
Mirroring Architecture and Planning
A mirror is a logical grouping of physically independent InterSystems IRIS® data platform instances simultaneously maintaining exact copies of production databases, so that if the instance providing access to the databases becomes unavailable, another can take over. A mirror can provide high availability through automatic failover, in which a failure of the InterSystems IRIS instance providing database access (or its host system) causes another instance to take over automatically and immediately.
This topic describes the components and mechanics of mirroring and explains issues in mirror planning including network requirements, redirecting application connections following failover, and mirroring in a virtualized environment.
Mirror Components
The system hosting an InterSystems IRIS instance configured as part of a mirror is called a mirror member. (Similarly, the InterSystems IRIS instance is sometimes referred to as a mirror member.) There are two types of mirror member:
Two additional components support automatic failover from one failover member to the other:
Failover Mirror Members
To enable automatic failover, the mirror must contain two failover members, physically independent systems each hosting an InterSystems IRIS instance. At any given time, one failover instance acts as primary, providing applications with access to the databases in the mirror, while the other acts as backup, maintaining synchronized copies of those databases in readiness to take over as primary. When the primary InterSystems IRIS instance becomes unavailable, the backup takes over, providing uninterrupted access to the databases without risk of data loss. See Automatic Failover Mechanics for detailed information about the automatic failover process.
The purpose of the non-primary failover member is to be ready to take over as primary. It is not supported to use this member directly to run queries or application code. If you do attempt to use this member to run queries or application code, the LOCK command will fail with a <PROTECT> error.
This same limitation does not apply to DR and Reporting Async members.
Failover members communicate with each other through several communication channels using several mirror member network addresses. External clients typically connect to the mirror through a virtual IP address (VIP), which is always bound to an interface on the current primary. Application server connections in a mirrored distributed cache cluster are automatically redirected to the new primary following failover, so a VIP is not required in this case.
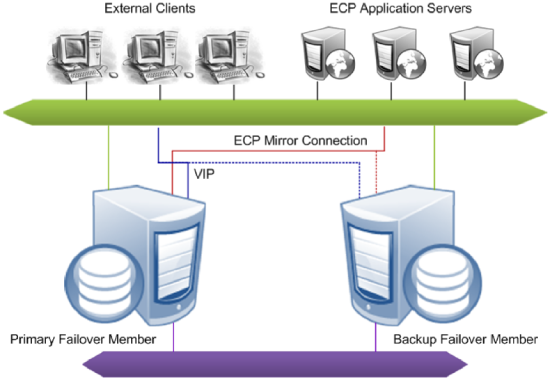
For information about configuring the failover members of a mirror, see Creating a Mirror.
The two failover members in a mirror are assumed to be coequal; neither is preferred as primary. For this reason, primary and backup must be considered temporary designations only. If a problem is detected on the primary and the backup is available to take over it will do so immediately, even if the problem on the primary might resolve on its own given enough time.
Because network latency between the failover members is an important factor in application performance, the relative physical locations of the failover members and the network connection between them should be chosen to minimize latency in the connection; see Network Latency Considerations for more information.
Async Mirror Members
Async members maintain asynchronous copies of mirrored databases. There are two types of async member, disaster recovery and reporting. A single mirror can include up to 16 members, so you can configure a mirror with a failover pair and up to 14 async members of either type in any combination. A mirror can even be configured with a single failover member to utilize async members without automatic failover.
Since the data on an async member is continually asynchronously updated with changes from the mirrors to which it is connected, there is no guarantee of synchronization of updates and synchronization of results across queries on the async member. It is up to the application running against the async member to guarantee consistent results for queries that span changing data.
Also, an async member can be configured for disaster recovery (DR) of a single mirror.
See Configure Async Mirror Members for information about adding an async member to a mirror.
Disaster Recovery Asyncs
A mirror can provide disaster recovery capability through a disaster recovery (DR) async member, which can be manually promoted to failover member and even become primary should both failover members become unavailable due to a disaster. A promoted DR can also be useful in performing planned maintenance on or temporarily replacing a failover member. A DR async member can belong to one mirror only, but you can configure as many as you want in a single mirror, up to the mirror member limit of 16.
Generally speaking, DR async mirror members are a form of geo-replication (or georeplication).
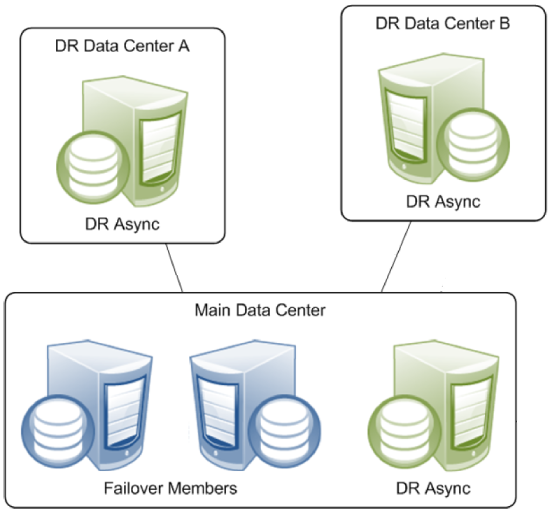
A DR async member is never a candidate for automatic failover, which can be from one failover mirror member to another only.
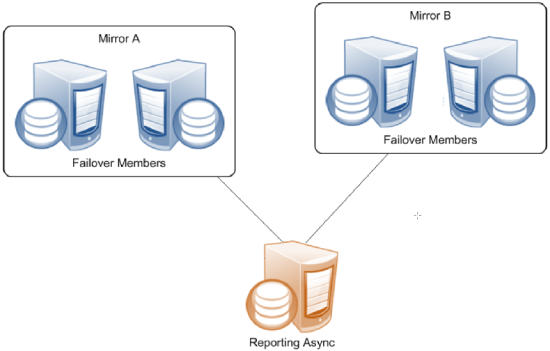
Reporting Asyncs
A reporting async mirror member maintains read-only or read-write copies of selected databases for purposes such as data mining and business intelligence, and cannot be promoted to failover member. A reporting async can belong to up to 10 mirrors, allowing it to function as a comprehensive enterprise-wide data warehouse bringing together sets of related databases from separate locations.
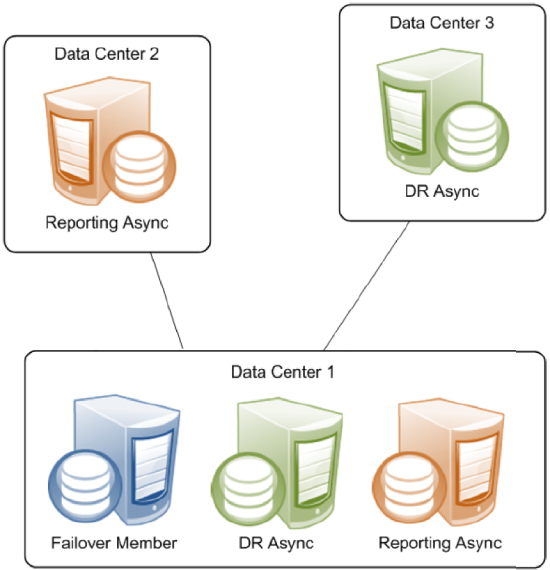
Single Failover Mirror Configuration
A mirror can also consist of a single failover member and one or more asyncs. This configuration does not provide high availability, but can address other needs. For example, a mirror with a single failover member, at least one DR async member, and some number of reporting asyncs can provide data security and disaster recovery while supporting data collection and warehousing. To provide high availability, the failover member can be located in an OS-level failover cluster or some other high-availability configuration (see Failover Strategies for High Availability.
ISCAgent
A process called the ISCAgent runs on each mirror member’s host system, providing an additional means of communication between mirror members. Most importantly, the ISCAgent provides a means by which one failover member can obtain information about the other when normal communication between the two has been interrupted. The ISCAgent can send data to mirror members that have been down or disconnected. The agent is also involved in failover decisions; for example, a backup that has lost contact with both the primary instance and the arbiter can contact the primary’s ISCAgent (assuming the primary’s host system is still operating) to confirm that the primary instance is truly down before taking over.
The ISCAgent is automatically installed with InterSystems IRIS, if not already installed. When multiple InterSystems IRIS instances belonging to one or more mirrors are hosted on a single system, they share a single ISCAgent.
See the sections Automatic Failover Mechanics and Configuring the ISCAgent for detailed information about the role and configuration of the ISCAgent.
Arbiter
The arbiter is an independent system hosting an ISCAgent with which the failover members of a mirror maintain continuous contact, providing them with the context needed to safely make failover decisions when they cannot communicate directly. A single arbiter can serve multiple mirrors, but a single mirror can use only one arbiter at a time. Use of an arbiter is not required, but is strongly recommended as it significantly increases the range of failure scenarios under which automatic failover is possible.

The arbiter plays no role in failover mechanics when the backup is not active.
Configuring a system as arbiter involves minimal software installation and does not require that InterSystems IRIS be installed. The arbiter uses minimal system resources and can be located on a system that is hosting other services, or even a workstation. The primary requirement concerning the arbiter is that it must be located and configured to minimize the risk of unplanned simultaneous outage of the arbiter and a single failover member; see Locating the Arbiter to Optimize Mirror Availability for more information.
