
How the System Builds and Uses Fact Tables
How the System Builds and Uses Fact Tables
When you compile a cube, the system generates a fact table and related tables. When you build a cube, the system populates these tables and generates their indexes. At runtime, the system uses these tables. This section describes this process. It includes the following topics:
The system does not generate tables for subject areas. A subject area uses the tables that have been generated for the cube on which the subject area is based.
Structure of a Fact Table
A fact table typically has one record for each record of the base table; this row is a fact. The fact contains one field for each level and one field for each measure. The following shows a sketch:
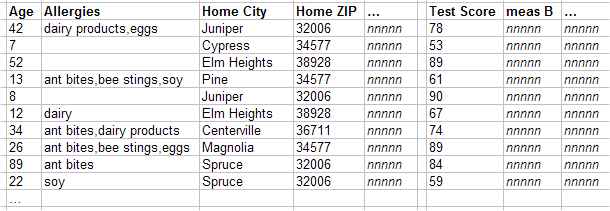
The field for a given level might contain no values, a single value, or multiple values. Each distinct value corresponds to a member of this level. The field for any given measure contains either null or a single value.
When the system builds this fact table, it also generates indexes for it.
The fact table does not contain information about hierarchies and dimensions. In the fact table, regardless of relationships among levels, each level is treated in the same way: the fact table contains one column for each level, and that column contains the value or values that apply to each source record.
By default, the fact table has the same number of rows as the base table. When you edit a cube class in an IDE, you can override its OnProcessFact() callback, which enables you to ignore selected rows of the base table. If you do so, the fact table has fewer rows than the base table.
Populating the Fact Table
When you perform a full build of a cube, the system iterates through the records of the base table. For each record, the system does the following:
-
Examines the definition of each level and obtains either no value, a single value, or multiple values.
In this step, the system determines how to categorize the record.
-
Examines the definition of each measure and obtains either no value or a single value.
The system then writes this data to the corresponding row in the fact table and updates the indexes appropriately.
When you perform a Selective Build, the system iterates through an existing fact table and updates or populates the selected columns.
When you build a cube upon which other related cubes depend, the system builds the related cubes as well, populating the related cubes’ fact tables in the appropriate order after it has done so for the independent cube.
Determining the Values for a Level
Each level is specified as either a source property or a source expression. Most source expressions return a single value for given record, but if the level is of type list, its value is a list of multiple values.
For a given record in the base table, the system evaluates that property or expression at build time, stores the corresponding value or values in the fact table, and updates the indexes appropriately.
For example, the Age Bucket level is defined as an expression that returns one of the following strings: 0-9, 10-19, 20-29, and so on. The value returned depends upon the patient’s age. The system writes the returned value to the fact table, within the field that corresponds to the Age Bucket level.
For another example, the Allergy level is a list of multiple allergies of the patient.
Determining the Value for a Measure
When the system builds the fact table, it also determines and stores values for measures. Each measure is specified as either a source property or an ObjectScript source expression.
For a given row in the base table, the system looks at the measure definition, evaluates it, and stores that value (if any) in the appropriate measure field.
For example, the Test Score measure is based on the TestScore property of the patients.
Determining the Value for a Property
When the system builds the fact table, it also determines values for properties, but it does not store these values in the fact table. In addition to the fact table, the system generates a table for each level (with some exceptions; see Details for the Fact and Dimension Tables). When the system builds the fact table, it stores values for properties in the appropriate dimension tables.
Using a Fact Table
Consider the following pivot table:
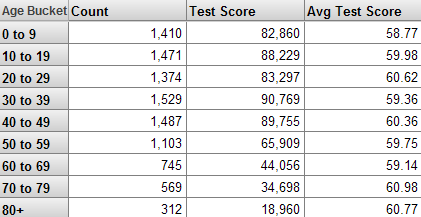
The first column displays the names of the members of the Age Bucket level. The first data column shows the Patient Count measure, the second data column shows the Test Score measure, and the last column shows the Avg Test Score measure. The Avg Test Score measure is a calculated member.
The system determines these values as follows:
-
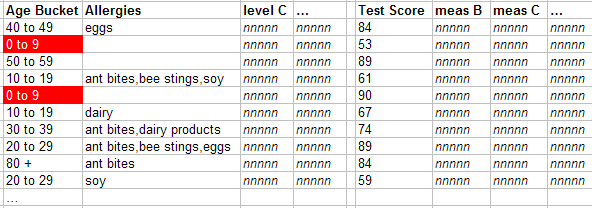
The first row refers to the 0-9 member of the Age Bucket level. The system uses the indexes to find all the relevant patients (shown here with red highlighting) in the fact table:
-
In the pivot table, the Patient Count column shows the count of patients used in a given context.
For the first cell in this column, the system counts the number of records in the fact table that it has found for the 0-9 member.
-
In the pivot table, the Test Score column shows the cumulative test score for the patients in a given context.
For the first cell in this column, the system first finds the values for the Test Score in the fact table that it has found for the 0-9 member:
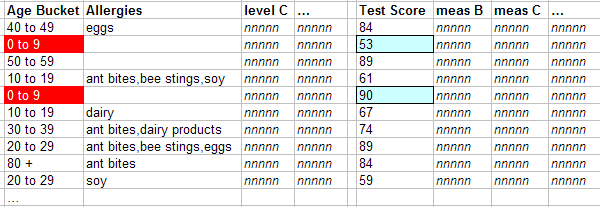
Then it aggregates those numbers together, in this case by adding them.
-
In the pivot table, the Avg Test Score column is meant to display the average test score for the patients in a given context.
The Avg Test Score measure is a calculated member, computed by dividing Test Score with Patient Count.
The system repeats these steps for all cells in the result set.