原則と推奨事項
ここでは、InterSystems IRIS® データ・プラットフォームの Business Intelligence モデルに関する主要な原則およびその他の推奨事項について説明します。
"このドキュメントに示したサンプルのアクセス方法" も参照してください。
ベース・テーブルの選択
キューブを定義する際、最初の手順は、そのキューブのベース・クラスとして使用するクラスの選択です。覚えておかなくてはならない主要ポイントは、キューブ内のレコード数はすべてこのクラスのレコード数を指すことです。これはキューブ内で参照される他のクラスと異なる点です。同様に、ベース・クラスの選択で、そのキューブ内のすべてのメジャーの意味が決まります。
以下はその例です。
-
ベース・クラスが Transactions の場合はトランザクションがカウントされます。このキューブでは、以下のようなメジャーを設定できます。
-
トランザクションあたりの平均ブローカ手数料 (またはトランザクションのグループの平均)
-
トランザクションあたりの平均トランザクション価額 (またはトランザクションのグループの平均)
-
-
ベース・クラスが Customer の場合は顧客がカウントされます。このキューブでは、以下のようなメジャーを設定できます。
-
顧客あたりの平均ブローカ手数料 (または顧客のグループの平均)
-
顧客あたりの平均トランザクション価額 (または顧客のグループの平均)
-
それぞれが使用するベース・クラスの異なる複数のキューブを設定し、ダッシュボードでそれらをまとめて使用することができます。
ベース・テーブルの形式の選択
また、ベース・テーブルの形式を考慮することも重要です。以下のテーブルに主な考慮事項を示します。
| ベース・テーブル | DSTIME をサポートしているか | リストをサポートしているか |
|---|---|---|
| ローカルの永続クラス (リンク・テーブル以外) | はい | はい |
| リンク・テーブル | いいえ | はい |
| ローカル・テーブルを使用するデータ・コネクタ | いいえ | はい |
| リンク・テーブルを使用するデータ・コネクタ | いいえ | いいえ |
DSTIME 機能は、対応するキューブを最新状態に保つ最も簡単な方法です。この機能を使用できない場合は、他の手法を使用できます。詳細は、"キューブの最新状態の維持" を参照してください。
多数のレベルおよびメジャーの回避
クラスのインデックス数には制限があるため、InterSystems IRIS® データ・プラットフォームは、キューブのレベルおよびメジャーの数に上限を設定します。この制限 (経時的に増加する場合あり) の詳細は、"一般的なシステム制限" を参照してください。レベルおよびメジャー用にシステムが作成するインデックス数の詳細は、"ファクト・テーブルおよびディメンジョン・テーブルの詳細" を参照してください。
過度に複雑なモデルを理解して使用するのは困難であるため、レベルおよびメジャーの数をこの制限によって要求される数よりもはるかに少なく維持することが適切です。
メジャーの適切な定義
メジャーは、ベース・テーブルのレコードと一対一のリレーションシップを持つ値に基づく必要があります。そうでない場合は、そのメジャーが適切に集約されなくなります。このセクションでは、この原則を例を使用して示します。
親テーブルに基づくメジャー
親テーブルのフィールドに基づくメジャーを定義しないでください。例えば、次のような 2 つのテーブルがあるとします。
-
Order — 各行は顧客から送信された注文を表しています。フィールド SaleTotal は、注文の合計金額を表しています。
-
OrderItem — 各行はその注文を構成する項目を表しています。このテーブルでは、注文の中でこの項目が占める合計金額をフィールド OrderItemSubtotal で表しています。
OrderItem をベース・テーブルとして使用するとします。また、親の SaleTotal フィールドに基づいて、メジャー Sale Total を定義するとします。このメジャーの目的は、選択した注文項目のすべての販売における売上総額を表示することです。
