インターシステムズ高可用性ソリューション
高可用性 (HA) とは、計画的および計画外のダウンタイムの両方を最小限に抑えることで、システムやアプリケーションを操作可能な状態に維持し、きわめて高い確率でユーザがシステムやアプリケーションを利用できるようにするという目標を指します。InterSystems IRIS には、独自の HA ソリューションが用意されています。また、オペレーティング・システムのプロバイダが提供する一般的な HA ソリューションに簡単に統合されます。
システムの高い可用性を維持するための主要機能として、フェイルオーバーと呼ばれるものがあります。この手法では、障害が発生したプライマリ・システムをバックアップ・システムと入れ替えることで、プロダクションをバックアップ・システムに障害回避 (フェイルオーバー) します。多くの HA 構成は災害復旧 (DR) の機能も備えています。これは、HA 機能でシステムを利用可能な状態に維持できなくなったときに、システムの可用性を復元する機能です。
このページでは、InterSystems IRIS ベースのアプリケーションで使用可能な一般的な HA 方式の概要を示し、InterSystems IRIS HA ソリューションにおける問題について説明し、HA ソリューションの機能の比較を提示し、特定のフェイルオーバー方式での分散キャッシュの使用法を紹介します。
HA ソリューションを配備しない場合
InterSystems IRIS データベースの構造的な整合性と論理的な整合性は、ライト・イメージ・ジャーナリング、データベース・ジャーナリング、およびトランザクション処理といった組み込みの機能によって、常にプロダクション・システムの障害から保護されています。これらの機能の詳細は、"データ整合性ガイド" の “データ整合性の概要” の章を参照してください。しかし、HA ソリューションを配備していないと、障害の原因や、原因の特定および解決の能力によっては、多大なダウンタイムを招くことがあります。業務上それほど重要ではない多くのアプリケーションでは、このリスクは許容できるかもしれません。
この方法を採用するお客様は、以下の特質を備えています。
-
ジャーナリングやバックアップとリストアなどの明確で詳細な運用面のリカバリ手順。
-
ディスクの冗長性 (RAID やディスク・ミラーリング)。
-
ハードウェアをすばやく入れ替えることができる能力。
-
すべてのベンダとの年中無休のメンテナンス契約。
-
障害に起因して発生するある程度のダウンタイムに対する管理上の受容とアプリケーション・ユーザの許容。
OS レベルのクラスタ HA
オペレーティング・システム・レベルで提供されている一般的な HA ソリューションに、フェイルオーバー・クラスタがあります。このソリューションでは、共有ストレージおよびアクティブ・メンバに向けられるクラスタ IP アドレスを使用し、プライマリ・プロダクション・システムをスタンバイ・システム (通常は、プライマリと同等のシステム) で補完します。プロダクション・システムに障害が発生すると、スタンバイ・システムは、それまで障害が発生したプライマリ・システムで実行されていたプログラムとサービスを引き継ぐことで、プロダクションのワークロードを引き受けます。スタンバイには、障害が発生したプライマリ・システムがリストアされるまでの間、通常のプロダクション・ワークロードを処理できるだけの能力が必要になります。スタンバイ・システムがプライマリ・システムになって、障害からリストアされたプライマリ・システムがスタンバイ・システムになる構成も可能です。
InterSystems IRIS は、("インターシステムズのサポート対象プラットフォーム" で説明されている) サポート対象プラットフォームのフェイルオーバー・クラスタ・テクノロジと簡単に統合できるように設計されています。InterSystems IRIS インスタンスは、クラスタの共有ストレージ・デバイスにインストールして、そのインスタンスが両方のクラスタ・メンバに認識されるようにします。その後で、このインスタンスをクラスタ構成に追加して、フェイルオーバーの構成要素としてスタンバイで自動的に再起動されるようにします。フェイルオーバー後の再起動時、システムは自動的に通常のスタートアップ・リカバリを実行し、障害が発生したシステムで InterSystems IRIS が再起動された場合とまったく同じように構造的な整合性と論理的な整合性が維持されます。複数の InterSystems IRIS インスタンスを単一クラスタにインストールすることもできます (必要な場合)。