Mirror Synchronization
As described in Journaling, journal files contain a time-sequenced record of the changes made to the databases in an InterSystems IRIS instance since the last backup. Within a mirror, the journal data that records a change made to a database on the primary becomes the basis for making that same change to the copy of the database on the backup and asyncs. Mirrored databases are therefore always journaled on the primary, while on the backup and on DR asyncs they are always read only to prevent updates from other sources. Typically they are read-only on reporting asyncs as well.
When data recording global update operations (primarily Set and Kill operations) on mirrored databases is written to the journal on the primary, the journal records are transmitted to other mirror members. Once the journal records are received on the backup or async member, the operations recorded in them are performed on the databases on that member. This process is called dejournaling. (See Managing Database Dejournaling for important information about managing dejournaling on async members.)
Transfer of journal records from the primary to the backup is synchronous, with the primary waiting for acknowledgement from the backup at key points. This keeps the failover members closely synchronized and the backup active, as described in detail in Backup Status and Automatic Failover. An async, in contrast, receives journal data from the primary asynchronously. As a result, an async mirror member may sometimes be a few journal records behind the primary.
When an InterSystems IRIS instance becomes a member of a mirror, the following journaling changes to support mirroring occur:
-
When an InterSystems IRIS instance become the primary failover member in a mirror, the following changes occur:
-
A journal switch is triggered, to a new journal file prefixed with MIRROR-mirror_name, for example MIRROR-MIR21-20180921.001. From that point, all journal files are written as mirror journal files and logged to the mirrorjrn-mirror_name.log, for example mirrorjrn-MIR21.log, as well as to journal.log.
-
The Freeze on error journaling configuration is automatically overridden to freeze all journaled global updates when a journal I/O error occurs, regardless of the current setting. If the current setting is No, behavior reverts to this setting when the instance is no longer a primary failover member. To understand the implications of this, see Configure Journal Settings and Journal I/O Errors.
-
-
When an instance becomes a backup or async mirror member, mirror journal files received from the primary are written to the configured journal directory along with the local instance’s standard journal files, and a copy of the primary’s mirror journal log (mirrorjrn-mirror_name.log) is created in install-dir\Mgr and continuously updated.
See Journaling for general information about journaling.
Automatic Failover Mechanics
Mirroring is designed to provide safe automatic failover to the backup when the primary fails or becomes unavailable. This section describes the mechanisms that allow that to occur, including:
Requirements for Safe Automatic Failover
The backup InterSystems IRIS instance can automatically take over from the primary only if it can ensure that two conditions are met:
-
The backup instance has received the latest journal data from the primary.
This requirement guarantees that all durable updates made to mirrored databases on the primary before the outage have been or will be made to the same databases on the backup, ensuring that no data will be lost.
-
The primary instance is no longer operating as primary and cannot do so without manual intervention.
This requirement eliminates the possibility that both failover members will simultaneously act as primary, which could lead to logical database degradation and loss of integrity.
Automatic Failover Rules
This section describes the rules that govern the automatic failover process and ensure that both automatic failover requirements are met.
The backup does not attempt to become primary under any circumstances unless the following is true:
-
All databases for which Mount Required at Startup is selected, both mirrored and nonmirrored, are mounted.
-
All mirrored database for which Mount Required at Startup is selected are activated and caught up (see Activating and Catching up Mirrored Databases).
For information on Mount Required at Startup, see Edit a Local Database’s Properties.
Backup Status and Automatic Failover
During normal mirror operation, the journal transfer status of the backup failover member is Active, meaning that it has received all journal data from and is synchronized with the primary. (See Mirror Synchronization for information about how the databases on the failover members are synchronized using journal data and related details; see Monitoring Mirrors for information about monitoring the status of mirror members.) An active backup receives the current journal data as it is written on the primary, and the primary waits for an active backup to acknowledge receipt of journal data before considering that data to be durable. An active backup therefore satisfies the first condition for failover.
If an active backup does not acknowledge receipt of new data from the primary within the Quality of Service (QoS) Timeout, the primary revokes the backup’s active status, disconnects the backup and temporarily enters the trouble state. While in the trouble state, the primary does not commit any new journal data (perhaps causing a pause in the application), allowing time for contact to be restored or for appropriate and safe failover decisions to take place without the two members becoming unsynchronized.
When the backup reconnects to the primary, it first catches up by obtaining all of the most recent journal data from the primary and then becomes active. When the backup has caught up by obtaining the most recent journal data from the primary and acknowledging its receipt, its active status is restored.
Automatic Failover When the Backup is Active
When the backup is active, it is eligible to take over as primary if it can confirm the second condition for failover—that the primary is not operating as primary and can no longer do so without human intervention. The backup can do this in one of three ways:
-
By receiving a communication from the primary requesting that it take over.
This happens during a normal shutdown of the primary instance or when the primary detects that it is hung. Once the primary sends this message it can no longer act as primary and the active backup can safely take over. If the former primary is hung, the new primary forces it down.
-
By receiving information from the arbiter that it has lost contact with the primary.
The primary and backup InterSystems IRIS instances maintain continuous contact with the arbiter, which updates each of them whenever contact with the other failover member is broken or restored. When a network event simultaneously isolates the primary from both the backup and the arbiter, it enters the trouble state indefinitely. Thus, if an active backup loses contact with the primary and learns from the arbiter that it too has lost contact with the primary, the backup can safely take over, because the primary must either have failed or be isolated and in a trouble state and thus can no longer act as primary. When connectivity is restored, if the former primary is hung, the new primary forces it down.
-
By receiving information from the primary system’s ISCAgent that the primary instance is down or hung.
When the arbiter is unavailable or no arbiter is configured, an active backup that has lost contact with the primary instance can attempt to contact the primary’s ISCAgent (this is possible only when the primary’s host system is still operating) to confirm that the primary instance is down, or to force it down if it is hung. Once the agent confirms that the primary can no longer act as primary and failover is therefore safe, the backup takes over.
When the primary is isolated from an active backup by a network event but the backup cannot confirm safe failover conditions in one of these ways, the backup is no longer active and is subject to the failover mechanics described in the following section.
When the primary is forced down, it will remain down until a person manually restarts the instance.
Automatic Failover When the Backup is Not Active
A backup that is not active can attempt to contact the primary’s ISCAgent to confirm that the primary instance is down or force it down if it is hung, and to obtain the primary’s most recent journal data from the agent. If successful on both counts, the backup can safely take over as primary.
A backup that is not active and cannot contact the primary’s ISCAgent has no way to ensure that the primary can no longer act as primary and that it has the latest journal updates from the primary, and therefore cannot take over.
The arbiter plays no role in failover mechanics when the backup is not active.
Mirror Response to Various Outage Scenarios
This section summarizes the mirror’s response to outages of the failover members and arbiter in different combinations.
It is possible for an operator to temporarily bring the primary system down without causing a failover to occur (see Avoiding Unwanted Failover During Maintenance of Failover Members). This can be useful, for example, in the event the primary system needs to be brought down for a very short period of time for maintenance. After bringing the primary system back up, the default behavior of automatic failover is restored.
Several of the scenarios discussed here refer to the option of manually forcing the backup to become primary. For information about this procedure, see Unplanned Outage of Primary Failover Member Without Automatic Failover.
Automatic Failover in Response to Primary Outage Scenarios
While circumstances and details vary, there are several main primary outage scenarios under which an active backup failover member automatically takes over, as follows:
-
A planned outage of the primary, for example for maintenance purposes, is initiated by shutting down its InterSystems IRIS instance.
Automatic failover occurs because the active backup is instructed by the primary to take over.
-
The primary InterSystems IRIS instance hangs due to an unexpected condition.
Automatic failover occurs because the primary detects that it is hung and instructs the active backup to take over.
-
The primary InterSystems IRIS instance is forced down or becomes entirely unresponsive due to an unexpected condition.
Under this scenario, the primary cannot instruct the backup to take over. However, an active backup takes over either after learning from the arbiter that it has also lost contact with the primary or by contacting the primary’s ISCAgent and obtaining confirmation that the primary is down.
-
The primary’s storage subsystem fails.
A typical consequence of a storage failure is that the primary instance hangs due to I/O errors, in which case the primary detects that it is hung and instructs the active backup to take over (as in scenario 2). Under some circumstances, however, the behavior described under scenario 3 or scenario 5 may apply.
-
The primary’s host system fails or becomes unresponsive.
Automatic failover occurs if the active backup learns from the arbiter that it has also lost contact with the primary.
If no arbiter is configured or if the arbiter became unavailable prior to the primary host failure, automatic failover is not possible; under these circumstances, manually forcing the backup to become primary may be an option.
-
A network problem isolates the primary.
If an arbiter is configured and both failover members were connected to it at the time of the network failure, the primary enters the trouble state indefinitely.
-
If the active backup learns from the arbiter that it has also lost contact with the primary, automatic failover occurs.
-
If the backup loses contact with the arbiter at the same time as it loses contact with the primary, automatic failover is not possible. If both failover members are up, when the network is restored the backup contacts the primary, which then resumes operation as primary. Alternatively, a primary can be designated manually.
If no arbiter is configured or one of the failover members disconnected from it before the network failure, automatic failover is not possible and the primary continues running as primary.