次にファクト・テーブルの内容を検討します。以下に例を示します。
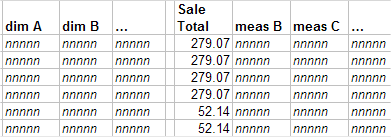
最初の 4 つの行は、同じ注文にある項目を表しています。次の 2 つの行は、別の注文の項目を表しています。
このモデルには Item Type という名前のディメンジョンがあるとします。システムによって、Item Type が type R であるすべての項目のレコードが取得されるときの動作について調べてみましょう。
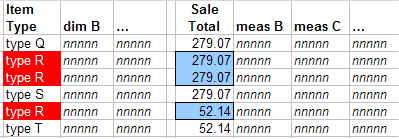
type R の Sale Total メジャーの値を計算するために、3 つの値 279.07、279.07、および 52.14 が加算されます。ただし、このアクションでは、1 件の注文が 2 回カウントされています。
Sale Total メジャーが正しく集約されることもあります。つまり、選択した注文項目の正確な総売上の数字が得られることもあります。ただし、この例で見たように、カウントの重複を回避できないので、このメジャーがいつでも正しく集約されるとは限りません。
子テーブルに基づくメジャー
子テーブルの値をメジャーの基礎として使用することは可能ですが、そのためにはその値を子テーブルの関連行に集約する必要があります。
次の 2 つのテーブルについて考えてみましょう。
-
Customer — 各行は 1 人の顧客を表しています。
-
Order — 各行は顧客からの 1 件の注文を表しています。フィールド SaleTotal は、注文の合計金額を表しています。
Customer をベース・テーブルとして使用し、SaleTotal フィールドに基づいてメジャーを作成するとします。
1 人の顧客に複数の注文が存在する可能性があるので、指定された顧客の SaleTotal には複数の値が存在します。このフィールドをメジャーとして使用するには、これらの値をまとめて集約する必要があります。考えられる選択肢は、このメジャーの目的に応じて、これらの値の合計値または平均値を求めることです。
時間レベルの理解
時間レベルでは、レコードを時間でグループ化します。つまり、どのメンバも特定の日時に関連付けられたレコードで構成されています。例えば、トランザクション日というレベルで、トランザクションをその発生日でグループ化します。時間レベルには、一般的な種類として以下の 2 つがあります。これらの相違を理解しておくことが重要です。
-
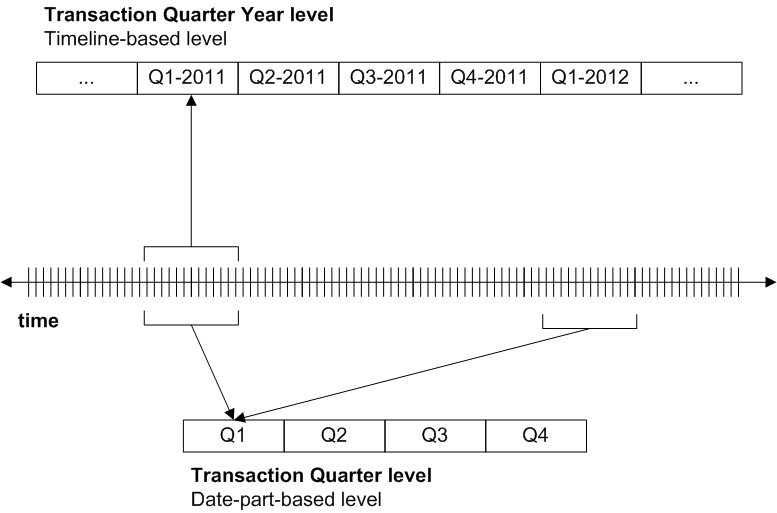
時間軸に基づくレベル :この種類の時間レベルでは、時間軸を互いに隣接する時間ブロックに分割します。このレベルのどのメンバも、単一の時間ブロックで構成されています。より正確に表現すると、その時間ブロックに関連付けられたレコードで各メンバが構成されています。年の四半期のトランザクションというレベルでは、2011 年の第 1 四半期に属する日付に発生したすべてのトランザクションが Q1-2011 メンバにグループ化されます。
この種類のレベルでは、ソース・データに応じて任意の数のメンバを扱うことができます。
-
日付部分に基づくレベル :この種類の時間レベルでは、日付部分 の値のみが考慮され、時間軸は無視されます。どのメンバも、以下に示すように、時間軸上の異なる位置にある複数の時間ブロックで構成されています。より正確に表現すると、これらの時間ブロックに関連付けられたレコードで各メンバが構成されています。四半期のトランザクションというレベルでは、あらゆる年の第 1 四半期に属する日付に発生したすべてのトランザクションが Q1 メンバにグループ化されます。
この種類のレベルでは、固定した数のメンバを扱います。
以下の図は、これらの種類の時間レベルを比較したものです。
これらの種類のレベルを同時に使用しても問題ありません。メンバをどのように組み合わせても、エンジンでは正しいレコード群が必ず返されます。ただし、混乱を招く典型的な原因が 2 つあります。