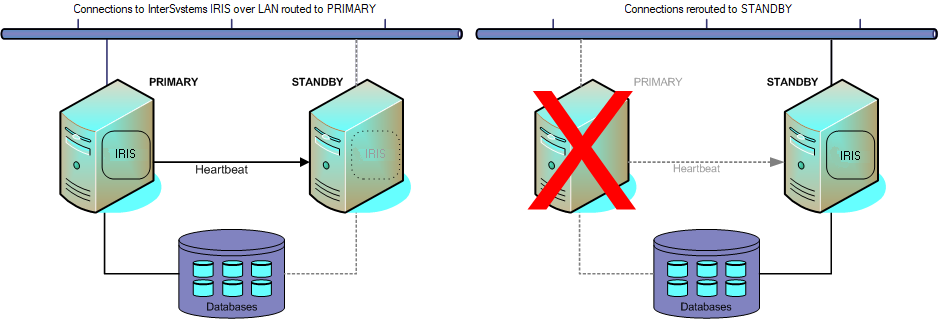
仮想化プラットフォーム HA
仮想化プラットフォームには、一般に HA 機能が備わっています。多くの場合、その HA 機能でゲスト・オペレーティング・システムと、それを実行しているハードウェアの両方の状態を監視します。そのどちらかに障害が発生すると、仮想化プラットフォームは障害が発生した仮想マシンを自動的に再起動します。必要に応じて、代替のハードウェア上で再起動することもあります。InterSystems IRIS インスタンスは、再起動時に通常のスタートアップ・リカバリを自動的に実行し、物理サーバで InterSystems IRIS が再起動された場合とまったく同じように構造的な整合性と論理的な整合性が維持されます。
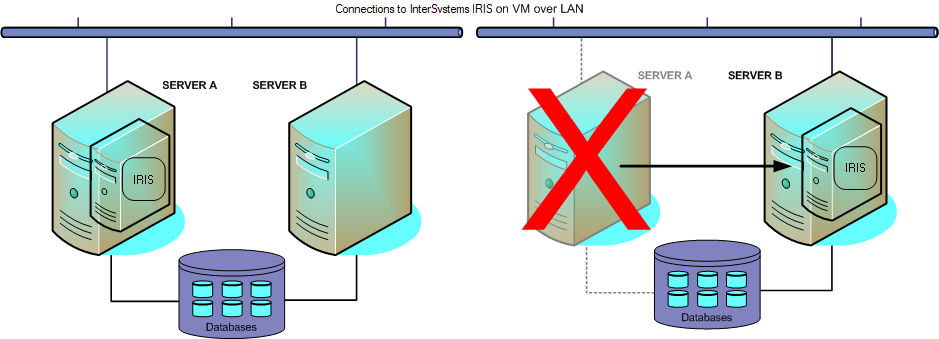
仮想化 HA は、仮想化プラットフォームのインフラストラクチャに組み込まれているため、非常にわずかな作業で構成できる (構成作業がまったく必要ないこともある) という利点があります。さらに、仮想化プラットフォームでは、仮想マシンをメンテナンス目的で代替のハードウェアに計画的に再配置することもできます。これにより、例えば、物理サーバのアップグレードをダウンタイムなしで実行できます。
InterSystems IRIS ミラーリング
自動フェイルオーバーを備えた InterSystems IRIS ミラーリングは、HA に別の手法を採用しています。この手法では、完全に独立したシステム間での論理的なデータ・レプリケーションによって、共有ストレージにおける単一障害点のリスクを回避し、ほとんどすべて (システム、ストレージ、およびネットワーク) の障害シナリオで、プロダクションは即座に代替の InterSystems IRIS インスタンスにフェイルオーバーできるようになります。
InterSystems IRIS ミラーでは、プライマリ・フェイルオーバー・メンバと呼ばれる 1 つの InterSystems IRIS インスタンスがプロダクション・データベースへのアクセスを提供します。別のホスト上のバックアップ・フェイルオーバー・メンバと呼ばれるもう 1 つのインスタンスは、プライマリと同期的に通信して、プライマリのジャーナル・レコードを取得し、レコードの受信を通知し、そのレコードを同じデータベースのバックアップ側専用のコピーに適用します。この方法では、バックアップがプライマリから最新のジャーナル・ファイルを受け取っているかどうかについて、プライマリとバックアップの両方が常に認識しているため、バックアップとプライマリのデータベースを正確に同期できるようになります。
これにより、プライマリが停止したときに、ミラーはデータを損失することなく、すばやく自動的にバックアップにフェイルオーバーできます。3 番目のシステム (アービター) は、プライマリが応答しなくなったときに、バックアップによる引き継ぎが必要かどうかの判断を支援します。フェイルオーバー・メンバが共有する仮想 IP アドレスや分散キャッシュ・クラスタなどのメカニズムにより、アプリケーションの接続は新しいプライマリにリダイレクトされます。フェイルオーバー・プロセスはわずか数秒で完了するため、このプロセスに気付くユーザはほとんどいないでしょう。また、バックアップは専用のデータベースのコピーを保持しているため、プライマリとプライマリのストレージに全体的な障害が発生しても、データベースが利用不可の状態になることはありません。実際、バックアップが最新のジャーナル・データを得られなかったとしても、バックアップのミラー・エージェントは、プライマリのホストがオンラインであれば、そのホストからジャーナル・データを取得できます。
フェイルオーバー後に、以前のプライマリを稼働状態にリストアすると、そのプライマリはバックアップになり、そのデータベースは新しいプライマリのデータベースに合わせて同期され、ミラーは完全な HA 機能を取り戻します。その後で、それぞれのシステムを元の役割に戻すことも、新しい配置を維持することもできます。
ミラーには、災害復旧 (DR) 非同期メンバを含めることもできます。このメンバには、プライマリのコピーが非同期的に維持されます。DR 非同期はフェイルオーバー・メンバに昇格させることができます。例えば、障害が発生したプライマリを短時間で稼働状態にリストアできないときや、(物理的に分離されている場合は) データ・センタの障害などで両方のフェイルオーバー・メンバがダウンする停止状態からの災害復旧の際には、DR 非同期がバックアップになります。最後に、ミラーにはレポート非同期メンバを含めることができます。このメンバは、ビジネス・インテリジェンスおよびデータ・ウェアハウジングを目的としたプロダクション・データベースの非同期コピーを維持します。