-
A backup that is not active (because it is starting up or has fallen behind) can take over under scenarios 1 through 4 above by contacting the primary’s ISCAgent and obtaining the most recent journal data. A backup that is not active cannot take over under scenarios 5 and 6 because it cannot contact the ISCAgent; under these circumstances; manually forcing the backup to become primary may be an option.
Effect of Arbiter Outage
An outage of the arbiter has no direct effect on the availability of the mirror. However, if primary outage scenarios 5 or 6 in Automatic Failover in Response to Primary Outage Scenarios occur before the arbiter is restored, the backup cannot take over automatically.
Effect of Backup Outage
Some applications may experience a brief pause (approximately the QoS timeout) before the primary can resume processing. If no arbiter is configured, or if the arbiter became unavailable prior to the backup outage, the pause experienced may be slightly longer (about three times the QoS timeout). If a primary outage occurs before the backup is restored, the result is a total mirror outage.
Effect of Combined Primary and Arbiter Outage
The consequences of this scenario are covered in Automatic Failover in Response to Primary Outage Scenarios. In brief, if the backup can contact the primary’s ISCAgent, it takes over; if not, the result is a total mirror outage, and manual intervention to force the backup to become primary may be an appropriate option.
Effect of Combined Backup and Arbiter Outage
If the backup and arbiter become unavailable simultaneously (or nearly simultaneously), the primary remains in trouble state indefinitely, because it assumes it is isolated and the backup could therefore have become primary. The result is a total mirror outage. When the backup becomes available again it contacts the primary, which then resumes operation as primary. Alternatively, the primary can be forced to resume through manual intervention. If the backup and arbiter fail in sequence, the primary continues operating as primary, after the brief pause described in Effect of Backup Outage, because it knows the backup cannot have become primary.
Effect of Combined Primary and Backup Outage
The result of this combination is always a total mirror outage. See Unplanned Outage of Both Failover Members for available options in this situation.
Locating the Arbiter to Optimize Mirror Availability
Together, the failover members and arbiter provide the mirroring high availability solution (with the arbiter playing the least significant role). The arbiter is not a quorum mechanism, but rather supports each failover member in arbitrating automatic failover by providing context when it loses contact with the other failover member; as long as both failover members are in contact with the arbiter immediately prior to a primary outage of any kind and the backup remains in contact with the arbiter, automatic failover can occur. While failure of the arbiter does eliminate the possibility of automatic failover under some circumstances, it does not prevent the mirror from operating while a replacement is configured, or from providing automatic failover under many primary outage scenarios, for example scenarios 1 through 4 in Automatic Failover in Response to Primary Outage Scenarios.
For these reasons, the arbiter need not be any more highly available than either of the failover members are independently, but only located and configured so that the risk of unplanned simultaneous outage of the arbiter and a single failover member is minimized. (If both failover members fail, the mirror fails and the status of the arbiter does not matter, so risk of simultaneous outage of all three is not a consideration.)
Based on this requirement, InterSystems recommends that, in general, the arbiter be separated from the failover members to the same extent to which they are separated from each other. Specifically,
-
If the failover members are located in one data center, the arbiter can be placed in the same data center. Within that data center, the arbiter should have the same physical separation from the failover members as they have from each other; for example, if you have placed the failover members in separate server racks to avoid power or network problems in one rack affecting both members, you should locate the arbiter separately from those two racks.
If the data center uses an internal network for communication within the mirror, the arbiter should be placed on the public side of the network so that failure of the internal network does not isolate the failover members from the arbiter in addition to each other.
-
If the failover members are located in separate data centers, the arbiter should be placed in a third location. This could be another data center, a location hosted by another party, or a public or private cloud service. Placing the arbiter in a location that is representative of the user community supports optimal mirror response to network outages.
A single system can be configured as arbiter for multiple mirrors, provided its location is appropriate for each; simply specify its host and port number, as described in Creating a Mirror , when creating or editing each mirror for which it will server as arbiter.
The arbiter need not be hosted on a newly deployed or dedicated system; in fact, an existing host of well-established reliability may be preferable. A reporting async mirror member (see Reporting Asyncs) can serve as a suitable host. Hosting on a DR async, however, should be avoided, as promotion of the DR async (see Promoting a DR Async Member to Failover Member) under a maintenance or failure scenario could lead to the arbiter being hosted on a failover mirror member, an incorrect configuration.
As noted in Installing the Arbiter, any system with a running ISCAgent can be configured as arbiter, including one that hosts one or more instance of InterSystems IRIS. However, a system hosting one or more failover or DR async members of a mirror should not be configured as arbiter for that mirror.
Automatic Failover Mechanics Detailed
This section provides additional detail on the mechanics of failover.
The mirror’s response to loss of contact between the failover members or between a failover member and the arbiter is supported by the use of two different mirror failover modes, as follows:
Agent Controlled Mode
When a mirror starts, the failover members begin operation in agent controlled mode. If the arbiter is not available or no arbiter is configured, they remain in this mode. When in agent controlled mode, the failover members respond to loss of contact with each other as described in the following.
If the primary loses its connection to an active backup, or exceeds the QoS timeout waiting for it to acknowledge receipt of data, the primary revokes the backup’s active status and enters the trouble state, waiting for the backup to acknowledge that it is no longer active. When the primary receives acknowledgement from the backup or the trouble timeout (which is two times the QoS timeout) expires, the primary exits the trouble state, resuming operation as primary.
If the primary loses its connection to a backup that is not active, it continues operating as primary and does not enter the trouble state.
If the backup loses its connection to the primary, or exceeds the QoS timeout waiting for a message from the primary, it attempts to contact the primary’s ISCAgent. If the agent reports that the primary instance is still operating as primary, the backup reconnects. If the agent confirms that the primary is down or that it has forced the primary down, the backup behaves as follows:
-
If the backup is active and the agent confirms that the primary is down within the trouble timeout, the backup takes over as primary.
-
If the backup is not active, or the trouble timeout is exceeded, the backup takes over if the agent confirms that the primary is down and if it can obtain the latest journal data from the agent.
Whether it is active or not, the backup can never automatically take over in agent controlled mode unless the primary itself confirms that it is hung or the primary’s agent confirms that the primary is down (possibly after forcing it down), neither of which can occur if the primary’s host is down or network isolated.
When one of the failover members restarts, it attempts to contact the other's ISCAgent and its behavior is as described for a backup that is not active.
Arbiter Controlled Mode
When the failover members are connected to each other, both are connected to the arbiter, and the backup is active, they enter arbiter controlled mode, in which the failover members respond to loss of contact between them based on information about the other failover member provided by the arbiter. Because each failover member responds to the loss of its arbiter connection by testing its connection to the other failover member, and vice versa, multiple connection losses arising from a single network event are processed as a single event.
In arbiter controlled mode, if either failover member loses its arbiter connection only, or the backup loses its active status, the failover members coordinate a switch to agent controlled mode and respond to further events as described for that mode.
If the connection between the primary and the backup is broken in arbiter controlled mode, each failover member responds based on the state of the arbiter connections as described in the following.
If the primary loses its connection to an active backup, or exceeds the QoS timeout waiting for it to acknowledge receipt of data, and learns from the arbiter that the arbiter has also lost its connection to the backup or exceeded the QoS timeout waiting for a response from the backup, the primary continues operating as primary and switches to agent controlled mode.
If the primary learns that the arbiter is still connected to the backup, it enters the trouble state and attempts to coordinate a switch to agent controlled mode with the backup through the arbiter. When either the coordinated switch is accomplished, or the primary learns that the backup is no longer connected to the arbiter, the primary returns to normal operation as primary.
If the primary has lost its arbiter connection as well as its connection to the backup, it remains in the trouble state indefinitely so that the backup can safely take over. If failover occurs, when the connection is restored the primary shuts down.
The trouble timeout does not apply in arbiter controlled mode.
If the backup loses its connection to the primary, or exceeds the QoS timeout waiting for a message from the primary, and learns from the arbiter that the arbiter has also lost its connection to the primary or exceeded the QoS timeout waiting for a response from the primary, the backup takes over as primary and switches to agent controlled mode. When connectivity is restored, if the former primary is not already down, the new primary forces it down.
If the backup learns that the arbiter is still connected to the primary, it no longer considers itself active, switches to agent controlled mode, and coordinates with the primary’s switch to agent controlled mode through the arbiter; the backup then attempts to reconnect to the primary.
If the backup has lost its arbiter connection as well as its connection to the primary, it switches to agent controlled mode and attempts to contact the primary’s ISCAgent per the agent controlled mechanics.
The following table describes the mirror’s response to all possible combinations of lost connections in arbiter controlled mode. The first three situations represent network failures only, while the others could involve, from a failover member’s viewpoint, either system or network failures (or a combination). The descriptions assume that immediately prior to the loss of one or more connections, the failover members and arbiter were all in contact with each other and the backup was active.
