dimension. For example, if the dimension has one level, it might look like this (this example shows added line breaks):
<dimension name="MyDictionaryDimension" disabled="false" ` hasAll="false" allCaption="MyDictionaryDimension" allDisplayName="MyDict" type="iKnow" iKnowType="dictionary" nlpMeasure="Report" hidden="false" showHierarchies="default"> <hierarchy name="H1" disabled="false"> <level name="Dictionary" disabled="false" list="false" useDisplayValue="true"> </level> </hierarchy> </dimension>Or, if the dimension has two levels:
<dimension name="MyDictionaryDimension" disabled="false" hasAll="false" allCaption="MyDictionaryDimension" allDisplayName="MyDict" type="iKnow" iKnowType="dictionary" nlpMeasure="Report" hidden="false" showHierarchies="default"> <hierarchy name="H1" disabled="false"> <level name="Dictionary" disabled="false" list="false" useDisplayValue="true"> </level> <level name="Items" disabled="false" list="false" useDisplayValue="true"> </level> </hierarchy> </dimension> -
In the dictionary level, optionally specify the dictionary or dictionaries for this level to use. If there are two levels, the dictionary level is the higher of the two levels. If there is one level, that level is the dictionary level.
If you do not specify any dictionaries, all dictionaries are used.
For each dictionary to use, add the following between the <level> element and the </level>:
<member name="dictionary name" />Where dictionary name is the name of a dictionary.
For example, with a single dictionary:
<dimension name="MyDictionaryDimension" disabled="false" hasAll="false" allCaption="MyDictionaryDimension" allDisplayName="MyDict" type="iKnow" iKnowType="dictionary" nlpMeasure="Report" hidden="false" showHierarchies="default"> <hierarchy name="H1" disabled="false"> <level name="Dictionary" disabled="false" list="false" useDisplayValue="true"> <member name="my dictionary" /> </level> <level name="Items" disabled="false" list="false" useDisplayValue="true"> </level> </hierarchy> </dimension> -
Save the cube definition.
Note that it is not necessary to specify anything for Source Values, either for the dimension or for the level. For an NLP dimension, the associated NLP measure specifies the source values.
Adding Member Overrides to an Item Level
Within a two-level dictionary dimension, by default, the dictionary level determines the members of the lower item level. In the item level, you can add <member> elements that override the definitions determined by the parent.
This is useful, for example, if you want to see only a subset of the dictionary.
If you create these overrides, each <member> element should have the following form:
<member name="itemURI" displayName="displayName" />
Where itemURI is the unique URI of a dictionary item, and displayName is the display name for the dictionary item. See Loading Dictionaries, earlier in this page.
List the <member> elements in the desired sort order. For example:
<level name="ReportDictInjuriesDimItem" displayName="Injuries" >
<member name=":injuries:none" displayName="not injured" />
<member name=":injuries:minor" displayName="minor injuries" />
<member name=":injuries:serious" displayName="serious injuries" />
<member name=":injuries:fatal" displayName="killed" />
</level>
These overrides work as follows:
-
If at least one <member> element can be matched to the given dictionary item, this level contains only the members listed by these <member> elements.
-
If none of the <member> elements can be matched to dictionary items, these overrides are all ignored.
Adding Measures That Use Plug-ins
A plug-in is essentially a query, and the system provides plug-ins that perform specialized text analytics queries. You can use these plug-ins to add calculated measures that provide information on entity occurrences and on matching results. The following sections give the details.
Adding Measures to Quantify Entity Occurrences
You can easily add measures that provide information on entity occurrences (indicate the total number, average number per record, and so on). For an example, see the calculated measure Distinct Entity Count in the Aviation Events cube.
To add your own measures, follow the steps in Defining a Calculated Measure. For Expression, use the following expression:
%KPI("%DeepSee.iKnow","Result",1,"aggregate","total","%CONTEXT")
This expression returns the total number of distinct entities, in any given context.
Instead of "total", you can use any of the following:
-
"sum" — In this case, the expression returns the total number of entities (as opposed to distinct entities), in the given context. That is, entities might be counted more than once.
-
"average" — In this case, the expression returns the average number of entities per record, in the given context.
-
"max" — In this case, the expression returns the maximum number of entities in any given record, in the given context.
-
"min" — In this case, the expression returns the minimum number of entities in any given record, in the given context.
This expression uses the %KPI MDX function and the plug-in class %DeepSee.PlugIn.iKnowOpens in a new tab. For details on the function, see InterSystems MDX Reference. For details on the class, see the class reference.