-
時間レベルの階層 (つまり、複数のレベルを含む階層) を定義する場合、組み込むものを注意深く考慮する必要があります。次のセクションで記述するように、MDX 階層は親子階層です。親レベルのどのメンバにも、その子メンバのすべてのレコードを含める必要があります。
つまり、例えば、年のトランザクション・レベルを年の四半期のトランザクション・レベルの親として使用できますが、四半期のトランザクション・レベルの親としては使用できません。これを確認するには、前の図を参照してください。Q1 メンバはすべての年の最初の四半期を表すため、Q1 の親になることができる単一の年はありません。
適切な時間階層のガイドラインについては、"時間レベルと階層" を参照してください。
-
一部の MDX 関数は、時間軸を表すレベルでは有用ですが、日付部分のみを表すレベルでは役に立ちません。このような関数として、PREVMEMBER、NEXTMEMBER などがあります。例えば、該当する日付を収めたデータに対して Q1–2011 で PREVMEMBER を使用すると、Q4–2010 が返されます。Q1 で PREVMEMBER を使用すると、有意なデータは返されません。
以下の柔軟性のある方法の定義を試行します。時間軸を表す 1 つのレベルを含むように Year レベルを定義します。他のすべての時間レベルを日付部分レベルとして定義します。以下の例のように、これらのレベルを同時に使用できます。
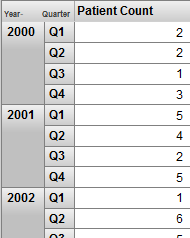
このピボット・テーブルは、行に対して Year (時間軸レベル) と Quarter (日付部分レベル) の組み合わせを使用します。Quarter レベルは、四半期ごとのパターンで情報を提供できるため、単独でも有用です。SAMPLES のサンプル・データはこのことを説明していませんが、この方法を確認できる多種類の季節ごとのアクティビティがあります。以下に例を示します。
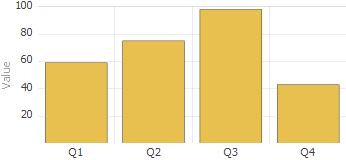
階層の適切な定義
どの階層でも、アーキテクトに示すようにレベルの順序には注意する必要があります。レベルは自動的に、その階層内で前にリストされたレベルの子になります。例えば、Patients サンプルの HomeD ディメンジョンを考えてみましょう。

ZIP レベルは City レベルの親です。より正確には、ZIP レベルの各メンバは City レベルの 1 つ以上のメンバの親です(現実には、郵便番号と市区町村には多対多のリレーションシップが存在しますが、Patients サンプルは単純化されており、このサンプルでは、郵便番号は市区町村より広い地域を表しています)。
階層内では、最初のレベルの粒度が最も低く、最後のレベルは粒度が最も高くなります。
MDX 階層は親子階層です。このルールを実施するために、システムは、キューブを構築するときに以下のロジックを使用します。
-
階層で定義された最初のレベルに対して、システムは一意のソース値ごとに個別のメンバを作成します。
-
その後のレベルでは、親メンバと組み合わせて、レベルのソース値が考慮されます。
例えば、最初のレベルが State で、2 番目のレベルが City だとします。City レベルのメンバを作成する際、システムは市区町村名とその市区町村が含まれる都道府県名の両方を考慮します。
時間階層では内部ロジックが若干異なりますが、目的は同じです。
階層反転の結果について
上記とは逆に、キューブ内で City レベルを ZIP レベルの前に移動して、リコンパイルおよび再構築するとします。ZIP レベルをピボット・テーブルの行に使用すると、以下のようになります。
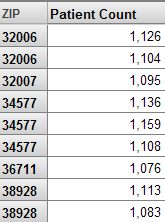
この場合、システムは、(例えば) 異なる市区町村に属する 2 つの ZIP コード 32006 が存在すると想定しているため、同名で複数のメンバを作成しています。