The mirror's response to most combinations of connection losses in arbiter controlled mode is to switch to agent controlled mode. Therefore, once one failure event has been handled, responses to a subsequent event that occurs before all connections are reestablished are the same as those described for agent controlled mode rather than the responses described in the table.
 |
All three systems connected:
|
 |
Backup loses connection to arbiter, still connected to primary:
|
 |
Primary loses connection to arbiter, still connected to backup:
|
 |
Failover members lose connection to each other, still connected to arbiter:
|
 |
Arbiter failed or isolated — failover members lose connections to arbiter, still connected to each other:
|
 |
Backup failed or isolated — primary and arbiter lose connections to backup, still connected to each other:
|
 |
Primary failed or isolated — backup and arbiter lose connections to primary, still connected to each other:
|
 |
All three connections lost:
Loss of all connections due to a single event (or multiple simultaneous events) is rare. In most cases, the mirror has switched to agent controlled mode before all connections are lost, in which case:
|
Preventing Automatic Failover
If you want to prevent a mirror from automatically failing over under any circumstances, the best approach is to configure a single failover member with one or more DR asyncs (see Async Mirror Members). A DR async never takes over automatically but can easily be promoted to failover member, including to primary when desired (see Promoting a DR Async Member to Failover Member).
To temporarily prevent automatic failover to backup during maintenance activity, you can temporarily demote the backup to DR async or use the nofailover option; both are described in Planned Outage Procedures, which provides procedures for performing maintenance on failover members without disrupting mirror operation.
If you require application intervention at various points in the automatic failover process, see Using the ^ZMIRROR Routine.
Mirroring Communication
This section discusses the details of communication between mirror members, including:
Network Configuration Considerations
The following general network configuration items should be considered when configuring the network between two failover members:
-
Reliability — For maximum reliability, an isolated (private) network should be configured for mirror communication between the two failover members (as illustrated in Sample Mirroring Architecture and Network Configurations). Additionally, this network should be configured in a redundant fashion (multiple NICs with failover-bonded ports, multiple redundant switches, and so on).
-
Bandwidth — Sufficient bandwidth must be available to transfer the volume of journal data generated by the application.
-
Latency — Network latency between the failover members is an important factor in application performance; see Network Latency Considerations for more information.
Mirror synchronization occurs as part of the journal write cycle on the primary failover member. It is important to allow the journal write cycle and, therefore, the mirror synchronization process to complete as soon as possible. Any delays in this process can result in performance degradation.
See Configuring a Mirror Virtual IP (VIP) for important networking requirements and considerations when using a VIP.
Network Latency Considerations
While there is no strict upper limit on network latency between failover members, the performance impact depends on the application and its workload. In the case of interoperability, however, InterSystems recommends less than 3ms of latency. This is because synchronous commits on inbound messages in the business service can otherwise throttle the rate at which messages are accepted. In such synchronous setups, low latency is crucial for maintaining performance.
The impact of increasing latency differs by application. If the round trip time between the failover members is similar to the disk write service time, no impact is expected. However, for applications that rely on synchronous operations–such as transaction commits or journal synchronization–latency becomes a critical factor. In nonmirrored environments, the wait for data to become durable includes a synchronous disk write of journal data; in mirrored environments with an active backup, it also includes a network round trip between the failover members. For asynchronous mirrors or nonmirrored systems, latency is typically less of a concern unless they transition to synchronous failover roles.
The mechanisms by which an application waits can include the following:
-
Transaction commit in synchronous commit mode (nondefault).
-
The Sync() method of %SYS.Journal.SystemOpens in a new tab.
-
A distributed cache cluster data server waiting for durability before responding to common requests from applications running on application servers (as part of application synchronization actions, such as locks and $increment).
-
Business Services SyncCommit capability (default)
Whether the round trip time, even if relatively large, negatively affects application response time or throughput depends on the frequency with which the above occur within the application, and whether the application processes such activity in serial or in parallel.
When network latency between mirror members becomes an issue, you may be able to reduce it by fine-tuning the operating system TCP parameters that govern the maximum values of SO_SNDBUF and SO_RCVBUF, allowing the primary and backup/asyncs to establish send and receive buffers, respectively, of appropriate size, up to 16 MB. The buffer size required can be calculated by multiplying the peak bandwidth needed (see Incoming Journal Transfer Rate) by the round trip time, and roughly doubling the product for protocol overhead and future growth. For example, suppose the following conditions apply:
-
Traffic between the primary mirror site and a DR site is 60 MB per second of journal data at peak,
-
Compression is used to reduce the bandwidth required to about 33% of the journal rate.
-
The round trip time is 50 milliseconds (typical for a distance of 1000 miles).
In this case, 60 MB * 0.05 * .33 * 2 = 2 MB minimum buffer size. In asynchronous or DR setups, larger buffer sizes can often compensate for higher latency. However, if these systems are expected to act as failover mirrors, low latency becomes important.
Mirror Traffic Compression
When creating or editing a mirror (see Create a mirror and configure the first failover member or Editing or Removing a Failover Member, respectively), you can select the compression mode for mirror traffic from the primary to the backup and from the primary to async members, as follows:
-
System Selected — Use a compression strategy that is optimal for most environments. When transmitting to the backup member, this means assuming a high-bandwidth, low-latency connection and optimizing for response time; that is, journal data is compressed before transmission when this will reduce the time required to synchronize the failover members. When transmitting to async members, it means optimizing for network utilization. System Selected is the default for both the failover members and asyncs.
Currently, for transmission to the backup, this setting causes LZ4 compression to be used only when the mirror requires TLS, as described in Securing Mirror Communication with TLS Security; for transmission to asyncs, Zstd compression is always used. Over time this behavior may change based on improved mechanisms for analyzing the network environment and optimizing compression behavior.
-
Uncompressed — Never compress mirror traffic.
-
Compressed — Always compress mirror traffic. When you select this setting, you must select one of the three compression types: zlib (the default), Zstd, or LZ4.
When Zstd or LZ4 compression is in use due to either System Selected mode or user choice in Compressed mode, and the receiving system does not support that type, zlib compression is used instead.
Choosing Uncompressed is desirable if the vast majority of the volume of database updates consist of data that is already highly compressed or encrypted, where the overall efficacy of compression is expected to be very low. In that case, CPU time may be wasted on compression. Examples include compressed images, other compressed media, or data that is encrypted before it is set into the database (using InterSystems IRIS data-element encryption or another encryption methodology). Use of InterSystems IRIS database encryption or journal encryption is not a factor in selecting compression.
Both compression and TLS encryption introduce some computational overhead that affects both throughput and latency. The overhead introduced by each is similar, but when TLS encryption is used, the addition of compression can actually reduce that overhead and improve performance by reducing the amount of data that needs to be encrypted. The specifics vary by operating system, CPU architecture, and the compressibility of application data. More specifically:
-
Use of compression and/or TLS encryption can limit the transfer rate due to the computation time required to compress the data; the maximum transfer rate is limited to the maximum compression rate. For most configurations, the maximum transfer rate imposed by compression and TLS encryption is much higher than the actual maximum throughput required by mirroring. As an example, on a typical system as of this writing, the computational rate to compress and encrypt may be in the range of 100 MB per second, which is several times greater than the peak journal creation rate for a large enterprise application.
-
Use of compression and/or TLS encryption introduces a “computational latency” that gets added to the network latency (see Network Latency Considerations). This is negligible for most applications. If a configuration requires higher throughput than can be achieved with compression and/or TLS encryption enabled, then they must be disabled (TLS can still be used for authentication) and sufficient bandwidth for peak transfer without compression must be provided.
Mirror Member Network Addresses
Mirror members use several network addresses to communicate with each other. These are described in this section and referred to in Sample Mirroring Architecture and Network Configurations. Note that the same network address may be used for some or all of the mirror addresses described here.
-
Mirror private address
When an InterSystems IRIS instance is running as the primary failover member, each of the other mirror members uses the mirror private address to establish its mirror data channel, the channel over which it receives journal data from the primary and the most heavily used mirror communication channel. A second failover member attempting to become the backup must connect to this address. This applies to a DR async that is promoted to failover member; if the promoted DR does not have access to the other failover member’s private address, it can still become primary when the other failover member is down, but cannot become backup.
The primary may also use the mirror private address to monitor async members.
Async members attempt to connect to the primary’s mirror private address, but fall back to the primary’s superserver address if they cannot reach the primary at the mirror private address. Because of this and because an ISCAgent can send journal data to other mirror members, journal data does travel over networks other than the mirror private network in some cases.
Note:When adding an async member to a mirror using the Management Portal (see Configure async mirror members), you enter an Async Member Address; the address you provide at this prompt becomes the async member’s mirror private address and superserver address. If you want these to be different, you can update the async’s addresses on the primary after adding it to the mirror.
-
Superserver address/port
External mirror-aware systems can connect to the primary using this address. Currently the only such external systems are application servers in a mirrored distributed cache cluster (see Redirecting Application Connections Following Failover or Disaster Recovery), although in the future this may extend to other connections. Other mirror members may also make connections to a member's superserver address for certain control and monitoring purposes; for example, the primary may use this address to monitor async members. An async member attempts to establish its data channel to the primary using this address if the primary’s mirror private address is not accessible, which means that journal data may travel over this network.
-
Agent address/port
When attempting to contact this member’s agent, other members try this address first. Critical agent functions (such as those involved in failover decisions) will retry on the mirror private and superserver addresses (if different) when this address is not accessible. Because the agent can send journal data to other members, journal data may travel over this network.
-
Virtual IP (VIP) address
If you are using a virtual IP (VIP) address as described in Planning a Mirror Virtual IP (VIP), you must enter the VIP address when creating or editing the primary failover member. The primary registers itself with this address dynamically as part of becoming primary; the two failover members must be on the same subnet of the network associated with the VIP so that the backup can acquire the VIP during failover. Administrators typically give the VIP address a DNS name on the DNS server. This address should never be used elsewhere in the mirroring configuration (nor as an address for application servers to connect to; ECP has its own mechanism of finding the primary using superserver addresses).