If you omit the "%CONTEXT", then in all cases, your calculated measures ignore any context and return results for your entire data set.
Adding Measures to Quantify Matching Results
You can easily add measures that provide information on dictionary matching results (indicate the total number, average matching score per record, and so on). For examples, see the calculated measures Dictionary Match Count and Total Dictionary Score in the Aviation Events cube.
To add your own measures, follow the steps in Defining a Calculated Measure. For Expression, use one of the following expressions:
-
To get counts of matching results (results that match dictionary items):
%KPI("%DeepSee.iKnowDictionary","MatchCount",1,"aggregate","sum","%CONTEXT")This expression returns the total number of matching results, in any given context.
Instead of "sum", you can use the alternative aggregation types listed in the previous section.
-
To get scores for matching results:
%KPI("%DeepSee.iKnowDictionary","MatchScore",1,"aggregate","sum","%CONTEXT")This expression returns the total score for matching results, in any given context.
Instead of "sum", you can use the alternative aggregation types listed in the previous section.
These expressions use the %KPI MDX function and the plug-in class %DeepSee.PlugIn.iKnowDictionaryOpens in a new tab. For details on the function, see InterSystems MDX Reference. For details on the class, see the class reference.
If you omit the "%CONTEXT", then in all cases, your calculated measures ignore any context and return results for your entire data set.
Including Text Analytics Results in Listings
You can include Text Analytics results in listings as follows:
-
You can add a link from the listing to the complete unstructured text
-
You can define a specialized listing for use in the Content Analysis plug-in
Including a Text Analytics Summary Field in a Listing
It can be useful for your listings to include a summary of the unstructured text. To include such a summary, use the $$$IKSUMMARY token within the listing field definition. This token takes two arguments (in square brackets):
$$$IKSUMMARY[nlpMeasure,summarylength] As Report
Where nlpMeasure is the name of the NLP measure to summarize and summary_length is the number of sentences to include in the summary (the default is five). You can omit nlpMeasure if there is only one NLP measure in the cube.
The As clause specifies the title of the column; in this case, the title is Report.
The $$$IKSUMMARY token returns the most relevant sentences of the source, concatenated into a string that is no longer than 32000 characters.
For example:
<listing name="Default" disabled="false" listingType="table"
fieldList="%ID,EventId,Year,AirportName,$$$IKSUMMARY[Report] As Report">
</listing>
Internally $$$IKSUMMARY uses the GetSummary() method of %iKnow.Queries.SourceAPIOpens in a new tab.
You can also use the $$$IKSUMMARY token to refer to an NLP measure in a related cube, if there is a many-to-one relationship between the listing cube and the related cube. In this case, use relationshipname.nlpMeasure instead of nlpMeasure as the first argument to $$$IKSUMMARY. For example, suppose that the Observations cube has a relationship called Patient, which points to the Patients cube. Also suppose that the Patients cube has an NLP measure named History. Within the Observations cube, you can define a listing that includes $$$IKSUMMARY[Patient.History].
You can refer to a relationship of a relationship in the same way. For example: $$$IKSUMMARY[Relationship.Relationship.Measure].
Including a Link from a Listing to the Full Unstructured Text
Your listings can also include a link to a page that displays the full unstructured text. To include such a link, use the $$$IKLINK token within the listing field definition. This token takes one argument (in square brackets):
$$$IKLINK[nlpMeasure]
Where nlpMeasure is the name of the NLP measure to display. You can omit nlpMeasure if there is only one NLP measure in the cube.
You can also use the $$$IKLINK token to refer to an NLP measure in a related cube, if there is a many-to-one relationship between the listing cube and the related cube. In this case, use relationshipname.nlpMeasure instead of nlpMeasure as the first argument to $$$IKLINK. You can refer to a relationship of a relationship in the same way. For example: $$$IKLINK[Relationship.Relationship.Measure].
See the examples in the previous subsection.
Creating a Specialized Listing for Use in Content Analysis Plug-in
The Analyzer provides advanced analysis options, which include the Content Analysis plug-in. This option uses a detail listing to display the five most typical and five least typical records. By default, the plug-in uses the default listing of the cube.
You might want to create a listing specifically for use here, for reasons of space. If you define a listing named ShortListing, the plug-in uses that listing instead.
In either case, the plug-in adds a Score column to the right of the columns defined in the listing.
For details on this analysis option, see Text Analytics Content Analysis.