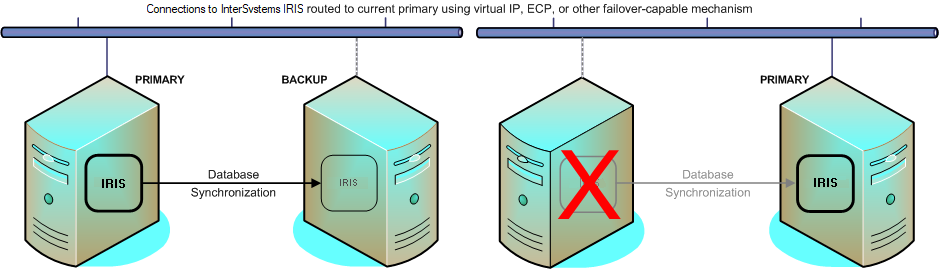
ミラーリングは、仮想化プラットフォーム HA と併用すると、ハイブリッド型 HA 手法も作成できます。この手法では、システム・レベルまたは OS レベルで発生する計画外停止に仮想化プラットフォームで対応し、すべての計画的停止と計画外データベース停止 (InterSystems IRIS 停止とストレージ障害の両方を含む) には、自動フェイルオーバーを通じたミラーリングで対処します。
InterSystems IRIS ミラーリング (DR 機能を含む) の詳細は、"高可用性ガイド" の “ミラーリング” の章を参照してください。
HA ソリューションの機能の比較
以下の表では、HA ソリューションのミラーリング、クラスタリング、および仮想化について、大まかな機能を比較しています。
| 機能 |
InterSystems IRIS ミラーリング |
OS レベルのクラスタリング |
仮想化プラットフォーム HA |
|---|---|---|---|
|
マシンの停電後またはクラッシュ後のフェイルオーバー |
マシンの障害をシームレスに処理します。 |
マシンの障害をシームレスに処理します。 |
物理マシンと仮想マシンの障害をシームレスに処理します。 |
|
ストレージの障害とデータの破損からの保護 |
組み込みのレプリケーションにより、ストレージの障害を防止します。論理レプリケーションにより、ほとんどの種類のデータ破損の持ち越しを回避します。 |
共有ストレージ・デバイスに依存するため、障害が深刻な状況を発生させます。ストレージ・レベルの冗長性を選択できますが、ある種のデータ破損を持ち越す可能性があります。 |
共有ストレージ・デバイスに依存するため、障害が深刻な状況を発生させます。ストレージ・レベルの冗長性を選択できますが、ある種のデータ破損を持ち越す可能性があります。 |
|
InterSystems IRIS のシャットダウン、ハング、またはクラッシュ後のフェイルオーバー |
高速な検出とフェイルオーバーが組み込まれています。 |
InterSystems IRIS の停止後にフェイルオーバーするように構成できます。 |
InterSystems IRIS の停止後にフェイルオーバーするように構成できます。 |
|
InterSystems IRIS のアップグレード |
最小限のダウンタイムで InterSystems IRIS のアップグレードが可能です。* |
InterSystems IRIS のアップグレードには、ダウンタイムが必要です。 |
InterSystems IRIS のアップグレードには、ダウンタイムが必要です。 |
|
アプリケーションの平均リカバリ時間 |
通常、フェイルオーバーの時間は数秒間です。 |
フェイルオーバーには数分間かかることがあります。 |
フェイルオーバーには数分間かかることがあります。 |
|
外部ファイルの同期化 |
データベースのみがレプリケートされます。外部ファイルについては、外部ソリューションが必要になります。 |
すべてのファイルを両方のノードで使用できます。 |
フェイルオーバー後にすべてのファイルを使用できます。 |
* アプリケーション・データを格納するデータベースとは別のデータベースに、アプリケーション・コード、クラス、およびルーチンが保持される構成が必要になります。
フェイルオーバー方策での分散キャッシュの使用法
HA に向けてどの手法を採用する場合でも、エンタープライズ・キャッシュ・プロトコル (ECP) に基づいた分散キャッシュ・クラスタを使用することで、ユーザとデータベース・サーバとを分離するレイヤを実現できます。データ・サーバに障害が発生しても、ユーザ側ではクラスタのアプリケーション・サーバとの接続が維持されます。この停止の間にデータに頻繁にアクセスするユーザ・セッションと自動トランザクションは、フェイルオーバーの完了または障害が発生したシステムの再起動によってデータ・サーバが再び利用可能になるまで一時停止状態になります。
なお、HA の計画に分散キャッシュを追加することでシステムが複雑になり、新たな障害点が発生することには注意を要します。
分散キャッシュの詳細は、"スケーラビリティ・ガイド" の “InterSystems 分散キャッシュによるユーザ数に応じたシステムの水平方向の拡張” を参照してください。