この状況では、同名で複数のメンバが存在することは明らかに不適切です。ただし、シナリオによっては、同名で複数のメンバが存在することが正当である場合もあります。例えば、異なる国々に同名の市区町村が存在する場合があります。つまり、メンバ名に重複がある場合、反転階層を示す可能性があります。ただし、すべての状況で当てはまるわけではありません。
時間階層
MDX 階層は親子階層です。特定の子メンバのレコードのすべてが、親メンバにも含まれている必要があります。時間レベルを階層に配置する方法を注意深く考慮することが重要です。前のセクションを参照してください。また、適切な時間階層のガイドラインについては、"時間レベルと階層" を参照してください。
メンバ・キーおよび名前の適切な定義
各メンバには、名前と内部キーの両方があります。既定では、これらは時間レベルを除いて同じです。これらの ID は両方とも文字列です。モデルを定義する際は、以下の項目について考慮する必要があります。
-
メンバ・キーが非常に長い場合、SUBSCRIPT エラーがトリガされることがあります。非常に長いメンバ・キーが生成されるソース・データを操作している場合、選択した方法でデータが保持されるように、お使いのレベルの sourceExpression にソース処理を実装することができます。
-
メンバ名の重複が適切な場合があります。例えば、別人が同じ名前を持つ場合があります。ユーザがメンバをドラッグ・アンド・ドロップすると、システムで生成されるクエリでは、名前でなくメンバ・キーが使用されます。
-
メンバ・キーが各レベルで一意であることを確認することをお勧めします。メンバ・キーの重複があると、すべての個別メンバを参照することが困難になります。
特に、メンバ・キーの重複がある場合、ユーザはダブルクリックで確実にドリルダウンすることができません。
-
1 つのレベルに同名の複数のメンバが存在する場合は、メンバ間の区別を可能にするため、値がキーと同じであるレベルにプロパティを追加することもお勧めします。これは、レベルで使用されるものと同じソース・プロパティまたはソース式をそのプロパティの基にするだけです。
その後、ユーザはメンバの区別に役立つプロパティを表示できます。
または、このレベルにツールのヒントを追加して、メンバ・キーを表示するようにします。
以降のセクションでは、メンバ・キーまたは名前に重複が生じる可能性があるシナリオについて説明します。
重複メンバ・キーが生成される状況
メンバ・キーの重複は適切ではありません。メンバ・キーの重複がある場合、ユーザはダブルクリックで確実にドリルダウンすることができません。
時間レベルを除き、レベルに対する一意の各ソース値がメンバ・キーになります(時間レベルは、すべてのメンバに対する一意のキーの生成に使用されるロジックが少し異なります)。
上位レベルが同じ階層に存在する場合、システムは同じキーで複数のメンバを生成することがあります。"メンバ・キーの一意性の保証" を参照してください。
重複メンバ名が生成される状況
重複メンバ名は、業務のニーズによって適切な場合と不適切な場合があります。
時間レベルを除き、レベルに対する一意の各ソース値が既定でメンバ名になります(時間レベルの場合は、システムによりすべてのメンバに対して一意の名前が生成されます)。
システムによって複数のメンバが同じ名前で生成される可能性がある状況は以下の 2 つのみです。
-
高いレベルが同じ階層に存在する場合。この高いレベルは、適切な場合も、不適切な場合もあります。"階層の適切な定義" を参照してください。
-
以下のようにレベルを定義している場合。
-
メンバ名が、レベル定義自体とは別に定義されている。
-
メンバ名が一意でないものに基づいている。
"プロパティ名をメンバ名として使用する方法" を参照してください。
-
InterSystems IRIS は、ファクト・テーブルの構築時に文字列値から先頭のスペースを自動的には削除しません。ソース・データに先頭のスペースが含まれる場合は、これらを削除するソース式を使用します。以下はその例です。
$ZSTRIP(%source.myproperty,"<W")