Text Analytics Domain Management
When you use the features described in this page, the system creates one or more Text Analytics domains. These Text Analytics domains are managed by Business Intelligence (unlike Text Analytics domains that you create directly as described in Using InterSystems IRIS Natural Language Processing (NLP)). To modify them, you should use only the APIs described in this page.
InterSystems IRIS manages these domains in a way that requires little or no intervention. If you are familiar with Text Analytics domains, however, you might be interested in the details.
The system creates one Text Analytics domain for each NLP measure that you add to a cube. The name of the domain is DeepSee@cubename@measurename where cubename is the logical name of the cube and measurename is the logical name of the NLP measure.
InterSystems IRIS manages these domains as follows:
-
When you compile the cube for the first time, the system creates the needed domains.
-
When you build the cube, the Analytics engine processes the text in the NLP measures and stores the results.
-
When you compile the cube again, the system checks to see if the needed domains exist. If so, it reuses them. If not, it creates them.
When it checks whether a given domain can be reused, the system considers the source value or source expression of each NLP measure (rather than considering the logical name of the NLP measure). Therefore, when you rename an NLP measure, the system reuses the existing Text Analytics domain.
-
When you remove an NLP measure and recompile the cube, the system deletes the corresponding Text Analytics domain and all associated engine results.
-
When you delete the cube, the system deletes the Text Analytics domains and removes all associated engine results.
Advanced Topics
This section discusses the following advanced topics:
Specifying Text Analytics Domain Parameters for a Measure
In rare cases, you might want to override the default Text Analytics domain parameters used for a given NLP measure. To do so, edit the cube class in an IDE and add the following to the definition of the applicable NLP measure:
iKnowParameters="parameter::value;parameter::value"
For parameter, use the parameter name or the macro that represents the parameter. Use two colons between a parameter and its value. Use a semicolon to separate each name/value pair from the next pair in the list.
The following example overrides the default values for the DefaultConfig and MAT:SkipRelations parameters:
iKnowParameters="DefaultConfig::Spanish;MAT:SkipRelations::0"
For details on Text Analytics domain parameters, see Alternatives for Creating an NLP Environment.
Loading Skiplists
A skiplist is a list of entities that you do not want a query to return. To load skiplists for use with Business Intelligence:
-
Create a term list that consists of the skiplist items. For information on creating term lists, see Defining Term Lists.
-
Edit an NLP measure to use this skiplist. To do this, edit the measure in an IDE and specify the iKnowParameters attribute. This attribute contains one or more name/value pairs, where the names are Text Analytics domain parameters and the values are the corresponding values. For general information on specifying iKnowParameters, see Specifying Text Analytics Domain Parameters for a Measure, earlier in this page.
In this case, the Text Analytics domain parameter is $$$IKPDSSKIPLIST and its value is the term list name.
-
Either rebuild the cube or manually load the term list as a skiplist.
To manually load the term list as a skiplist, use the following class method of %iKnow.DeepSee.CubeUtilsOpens in a new tab:
classmethod LoadTermListAsSkipList(pCube As %String, pMeasure As %String, pTermList As %String) as %StatusWhere:
-
pCube is the name of the cube that uses this NLP measure.
-
pMeasure is the name of NLP measure that uses this skiplist.
-
pTermList is the name of term list.
-
The system uses this skiplist for the following purposes:
-
To filter entities returned by the entity dimension, in the Analyzer or directly through MDX.
-
To exclude entities from the derivation of top groups as shown in the Entity Analysis screen (described in Using the Pivot Analysis Window). Entries on skiplists (or their standardized form) will not be a group by themselves, but still contribute to the scores of other groups. For example, if pilot is on a skiplist, helicopter pilot still contributes to the group helicopter.
-
To filter entities shown in the Entities detail tab in the Entity Analysis screen.
The skiplist does not affect the assisted text entry for the Analyze String option in the Entity Analysis screen.
Updating Skiplists
To update a skiplist, edit the corresponding term list and then either rebuild the cube or manually load the term list as a skiplist as described in the previous subsection.
When the NLP Updates Occur
The following table summarizes when the Analytics engine updates dictionaries, skiplists, and matching results:
| Action | Automatic NLP Updates by the Analytics Engine |
|---|---|
| Compiling a cube | None |
| Building a cube |
|
| Synchronizing a cube |
|
| Updating a term list via the API or the Management Portal | None |
| Updating a term list via the UpdateDictionary() method of %iKnow.DeepSee.CubeUtilsOpens in a new tab |
|