-
Arbiter address/port (outgoing)
The address used by the failover members to connect to the arbiter; this address is configured when creating or editing the primary failover member. See Locating the Arbiter to Optimize Mirror Availability for important information about the network location of the arbiter.
While it is optional to configure TLS for mirror communication between the addresses described here, it is highly recommended, because sensitive data passes between the failover members, and TLS provides authentication for the ISCAgent, which provides remote access to journal files and can force down the system or manipulate its virtual IP address. If an instance has journal encryption enabled and you make it the primary failover member of a mirror, you must configure the mirror to use TLS. For more information, see Securing Mirror Communication with TLS Security.
Sample Mirroring Architecture and Network Configurations
This section describes and illustrates several sample mirroring architectures and configurations.
-
Mirroring Configurations within a Single Data Center, Computer Room, or Campus
-
Mirroring Configurations For Dual Data Centers and Geographically Separated Disaster Recovery
Some diagrams depict a disaster recovery (DR) async member and a reporting async member in variety of locations. One or both may be omitted, multiples of each are allowed, and in general the locations depicted in different diagrams may be combined.
For purposes of illustration, sample IPv4 addresses on the organization's internal network are shown. Assume that subnets are specified by 24 bits (that is, CIDR notation a.b.c.d/24 or netmask 255.255.255.0) so addresses that are depicted on the same subnet will differ only in the fourth dot-delimited portion.
Equivalent DNS names may also be specified in place of IP addresses in the mirror configuration, except for the mirror virtual IP (VIP) address, which must be an IP address.
Mirroring Configurations within a Single Data Center, Computer Room, or Campus
The following diagrams illustrate a variety of mirroring configurations typical within a data center, computer room, or campus. Each diagram describes the appropriate network topology, and the relationship to the network addresses specified in the mirror configuration. Variations are described, and may be particularly applicable when mirror members reside in multiple locations within the campus.
Simple Failover Pair
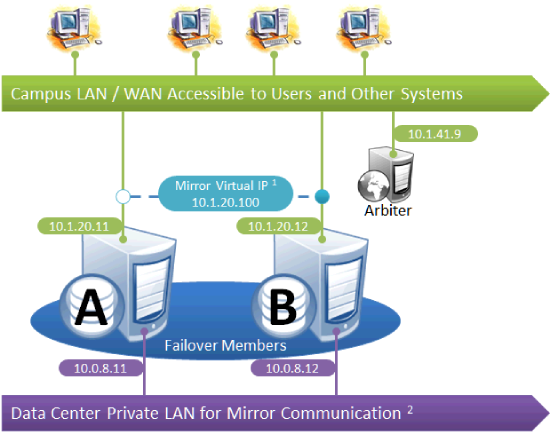
This is the simplest mirror configuration. The failover members communicate with each other over a private network while external connections to them are made over a public network, optionally through a mirror virtual IP (VIP). The arbiter is on the external network (as recommended in Locating the Arbiter to Optimize Mirror Availability), but since it is always the failover members that initiate connections to the arbiter, the VIP is not involved in these connections.
The following IP addresses are used in this configuration:

Notes:
-
A VIP requires both failover members to be on the same subnet.
-
While not required for mirroring, the separate, private LAN for mirror communication depicted here is recommended for optimal control of network utilization. If such a LAN is not used, the mirror private addresses in the mirror configuration should be changed to use the addresses depicted on green backgrounds. Although the mirror private addresses as shown imply that the members are on the same subnet of this network, this is not required.
Failover Pair with DR and Reporting Ayncs Homogeneously Connected
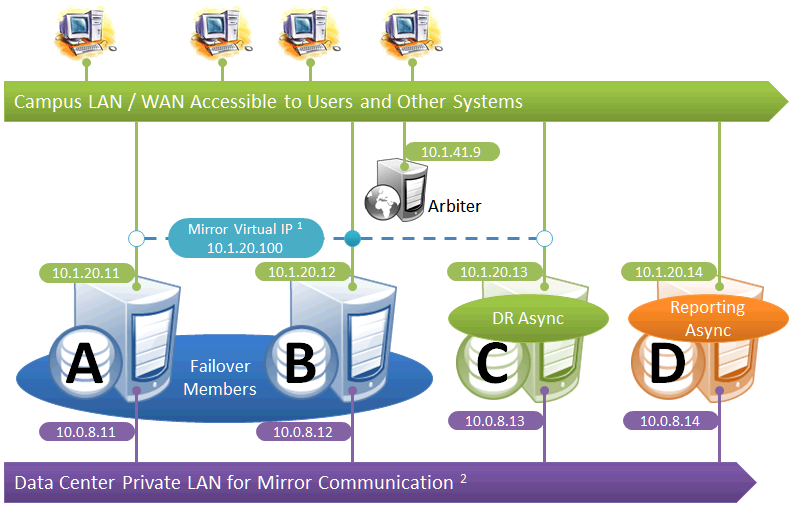
This configuration allows maximum functional flexibility for the DR async, allowing it to be promoted to replace a failover member that is down for maintenance or repair, in addition to providing disaster recovery capability. The promoted DR can function fully as backup or primary and participates in the VIP. The failover members and DR are on the same public-facing subnet for the VIP. Their private network addresses, if used, are accessible to one another (if not the same subnet, then by routing). Network topology and latency may place constraints on the physical separation possible between the DR and the two failover members.
The following IP addresses are used in this configuration:
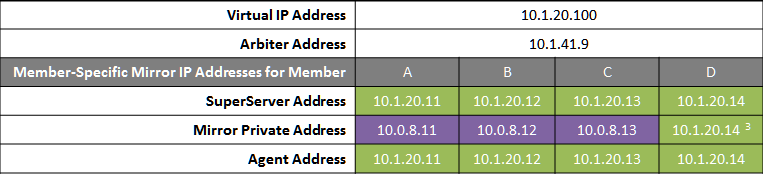
Notes:
-
All members that may hold or acquire the VIP must be on the same subnet.
-
A separate, private LAN for mirror communication as depicted here is not required for mirroring, but is recommended for optimal control of network utilization. If such a LAN is not used, the mirror private addresses should be changed in the mirror configuration to use the addresses depicted in green. Although the depicted mirror private addresses imply that the members are on the same subnet of this network, this is not required.
-
Since reporting members can never become primary, they make only outgoing connections on the mirror private network. Therefore that address need not be separately specified in the mirror configuration.
Failover Pair with DR and Reporting Anywhere on Campus
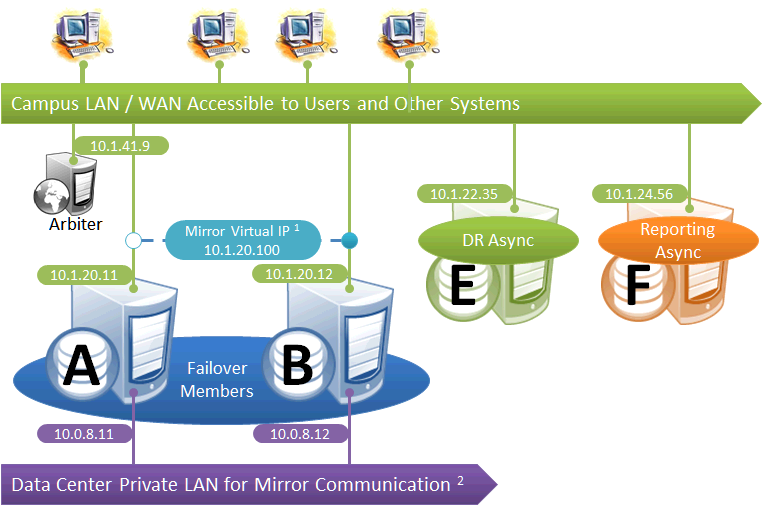
This configuration allows maximum flexibility in the locations of async members and the network connecting them. Since the DR in this configuration is not assumed to be on the VIP subnet, some alternative means must be used to redirect user connections to the DR during disaster recovery; for example, manually updating the DNS name to point to the DR async’s IP instead of the VIP, or configuring one of the mechanisms discussed in Redirecting Application Connections Following Failover. Additionally, since the DR member is not assumed to have connectivity to the mirror private network (if used), it can be promoted only when no failover member is in operation, and only to become primary.
The following IP addresses are used in this configuration:
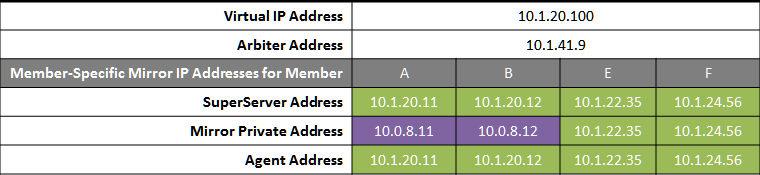
Notes:
-
Any member that is to acquire the Virtual IP must be on the same subnet.
-
A separate, private LAN for mirror communication is depicted here but not required. If such a LAN not used, the mirror private addresses should be changed in the mirror configuration to use the addresses depicted in green. Although the depicted mirror private addresses imply that the failover members are on the same subnet of this network, this is not required.