このようにしないと、同じように見える名前を持つ複数のメンバが作成されることになります (一部の名前の先頭に余分なスペースが存在するため)。
過度な粒度レベルの回避
Business Intelligence の新規ユーザは、通常、ベース・テーブルとの 1 対 1 のリレーションシップを持つレベルを定義します。このようなレベルは有効ですが、そのレベルをさらにフィルタと組み合わせて、表示されるメンバの数を制限しないときには、特に役立つことはありません。
過度な粒度レベル (詳細レベル) には大量 (おそらく数十万から数百万) のメンバが含まれ、Business Intelligence はこのシナリオに向けて設計されていません。
例えば、Patient サンプルに変更を加えて Patient レベルを持つようにしたとします。このようにすると、以下のようなピボット・テーブルが得られます。
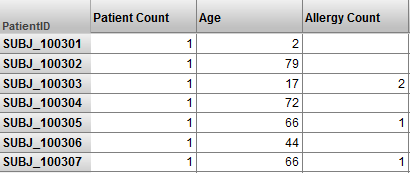
これは、有効ですが、これと同じ結果は SQL クエリでより効率的に生成できます。"Business Intelligence によるファクト・テーブルの構築方法と使用方法" で説明した処理について検討してください (その説明では、実際の処理ではなく概念的な流れを示していますが、全体的な考え方は同じです)。その処理は、できる限り短時間で値を集約することを目的としています。上記のピボット・テーブルには、集約がありません。
ここに示したようなピボット・テーブルが必要な場合は、SQL ベースの KPI として作成してください。"InterSystems Business Intelligence の上級モデリング" を参照してください。
リスト・ベースのレベルの使用に関する注意
Business Intelligence では、他の多くの BI ツールと異なり、レベルのベースにリスト値を使用できます。このようなレベルは便利ですが、その動作を理解しておくことが重要です。
例えば、1 人の患者に複数のアレルギーを指定できます。各アレルギーにはアレルゲンと重症度があります。ベース・テーブルは Patients で、モデルには Allergies と Allergy Severity の各レベルが存在するとします。次のようなピボット・テーブルを作成できます。
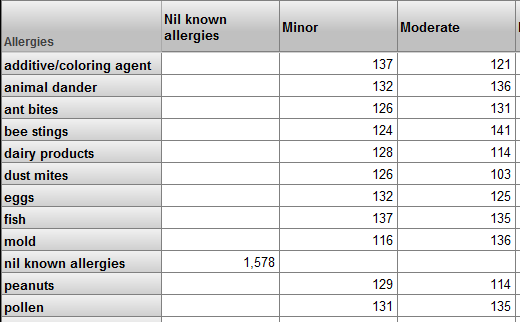
このピボット・テーブルを初めて見たユーザは、このピボット・テーブルでは、患者のさまざまなアレルギーどうしの相関関係が示されていると考えるかもしれません。しかし、それは正しくありません。
このキューブの他のすべてのピボット・テーブルと同様、このピボット・テーブルも患者のセットを示します。例えば、ant bites の行は、アリによる咬傷に対してアレルギーがある患者を表しています。Minor 列は、軽度と識別されたアレルギーを 1 つ以上持っている患者を表しています。アリによる咬傷に対する 1 つのアレルギーと、軽度とマークされたアレルギーを 1 つ以上持つ患者が 126 人います。これは、アリによる咬傷に対して軽度のアレルギーを持つ患者が 126 人いるということではありません。
患者のさまざまなアレルギーどうしの相関関係を示すピボット・テーブルを作成することもできます。ただし、そのためには、患者ではなく患者のアレルギーに基づいたモデルを定義する必要があります。
フィルタ内でリスト・ベースのレベルを使用する場合は、結果に対する慎重な配慮が必要です。次のようなピボット・テーブルがあるとします。
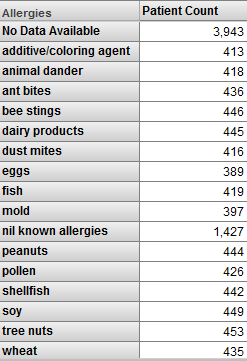
このピボット・テーブルは、患者をアレルギー別に分類して表示します。ここで、このピボット・テーブルにフィルタを適用し、フィルタで魚のメンバを選択するとします。
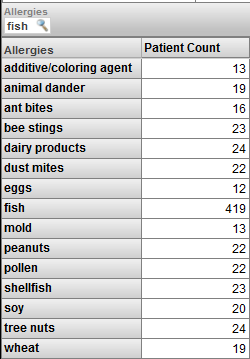
これで、魚に対するアレルギーを持つ患者のみが表示されます。以下のことに注意してください。
-
このピボット・テーブルは、魚のメンバを表示します。このメンバの患者数は、前のピボット・テーブルと同じです。
-
