
Introduction to IntegratedML
IntegratedML is a feature within InterSystems IRIS® data platform which allows you to use automated machine learning functions directly from SQL to create and use predictive models.
Purpose
Successful organizations recognize the need to develop applications that effectively harness the massive amounts of data available to them. These organizations want to use machine learning to train predictive models from large datasets, so that they can make critical decisions based on their data. This places organizations without the in-house expertise to build machine learning models at a significant disadvantage. For this reason, InterSystems has created IntegratedML.
IntegratedML enables developers and data analysts to build and deploy machine learning models within a SQL environment, without any expertise required in feature engineering or machine learning algorithms. Using IntegratedML, developers can use SQL queries to create, train, validate, and execute machine learning models.
IntegratedML considerably reduces the barrier to entry into using machine learning, enabling a quick transition from having raw data to having an implemented model. It is not meant to replace data scientists, but rather complement them.
Introduction to Machine Learning
To understand IntegratedML, you need an introductory understanding of several commonly used terms:
-
Machine learning
-
Models
-
Regression versus classification
-
Training
-
Features and labels
-
Model validation
Machine learning is the study of computer algorithms that identify and extract patterns from data in order to build and use predictive models.
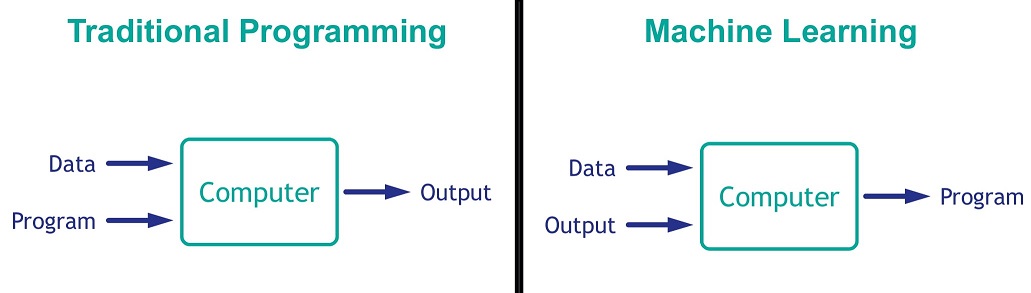
In traditional programming, a program is manually developed that, when executed on input data, generates the desired output. In machine learning, the computer takes sample data and its known (or expected) output to develop a program (in this case, a predictive model), which can in turn be executed on further data.
The training process is how a machine learning algorithm develops a predictive model. The algorithm uses sample data, or training data, to identify patterns that map the inputs to the desired output. These inputs (or features) and outputs (or labels) are columns in the data set. A trained machine learning model has an algorithmically derived relationship between the features and the resulting label.
After training a model, but before deployment, you can validate your model to confirm that is useful on data aside from the data that was used to train it. Model validation is the process of evaluating a model’s predictive performance by comparing the model’s output to the results of real data. While training data was used to train the model, testing data is used to validate it. In the simplest case, the testing dataset is data from an original dataset that is set aside from the training data.
A trained machine learning model is used to make predictions on new data. This data contains the same features as the training and testing data, but without the label column; the label is the output of the model.
A regression model is used to predict continuous numeric values, such as cost, lab result, and so on, and may therefore output a label value (for example, $12.52) that does not appear in the training data. A classification model is used to predict discrete values such as true/false, country name, and so on, where possible label values are defined by those that appear in the training data; for example, if the label is country name, predicted values are restricted to the country names that actually appear in the training data. When using a classification model you can also output the probability of a specified value being the label value for each prediction, allowing you to evaluate the relative strength of predictions of that value.