Mirroring for Disaster Recovery and Reporting Only
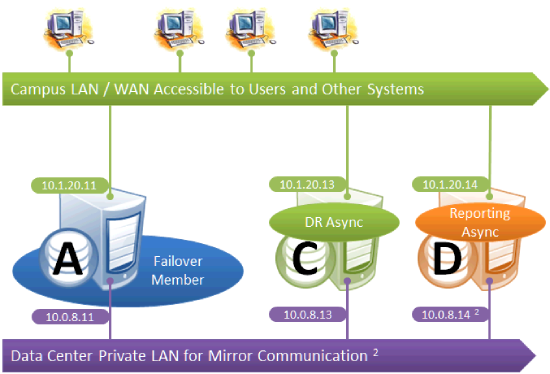
This configuration uses mirroring to provide DR and/or reporting capabilities only. High availability is provided for the single failover member using OS failover clustering, virtualization HA or other infrastructure-level options as described in Failover Strategies for High Availability. Since mirroring is not used for automatic failover in this configuration, no VIP is depicted. If desired, a VIP can be configured for use during disaster recovery, but this requires the DR member to be on the same subnet as the failover member. Otherwise, alternative technology or procedures such as those discussed in Redirecting Application Connections Following Failover must be used to redirect user connections to the DR during disaster recovery.
The following IP addresses are used in this configuration:

Notes:
-
A separate, private LAN for mirror communication is depicted here but not required. If such a LAN is not used, the mirror private addresses should be changed in the mirror configuration to use the addresses depicted in green. Although the depicted mirror private addresses imply that the failover members are on the same subnet of this network, this is not required.
-
Since reporting members can never become primary, they make only outgoing connections on the mirror private network. Therefore that address need not be separately specified in the mirror configuration.
Mirroring in a Distributed Cache Cluster
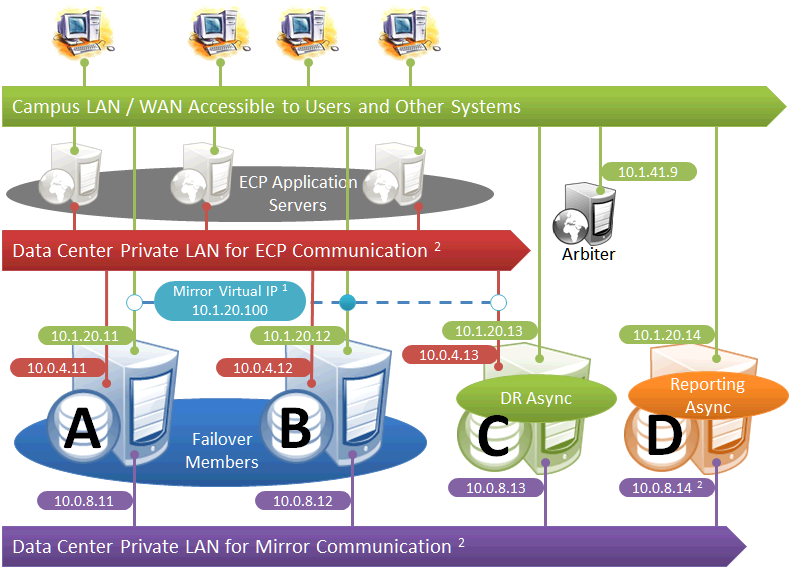
This diagram depicts application servers added to a mirrored environment. While increasing complexity, the application server tier allows horizontal scalability and preserves user sessions across database server failover. For information about distributed caching and distributed cache clusters, see Horizontally Scaling Systems for User Volume with Distributed Caching.
The following IP addresses are used in this configuration:

Notes:
-
Application servers do not use the VIP and will connect to any failover member or promoted DR member that becomes primary, so the VIP is used only for users' direct connections to the primary, if any. A VIP requires both failover members to be on the same subnet. In order for the DR member to acquire the VIP when promoted, it must also reside on the same subnet; if it does not, see Redirecting Application Connections Following Failover.
-
The private LANs for both ECP and mirror communication shown here, while not required, are recommended for both optimal control of network utilization and ECP data privacy. Configurations with fewer networks are possible by collapsing one of the networks into another. Although the private addresses shown imply that the members are on the same subnets of these networks, the only requirement is that the addresses are routable between one another.
When considering network layout, bear in mind that all async members require connectivity to the primary on either the primary's mirror private address or its superserver address. Thus in the depicted configuration, an async member that has access only to the green user network will not function.
-
Since reporting members can never become primary, they make only outgoing connections on the mirror private network. Therefore that address need not be separately specified in the mirror configuration.
Mirroring Configurations For Dual Data Centers and Geographically Separated Disaster Recovery
The following diagrams depict HA and DR configurations utilizing geographical separation for recovery from disasters affecting a data center, campus, or geographic region. Reporting members are omitted from these diagrams for simplicity of illustration, but may be added in either of the locations just as depicted in the single campus configurations.
All of the following configurations require a strategy for redirecting connections to the primary when a member in the other location becomes primary. For geographically separated locations, a VIP may be difficult or impossible to configure because it requires the subnet to be stretched between the two locations. Even if configured, it may not be sufficient, as described in the paragraphs that follow. Alternative technology, hardware, or procedures, such as those discussed in Redirecting Application Connections Following Failover, provide other means of redirecting connections. Whether utilizing a stretched subnet or not, a VIP is extremely useful for automatic failover between two members within a single data center, and its use is depicted in these diagrams for that purpose.
A stretched subnet for VIP is typically useful for internal intranet applications. With it, users and systems with a connection, or VPN access, to the LAN/WAN depicted in green can access the primary in either location over its VIP.
For Internet-facing applications, on the other hand, a stretched subnet for VIP does not provide a solution for connectivity in a disaster. The main data center’s DMZ presents the application's Internet-facing IP address and/or DNS names as a proxy for the internal mirror VIP; in the event of a disaster, they may need to be externally transferred to the other data center. Solutions involve either sophisticated external routing or one of the techniques described in Redirecting Application Connections Following Failover, any one of which obviates the need for a stretched subnet.
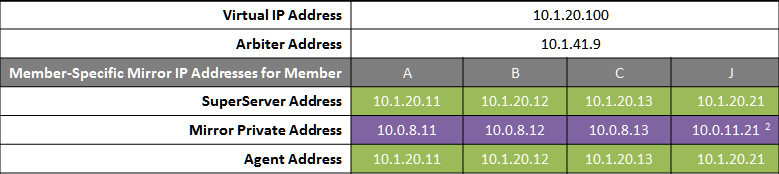
Failover Pair with Local DR and Geographically Separated DR
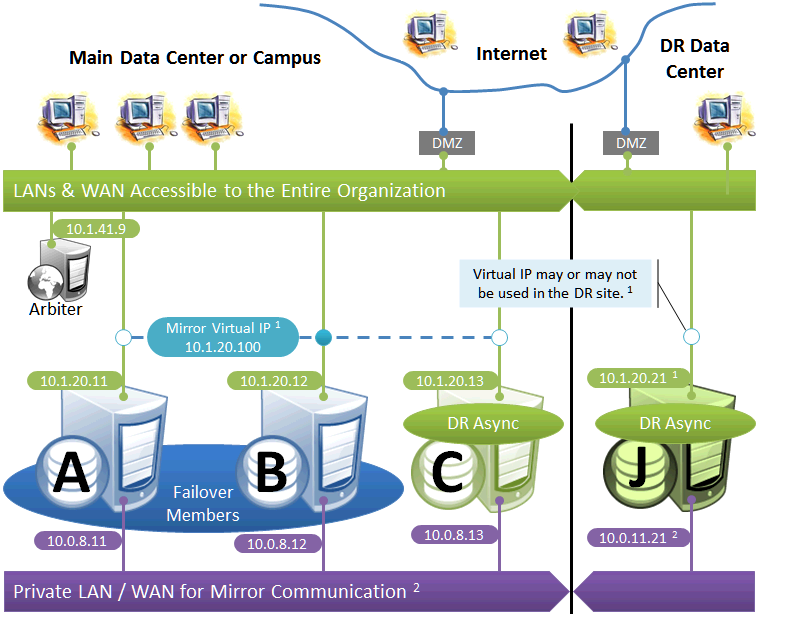
The local DR async provides contingency for events affecting one or both of the failover members. The local DR can be promoted to replace one of the failover members that is down for maintenance or repair, or to recover from a disaster affecting both failover members. The geographically separated DR is used to recover from disasters affecting the entire main data center or campus.
The following IP addresses are used in this configuration:
Notes:
-
See preceding discussion of VIP.
-
When possible, making the mirror private network (if used at all) accessible to the DR data center through the data center interconnect (WAN) offers some additional functional flexibility for member J. This does not require stretching the subnet, only that the traffic on this network is routed between the data centers. In this configuration, when J is promoted, it can connect as backup to the primary in the main data center. If the DR does not have access to the mirror private network, it can be promoted only to function as primary, and that only when no failover member is in operation. The flexibility mentioned here is primarily useful in configurations in which the VIP is stretched and the application is not substantially impacted by latency between the data centers.