また、Allergies レベルのその他のメンバも表示されます。これらのメンバについては、患者数が前のピボット・テーブルより少なくなります。
-
このピボット・テーブルには、Diagnoses レベルの No Data Available メンバは含まれません。Nil Known Allergies メンバも含まれません。
これらの結果を理解するには、魚に対するアレルギーのある患者だけを表示していること、およびこれが魚アレルギーのみの表示とは同じでないことを忘れないでください。魚に対してアレルギーがある患者は、他の物に対するアレルギーもあります。例えば、魚に対してアレルギーがある患者のうち 13 人は、添加物/着色料に対するアレルギーもあります。
フィルタを変更して No Data Available メンバのみを選択すると、以下のように表示されます。
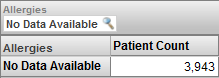
この場合は、アレルギーの記録がない患者のみが表示されます。定義により (このレベルの定義方法により)、これらの患者と特定のアレルギーのある患者の重複はありません。
リスト・ベース・レベルは、子レベルまたは親レベルを持つことができません。
NULL 値の適切な処理
どのメジャーやレベルでも、状況によってはソース値が NULL になる可能性があります。ユーザの業務上の必要性および使いやすさの要件に応じて、システムが NULL を処理する方法を理解して、目的のモデルを調整することは重要です。
メジャーにおける NULL 値
メジャーの場合、特定のレコードのソース値に欠落があると、システムはファクト・テーブルのメジャー列に値を何も書き込みません。また、そのレコードは、メジャー値の集約時にシステムによって無視されます。ほとんどのシナリオでは、これが適切な動作です。これが適切ではない場合は、NULL 値を検出し、これを 0 などの適切な値に置換するソース式を使用する必要があります。
レベルにおける NULL 値
レベルで、ベース・クラスの特定のレコードのソース値が欠落している場合、システムは NULL 値を含むメンバを自動的に作成します (1 つの例外を除く)。メンバ名として使用するヌル置換文字列を指定します。この指定がないと、そのメンバには Null という名前が付けられます。
例外は計算ディメンジョンです。詳細は、"InterSystems Business Intelligence の上級モデリング" を参照してください。置換文字列はこの状況において何の影響も及ぼしません。
使いやすさに関する考慮事項
モデル要素がユーザにどのように表示され、ユーザがこれらをどのように使用するかを考慮することも有益です。ここではアナライザとピボット・テーブルでモデル要素をどのように表示するかについて説明し、最後にモデルに対する推奨事項を紹介します。
ディメンジョン、階層およびレベルの表示に関する考慮事項
アナライザの [モデル・コンテンツ] 領域には、各ディメンジョンとその中のレベルが表示されますが、階層は表示されません (スペースの関係上)。以下はその例です。
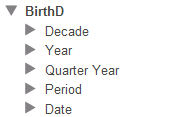
このため、アナライザで作業するユーザは、階層を介してどのレベルが関連しているかを認識しているとは限りません。
レベルが行に使用されている場合、レベル名が列タイトルとして表示されます。以下はその例です。
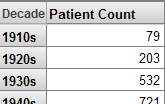
ディメンジョンが行に使用されている場合は、ディメンジョン名が列タイトルとして表示されます。また、ディメンジョンの All メンバ、およびそのディメンジョンで定義された最初のレベルのすべてのメンバを取得する MDX 関数も使用されます。
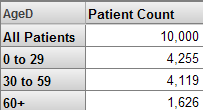
All メンバの使用に関する考慮事項
[モデル・コンテンツ] 領域にはすべての All メンバが表示されます。以下はその例です。
アナライザで、ユーザは他のメンバのドラッグと同様の方法で All メンバをドラッグ・アンド・ドロップできます。
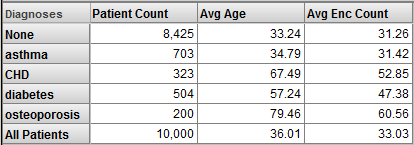
あるディメンジョンの All メンバは、他のすべてのディメンジョンの All メンバと等しくなります (名前は除きます)。適切な汎用名がある場合は All メンバは最下行として役立ちます。次に例を示します。
複数キューブの考慮事項
業務のある領域を分析するために、複数のキューブを定義する必要があることに気付いたときには、以下の点について検討してください。
-
キューブが多数あるときには、多くの場合、リレーションシップが役立ちます。個別の (定義が異なる) キューブに同じディメンジョンを何度も定義する代わりに、そのディメンジョンを 1 か所で定義できます。こうすることで、開発がより容易になり、必要なディスク容量が少なくなります。
リレーションシップの短所をあえて挙げると、"InterSystems Business Intelligence の上級モデリング" で説明するように、個別のキューブを再構築したときには、それに依存するすべてのキューブも適切な順序で再構築する必要があることです。
-
リレーションシップまたは共有ディメンジョンを定義する場合は、キューブ・マネージャを使用してキューブを正しい順序で構築してください。"キューブの最新状態の維持" を参照してください。
または、キューブを適切な順序で構築するユーティリティ・メソッドまたはルーチンを定義します。キューブを追加するときにそのようなメソッドを維持するほうが、それらのキューブを正しい順序で手動で再構築するよりも簡単です。
関連キューブを間違った順序で構築すると、トラブルシューティングが困難な問題が発生することがあります。
-
複数のキューブからのメジャーを表示するピボット・テーブルが必要な場合は、共有ディメンジョンと複合キューブを定義する必要があります。複合キューブは、それぞれ異なるキューブに属するメジャーを同時に使用するための唯一の方法です。
推奨事項
業務のニーズによっては、次の推奨事項も役立ちます。
-
ピボット・テーブルでディメンジョンを直接使用するかどうかを決定します。直接使用する場合、それらのディメンジョン (少なくとも表示名) にはわかりやすい名前を割り当てます。
直接使用しない場合は、MDX クエリおよび式の作成を容易にするため、名前を簡潔なものにして、スペースを省略します。
また、MDX クエリまたは式の表示や作成が必要な場合は、構文をわかりやすくするため、ディメンジョンにはディメンジョン内のどのレベルとも異なる名前を使用します。
-
階層名はアナライザやピボット・テーブルに表示されません。短い名前 (H1 など) を使用すると、MDX クエリおよび式が簡潔かつ読みやすくなります。
-
どのディメンジョンでも階層を 1 つのみ定義します。この規則を使用すると、ユーザはディメンジョン内のレベルが相互に関連付けられているかどうかを容易に認識できます。
-
All メンバは、1 つのディメンジョンでのみ定義します。この All メンバには All Patients などの適切な汎用名を指定します。All メンバの使用目的によっては、Total や Aggregate Value などの名前が適している場合もあります。
-
レベルにはわかりやすい名前を使用します。この名前はピボット・テーブルに表示されます。
-
階層が異なれば、同じ名前で複数のレベルを設定できます。ただし、ピボット・テーブルおよびフィルタはレベル名しか表示されないため、レベル名は一意にすることをお勧めします。
-
適用可能なレベルおよびメジャーごとに [ファクト・テーブルのフィールド名] オプションの値を指定します。このオプションは、時間レベル、NLP レベル、または NLP メジャーには適用されません。一意の名前を使用するように注意してください。
ファクト・テーブル内で指定されたレベルまたはメジャーが格納されているフィールドを特定できる場合は、トラブルシューティングが非常に簡単になります。
詳細は、"ファクト・テーブルおよびディメンジョン・テーブルの詳細" を参照してください。