Failover Pair with Geographically Separated, Fully Redundant DR Environment
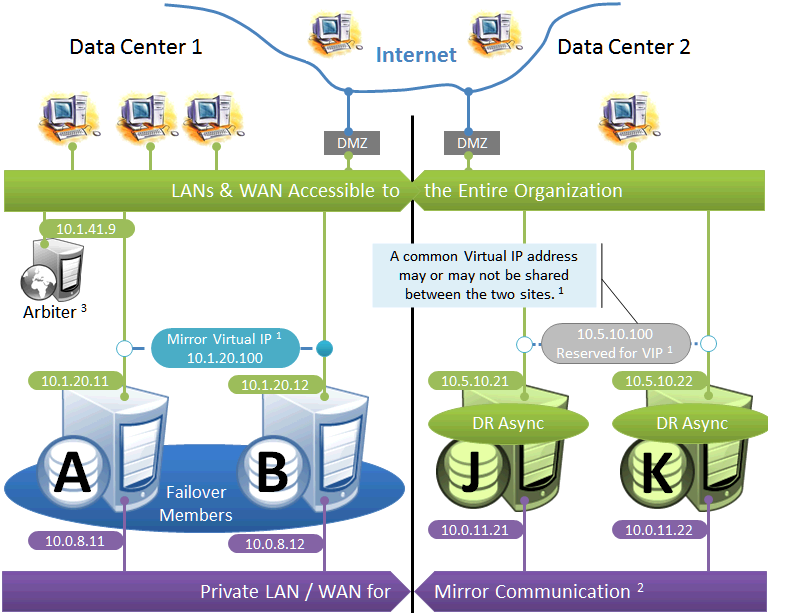
In the event of disaster affecting Data Center 1, two DR members in Data Center 2 are promoted, providing a completely redundant alternate HA environment. The following IP addresses are used in this configuration:
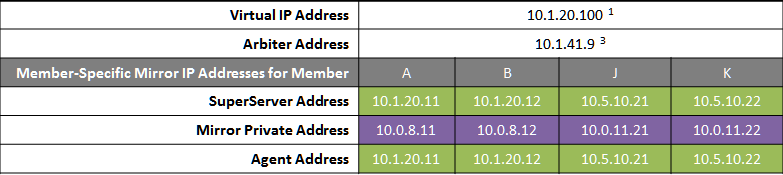
Notes:
-
See preceding discussion of VIP. This illustration does not assume a stretched subnet; instead, upon transitioning to Data Center 2, the mirror is to be reconfigured to use a different VIP for subsequent automatic failovers within that data center. External technology, hardware, or procedures, as discussed in Redirecting Application Connections Following Failover, are then used to redirect connections to the new VIP address.
-
When possible, giving both data centers access to the mirror private network (if used) through the data center interconnect (WAN) adds functional flexibility. This does not require stretching the subnet, only that the traffic on this network is routed between the data centers. In that configuration, a promoted DR member in one data center can connect as backup to the primary in the other. This is useful mainly in configurations in which the VIP is stretched and the application is not substantially impacted by latency between the data centers. (If the DR has no access to the mirror private network, it can be promoted only to function as primary, and that only when no failover member is operating.)
-
In the event that Data Center 1 is completely offline and members J and K are promoted to failover members, a new arbiter can be made available in Data Center 2 and the mirror configuration can be updated with the IP address of the new arbiter. The depicted configuration is not intended to operate for extended periods with two failover members in opposite data centers; if operated in this manner, an arbiter in a separate, third location (the Internet in this depiction) is recommended. See Locating the Arbiter to Optimize Mirror Availability for more details.
Geographically Separated Failover Pair
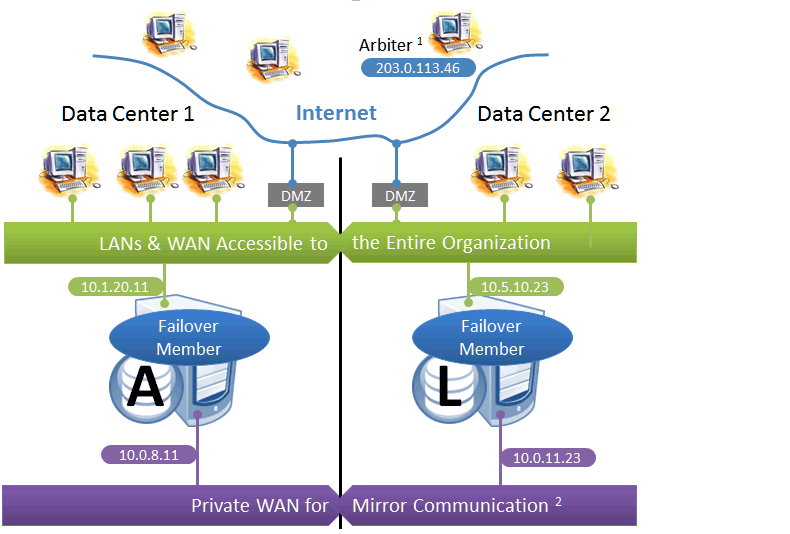
This configuration utilizes two machines in separate locations to achieve both high availability and disaster recovery needs with minimal hardware. Network latency between the failover members is an important consideration, but its impact, if any, depends on the application; see Network latency considerations for more information.
Mirroring does not prefer one failover member over another to act as primary, and a failover may occur as a result of any type of outage, even if the problem on the primary turns out to have been transient. Therefore, this configuration is best used with no implicit preference for the primary running in a particular data center.
Use of a VIP may or may not be possible in this configuration for reasons described in the preceding discussion. Since failover between the two data centers happens automatically, any alternative strategy employed must provide rapid and automatic redirection of users to the new primary; strategies that require manual intervention are typically not sufficient.
The following IP addresses are used in this configuration:

Notes:
-
The arbiter is best placed in a third location in this configuration. See Locating the Arbiter to Optimize Mirror Availability for more details.
-
A private network for mirror communication running over a data center interconnect (WAN) is depicted here but not required.
Redirecting Application Connections Following Failover or Disaster Recovery
When the backup failover member becomes primary through automatic failover or a DR async is manually promoted to primary as part of disaster recovery, some mechanism for redirecting application connections to the new primary is required. There are numerous ways to accomplish this, some of which are discussed in detail on this page. One solution may apply to both automatic failover and DR promotion, or solutions may be combined, for example a mirror VIP for automatic failover and DNS update for DR promotion.
Built-in Mechanisms
The following mechanisms can be included in the mirror configuration, as shown in Sample Mirroring Architecture and Network Configurations, to address application redirection:
-
Mirror virtual IP address (VIP)
When a mirror VIP is in use (see Planning a Mirror Virtual IP (VIP)) and a member becomes primary, the VIP is automatically bound to a local interface on the new primary, allowing external clients to continue to connect to the same IP address. The use of a VIP requires that members eligible to become primary be on the same subnet, as described in Sample Mirroring Architecture and Network Configurations.
Note:Typically, a VIP cannot be used in cloud environments; for information on alternatives and other considerations when mirroring in the cloud, see Mirroring in a Cloud Environment.
-
Distributed cache cluster
In a mirrored distributed cache cluster (see Configuring Application Server Connections to a Mirror), the failover members are configured as data servers and all application server connections are configured specifically as mirror connections. Following failover, application servers reestablish their connections to the new primary failover member and continuing to process their in-progress workload. During the failover process, users connected to the application servers may experience a momentary pause before they are able to resume work. For information about ECP recovery, see ECP Recovery and ECP Recovery Process, Guarantees, and Limitations .
Bear in mind that the primary purpose of distributed caching is horizontal scaling; deploying a cluster simply as a component of your HA strategy can add costs, such as increased complexity and additional points of failure, as well as benefits.
-
Web Gateway
When a Web Gateway Server Access entry is configured to be mirror aware, the Gateway is initially configured to connect to one of the failover members, from which it obtains a list of the failover and DR async members in the mirror. The Gateway identifies and connects to the current primary based on this list. If the mirror fails over, the Gateway changes the connection to the new primary. If no primary can be found among the failover members, the Gateway attempts to find one among the DR asyncs in the list, which enables it to reestablish the connection when a DR async is promoted to primary. A mirror aware Gateway connection uses the superserver addresses to contact the mirror members (see Mirror Member Network Addresses).
Generally, if you have enabled another method of redirecting application connections to the primary (such as a VIP), the best practice is to configure a standard Web Gateway connection to that mechanism, and not a mirror aware connection. A mirror aware Web Gateway connection should be used only as the principal means of redirecting application connections.
By default, Server Access entries are not mirror aware, as it is not appropriate for many Gateway server configurations, including those supporting the InterSystems IRIS Management Portal. See Configuring Server Access for more information about mirror aware Web Gateway connections.
External Technologies
The following mechanisms can be implemented in conjunction with mirroring to address application redirection:
-
Hardware load balancers and site selectors
Redirection of application traffic at the network level can be implemented using mechanisms such as hardware-based site selectors.
-
DNS update
Automatic and manual options are available; some may be too slow for use with automatic failover.
-
Application programming
Individual applications can be adapted to maintain knowledge of mirror members and connect to the current primary.
-
User-level procedures
Users can be provided with the means to connect to multiple mirror members, for example a second icon for connection to the disaster recovery site.
Planning a Mirror Virtual IP (VIP)
As described in Built-in Mechanisms, when a mirror VIP is in use and a member becomes primary, the VIP is reassigned to the new primary, which allows all external clients and connections to interact with a single static IP regardless of which failover member is currently serving as primary.
During the failover process, connected clients that experience a network disconnect are able to reconnect once the backup has become primary. If a VIP is configured, the backup completes the failover only if it is successfully able to assign the VIP; otherwise, the failover process is aborted and the mirror requires manual intervention.
In preparing to set up a mirror VIP, consider the following:
-
To use a mirror VIP, both failover members must be configured in the same subnet, and the VIP must belong to the same subnet as the network interface that is selected on each system. A DR async member must have a network interface on the same subnet to be able to acquire the VIP when promoted to primary as part of disaster recovery; if this is not the case, an alternative redirection mechanism must be incorporated into disaster recovery procedures.
-
When failover and/or DR async members are in separate data centers, a VLAN subnet can be extended across the data centers to continue supporting the same VIP address. This requires Layer 2 connectivity between the two sites and may not be sufficient for all cases; see the discussion in Mirroring Configurations For Dual Data Centers and Geographically Separated Disaster Recovery.
-
You should assign a DNS name for the VIP on your DNS server for use by connecting clients.
-
If a VIP is in use and a failover member is removed from the VIP subnet, that member must be demoted to DR async (see Demoting the Backup to DR Async) or removed from the mirror, or the VIP configuration must be removed from both failover members. Otherwise, when the failover member attempts to take over as primary it will fail to acquire the VIP and therefore fail to become primary.
If one or more of a mirror’s members is a nonroot InterSystems IRIS instance on a UNIX® or Linux system, as described in InterSystems IRIS Nonroot Installation, a mirror VIP cannot be used.
Mirroring in a Virtualized Environment
The use of mirroring in a virtualized environment, in which the InterSystems IRIS instances constituting a mirror are installed on virtual hosts, creates a hybrid high availability solution combining the benefits of mirroring with those of virtualization. While the mirror provides the immediate response to planned or unplanned outages through automatic failover, virtualization HA software automatically restarts the virtual machine hosting a mirror member following an unplanned machine or OS outage. This allows the failed member to quickly rejoin the mirror to act as backup (or to take over as primary if necessary).
When a mirror is configured in a virtualized environment, the following recommendations apply:
-
The failover members’ virtual hosts should be configured so that they will never reside on the same physical host.
-
To avoid a single point of storage failure, the storage used by the InterSystems IRIS instances on the failover members should be permanently isolated in separate datastores on separate disk groups or storage arrays.
-
Some operations performed on the virtualization platform level, such as backup or migration, can cause the failover members to be unresponsive for long enough to result in unwanted failover or an undesirable frequency of alerts. To address this problem, you can increase the QoS timeout setting (see Quality of Service (QoS) Timeout).
-
When conducting planned maintenance operations that cause interruptions in failover member connectivity, you can temporarily stop mirroring on the backup to avoid unwanted failover and alerts.
-
Snapshot management must be used very carefully on mirror members, as reverting a member to an earlier snapshot erases both the most recent status of the member—which may, for example, have been changed from primary to backup since the snapshot was taken—and journal data that is still possessed by other members. In particular,
-
A failover member that has been reverted to an earlier snapshot should be resumed only from a powered-off state; resuming it from a powered-on state creates the possibility of both failover members simultaneously acting as primary.
-
If a failover member that was reverted to an earlier snapshot becomes primary without obtaining all of the journal data created since the snapshot—for example, because it is forced to become primary—all other mirror members must be rebuilt (as described in Rebuilding a Mirror Member).
-
Mirroring in a Cloud Environment
When InterSystems IRIS is deployed on a public cloud platform, mirroring can provide robust high availability and disaster recovery solutions. While the specifics of your deployment will vary depending on your application requirements, some general considerations are:
-
It is best practice to split the failover members between two availability zones within the same region. This configuration balances latency and resiliency considerations.
-
If your application has exceptionally high update workloads or uses synchronous commit transactions, you might consider further reducing latency at the expense of resiliency by deploying using proximity placement groups. These placement groups physically place the virtual machine instances close to each other within a single availability zone which allows for the lowest latency. This configuration is less resilient and should be considered only if exceptionally low latency is necessary for your application.
-
To maximize resiliency, DR async members should be located in a separate region from the failover members.
-
Typically, a VIP cannot be used in cloud environments. Alternatives are available, however. Network traffic management appliances such as load balancers (physical or virtual) can be used to achieve the same level of transparency as a VIP, presenting a single address to the client applications or devices. Depending on the platform, it may also be possible to establish a VIP using a special-purpose configuration. For detailed information about these options for configuring application redirection following failover in a cloud environment, please see Database Mirroring without a Virtual IP AddressOpens in a new tab and VIP on AWSOpens in a new tab on InterSystems Developer Community.
-
The arbiter should generally be placed in the same network tier as web servers or wherever the ingress point to the cloud-based InterSystems IRIS deployment will be. If there are no web or application servers, then the arbiter can be placed in the same tier or security group as the mirror members themselves.
-
In deployments with two availability zones, the arbiter can be placed in either zone. If you already have a third zone deployed for other purposes, then it can be advantageous to locate the arbiter in that zone. Deploying a third zone specifically for the arbiter generally incurs added cost and management overhead incommensurate with any advantage. For more information, see Locating the Arbiter to Optimize Mirror Availability.
-
Encryption is highly recommended when mirroring in the cloud. It is best practice to use encryption on all mirror members, not just the primary member. Database encryption protects the data on the storage volume, but not in transmission between mirror members. To protect data in transmission journal encryption should be configured as well. Public cloud platforms also offer database encryption which may need to be specified when configuring storage volumes. For general information on encryption, see the Encryption Guide.
Limiting Access to the Backup Failover Member
While the system hosting the backup failover member of a mirror may have unused resources or capacity, or you may want to run read only queries on its mirrored databases, InterSystems recommends the best practice of dedicating the host to its role as backup mirror member only. Any mirror-related or nonmirror use of the backup can have the following effects:
-
If a reduction in the backup’s performance causes it to be slow to acknowledge receipt of journal data from the primary, users of applications accessing mirrored databases on the primary may experience reduced performance. Any application interaction that must wait for acknowledgement by the primary, including those that involve an explicit journal synchronizations as well as synchronous commit transactions and ECP activity, may be affected in this manner.
-
If acknowledgement by the backup is delayed enough to prevent it from happening within the QoS timeout, the primary revokes the backup’s active status, causing automatic failover to become more difficult or impossible, depending on the nature of the primary outage.
-
If automatic failover does occur, the backup is now supporting both its existing resource usage and the primary’s user application resource usage. If this is a possibility, the backup host must have the capacity to handle both of these loads.
For these reasons, an async member, not the backup, should be used if user activity must be offloaded from the primary.
Installing Multiple Mirror Members on a Single Host
The InterSystems IRIS instances that make up a mirror are typically installed on separate physical or virtual hosts, but this is not a requirement. Assuming the capacity of the system is sufficient to handle the resource loads involved without incurring reduced performance, multiple mirror members, including multiple mirrors in their entirety, can be installed on the same host; individual circumstances will determine whether this is feasible, and how many mirrors or mirror members can be cohosted.
When cohosting multiple failover members, bear in mind that failover mirroring assumes that the members are coequal; there is no preferred primary member. For this reason, the best practice when placing failover member instances on separate hosts is to make the hosts as similar as possible and roughly equal in capacity. Cohosting failover members has the potential to go outside the bounds of this model. For example, if five mirrors are created on five separate hosts and then five InterSystems IRIS instances on one host are added to the mirrors as second failover members, the mirrors may initially operate with primaries on separate hosts and all backups cohosted on a single system. But if there are two simultaneous or nearly simultaneous outages resulting in failover, the single system is now hosting two primaries and three backups, which may be too large a load for it to handle with adequate performance.
When multiple InterSystems IRIS instances belonging to one or more mirrors are cohosted, they share a single ISCAgent.
When cohosting multiple mirror members, bear in mind the following networking considerations:
-
You must ensure that each mirror uses a unique set of ports on each machine (see Mirror Member Network Addresses), and ensure that other mirror members that are not cohosted, if any, use the same ports. For example, two primaries running on two separate hosts might both use port 1972, but if they can both potentially be replaced by cohosted DR asyncs, as described in the previous item, the new primaries (the former DR asyncs) will have conflicting port assignments. If one primary uses port 1972 and another 1973 and these same ports are configured on the asyncs, the asyncs are ready for simultaneous promotion, and when it happens client can access the mirror using the same ports as before the outages.
-
The failover and DR async members of each mirror (whether entirely or partially cohosted with other mirrors or their members) must have its own subnet, and each mirror its own VIP (if VIPs are used). This may be more or less complex, depending on the environment involved, and requires the node cohosting the mirror members to have multiple NICs to support the multiple subnets. For important information about mirror network configuration and VIPs , see Mirroring Communication, Sample Mirroring Architecture and Network Configurations, and Planning a Mirror Virtual IP (VIP), and Configuring a Mirror Virtual IP (VIP).
-
The cohosting of mirror members has no impact on the network location of the arbiter for each mirror, as described in Locating the Arbiter to Optimize Mirror Availability. The mirrors involved can share an arbiter or use separate arbiters, as long as the failover members and arbiter(s) are appropriately located.